环境部署
这一篇会带大家写部署环境的环境变量,配置文档,还有一些库包的清理删除问题;尽量让大家在部署的过程中更加舒适
一、安装包的传输与解压
这部分我们会用到 XFTP 或者 XTerminal,鉴于也不知道大家喜欢使用哪个,我就都写一下,当然,要是爱用 scp 进行文件传输的我也不拦着,毕竟大家都有自己的想法嘛不是。
1. XFTP 传输文件
-
首先,我们还是先打开
XFTP,然后连接上虚拟机,然后我们先在本机找到需要传输的目录路径,可以在上方地址栏输入路径,也可以点击打开目录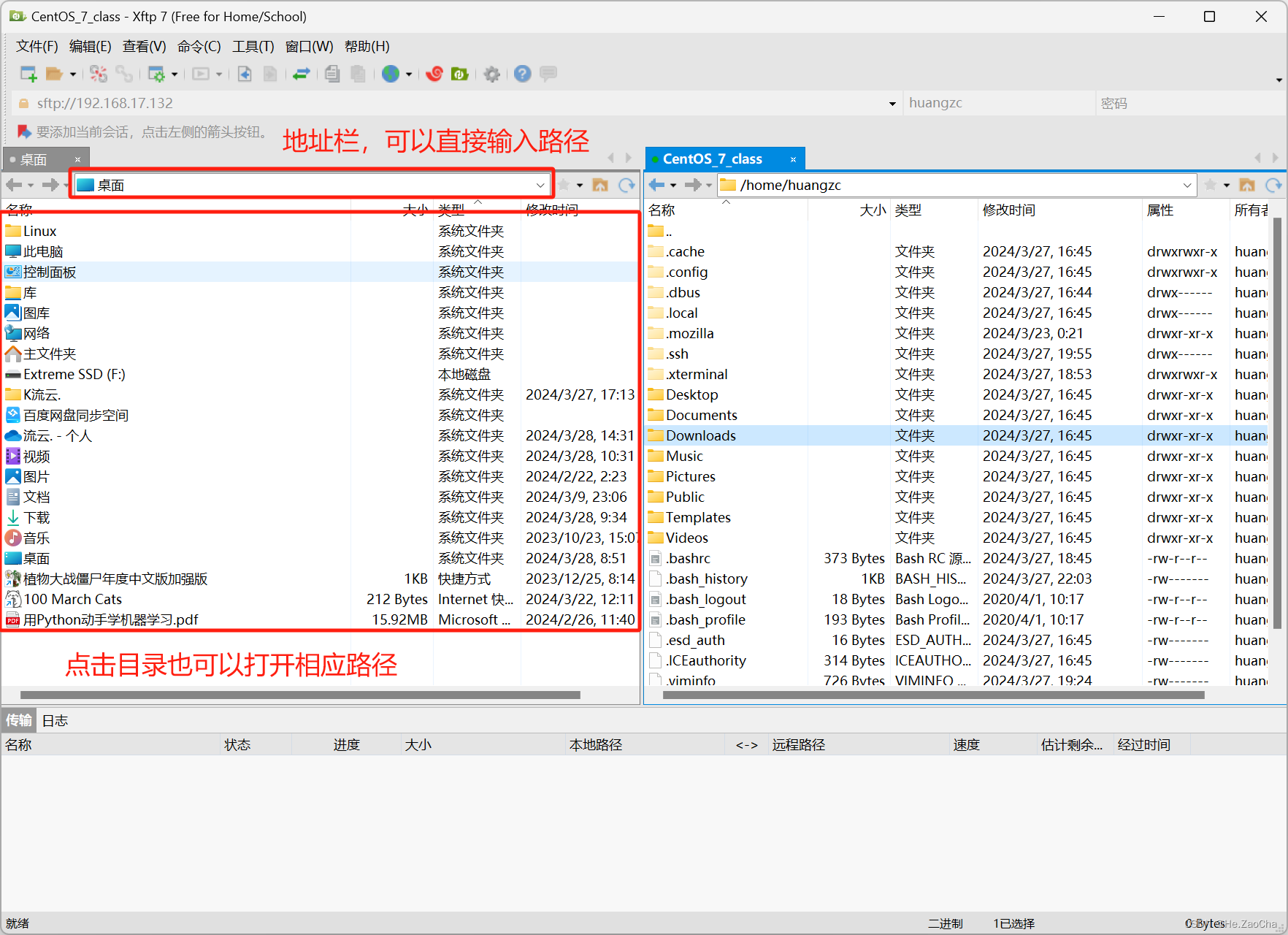
-
同理,我们在右边也是相同的操作,不过是虚拟机中存放这些安装包的目录路径,当然各位同学可以自行设置哪个目录,这都是不影响的。
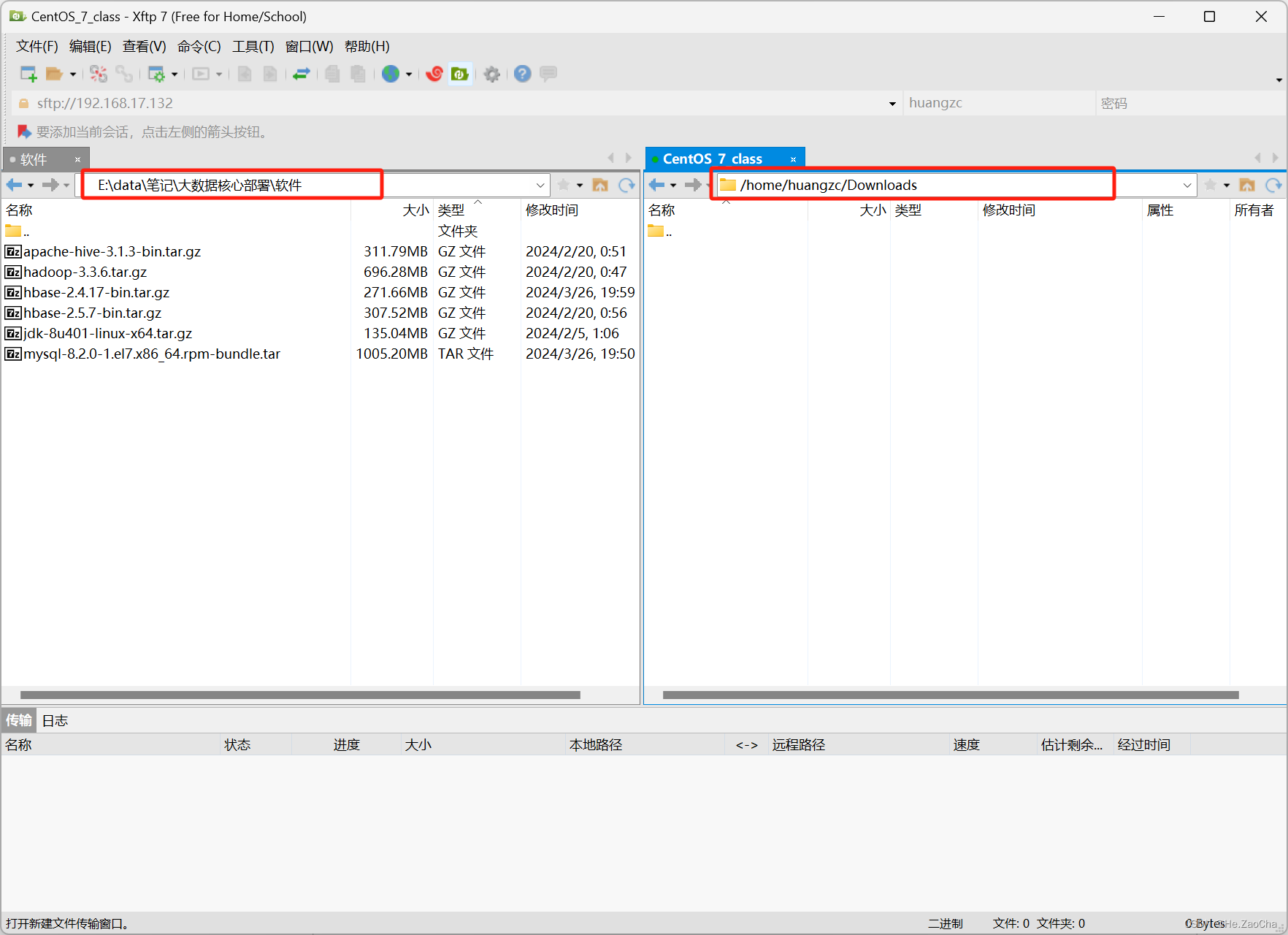
-
然后我们选择左边我们需要传输过去的安装包,然后拖动到右边即可进行传输
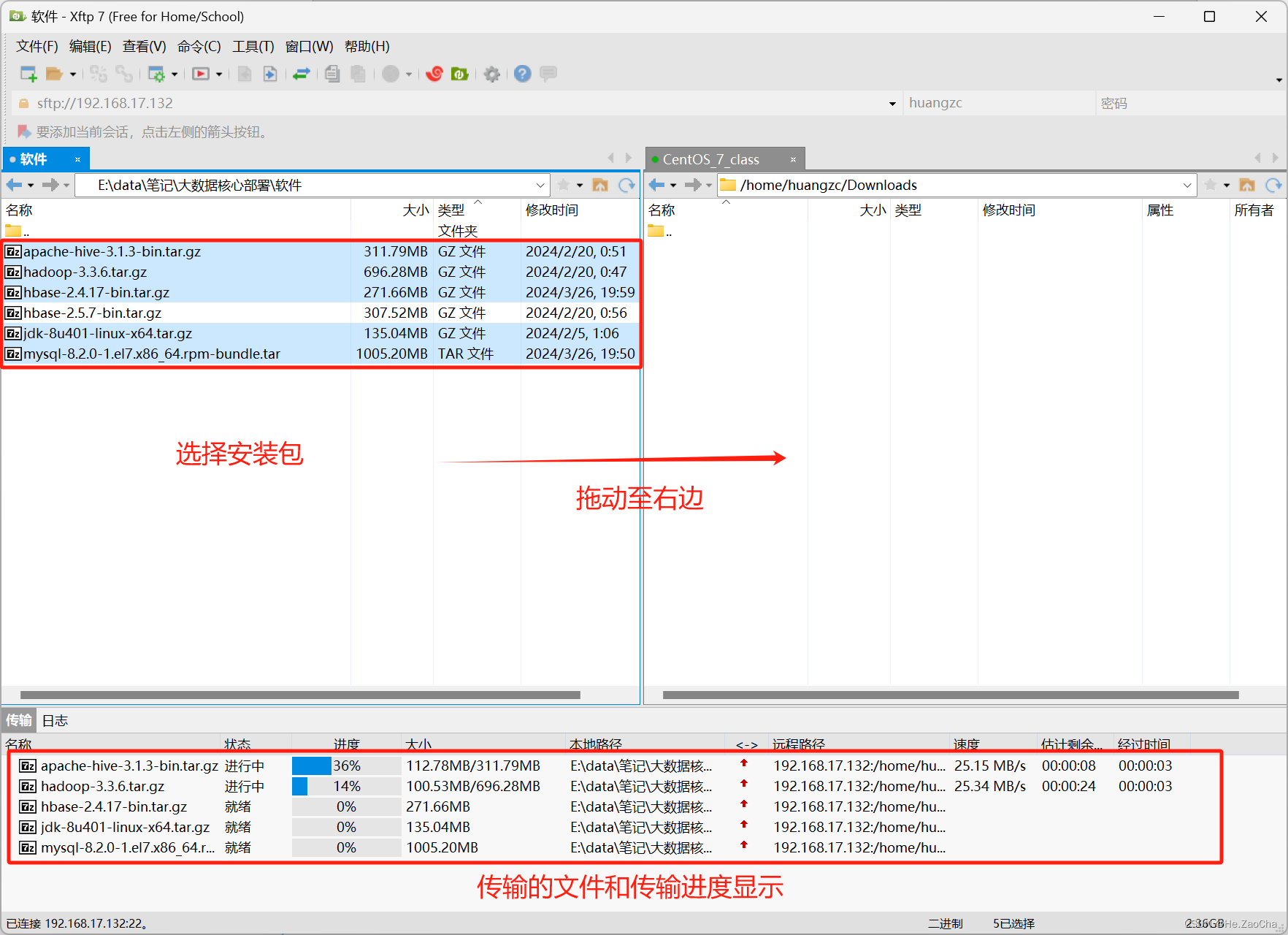
-
传输完成后,会如下图显示,右边的目录就会有传输过去的压缩包,不用担心格式问题。

