一、介绍
Faiss(Facebook AI Similarity Search)是一个面向相似性搜索和聚类的开源库,专注于高维向量的快速相似性搜索。该库提供了一系列高效的算法和数据结构,可用于处理大规模高维向量数据,广泛应用于信息检索、机器学习和深度学习等领域。本文主要介绍Faiss中包含的量化器,量化器可以将高维向量映射到低维码本(codebook)以便进行快速近似最近邻搜索。当然在介绍量化器之前还有说一些前置的概念。
Faiss的API:
Search — Faiss documentation
二、常用的距离
衡量两个向量的距离常用的有L2距离(空间距离)和余弦相似度(角度距离),其中余弦相似度在Faiss中并未直接提供,而是使用内积来变相实现,接下来介绍一下L2距离、内积和余弦相似度。
1.L2距离(欧氏距离)
L2距离是最常见的距离度量方式,用于衡量两个向量之间的空间距离。在二维空间中,L2距离可以通过勾股定理计算得出,即两点之间的直线距离。在多维空间中,L2距离表示为两个向量之间每个对应维度差值的平方和的平方根。
空间中两点的L2距离公示如下:
=\sqrt{\sum_{i=0}^{n}(A_i-B_i)}")
其中n是AB两点的坐标向量长度。
2.内积(Inner Product)
内积(点积)和余弦相似度是线性代数中常用的两种度量方式,它们在机器学习和数据科学中经常用于衡量向量之间的相似性。余弦相似度是基于向量的方向来度量的,而不是它们的长度。内积有他的几何意义,但是比较抽象,我理解他的主要作用还是用来表示余弦相似度,以下是内积公式,很简单就是向量的每一维相乘后相加:

3.内积和余弦相似度
要在 Faiss 中使用余弦相似度,通常需要将向量进行归一化处理,然后使用内积计算余弦相似度。那么为什么将向量进行归一化处理后,内积就等价于余弦距离了呢,其实很简单,先来看一下余弦相似度公式:
 = \frac{A\cdot B}{\left \| A \right \|\left \| B \right \|}")
取值范围[-1, 1],值越接近1表示向量越相似。通过上式可以看出,当向量进行归一化处理后,它们的长度(范数)变为1,即

。所以在向量归一化处理之后,两个向量的内积实际上就等于它们之间的余弦相似度。 当然也可以将余弦相似度的的结果控制在0到1之间,像这样
 + 1) / 2")
,其实在很多时候这样做更有用。
4.余弦距离
多说一句余弦距离,余弦距离定义为余弦相似度的一个变形,通常用于衡量向量之间的不相似度。它可以通过以下公式计算:
 = 1-cos \ similarity(A,B)")
取值范围[0, 2],越接近0距离越近,当然也可以做一下归一化。
三、Flat索引
Flat索引是一种基本的索引结构,使用简单的线性扫描方式进行相似性搜索。简单来说,就是暴力搜索,入库的向量不会经过任何形式的预处理(例如归一化)或量化,它们以原始的、完整的形式存储。在进行相似度检索时,Flat索引会完整地扫描整个库,因此它的计算结果一定是全局最优的。
Flat有如下相关算法:
类名 | 描述 |
faiss.IndexFlat(1024, faiss.METRIC_L2) | 基础的Flat实现,支持多种不同的相似性度量,如 L2 距离、内积等。 d:每个向量的维度 metric:相似度算法,常用的有faiss.METRIC_L2和faiss.METRIC_INNER_PRODUCT |
faiss.IndexFlatL2(1024) | 使用L2距离作为相似度算法的Flat |
faiss.IndexFlatIP(1024) | 使用内积作为相似度算法的Flat |
faiss.IndexFlat1D(continuous_update=True) | 继承自 IndexFlatL2,专门用于在一维向量数据集上执行相似性搜索,当将continuous_update=False时,索引结构不会自动在每次插入新向量后立即更新,需要手动调用update_permutation来更新索引的排序。 |