-
最后我们也可以在终端中可以使用
ls指令查看该目录下是否有压缩包,如下图所示,说明我们成功了,这个路径的话,大家如果对Linux还有印象的话,应该是知道这个的,因为我的操作是在用户目录下,也就是/home/用户名/这个目录下,所以我可以直接查找该目录下存在的目录。
2. XTerminal 传输文件
-
首先,打开
XTerminal,然后连接虚拟机,左边应该会有文件树结构的,如果没有可以参照下图,在右下角打开。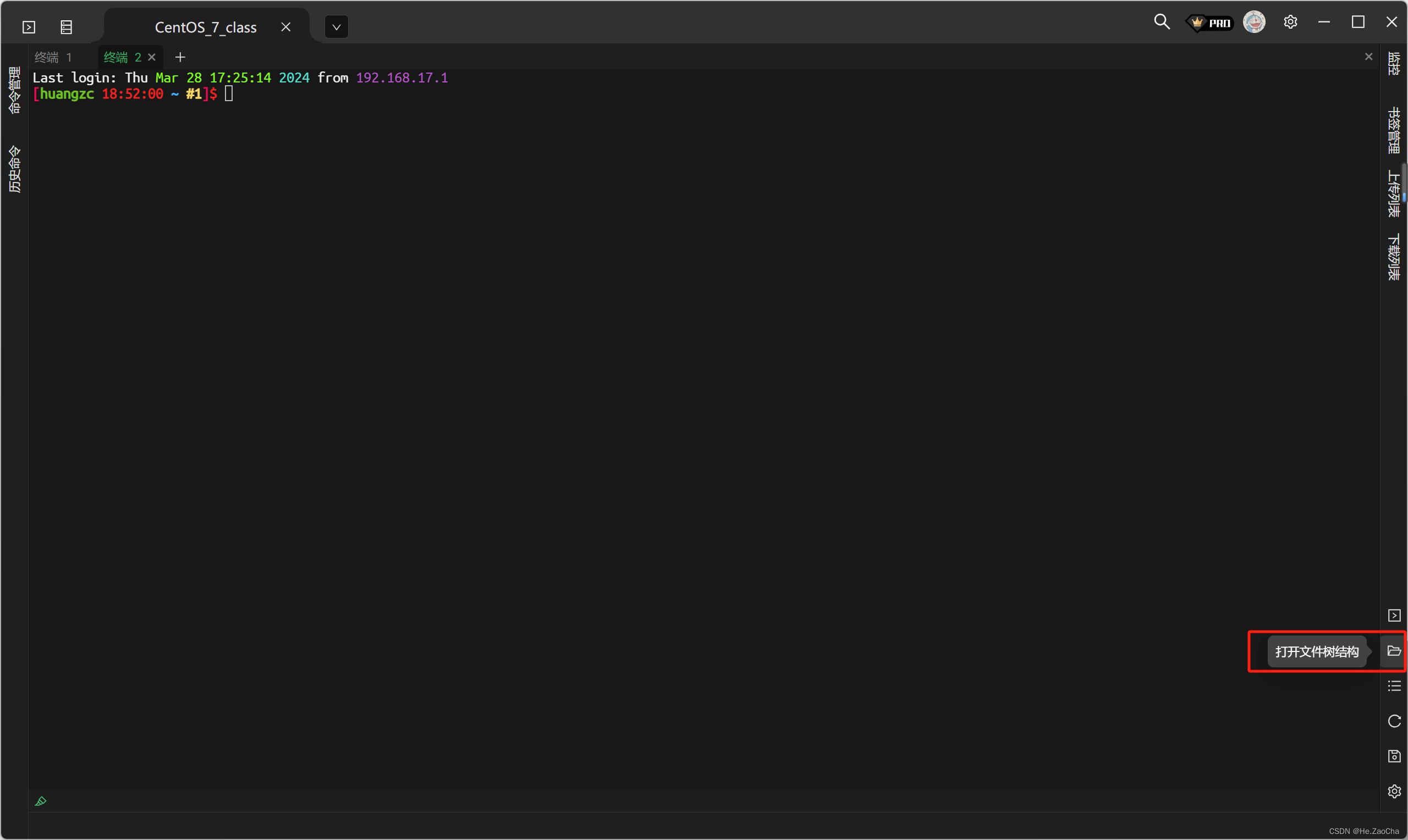
-
然后在左边的文件管理中选择放安装包的目录,记得要点击该目录,燃火左上角的栏目中最右边有个上传按钮,点击并选择
上传文件
-
选择要上传的文件,然后点击打开即可
-
传输过程会在右边显示
-
传输完成后右边会显示传输完成提示,也可以使用命令行进行查看

3. 解压安装包
关于解压这部分,我们会用到 tar 指令,如果有不清楚的也没关系,跟着走就可以了;我们得先想好我们需要将安装包解压到哪个目录中,这个没那么多讲究,要是想各个用户都可以使用,那么就解压到大家都有权限的目录中区中去,比如 /usr/local,这我选择直接在用户目录下新建一个目录进行解压存储。
-
新建一个目录用于存储软件
mkdir softwares # 新建一个名为 softwares 的目录如果操作没有问题的话,应该是不会有任何提示出现的,
Linux的优秀之处,没有报错那就是对的
-
解压
jdk-8u401-linux-x64.tar.gz,解压编程语言的解释器编译器这方面,我是会另建一个目录的,以防止使用的时候有冲突,所以我们先在softwares目录下再新建一个jvm目录来存放jdk的解压文档;解压的时候会有时间,但是因为没有提示,所以看起来像断开连接一样,所以如果想要进度条只能自己写脚本,但是可以加个-v来查看解压了什么文件,也算另一种方式查看进度条了。tar命令后面的-C是为了指定解压到某一目录mkdir softwares/jvm # 在 softwares 目录下新建 jvm 目录 tar -zxf Downloads/jdk-8u401-linux-x64.tar.gz -C softwares/jvm/ # 解压 jdk 到 jvm 目录下(注意,这里不会显示进度和解压的文件,如果需要查看解压了什么文件,请将 -zxf 改为 -zxvf)
-
解压
hadoop-3.3.6.tar.gz,关于同一类的文件我也会新建一个目录的,就比如JetBrains系列的工具会新建一个jetbrains目录来存储,不直接在softwares目录下面,同理,大数据的核心组件基本都是apache的工具,所以这里我也新建一个名为apache目录mkdir softwares/apache # 在 softwares 目录下新建 apache 目录 tar -zxf Downloads/hadoop-3.3.6.tar.gz -C softwares/apache/ # 解压 hadoop-3.3.6
-
解压
hbase-2.4.17-bin.tar.gztar -zxf Downloads/hbase-2.4.17-bin.tar.gz -C softwares/apache/ # 解压 hbase-2.4.17
-
解压
apache-hive-3.1.3-bin.tar.gztar -zxf Downloads/apache-hive-3.1.3-bin.tar.gz -C softwares/apache/ # 解压 hive-3.1.3 -
解压
MySQL系列包,这个会有一点复杂,因为MySQL是直接把离线的所有包下载下来了,所以就算是解压了tar包,还会有很多个rpm包,为什么不直接找可用包,因为感觉还是rpm安装起来比较简单,所以我们先在Downloads目录下新建一个名为mysql的文件夹,然后将mysql-8.2.0-1.el7.x86_64.rpm-bundle.tar解压到那里去,这里命令会有一些变化mkdir Downloads/mysql # 在 Downloads 目录下新建 mysql 目录 tar -xf Downloads/mysql-8.2.0-1.el7.x86_64.rpm-bundle.tar -C Downloads/mysql # 将 mysql 的 rpm 包解压到 mysql 目录中
到这,我们解压的部分就已经完成了,下面我们会进行一些安装配置,当然如果出现问题的话,大家也可以私信我私信老师或者上网搜索,能解决问题的都是好办法各位说对吧。
二、配置环境变量
这部分会先配置一定的环境变量,当然是用户级的,也就是当前用户才生效,这部分不会涉及配置文件的修改,所以大家要是已经做好了这一部分,可以直接跳过然后进入下一部分。
配置环境变量一共有两个文件,在 CentOS 里面是 .bashrc 和 .bash_profile,当然不同的系统会有不同的名称,但是大差不差,各位有兴趣可以自行了解。下面是使用 vim 编辑器编辑 .bash_profile 的指令,这里我在路径最前面使用了 ~/ 这是为了保证是打开用户目录下的 .bash_profile 文件,因为如果在其他目录下直接查找应该是没有该文件的。
vim ~/.bash_profile # 使用 vim 打开 用户目录下的 .bash_profile 文件
打开它是为了修改里面的内容,添加环境变量,下面我们正式开始配置。
1. JAVA_HOME
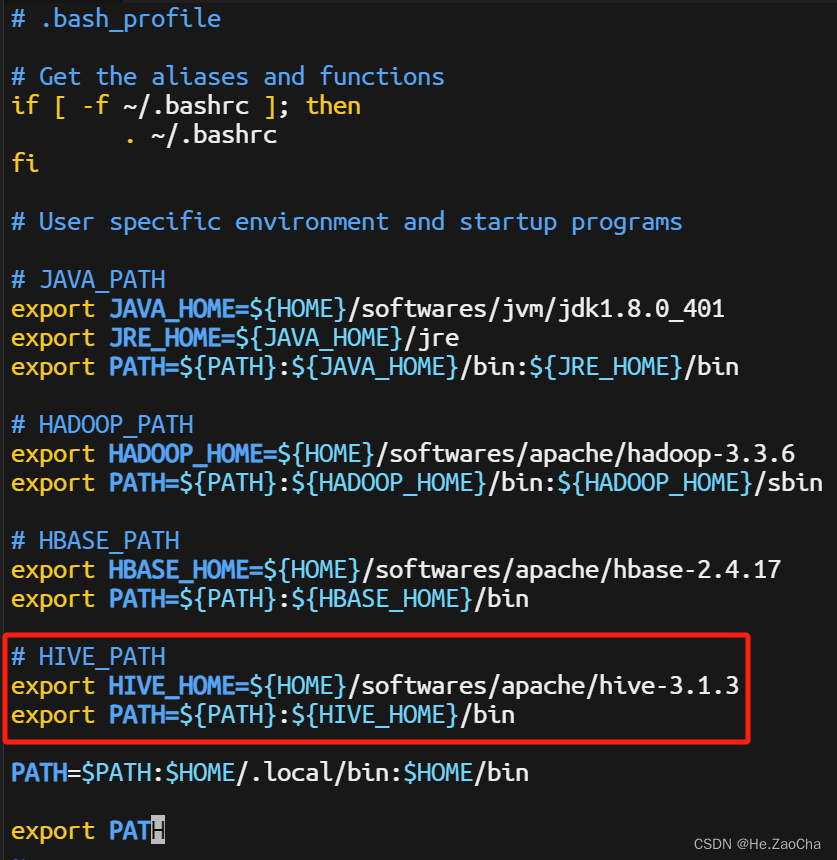
配置 jdk 的环境变量,众所周知,如果你要运行该程序,就需要找得到该程序的执行文件,才能运行,那么问题来了,计算机如何寻找到执行文件呢,这就需要环境变量来帮忙了,当然,能找到执行文件的环境变量只有一个,就是 PATH,所以请不要胡乱配置,这个毕竟还是有点说法的,首先,我们需要使用 vim 等编辑工具打开当前用户目录下的 .bash_profile 文件,然后在里面添加环境变量,不用太明白,看下面就好,有兴趣自己了解学习。注意各位的 JAVA_HOME 路径,这个大概率跟我是不一样的,所以请大家先确认自己的路径再配置,这里的 ${HOME} 是指代当前用户目录,所以如果大家跟我的步骤一样的话,这里也是可以直接复制黏贴的,哪怕我们的用户名不一样。
# JAVA_PATH
export JAVA_HOME=${HOME}/softwares/jvm/jdk1.8.0_401 # 设置 JAVA_HOME
export JRE_HOME=${JAVA_HOME}/jre # 设置 JRE_HOME
export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/bin # 添加进 PATH 变量

然后文件就会如上图所示的样子,前面有带 # 的都是注释哈,各位可以酌情添加,主要目的就是为了看懂
2. HADOOP_HOME
Hadoop 的环境变量也类似,不一样的是,它的目录下面会有两个执行文件目录,bin 和 sbin,如下图所示
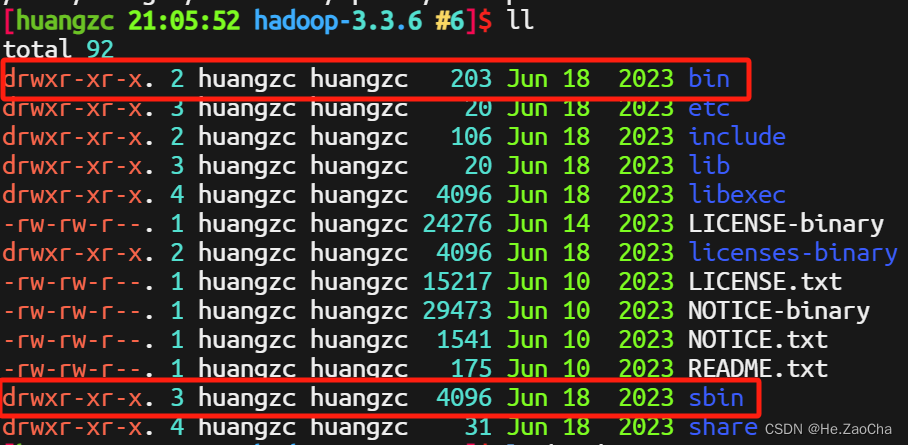
所以我们添加 PATH 的时候需要添加两个路径进去,问题不大,照着下面抄作业就好
# HADOOP_PATH
export HADOOP_HOME=${HOME}/softwares/apache/hadoop-3.3.6 # 设置 HADOOP_HOME
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin # 添加 PATH 变量

3. HBASE_HOME
HBase 的目录结构如下,该目录下只有一个执行目录 bin,所以写环境变量的时候只用添加一个即可
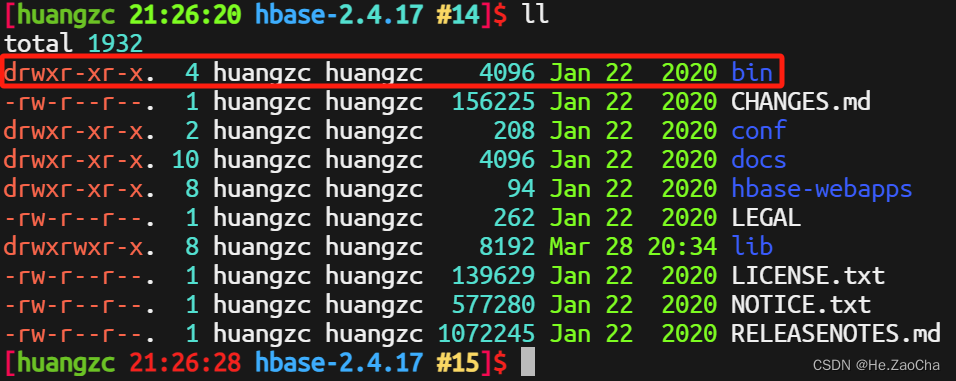
接下来就是抄作业时间
# HBASE_PATH
export HBASE_HOME=${HOME}/softwares/apache/hbase-2.4.17 # 配置 HBASE_HOME
export PATH=${PATH}:${HBASE_HOME}/bin # 添加 PATH 变量