IndexFlat、IndexFlatL2、IndexFlatIP的代码很像,就写在一起,代码中的1024表示向量长度,下面的例子我们都使用1024维的向量:
import numpy as np
import faiss
# 创建一些示例向量数据
np.random.seed(0)
data = np.random.rand(10, 1024).astype('float32')
# 创建 Flat 索引
# 第二个参数使用faiss.METRIC_L2时该方法等价于IndexFlatL2
# 第二个参数使用faiss.METRIC_INNER_PRODUCT时该方法等价于IndexFlatIP
index = faiss.IndexFlat(64, faiss.METRIC_L2)
# 创建 FlatL2 索引
# index = faiss.IndexFlatL2(1024)
# 创建 FlatIP 索引
# index = faiss.IndexFlatIP(1024)
# 向索引中添加向量数据
index.add(data)
# 创建一个查询向量
query = np.random.rand(1, 1024).astype('float32')
# 执行相似性搜索
k = 5 # 指定返回最相似的 k 个向量
D, I = index.search(query, k) # D 为距禃,I 为对应的向量索引
print("最相似的向量索引:", I)
print("对应的距禃:", D)
'''
最相似的向量索引: [[1 3 9 2 8]]
对应的距禃: [[ 7.4712954 8.061846 8.335889 8.582125 10.274038 ]]
'''下面是IndexFlat1D的代码示例:
import numpy as np
import faiss
# 创建一些示例的一维向量数据
data = np.array([[1.2], [3.4], [5.6], [7.8], [9.0]], dtype='float32')
# 创建 IndexFlat1D 索引
index = faiss.IndexFlat1D()
# 向索引中添加向量数据
index.add(data)
# 创建一个查询向量
query = np.array([[4.5]], dtype='float32')
# 执行相似性搜索
k = 1 # 指定返回最相似的 1 个向量
D, I = index.search(query, k) # D 为距禃,I 为对应的向量索引
print("最相似的向量索引:", I)
print("对应的距禃:", D)
'''
最相似的向量索引: [[2]]
对应的距禃: [[1.0999999]]
'''四、IVF索引
IVF(Inverted File)倒排索引,相较于暴力匹配(Flat)多了一个预筛的步骤。目的是减少需要计算距离的次数。
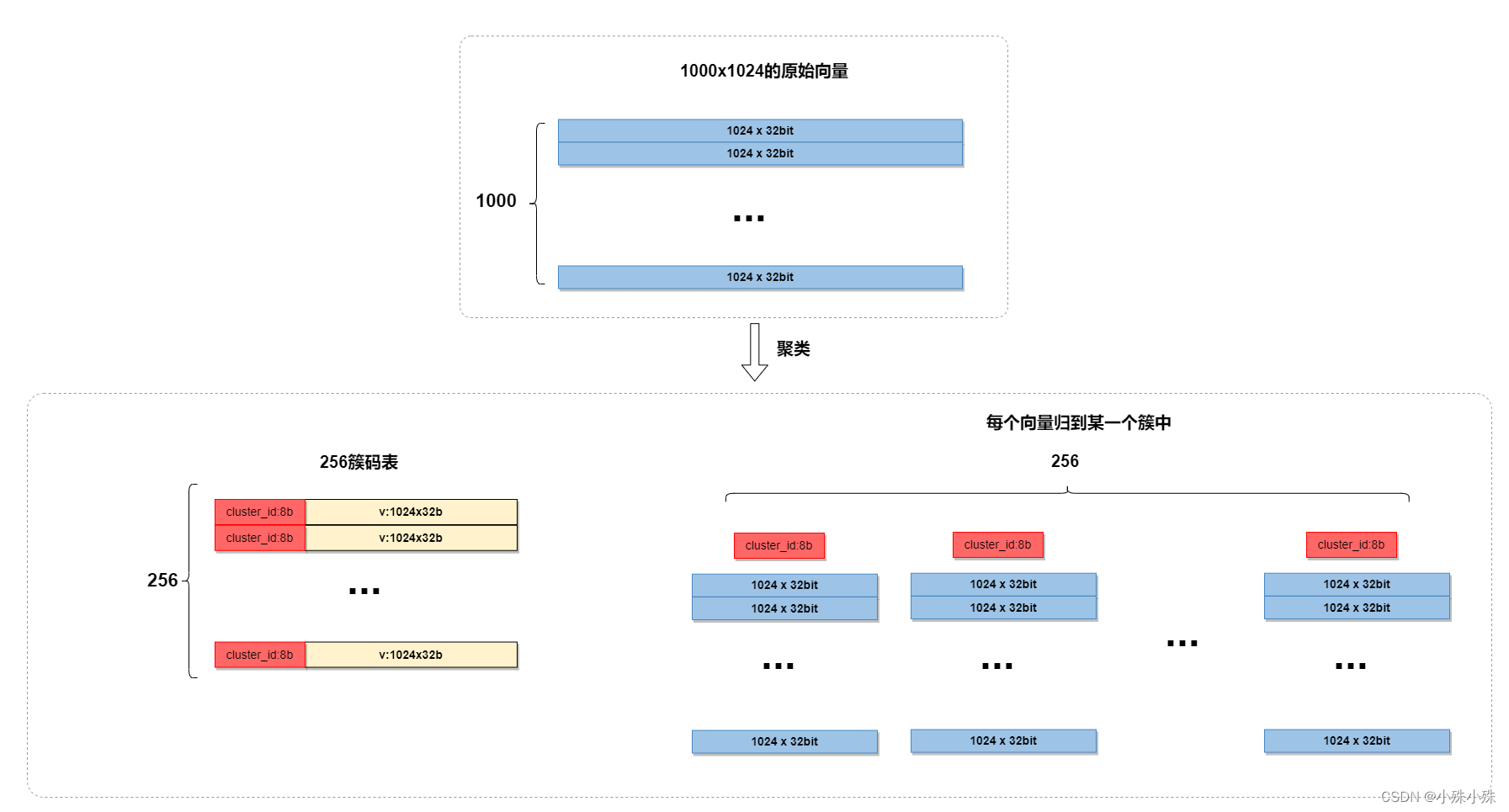
索引过程并不复杂,就是直接对所有向量做k-means,然后所有的向量都会归到某一个簇中;检索的时候,每来一个查询向量,首先计算其与每个簇心的距离,然后选择距离最近的若干个簇,只计算查询向量与这几个簇底下的向量的距离,然后排序取top-k就可以了。
索引过程如下:
检索过程如下:
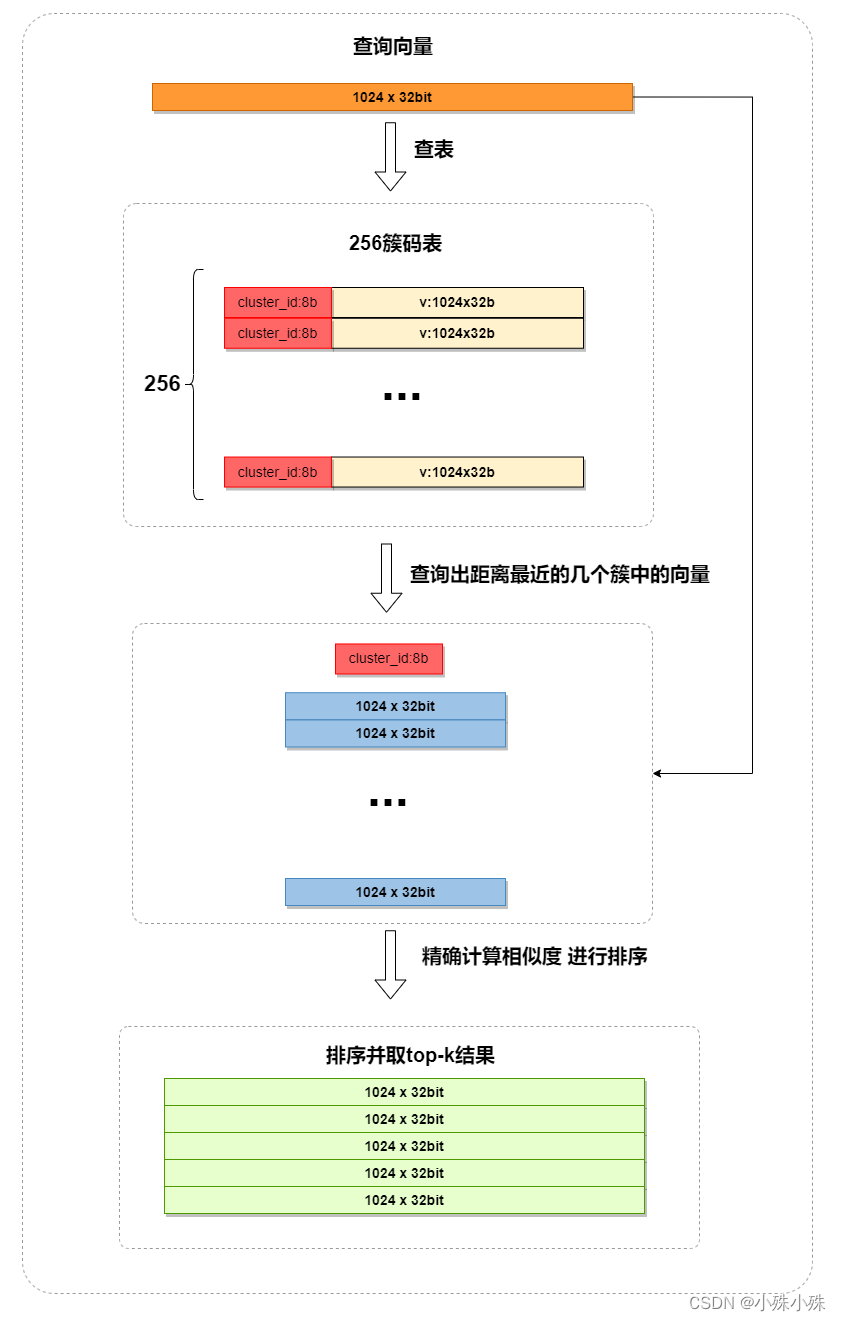
Faiss具体实现有一个小细节就是在计算查询向量和一个簇底下的向量的距离的时候,所有向量都会被转化成与簇心的残差,这应该就是类似于归一化的操作。使用了IVF过后,需要计算距离的向量个数就少了几个数量级,最终向量检索就变成一个很快的操作。
IVF相关的代码会随着量化算法介绍。
五、量化算法
量化算法大体分3类,标准量化、乘积量化和加法量化。简单地说,标准量化直接将向量离散化,不变维度;乘积量化是将向量分段,然后对每段进项单独量化;加法量化是将完整的向量拆分成多级向量(维度与原始向量相同)的和,对每级进行量化。
Faiss中量化算法一般是成组出现的,由量化类、量化索引和IVF索引,其中量化类可以对数据进行量化,返回量化结果,一般并不直接使用;量化索引在量化类的基础上将数据进行索引存储,可以执行检索;IVF量化索引是使用了倒排索引的量化索引。
1.标准量化(Scalar Quantizer)
标量量化是最基础的量化手段,将向量分成若干个区间,然后将每个区间映射到一个离散的数值用对数据直接量化。比如数据是1000x1024按照8bit量化,假设每个维度的取值范围是0到1000,我们先根据维度分成1024组,每组划分为

个级别,每个级别代表4(1000/256)。最终向量中的值将被分配到所在组的256个级别中的一个,得到量化结果。
值得注意的是,在检索的时候faiss.IndexScalarQuantizer还会遍历所有数据,然后对筛选出的数据计算精确的距离,时间复杂度很高,所以实际中不要使用faiss.IndexScalarQuantizer,可以使用faiss.IndexIVFScalarQuantizer
Faiss中SQ相关的有如下相关算法:
类名 | 描述 |
faiss.ScalarQuantizer(1024,faiss.ScalarQuantizer.QT_8bit) | 标准量化 d:每个向量的维度 qtype:QT_8bit的意思是每个维度聚类簇的数量为
|
faiss.IndexScalarQuantizer(1024, faiss.ScalarQuantizer.QT_8bit, faiss.METRIC_L2) | 标准量化索引类 d:每个向量的维度 qtype:QT_8bit的意思是每个维度聚类簇的数量为
metric:相似度算法,常用的有faiss.METRIC_L2和 |
faiss.IndexIVFScalarQuantizer(quantizer,1024, 32, faiss.ScalarQuantizer.QT_8bit, faiss.METRIC_L2) | 实现了IVF的标准量化索引类 quantizer:Index的子类,通常是IndexScalarQuantizer,作用是将高维向量映射到倒排文件中的聚类中心,以便在搜索时能够快速定位到候选向量faiss.IndexFlat就是暴力搜索 d:每个向量的维度 nlist:用于IVF,倒排文件中的聚类中心的数量 qtype:QT_8bit的意思是每个维度聚类簇的数量为
metric:相似度算法,常用的有faiss.METRIC_L2和 |
示例代码如下:
"""
标准量化示例
"""
import numpy as np
import faiss
import time
def test_sq():
# 设定量化器参数
quantizer = faiss.ScalarQuantizer(d, faiss.ScalarQuantizer.QT_8bit)
# 对示例数据进行训练
quantizer.train(data)
# 进行量化
codes = quantizer.compute_codes(data)
print("data0:", data[0])
print("codes0:", codes[0])
def test_index():
# 向索引中添加数据
t = time.time()
index.train(data)
index.add(data)
cost1 = time.time() - t
# 进行近似最近邻搜索
k = 50 # 返回最近邻的数量
t = time.time()
D, I = index.search(query, k)
cost2 = time.time() - t