4. HIVE_HOME
Hive 目录的名称我们需要稍作修改,因为解压出来后名称为 apache-hive-3.1.3-bin,为了方便我们后续的操作,所以我们需要将其改变一下,变成 hive-3.1.3;这里稍微说一下,因为我保留了版本号,也就是 3.1.3 一般来说是不会保留版本号的,因为这样会更方便一些,不保留版本号,但是我这里保留了,是有一个习惯问题,如果大家需要深入学习的话,一定要清楚保留版本号是有弊端的,在升级的时候会造成一些麻烦,虽然升级本来就很麻烦了,如果大家只是学习,可以保留,因为大家不会随便变更版本,但是在生产环境中,会面临版本变更的问题,虽然很久才会有那么小小的一次,但是变更版本的时候目录中的版本号就会造成一些错误。
然后就是抄作业的时刻
mv ~/softwares/apache/apache-hive-3.1.3-bin/ ~/softwares/apache/hive-3.1.3 # 这里可以理解为目录重命名,但其实是一个移动命令,将其移动到某个路径下的某个目录下,当然目录不存在的时候就变成了重命名

理论上这一步是不会报错的,大家可以自行查看一下如果出问题的话。然后是修改环境变量,可以先看一下 hive 安装目录下的内容,只有一个 bin 的执行目录,所以下面配置的 PATH 就只用加上这个就好
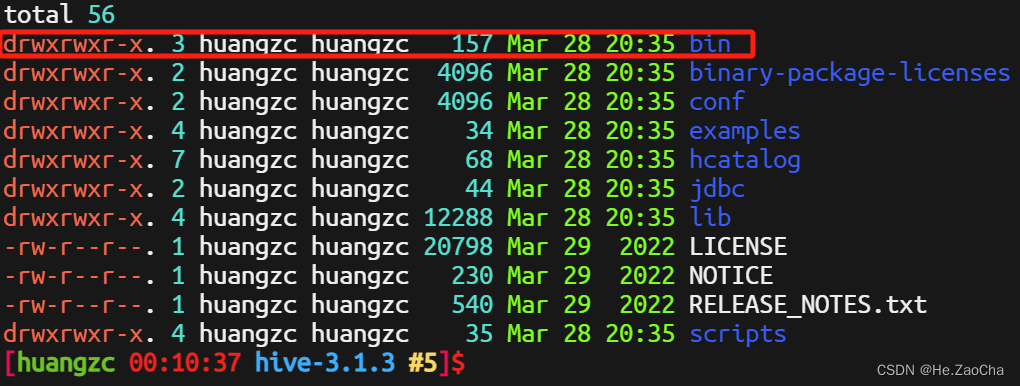
然后还是打开 .bash_profile,添加环境变量,经典抄作业时刻
# HIVE_PATH
export HIVE_HOME=${HOME}/softwares/apache/hive-3.1.3 # 配置 HIVE_HOME
export PATH=${PATH}:${HIVE_HOME}/bin # 添加 PATH 环境变量
5. 加载环境变量
到这里应该是配置完毕了,然后我们还需要让环境变量生效,并不是你一修改完成就可以了,他还没重新加载,那么新修改便不会生效。保存退出编辑后,输入下面命令重新加载环境变量。如果你修改的是另外一个环境变量文件,那么请你将下面代码的文件名修改一下
source ~/.bash_profile # 重新加载 .bash_profile

6. 卸载原有 jdk
在做完上述配置之后,我们还有一个问题,因为装载中带有自带的 openjdk,所以导致我们安装的 jdk1.8.0_401 无法直接生效,如下图。

所以我们需要将其进行卸载,当然它是 rpm 包,所以需要用到 rpm 的指令
rpm -qa | grep jdk # 查找现已有的带有 jdk 字样的包
rpm -qa |grep java # 查找现已有的带有 java 字样的包
rpm -qa |grep gcj # 查找现已有的带有 gcj 字样的包
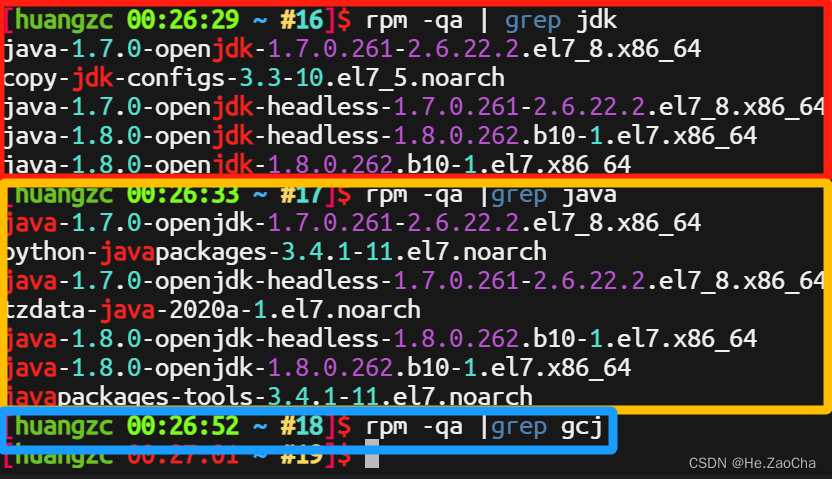
根据上面结果可以看出来,有预先安装两版的 openjdk,我们需要对其进行删除,下面我们将分别以 jdk、java,进行卸载删除。这里我们用到了 sudo,因为卸载和安装 rpm 包都是需要有 root 权限的,所以我们在最后一个管道符,也就是删除操作真正生效的地方加上了 sudo
rpm -qa | grep java |sudo xargs rpm -e --nodeps # 卸载带有 java 字样的软件
rpm -qa | grep jdk |sudo xargs rpm -e --nodeps # 卸载带有 jdk 字样的软件

再次检查,已经不存在这样子的包了。
rpm -qa | grep jdk # 查找现已有的带有 jdk 字样的包
rpm -qa |grep java # 查找现已有的带有 java 字样的包