return D, I, cost1, cost2
if __name__ == '__main__':
d = 1024
nlist = 32
n = 1000000
np.random.seed(0)
# 生成一些随机向量作为示例数据
data = np.random.rand(n, d).astype(np.float32)
# 定义查询向量
query = np.random.rand(1, d).astype(np.float32)
# 量化器的示例
test_sq()
# 暴力检索的示例
index = faiss.IndexFlat(d, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("Flat索引 最近邻的距离:", D)
print("Flat索引 最近邻的索引:", I)
print("Flat索引 耗时:", cost1, cost2)
# SQ索引的示例
index = faiss.IndexScalarQuantizer(d, faiss.ScalarQuantizer.QT_8bit, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("SQ索引 最近邻的距离:", D)
print("SQ索引 最近邻的索引:", I)
print("SQ索引 耗时:", cost1, cost2)
# IVF+SQ的示例
# quantizer = faiss.IndexScalarQuantizer(d, faiss.ScalarQuantizer.QT_8bit, faiss.METRIC_L2)
quantizer = faiss.IndexFlat(d, faiss.METRIC_L2)
index = faiss.IndexIVFScalarQuantizer(quantizer, d, nlist, faiss.ScalarQuantizer.QT_8bit, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("IVF+SQ索引 最近邻的距离:", D)
print("IVF+SQ索引 最近邻的索引:", I)
print("IVF+SQ索引 耗时:", cost1, cost2)2.乘积量化(Product Quantization)
PQ是一种用于高维向量压缩和相似性搜索的技术,特别适用于大规模向量数据集的近似最近邻搜索。PQ 技术将高维向量分解为多个子空间,并对每个子空间进行独立的向量量化,从而实现高效的向量压缩和搜索。下面将对量化和检索两个方面进行介绍:
PQ的论文地址:
https://arxiv.org/pdf/2401.08281.pdf
(1)PQ量化
量化过程有如下3个步骤:
1. 向量分解:将原始高维向量分解为多个子向量,每个子向量属于一个子空间。
2. 子空间量化:对每个子空间进行独立的向量量化,将连续的向量空间划分为离散的子空间。
3. 编码:将原始向量编码为子空间的离散码字,以表示原始向量在每个子空间中的位置。
下面来看一个例子:
数据集是一个1000x1024的矩阵,每个向量维度1024:

向量分解:先将每个1024维的向量平均分成8个128维的子向量,如下图所示:

子空间量化:然后对这8组子向量分别使用k-means聚成256类。下图中(1)竖着的一列为一组,每组进行聚类,聚类成256个簇,形成8x256的码表(2)。然后将每个128维的原向量转换成簇的中心点,如下图中的(3)
编码:接下来将每一个格中的128维向量根据(2)量化成一个簇ID(0-256 占8bit),这样原始1024维浮点数(32位)向量便压缩成8个8位整数,即下图(4)中粉色矩阵中的一行。
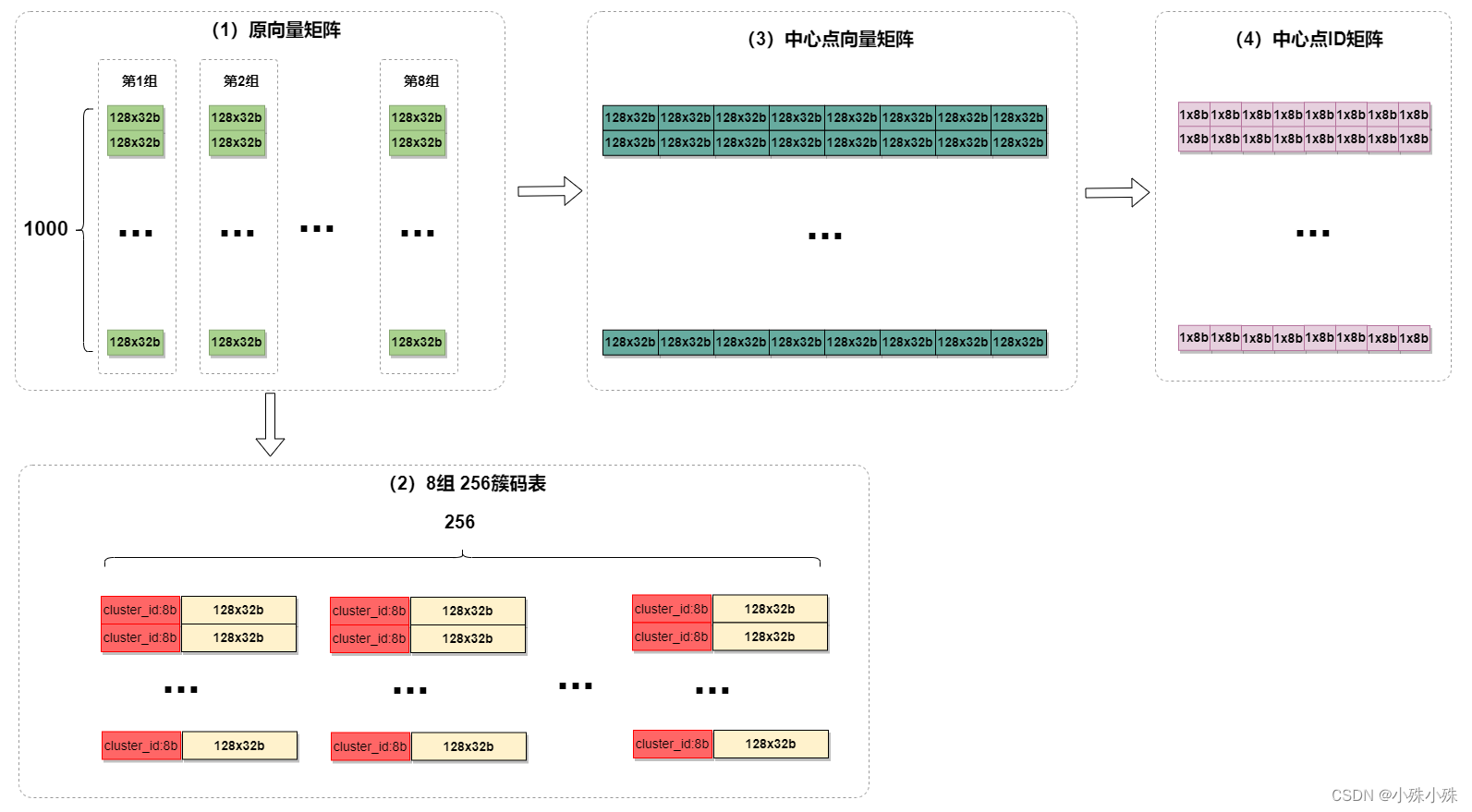