然后再查看一下 java 是否正常能使用了
java -version # 查看 java 版本

显示正常,说明我们的操作很成功。
7. 总结
其实搞了这么久,在我的感觉上还是没有很顺利,主要是我习惯使用最小化安装了,突然的这界面问题,然后一些奇奇怪怪的包存在,搞得有点麻烦,说明大家上课确实没那么容易哈,但还是希望大家好好学。本来想给大家更深入一些的,比如环境变量中如何做到判断该目录是否存在,是否需要添加到 PATH 变量中等 Shell 编程的内容,但是后面写着写着发现有点麻烦,不是不能写,只是觉得大家可能没那么感兴趣;想了想,还是不要搞那么多无用功,只希望大家能更轻松地完成这个课程即可。如果后续有时间的话,我会在后面再写一份拓展,也是希望能帮助到大家。
三、安装部署
这一部分我们正式进行安装部署,这部分需要大家做的东西比较多,但是不会强求大家一定要会,所以我会直接把配置文件给出来,大家只需要抄好作业即可,不需要做太多的操作,毕竟单机还是很好解决问题的。
1. MySQL
第一部分说到,我们解压了安装包,但是我们并没有真正安装到它,因为它解压出来时很多的 rpm 包,所以安装的方式也比较另类,解压文件如下图
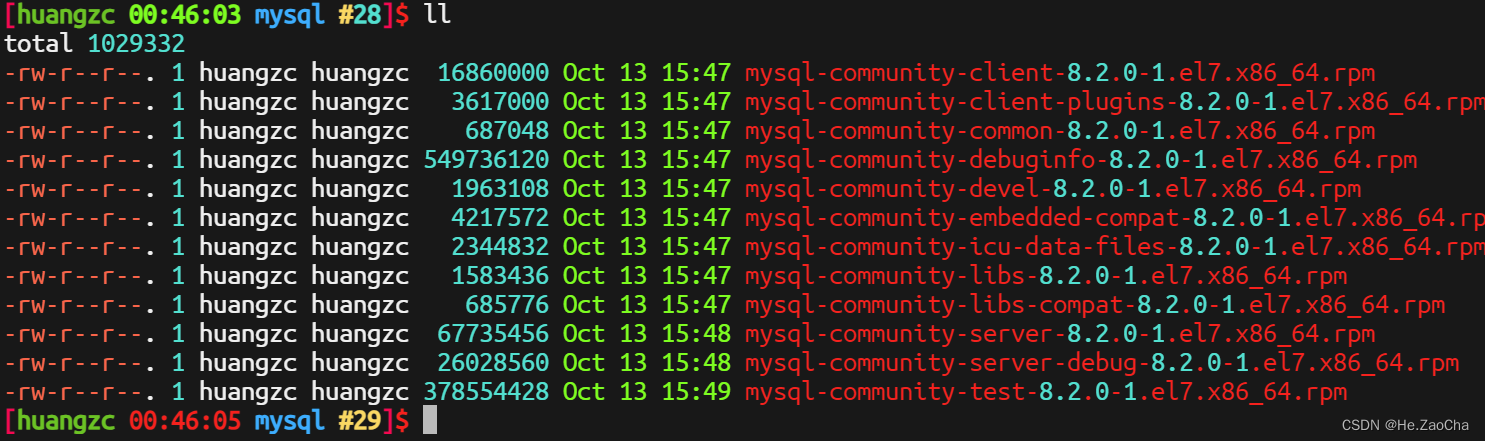
这么多的包,这里不会进行挑选,这里直接全部一股脑全装了,如果有兴趣学习的话,大家可以自行装配,这里就不多做麻烦的事情了。这里还是稍微介绍一下 rpm 批量安装的方法,如下所示
这命令也不是哪都能用,请大家先使用 cd 进入 MySQL 的 rpm 包的解压目录中,然后再输入下面的指令
sudo rpm -Uvh *.rpm --nodeps --force # 批量安装该目录下的 rpm 包
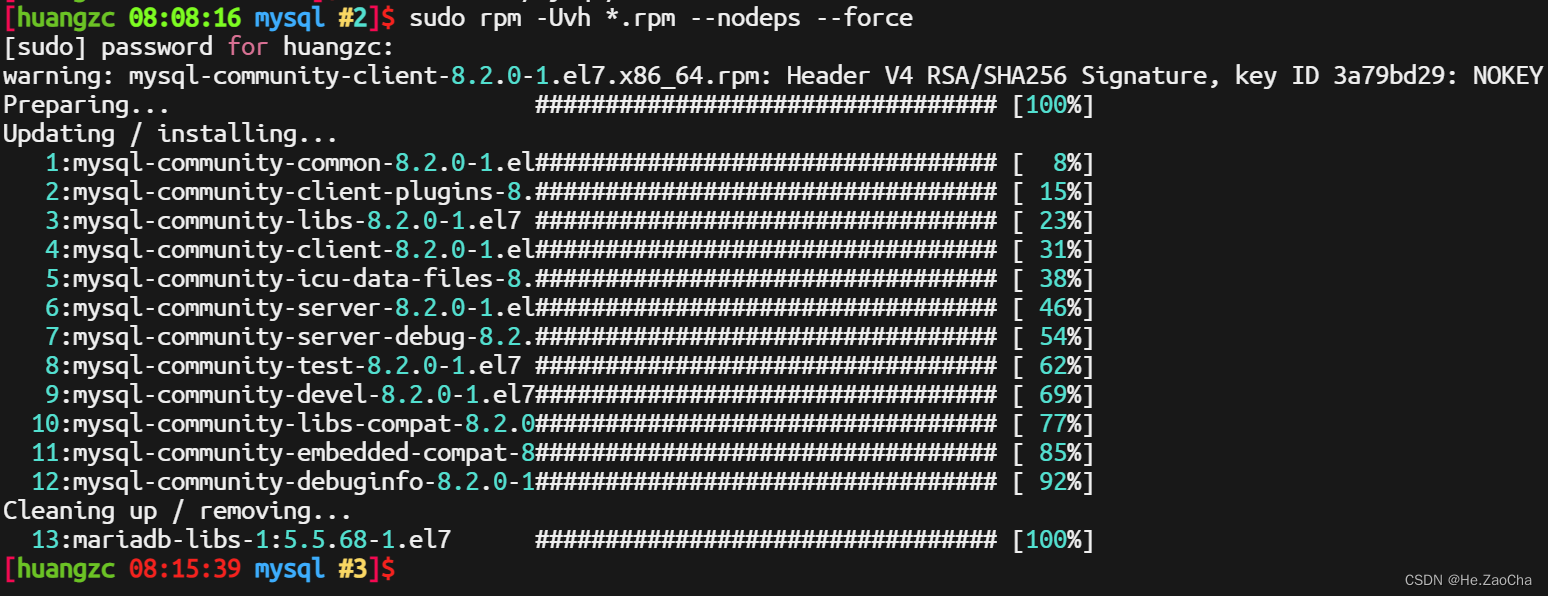
这里我们便安装成功了,但是这不意味着我们就可以使用了,因为在这个普通用户中,没有 MySQL 的账户以及权限,所以是登录不进 MySQL 中的,下面我们还需要开启服务、进行用户的添加以及赋予权限等配置。
-
首先,我们需要查看
MySQL服务是否已启动,若未启动,则需要进行启动,也可以配置自启动,看大家需求即可,一般会像下图所示,进程停止,但是已经有开机自启动,此时大家可以选择重启虚拟机,或者使用命令开启systemctl status mysqld.service # 查看 MySQL 进程运行情况
输入下面命令开启服务,注意,一般进程都是需要
root的权限进行开启的,所以要加上sudosudo systemctl start mysqld.service # 开启 MySQL 进程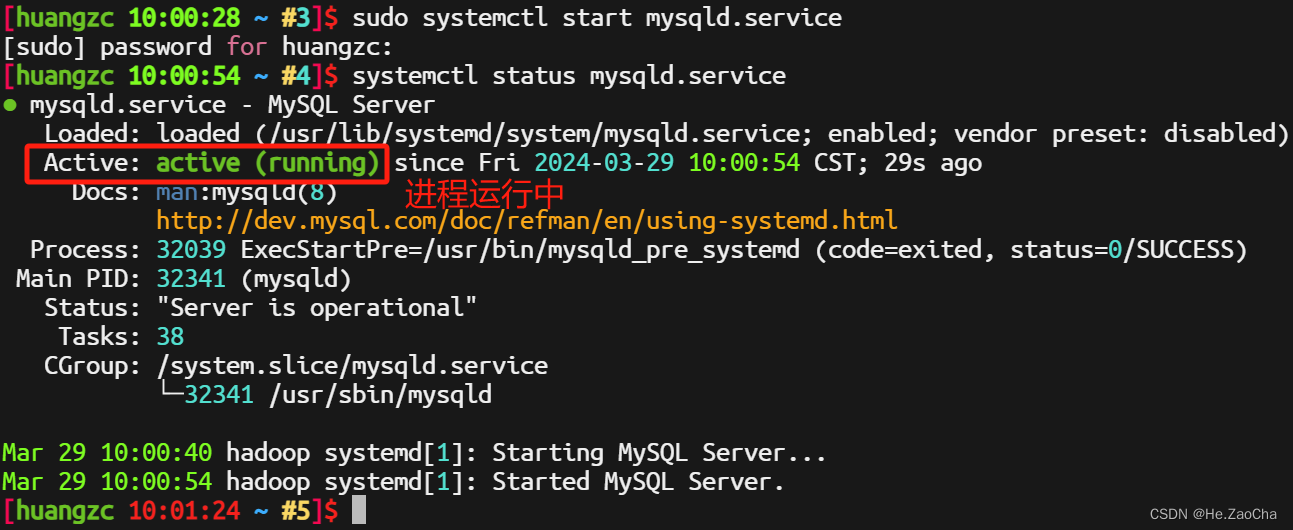
下面再给大家写几条指令,用于开机自启动服务,关闭服务等
sudo systemctl enable ${服务名称} # 使某进程开机自启动 sudo systemctl disable ${服务名称} # 禁止某服务开机自启动 sudo systemctl restart ${服务名称} # 重启某一服务 sudo systemctl stop ${服务名称} # 停止某一服务 -
启动
MySQL后,我们还需要添加一个MySQL用户并赋予权限,毕竟不能什么都使用root操作是吧;但是,这样子安装的MySQL是会有一个临时密码的,所以我们还需要查看临时密码,使用root用户登录MySQL,临时密码存储在/var/log/mysqld.log文件中,但是查看该文件需要root权限,所以这里我也添加了sudo,用了这么久,大家应该不会知道sudo对运维来说多么重要吧;后面的grep用于筛选我们需要的信息。sudo cat /var/log/mysqld.log | grep root@ # 查看 mysqld.log 日志并且筛选关键字 root@
-
现在
MySQL中我们可以使用的用户只有root,所以我们需要使用root账户登录后新建一个与我们虚拟机中用户名同名的用户,当然要是你想不同名也可以,但是因为Mysql登录默认是使用同名登录,也就是登录虚拟机的用户的名称进行登录的,所以如果设置了不同名,则需要加上-u ${用户名}指定用户名进行登录,下面指令中还有一个-p选项,这个是使用验证账户密码的方式登录需要加上的选项,从这里就可以看出来,MySQL也是可以实现免密登录的,大家有兴趣也可以自行了解,这里不多做赘述。这里还得说个事儿,-p后面是可以直接写密码的,但是这样有一些不好,比如不太安全,也比如临时密码这个时候无法这样进行登录,所以大家还是老老实实,-p之后回车输入密码,登录成功示意图如下所示。mysql -u root -p # 使用 root 账户登录,并且登录方式为验证账户密码
-
然后进入之后需要修改
root的登录密码,这个就是简单的SQL语句了,大家照葫芦画瓢即可;root大家应该都一样,后面的localhost不建议修改,毕竟如果在任何一台电脑都能使用root用户连接上服务器的MySQL是一件很恐怖的事情,所以我们设置只有本地登录才能使用root连接上MySQL;后面一长串就是密码,大家喜欢什么设置什么就好,当然会有密码强度的提示,默认是高强度密码,我没记错的话至少需要大写字母+小写字母+数字+不少于6位,不记得是6位还是8位了,报错了大家就换个密码就好,也不记得要不要加特殊字符了,理论上应该不用吧…反正我加了,也没影响。执行结果如下图ALTER USER 'root'@'localhost' IDENTIFIED BY 'Hzc.12246577030.0'; # 重新设置 root 的登录密码 FLUSH PRIVILEGES; # 刷新权限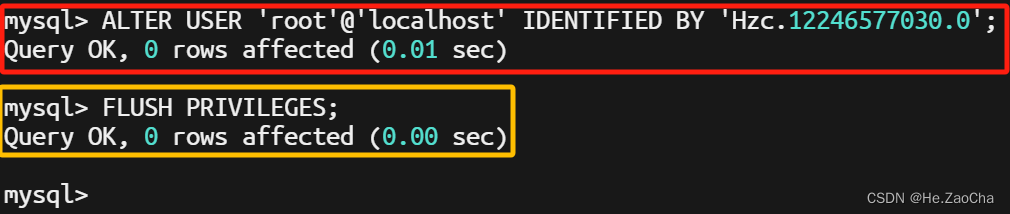
-
然后我们需要新建一个用户,并且为其赋予权限,权限这里就全部都给就好,反正也不会怎么样,学习的时候就要大胆一点,多犯错是对的,最后还需要再次刷新权限以写入修改,然后就可以输入
exit退出MySQL了。CREATE USER 'huangzc'@'%' IDENTIFIED BY 'Hzc.1230.0'; # 新建一个用户名称为 huangzc 的用户并且允许其在任意主机上连接到 MySQL,密码设置为 Hzc.1230.0 GRANT ALL PRIVILEGES ON *.* TO 'huangzc'@'%' WITH GRANT OPTION; # 授予 huangzc 用户所有的权限并且使其可以赋予权限到其他用户 FLUSH PRIVILEGES; # 刷新权限
-
最后我们再使用密码登录尝试一下,如果能登录进去就说明我们成功了,如下图所示就是成功。
mysql -pHzc.1230.0 # 账户密码进行登录,账户没写就默认是当前登录的用户的名称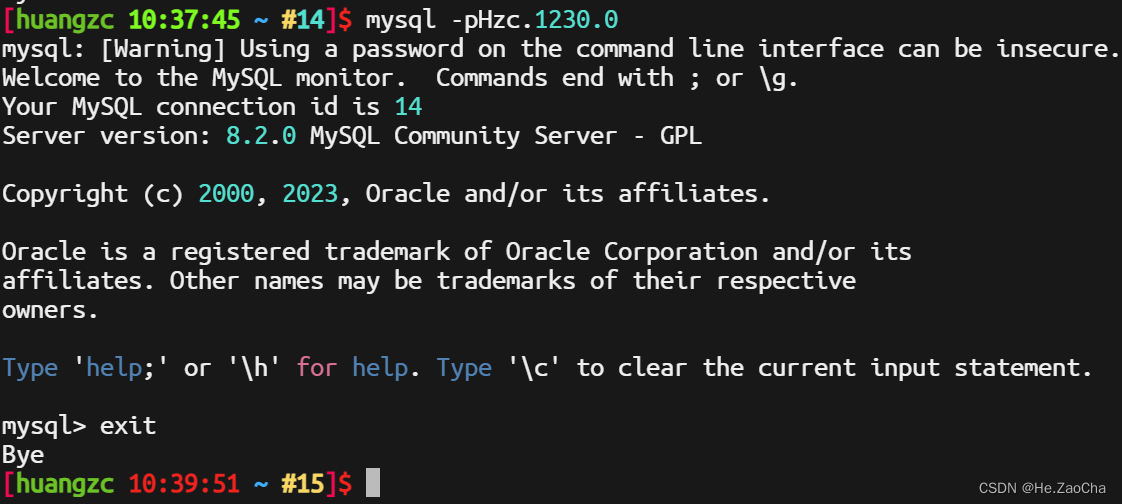
-
关于其他连接的问题,其实很好解决,这里稍微拓展一下,我用
Navicat给大家展示一下连接,大家应该就能懂意思了,当然这是远程操作的内容,用jetbrains的数据库工具也是可以的,大差不差,大家没兴趣可以直接跳过。打开Navicat后,选择连接 --> MySQL,进入链接配置界面
-
然后我们需要
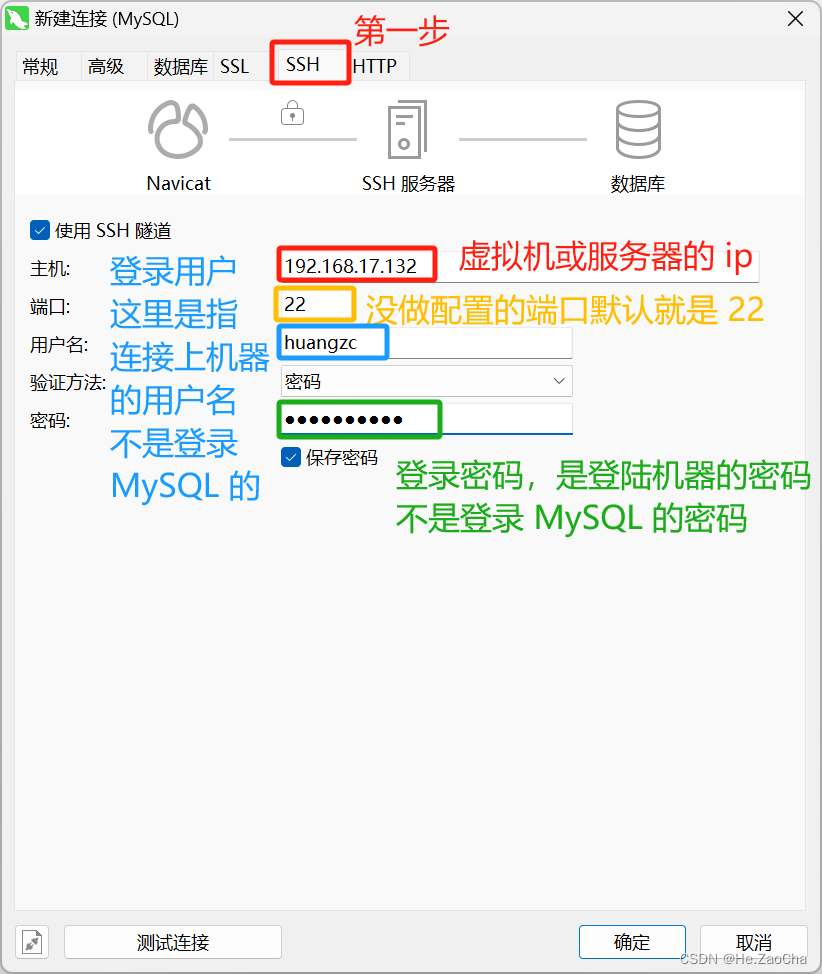
-
然后我们还需要在左上角
常规处再次进行设置用户名和密码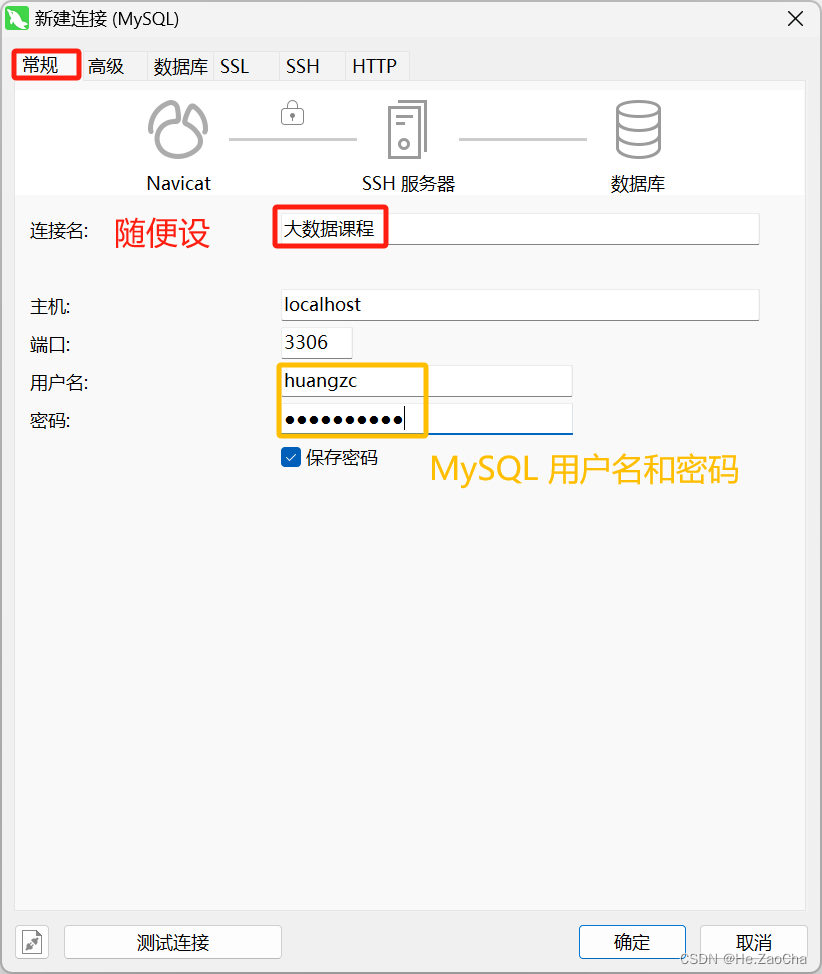
-
设置完后我们可以点击左下角测试连接进行测试使用,如果测试成功即可按确定,完成连接配置。
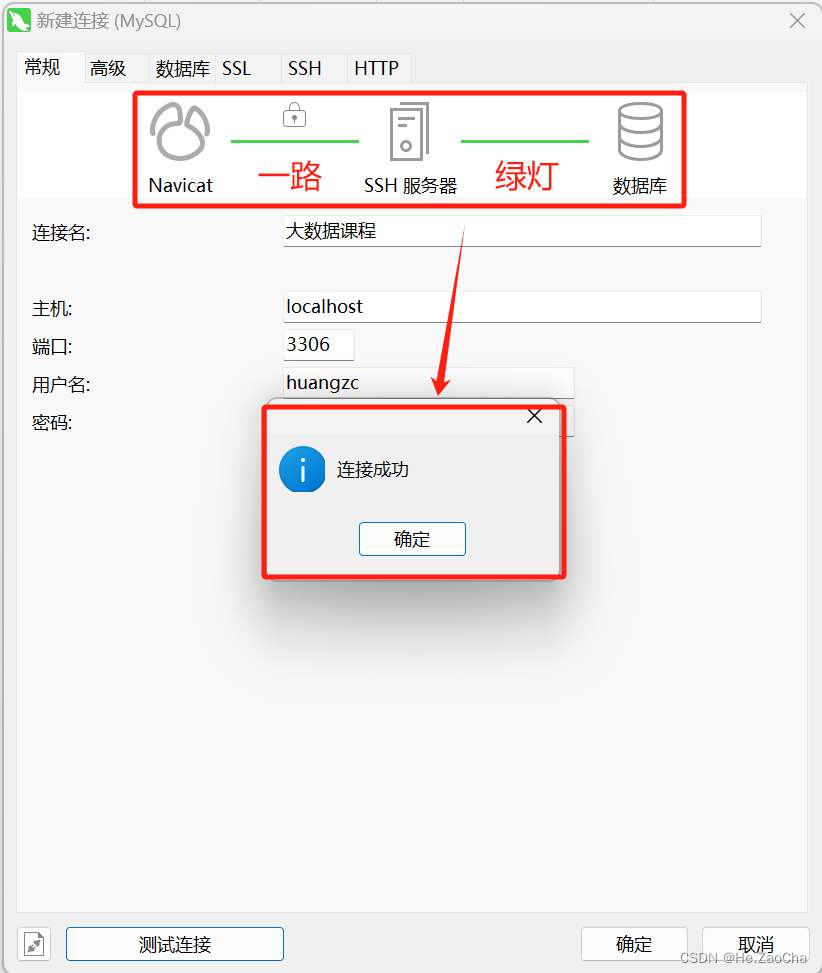
-
然后在左边栏中会出现一个名称是上面输入的连接名,然后灰色图标的
MySQL标志的连接,双击即可连接,连接成功图表会亮起来,如下图所示
当然大家如果有兴趣还可以尝试一下 root 是否可以登录,这里会有两种情况,直接连接到数据库和先链接服务器再通过服务器数据库两种;通过 SSH 连接到服务器再连接到数据库是可以正常连接的,但是直接连接到数据库是不可以的,因为之前我们设置过 root 只能在 localhost 进行登录。
2. Hadoop
下面我们会进行 Hadoop 的配置文件修改,初始化,还有单机启动,当然,如果各位对伪分布和全分布感兴趣的话,也可以参考CentOS-7 Hadoop集群部署-CSDN博客该文章,厦门大学大数据实验室的文章也可以,不过好像没有 CentOS 的,大家自行选择。
Hadoop 的配置文件都存放于 ${HADOOP_HOME}/etc/hadoop/ 目录下,其中,我们需要配置的文件一般来说有 6 个,分别是 hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers,这些配置文件产生的效果各不相同,如果只是需要存储功能,那么只需要 hadoop-env.sh、core-site.xml、hdfs-site.xml 即可,如果需要使用 MapReduce 进行计算,则需要配置 mapred-site.xml、yarn-site.xml。最后还有一个 workers 文件适用于集群,所以单机的话咱就不做配置了。