在上面的例子中,子向量数量和每个子向量簇的数量是两个超参数,经过实验子向量数量选择8和簇的数量选择256通常是最佳的。
(2)PQ检索
检索过程非常类似于找回+排序:
1. 量化查询向量:使用上面的压缩过程将查询向量转换成中心点ID矩阵。
2.召回:将查询的 PQ 编码与码本中的所有 PQ 编码进行比较,寻找与查询编码最接近的候选向量,比如计算海明距离。
3.排序:对于每个候选编码,找到对应的原始向量,然后精确计算相似度,进行排序。
这个流程大致如下:
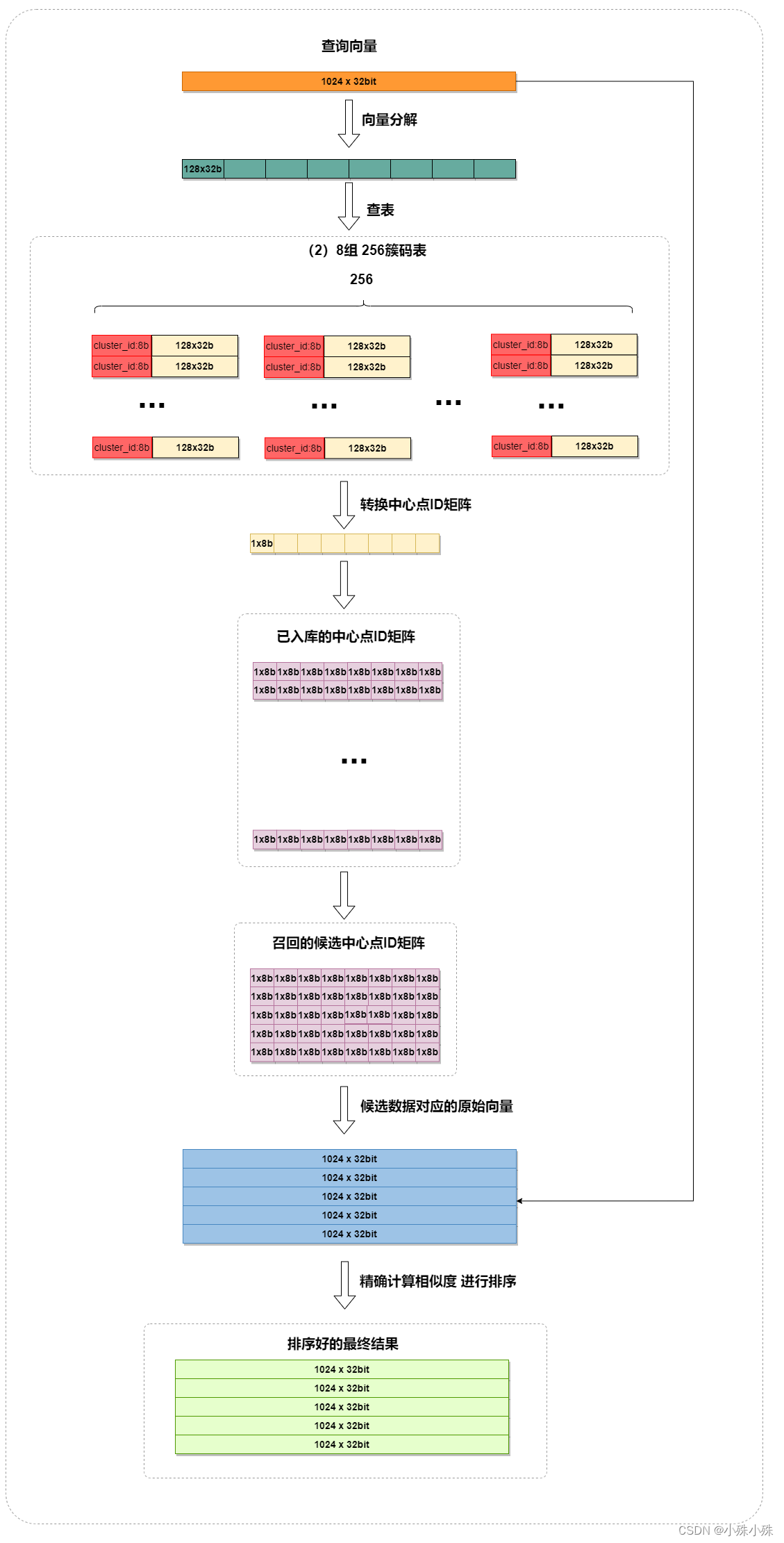
上图中M=8,nlist=8
Faiss中PQ相关的有如下相关算法:
类名 | 描述 |
faiss.ProductQuantizer(1024, 8, 8) | 乘积量化 d:每个向量的维度 M:划分子空间的数量,用于将原始向量分解为多个子向量。这个数必须能被d整除。 nbits:每个子空间的比特数,用于量化每个子向量的精度。用它可以计算出簇的数量为
|
faiss.IndexPQ(1024, 8, 8, faiss.METRIC_L2) | 乘积量化索引类 d:每个向量的维度 M:划分子空间的数量,用于将原始向量分解为多个子向量。这个数必须能被d整除。 nbits:每个子空间的比特数,用于量化每个子向量的精度。用它可以计算出簇的数量为
metric:相似度算法,常用的有faiss.METRIC_L2和 |
faiss.IndexPQFastScan(1024, 8, 8, faiss.METRIC_L2,32) | 实现了FastScan算法的PQ,FastScan将数据分块,在检索的时候可以使用多线程加速。 最后一个参数是bbs,该参数在 FastScan 算法中通常表示 "Block Size",即块大小。在 FastScan 算法中,块大小指定了在进行快速扫描时每个块的大小或长度。这个参数影响了 FastScan 算法中数据的分块处理方式,可以影响算法的性能和效率。 |
faiss.IndexIVFPQ(quantizer, 1024, 8, 1000, 8, faiss.METRIC_L2) | 实现了IVF的乘积量化索引类 quantizer:Index的子类,在精确计算距离阶段使用的量化索引,以便在搜索时能够快速定位到候选向量faiss.IndexFlat就是暴力搜索 d:每个向量的维度 nlist:用于IVF,倒排文件中的聚类中心的数量 M:划分子空间的数量,用于将原始向量分解为多个子向量。这个数必须能被d整除。 nbits:每个子空间的比特数,用于量化每个子向量的精度。用它可以计算出簇的数量为
metric:相似度算法,常用的有faiss.METRIC_L2和 |
faiss.IndexIVFPQFastScan(quantizer, 1024, 8, 1000, 8, faiss.METRIC_L2,32) | 实现了FastScan的IVF乘积量化索引类 |

代码示例如下:
"""
乘积量化示例
"""
import numpy as np
import faiss
import time
def test_pq():
# 设定量化器参数
quantizer = faiss.ProductQuantizer(d, M, nlist)
# 对示例数据进行训练
quantizer.train(data)
# 进行量化
codes = quantizer.compute_codes(data)
print("data0:", data[0])
print("codes0:", codes[0])
def test_index():
# 向索引中添加数据
t = time.time()
index.train(data)
index.add(data)
cost1 = time.time() - t
# 进行近似最近邻搜索
k = 50 # 返回最近邻的数量
t = time.time()