下面我们先进入到 ${HADOOP_HOME}/etc/hadoop/ 目录下,这样方便我们不用写那么多路径。
cd ${HADOOP_HOME}/etc/hadoop/ # 进入 hadoop 配置目录
(1) hadoop.env.sh
首先我们设置 core-site.xml,使用 vim 编辑器,打开 hadoop.env.sh 文件,然后复制下面配置内容,黏贴到最上面即可,如下图所示;然后是第一条环境变量 HOME 变量需要是自己的用户名,大家请记得修改,如果大家俺咋混个位置与我并不一样,那么请大家,按照自己路径为主。
export HOME=/home/huangzc
export JAVA_HOME=${HOME}/softwares/jvm/jdk1.8.0_401
export HADOOP_HOME=${HOME}/softwares/apache/hadoop-3.3.6
export HBASE_HOME=${HOME}/softwares/apache/hbase-2.4.17
export HIVE_HOME=${HOME}/softwares/apache/hive-3.1.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_DATA_DIR=${HOME}/data/apache/hadoop
export HADOOP_LOG_DIR=${HADOOP_DATA_DIR}/logs
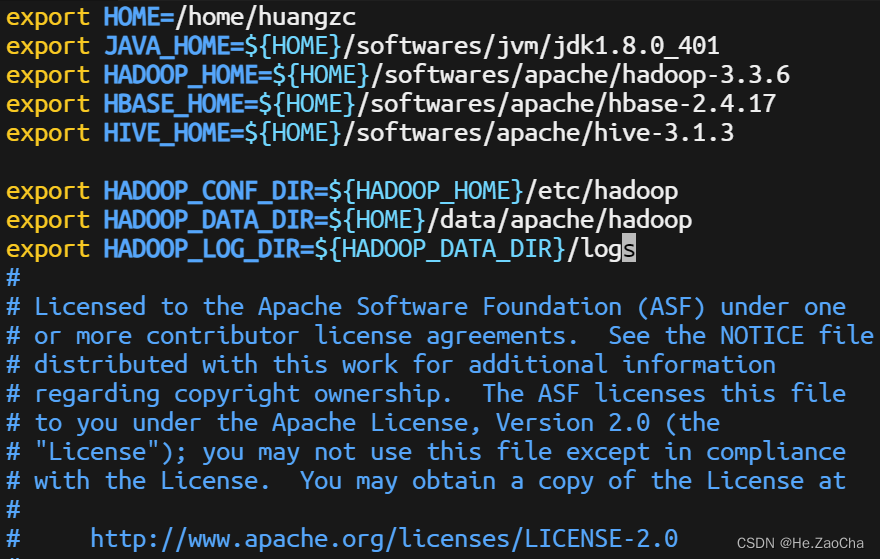
这里里面有一个 HADOOP_DATA_DIR,这个是需要大家自行创建的,需要在命令行中输入 mkdir 进行创建,虽然好像不创建应该也可以,因为它好像会被动创建,但是为了防止大家可能的报错,大家还是自己创建一下
mkdir -p ${HOME}/data/apache/hadoop # 存放 hdfs 数据的目录

这个 ${HOME} 在本身环境变量已经有了,所以在哪个目录都不会创建失败的,-p 是递归创建的意思,需要加上。
(2) core-site.xml
首先我们设置 core-site.xml,使用 vim 编辑器,打开 core-site.xml 文件,然后复制下面配置内容,黏贴到 <configuration> </configuration> 标签里面即可
vim core-site.xml # 使用 vim 打开 core-site.xml
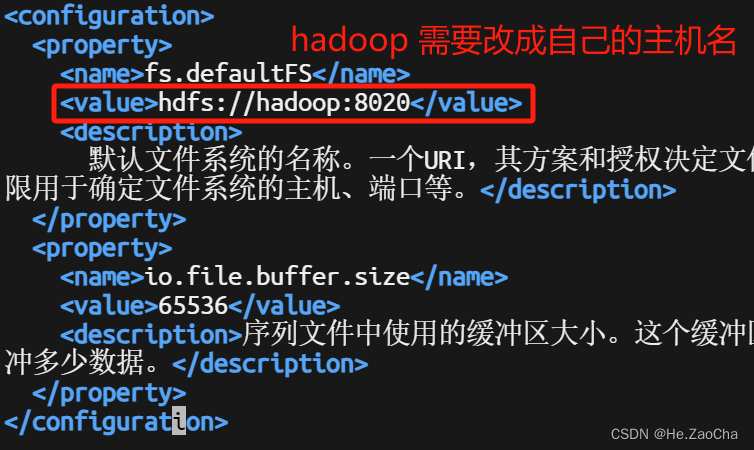
配置内容如下,注意不要把 <configuration> </configuration> 标签也复制进去了,还有就是这里的 hadoop 需要改成自己的主机名称,buffer.size,大家可以根据自己电脑的配置进行修改,没有强制要求。修改完后 :wq 保存退出即可。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
<description>
默认文件系统的名称。一个URI,其方案和授权决定文件系统实现。URI的方案确定命名FileSystem实现类的配置属性(fs.SCHEME.impl)。uri的权限用于确定文件系统的主机、端口等。</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
<description>序列文件中使用的缓冲区大小。这个缓冲区的大小应该是硬件页面大小的倍数(在Intel x86上为4096),它决定了在读写操作期间缓冲多少数据。</description>
</property>
</configuration>
(3) hdfs-site.xml
打开 hdfs-site.xml,输入下面配置即可,注意不要将 <configuration> </configuration> 也复制进去了,这里有两个需要修改的地方 dfs.namenode.name.dir 和 dfs.datanode.data.dir,里面的值必须是绝对路径,并且需要修改成大家自己设置的路径,当然前缀可以不加,这个不会特别影响,当然加上肯定是更好的。
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
<description>查找DFS数据节点存储其块的本地文件系统上的目录。权限可以是八进制的,也可以是符号的。</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/huangzc/data/apache/hadoop/dfs/name</value>
<description>确定DFS名称节点应在本地文件系统上的何处存储名称表(fsimage)。如果这是一个以逗号分隔的目录列表,则名称表将复制到所有目录中,以实现冗余。</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>256m</value>
<description>新文件的默认块大小,以字节为单位。您可以使用以下后缀(不区分大小写):k(kilo),m(mega),g(giga),t(tera),p(peta),e(exa)来指定大小(如128k,512m,1g等),或者以字节为单位提供完整的大小(例如134217728表示128
MB)。</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>25</value>
<description>侦听来自客户端的请求的Namenode RPC服务器线程数。如果未配置dfs.namenode.servicerpc-address,则Namenode
RPC服务器线程将侦听来自所有节点的请求。</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/huangzc/data/apache/hadoop/dfs/data</value>
<description>
确定DFS数据节点应将其块存储在本地文件系统上的何处。如果这是一个逗号分隔的目录列表,那么数据将存储在所有命名的目录中,通常在不同的设备上。对于HDFS存储策略,应使用相应的存储类型([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK])标记目录。如果目录没有明确标记的存储类型,则默认存储类型为DISK。如果本地文件系统权限允许,将创建不存在的目录。</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.namenode.https-address</name>
<value>0.0.0.0:9871</value>
</property>
<property>
<name>dfs.datanode.http-address</name>
<value>0.0.0.0:9864</value>
</property>
<property>
<name>dfs.datanode.https-address</name>
<value>0.0.0.0:9865</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>0.0.0.0:9868</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>0.0.0.0:9869</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>5120</value>
<description>指定用于将数据传入和传出DN的最大线程数.</description>
</property>
</configuration>
完成配置后我们就可以尝试进行启动 HDFS 了,启动之前还需要对 NameNode 也就是名称节点进行初始化,这个是在我们上面 core-site.xml 就已经配置完毕的了,所以计算机会知道哪个是名称节点;指令如下
hdfs namenode -format # 初始化名称节点
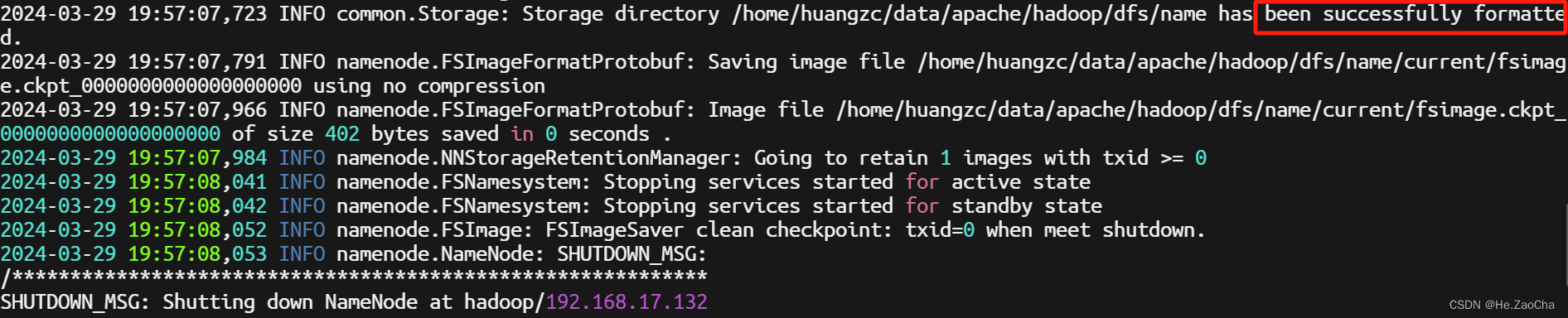
一般出现如图上 示意那样就是正确的,但是注意如果有像 java 抛出异常的话说明还是没有成功,可能只是看起来没事情而已。
然后我们需要启动 HDFS 来验证我们的配置是否没有出现问题,这里 Hadoop 已经有写好的脚本,名为 start-dfs.sh,然后我们可以使用 jps 命令来查看他们是否启动了,因为 Hadoop 的底层其实也是建立在 jdk 的基础上,也就是使用 java 编译运行的,所以可以使用 jps 指令查看使用了 jdk 的进程,如下所示
start-dfs.sh # 开启 HDFS 集群
jps # 查看正在使用 jdk 的进程

上图有一个警告 Warning 是正常的,因为我做完免密登录之后没有使用 ssh localhost 连接自己,这个不影响的,它会自己把自己添加进去,就是说它会自己解决这个问题;然后如果能看到下图这三个节点,那么就说明我们的配置没有问题,当然,如果过了 10s 就少了哪一个的话,就说明配置还是有问题,也就是我们所说的节点挂掉了,此时请返回检查你的配置文件,如果没有发现问题,可以联系老师,联系我,联系…能解决问题的地方。
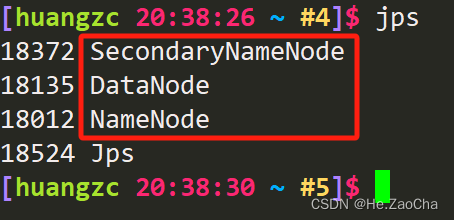
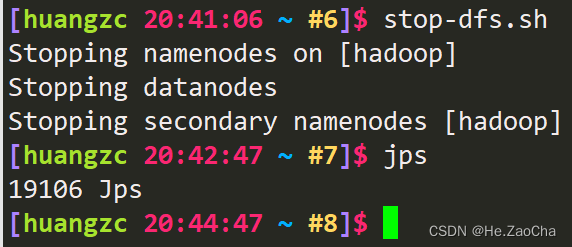
最后再讲一下关闭,关闭比较简单,就也是脚本,只要吧上面的 start 改成 stop 即可,关闭后使用 jps 再次查看,如下图所示三个节点都已经成功关闭了。
stop-dfs.sh # 关闭 HDFS 集群
jps # 查看正在使用 jdk 的进程
(4) mapred-site.xml
改配置文件是为了配置能够使用 MapReduce 进行计算所以才需要配置,但是我们这个课程并不涉及需要自定义该文件,所以我们可以选择不配置;这里我设置了几个选项,为的是能在浏览器上实时监控;当然默认也是这几个配置项,但是为了保证他启动一定会有,我还是写上去了
<configuration>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.https.address</name>
<value>0.0.0.0:19890</value>
<description>The https address the MapReduce JobHistory Server WebApp is on. </description>
</property>
</configuration>

(5) yarn-site.xml
最后是关于 yarn,这个是管理集群资源调度的一个配置文件,这个因为我们使用的是单机,所以我觉得也不需要配置,我反正没有配置,这里了解一下就行,要是大家头铁,可以自行寻找有配置的材料进行配置。
(6) workers
这个文件是管理集群中的 DataNode 的,但是我们是单机,所以也不需要进行配置,所以这里制作了解,不做配置。
(7) 启动集群
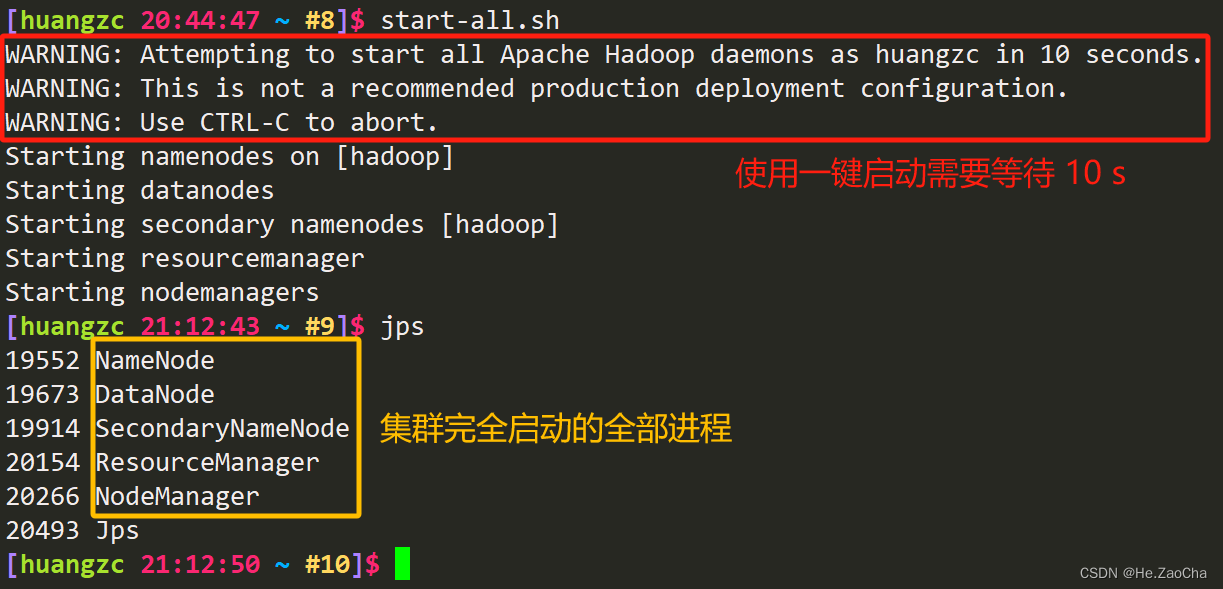
启动一共有很多个脚本,如果大家环境变量没有配置错误的话,那么应该是可以使用 start-all.sh 进行集群的一键启动的,当然,如果是只需要启动某一个节点也是可以的,这里我不写,大家有兴趣自行了解,毕竟我要是什么都写完了,那就变成是我在做这个东西了,这不太合适,下面是集群的启停指令。
start-all.sh # 启动 Hadoop 集群
jps # 查看集群进程
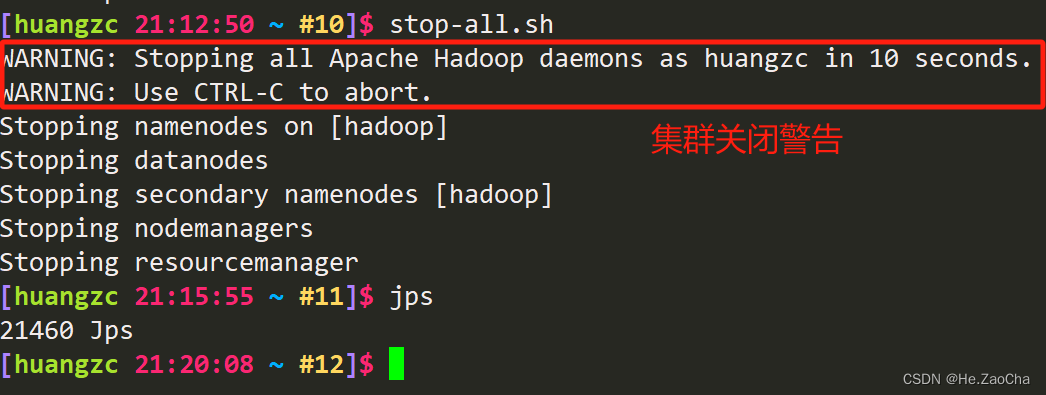
下面是停止整个 Hadoop 集群的命令
stop-all.sh # 关闭 Hadoop 集群
jps # 查看集群进程
到这里,关于 Hadoop 的部署就完成了,后续也会出一篇实践的内容(有空的话)
3. HBase
HBase 的配置文件存在于 ${HBASE_HOME}/conf,然后我们还是先进入目录然后查看一下目录中的配置文件
cd $HBASE_HOME/conf # 进入 HBase 配置文件目录
(1) hbase-env.sh
然后我们先配置 hbase-env.sh 文件,将下列配置项添加在文件的开头即可
vim ${HBASE_HOME}/conf/hbase-env.sh # 使用 vim 打开该文件
配置项中的 HOME 也需要改成对应的路径
export HOME=/home/huangzc
export JAVA_HOME=${HOME}/softwares/jvm/jdk1.8.0_401
export HADOOP_HOME=${HOME}/softwares/apache/hadoop-3.3.6
export HBASE_HOME=${HOME}/softwares/apache/hbase-2.4.17
export HIVE_HOME=${HOME}/softwares/apache/hive-3.1.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# The maximum amount of heap to use. Default is left to JVM default.
export HBASE_CLASSPATH=${HADOOP_CONF_DIR}
export HBASE_DATA_DIR=${HOME}/data/apache/hbase
export HBASE_LOG_DIR=${HOME}/data/apache/hbase/logs
export HBASE_PID_DIR=${HOME}/data/apache/hbase/pids
至于环境变量的含义我就不多说了,这个大家可以自行了解,当然版本这个大家也要记得改,不要只是复制黏贴。
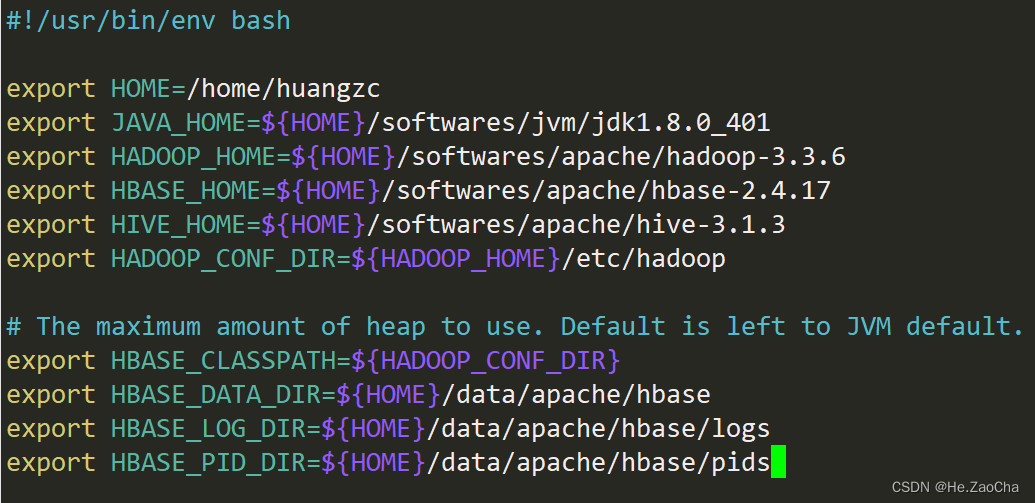
这里我们跳过了第一行然后再黏贴的,因为这个注释是文件标头,说明使用的 bash 是哪里的,这个我们让它留在第一行,当然,就算在后面应该也不会出问题的。
(2) hbase-site.xml
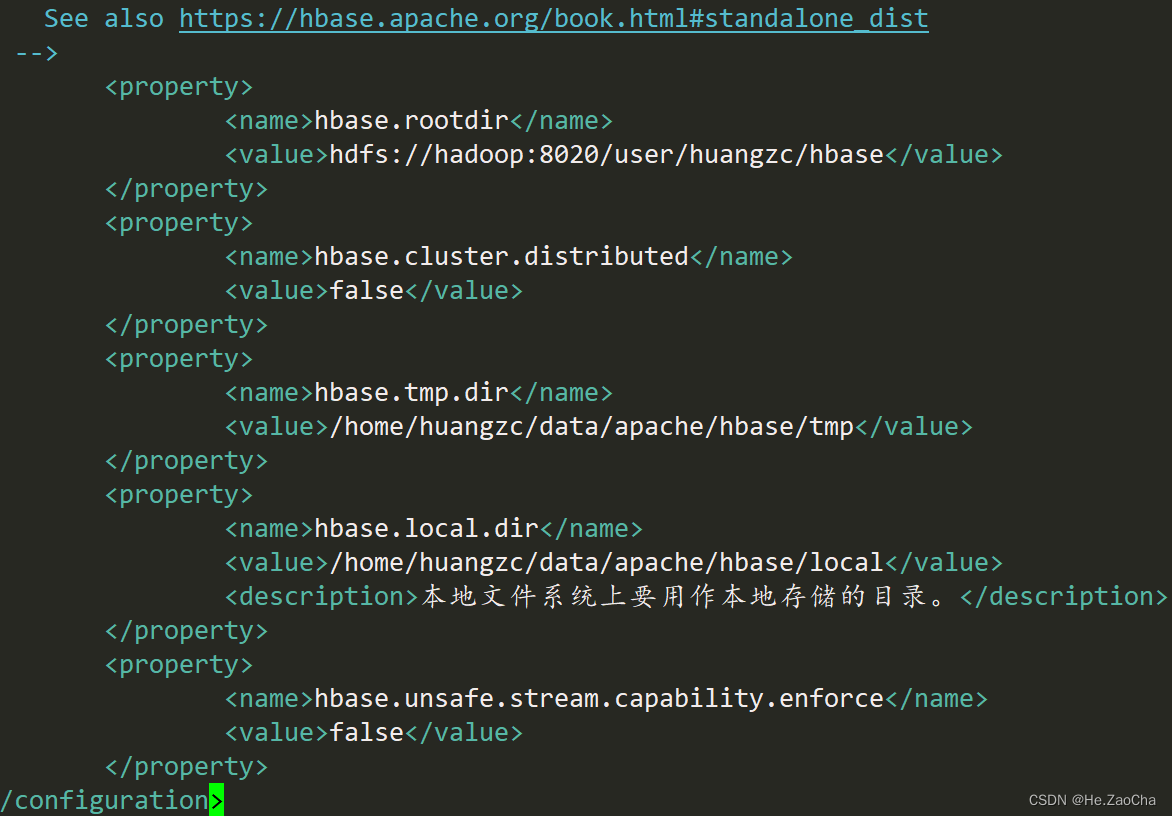
下面打开 hbase-site.xml 进行配置,下面要将配置项添加到文件中,因为中间有注释,我就只复制了需要配置的,大家不要直接复制黏贴,不然会报错。还有三个需要改的地方,大家看着改 hbase.rootdir 的值,hadoop 和 huangzc 要改成自己设置的 主机名称 和 用户名称;下面 hbase.tmp.dir 和 hbase.local.dir 也要改成将 /home/huangzc/ 改成自己的用户目录,或者自己也可以创建一个别的目录也是可以的。
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop:8020/user/huangzc/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/huangzc/data/apache/hbase/tmp</value>
</property>
<property>
<name>hbase.local.dir</name>
<value>/home/huangzc/data/apache/hbase/local</value>
<description>本地文件系统上要用作本地存储的目录。</description>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
然后配置完成我们就可以尝试开启 HBase 集群,但是需要先开启 Hadoop 集群,请记住一定要先开启 Hadoop 集群,所以启动命令的顺序一定要注意,如下
start-all.sh # 开启 Hadoop 集群
start-hbase.sh # 开启 HBase 集群
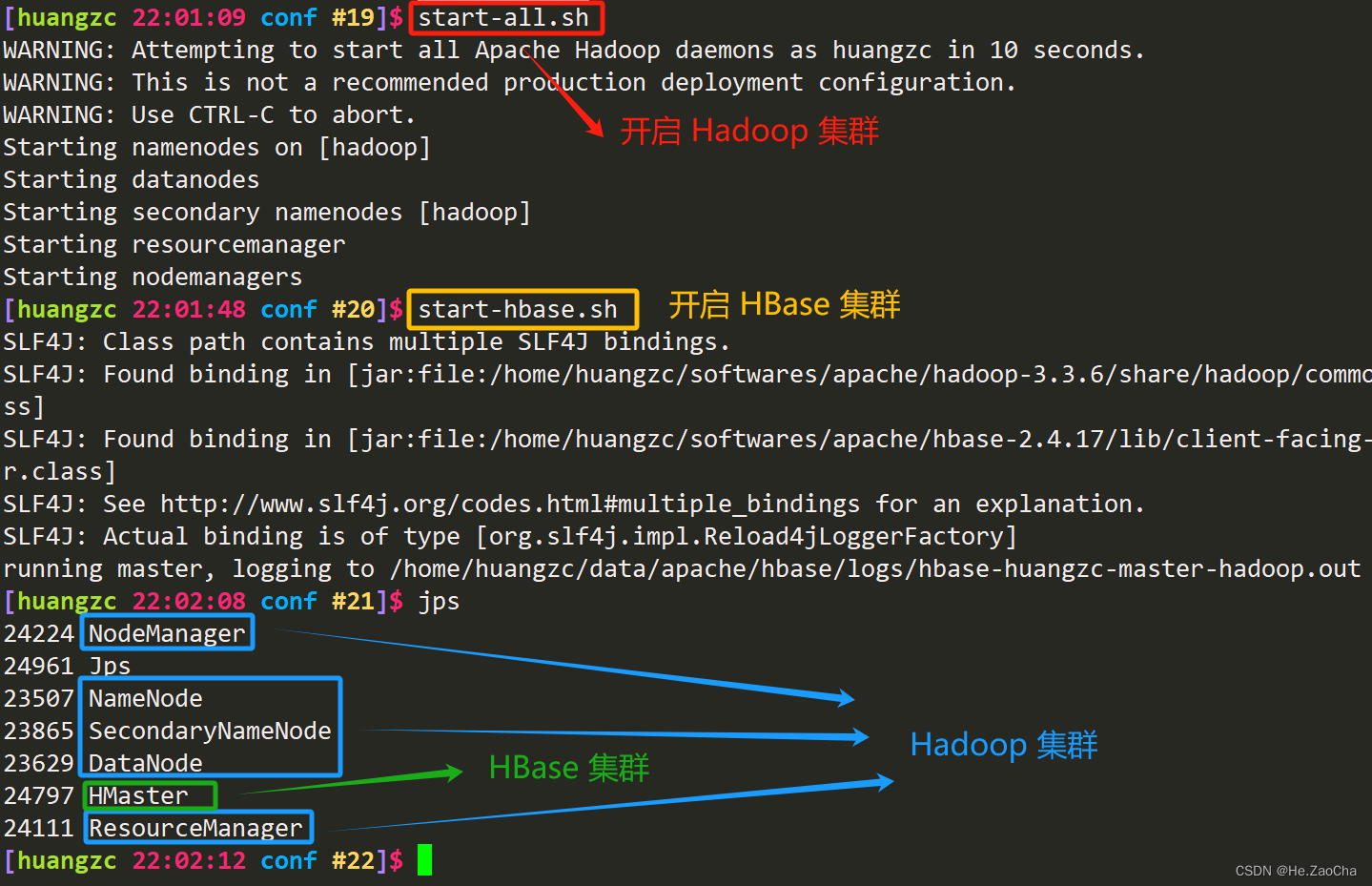
至此我们就可以使用 HBase 数据库了,当然,我们还是先和 MySQL 一样先使用命令行,因为 Navicat 好像没有支持 HBase,退出数据库的操作和 MySQL 一样,输入 exit 即可。
hbase shell # 开启 Hbase 命令行
当然,启动的时候可能会遇到下面这个小小的警告,报错如下
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/huangzc/softwares/apache/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/huangzc/softwares/apache/hbase-2.4.17/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory]