D, I = index.search(query, k)
cost2 = time.time() - t
return D, I, cost1, cost2
if __name__ == '__main__':
d = 1024
M = 8
nbits = 8
nlist = 500
nbits_per_idx = 4
n = 100000
np.random.seed(0)
# 生成一些随机向量作为示例数据
data = np.random.rand(n, d).astype(np.float32)
# 定义查询向量
query = np.random.rand(1, d).astype(np.float32)
# 量化器的示例
# test_pq()
# 暴力检索的示例
index = faiss.IndexFlat(d, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("Flat索引 最近邻的距离:", D)
print("Flat索引 最近邻的索引:", I)
print("Flat索引 耗时:", cost1, cost2)
# PQ索引的示例
index = faiss.IndexPQ(d, M, nbits, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("PQ索引 最近邻的距离:", D)
print("PQ索引 最近邻的索引:", I)
print("PQ索引 耗时:", cost1, cost2)
# IVF+PQ的示例
# quantizer = faiss.IndexPQ(d, M, nbits, faiss.METRIC_L2)
quantizer = faiss.IndexFlat(d, faiss.METRIC_L2)
index = faiss.IndexIVFPQ(quantizer, d, nlist, M, nbits_per_idx, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("IVF+PQ索引 最近邻的距离:", D)
print("IVF+PQ索引 最近邻的索引:", I)
print("IVF+PQ索引 耗时:", cost1, cost2)3.加法量化
加法量化(Additive Quantization)的基本思想是将原始向量表示为多个部分的和,每个部分都可以独立进行量化。在加法量化中,每个部分由一个码本表示,最终的量化结果是这些部分码本的加和。
Faiss中AQ相关的算法有ResidualQuantizer、LocalSearchQuantizer和AdditiveQuantizer,其中AdditiveQuantizer是ResidualQuantizer和LocalSearchQuantizer的父类。
(1)残差量化(Residual Quantizer)
残差量化,涉及对数据进行多次量化,每次量化(通常使用的是简单的标量量化)都使用相同的量化级别,但重建过程中会考虑前一次量化产生的误差。这种方法的关键在于,通过只处理量化过程产生的误差,可以更有效地压缩数据,同时尽量减少信息损失。
过程包括以下步骤:
a.初步量化:对数据进行一次简单的量化(K-means),将其划分到有限数量的级别中。
b.计算残差:计算初步量化后的数据与原始数据之间的差异,这些差异被称为“残差”。
c.再次量化:对计算出的残差进行再次量化,这次量化可以更加精确,因为残差通常比原始数据小很多。
d.迭代过程:b、c两个步骤迭代进行,即对残差的量化结果再次计算残差,并进行量化。
Faiss中残差量化相关的有如下相关算法:
类名 | 描述 |
faiss.ResidualQuantizer(1024, 5, 8) | 残差量化 d:每个向量的维度 M:执行量化与残差的轮数,这个参数很有意思,单数执行量化,双数执行残差,比如这个参数=5:1量化、2残差、3量化、4残差、5量化,对于结果残差会覆盖前一次量化,所以结果的维度是(d,(M-1)/2) nlist:量化时聚类中心的数量 |
faiss.IndexResidualQuantizer(1024, 5, 8, faiss.METRIC_L2) | 残差量化索引类 参数同上,只是多了一个metric |
faiss.IndexIVFResidualQuantizer(quantizer, 1024, 100, 5, 8, faiss.METRIC_L2, faiss.ResidualQuantizer.ST_norm_qint8) | 实现了IVF的乘积量化索引类 quantizer:Index的子类,在精确计算距离阶段使用的量化索引,以便在搜索时能够快速定位到候选向量faiss.IndexFlat就是暴力搜索 d:每个向量的维度 nlist:用于IVF,倒排文件中的聚类中心的数量 M:执行量化与残差的轮数,这个参数很有意思,单数执行量化,双数执行残差,比如这个参数=5:1量化、2残差、3量化、4残差、5量化,对于结果残差会覆盖前一次量化,所以结果的维度是(d,(M-1)/2) nbits:每个子空间的比特数,用于量化每个子向量的精度。用它可以计算出簇的数量为
metric:相似度算法,常用的有faiss.METRIC_L2和 qtype:QT_8bit的意思是每个维度聚类簇的数量为
|
faiss.IndexIVFResidualQuantizerFastScan(quantizer, 1024, 100, 5, 8, faiss.METRIC_L2, faiss.ResidualQuantizer.ST_norm_qint8) | 实现了FastScan的IVF残差量化索引类 |
代码示例:
"""
残差量化示例
"""
import numpy as np
import faiss
import time
def test_rq():
# 设定量化器参数
quantizer = faiss.ResidualQuantizer(d, M, nbits)
# 对示例数据进行训练
quantizer.train(data)
# 进行量化
codes = quantizer.compute_codes(data)
print("data0:", data[0])
print('shape:', codes.shape)
print("codes0:", codes[0])
def test_index():
# 向索引中添加数据
t = time.time()
index.train(data)
index.add(data)
cost1 = time.time() - t
# 进行近似最近邻搜索
k = 50 # 返回最近邻的数量
t = time.time()
D, I = index.search(query, k)
cost2 = time.time() - t
return D, I, cost1, cost2
if __name__ == '__main__':
d = 1024
M = 3
nbits = 8
nlist = 100
n = 100000
np.random.seed(0)
# 生成一些随机向量作为示例数据
data = np.random.rand(n, d).astype(np.float32)
# 定义查询向量
query = np.random.rand(1, d).astype(np.float32)
# 量化器的示例
test_rq()
# 暴力检索的示例
index = faiss.IndexFlat(d, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("Flat索引 最近邻的距离:", D)
print("Flat索引 最近邻的索引:", I)