这个警告是因为有两个同样功能的 jar 包冲突了,我们可以选择封印版本低的包,封印就是重命名,让它变成 .bak,虽然存在,但是不能用。这里可以看到第三行,/home/huangzc/softwares/apache/hbase-2.4.17/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar 这个版本比第二行的 /home/huangzc/softwares/apache/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar 低,所以我们选择封印 HBase 的包;做该操作时,请确保 HBase 集群已关闭,指令如下
stop-hbase.sh # 关闭 HBase 集群
jps # 确认进程已经关闭
mv ${HBASE_HOME}/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar ${HBASE_HOME}/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak # 移动文件变成 .bak
然后我们再启动 HBase 集群,打开 HBase Shell,此时应该不会有包冲突了
start-hbase.sh # 启动 HBase 集群
hbase shell # 打开 HBase Shell
(3) HBase 启停
这是需要单独拿出来讲的一部分,关于 HBase 的启动和停止问题,它必须在 HDFS 集群启动之后才能启动,否则将会造成不可逆的后果,请重视它,如果实在出现了这种操作,那停止 HBase 集群的时候将会耗费大量的时间,也可能根本停止不了;这个时候需要使用单挂节点来解决这个问题,因为是单机配置,所以只有一个 HMaster 进程,所以我们只用停掉这一个就行,输入下面命令即可
hbase-daemon.sh stop master # 单独关闭 HMaster
下面是因为我已经成功关闭了 HMaster 了,所以他说没有 Master 进程。

4. Hive
最后是 Hive 的配置,Hive 也需要先开启 HDFS 集群,但是不需要 HBase,之前我们已经说过了我们会是建立在 MySQL 上面的,所以我们可以单启动 Hadoop 而不需要启动 HBase。但是请注意,我们需要确保 MySQL 是启动的。
Hive 的配置文件存放于 ${HIVE_HOME}/conf,目录结构如下
这里我们需要创建两个文件,一个是 hive-env.sh 和 hive-site.xml,这两个文件在该目录中是有模板的,也就是后缀带 template 的文件,但是,为了大家不会出问题,还是直接跟着我来好了,复制配置文件可能会出各种各样的问题。
(1) hive-env.sh
-
首先,我们需要使用
vim新建该文件,具体命令如下vim ${HIVE_HOME}/conf/hive-env.sh # 使用 vim 打开编辑,若文件不存在则新建该文件 -
然后复制下面配置内容黏贴到该文件中即可,当然路径这件事情还得大家自行修正最后保存退出即可
export HOME=/home/huangzc export JAVA_HOME=${HOME}/softwares/jvm/jdk1.8.0_401 export HADOOP_HOME=${HOME}/softwares/apache/hadoop-3.3.6 export HBASE_HOME=${HOME}/softwares/apache/hbase-2.4.17 export HIVE_HOME=${HOME}/softwares/apache/hive-3.1.3 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HIVE_CONF_DIR=${HIVE_HOME}/conf export HIVE_DATA_DIR=${HOME}/data/apache/hive export HIVE_LOG_DIR=${HIVE_DATA_DIR}/logs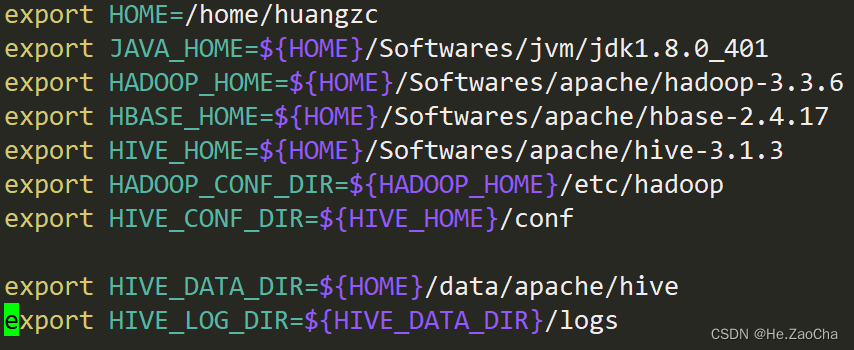
(2) hive-site.xml
该文件和上面一样,也是自行创建然后复制黏贴配置项即可
vim ${HIVE_HOME}/conf/hive-site.xml # 使用 vim 打开编辑,若文件不存在则新建该文件
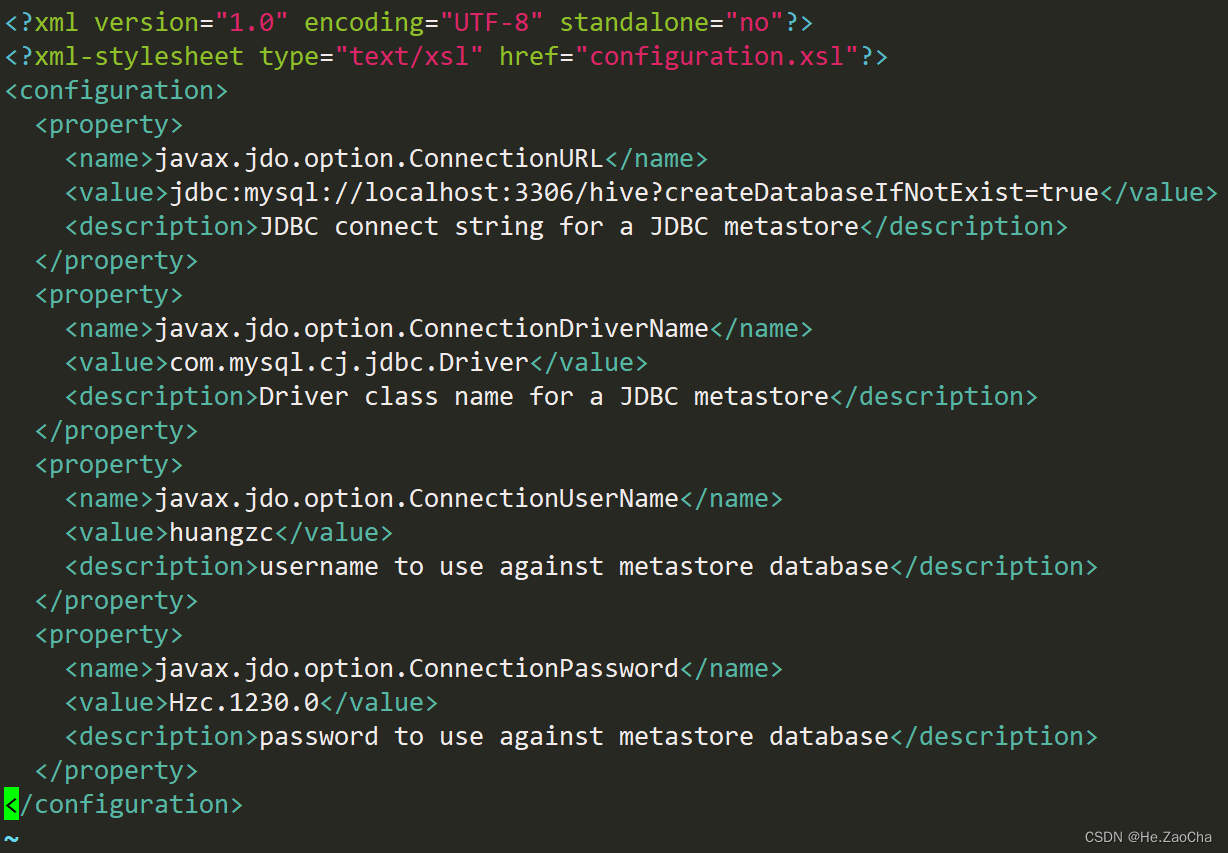
文档配置内容如下,这个就需要全部复制黏贴了,然后 javax.jdo.option.ConnectionUserName 和 javax.jdo.option.ConnectionPassword,需要改成 MySQL 的用户和密码,其他的就不需要尽行修改了,最后保存退出即可。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>huangzc</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Hzc.1230.0</value>
<description>password to use against metastore database</description>
</property>
</configuration>
到这,你们别以为完了,仔细看 xml 文档的内容,是需要使用 jdbc 连接的;但是!问题就是,哪里来的 jdbc 的 jar 包呢?前面忘记跟大家说需要下载了,所以这里就用 wget 给大家演示一下下载的命令。
(3) jdbc
首先就是,我们需要知道从哪里能找到下载的链接,先去到 MySQL 的官网,MySQL,点击 DOWNLOADS,进入下载的页面。
然后在页面下方点击 MySQL Community (GPL) Downloads »,进入选择下载组件界面

然后在页面的右边,会有需要选择下载的 Connector,有分很多种,而我们需要的是 Java 版的,所以就是 Connector/J,点击它进入下一个页面

然后我们会见到是 8.3.0 的下载,然后我们这个操作系统我们选择通用的,然后点击右边 Download (mysql.com) 进入下一界面;
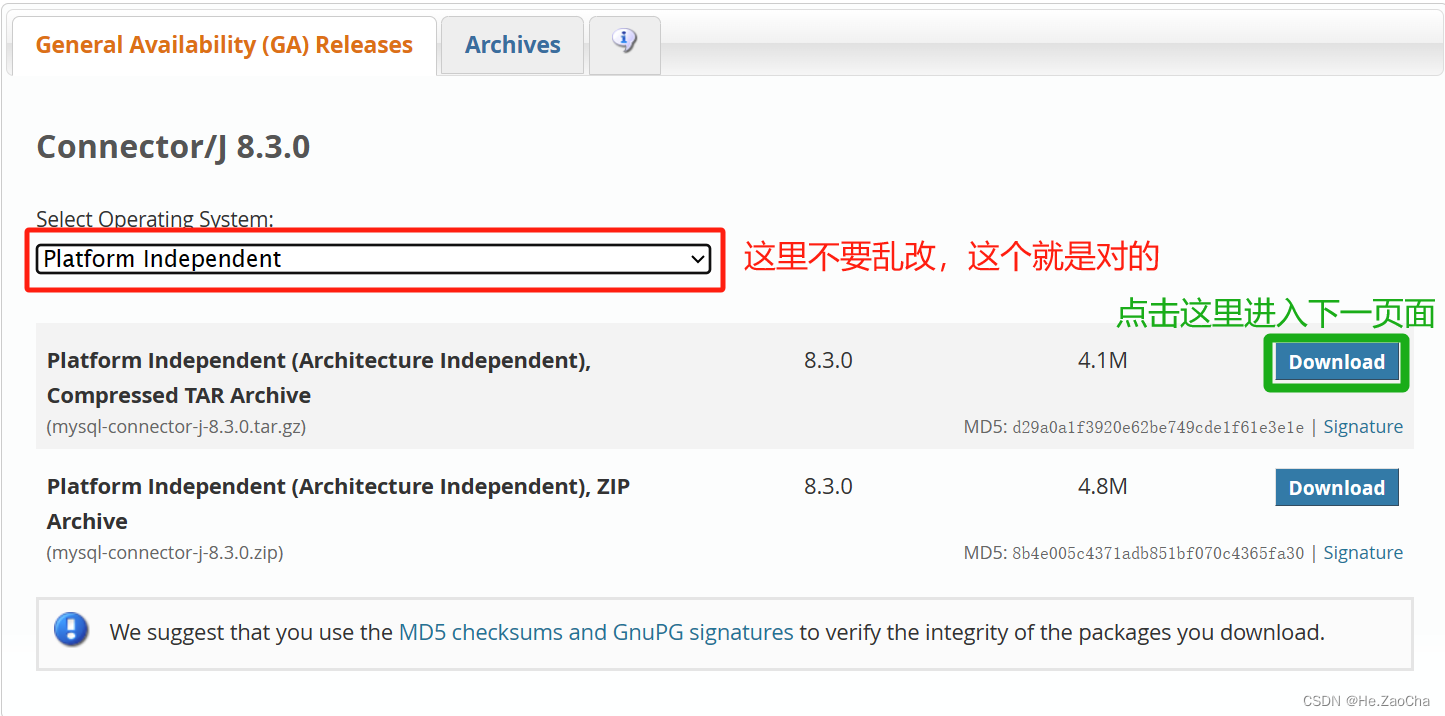
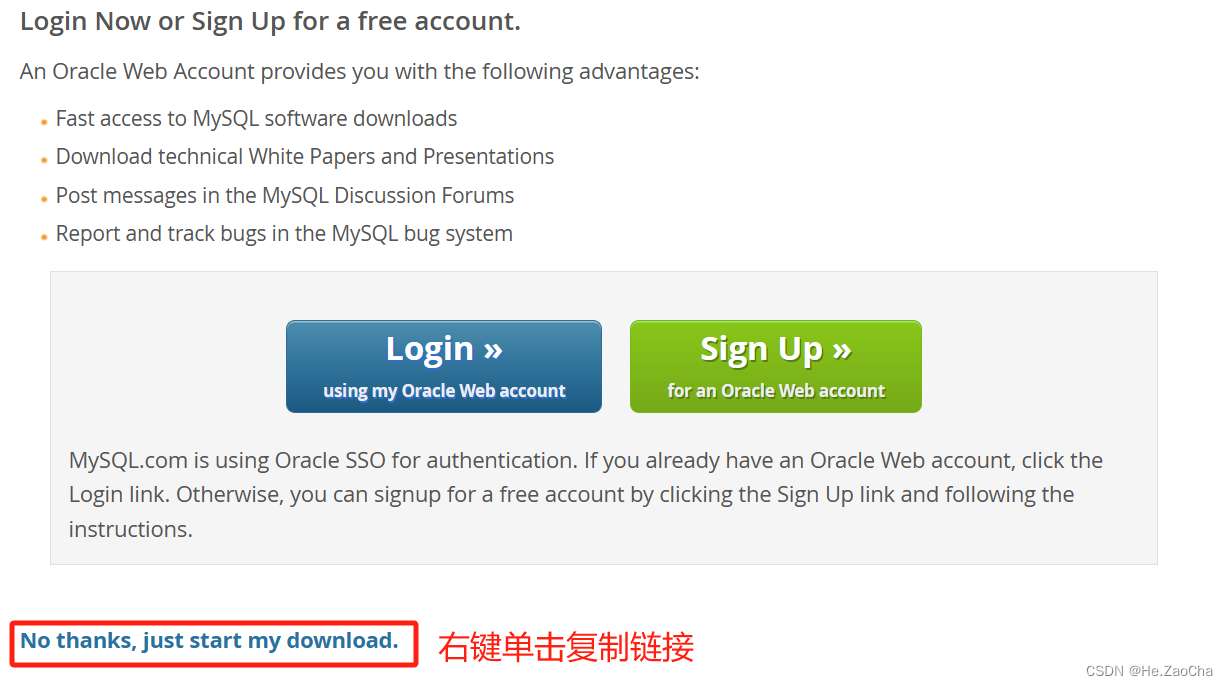
然后我们需要右键单击下面 No thanks, just start my download. (mysql.com) 复制链接
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-8.3.0.tar.gz
如果大家安装的 MySQL 是其他版本的,例如我这里安装的是 8.2.0 版本的,请点击右边的 Archives 进行选择下载。
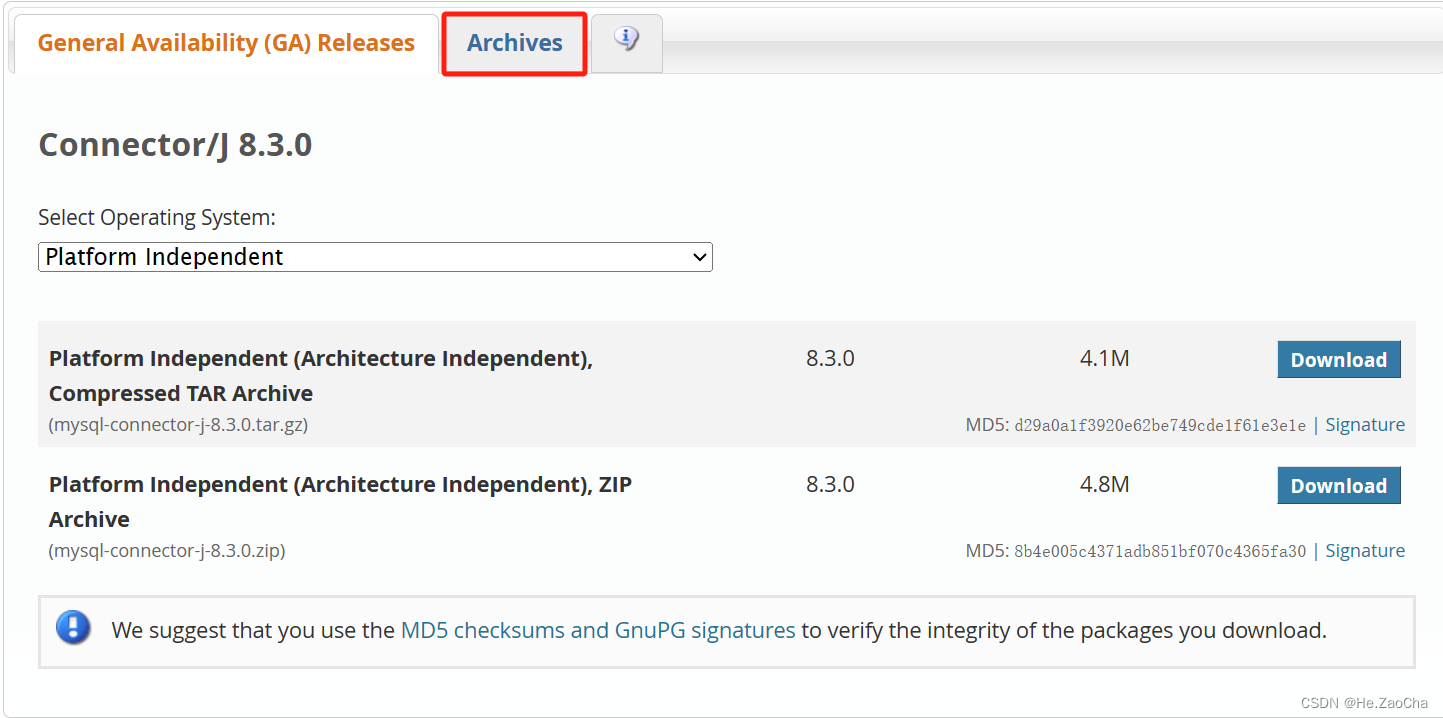
然后选择对应的版本,然后选择对应的系统,系统选通用的,也就是下图所示的这个,请不要胡乱选择!!!,然后复制第一个链接,当然你想解压 zip 也可以,我习惯 tar.gz 而已。

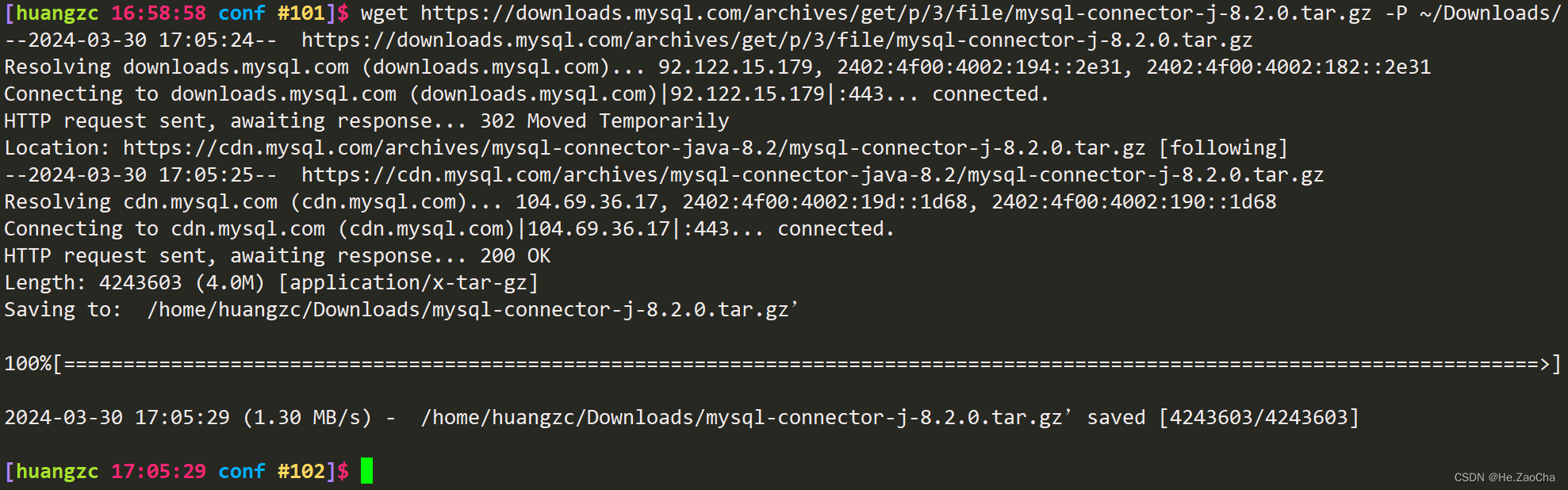
然后回到 CentOS-7,输入命令为 wget [复制的链接] -P [下载的文件需要存储到的路径],这里应该没有看不懂的吧,有的话直接看下面指令即可
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.2.0.tar.gz -P ~/Downloads/ # 下载该压缩文档到用户目录下的 Downloads 目录中
然后进入我们的下载压缩文档的目录中,然后使用 tar 指令进行解压缩,不需要加其他选项,解压到下载目录就可以;然后会出现一个解压目录,我这里是 mysql-connector-j-8.2.0/,大家可能版本号会有所不同,然后我们需要复制该目录中的 mysql-connector-j-8.2.0.jar 包到 ${HIVE_HOME}/lib 中,
cd ~/Downloads/
tar -zxf mysql-connector-j-8.2.0.tar.gz # 解压
cp mysql-connector-j-8.2.0/mysql-connector-j-8.2.0.jar ${HIVE_HOME}/lib # 复制 jar 包
到这里就可以了,示意图如下,如果报错了说明大家的路径有问题,请对应修改。

然后需要对 hive 进行初始化,出现下面这两句说明初始化成功了,那么我们就可以使用 hive 了
schematool -dbType mysql -initSchema # hive 初始化

(4) Hive 启停
启动 hive 的指令很简单,就是 hive
hive # 启动 Hive

四、总结
到这里我们的部署流程就已经完成了,不知道大家有没有收获,没有也没关系,只是希望大家能够好好学习,到这应该就可以支持大家做完所有实验了,实验内容还是得大家自行完成,祝大家学业进步,考研考公考教资四六级雅思托福样样精通。