print("Flat索引 耗时:", cost1, cost2)
# SQ索引的示例
index = faiss.IndexResidualQuantizer(d, M, nbits, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("RQ索引 最近邻的距离:", D)
print("RQ索引 最近邻的索引:", I)
print("RQ索引 耗时:", cost1, cost2)
# IVF+SQ的示例
# quantizer = faiss.IndexResidualQuantizer(d, M, nlist, faiss.METRIC_L2)
quantizer = faiss.IndexFlat(d, faiss.METRIC_L2)
index = faiss.IndexIVFResidualQuantizer(quantizer, d, nlist, M, nbits, faiss.METRIC_L2, faiss.ResidualQuantizer.ST_norm_qint8)
D, I, cost1, cost2 = test_index()
print("IVF+SQ索引 最近邻的距离:", D)
print("IVF+SQ索引 最近邻的索引:", I)
print("IVF+SQ索引 耗时:", cost1, cost2)(2)局部检索量化(LocalSearchQuantizer)
局部检索量化,先使用k-means将原始高维向量空间划分为若干个簇,然后将原始的高维向量其映射到最近的簇心,最后再使用量化方法将高维向量转换成一个代表性的低维向量。检索的时候使用局部搜索的方法在这些低维向量上进行最近邻搜索。
LocalSearchQuantizer是下面两篇论文的实现:
Revisiting additive quantization Julieta Martinez, et al. ECCV 2016
LSQ++: Lower running time and higher recall in multi-codebook quantization Julieta Martinez, et al. ECCV 2018
示例代码如下:
"""
局部检索量化示例
"""
import numpy as np
import faiss
import time
def test_lsq():
# 设定量化器参数
quantizer = faiss.LocalSearchQuantizer(d, M, nbits)
# 对示例数据进行训练
quantizer.train(data)
# 进行量化
codes = quantizer.compute_codes(data)
print("data0:", data[0])
print('shape:', codes.shape)
print("codes0:", codes[0])
def test_index():
# 向索引中添加数据
t = time.time()
index.train(data)
index.add(data)
cost1 = time.time() - t
# 进行近似最近邻搜索
k = 50 # 返回最近邻的数量
t = time.time()
D, I = index.search(query, k)
cost2 = time.time() - t
return D, I, cost1, cost2
if __name__ == '__main__':
d = 1024
M = 3
nbits = 8
nlist = 100
n = 10000
np.random.seed(0)
# 生成一些随机向量作为示例数据
data = np.random.rand(n, d).astype(np.float32)
# 定义查询向量
query = np.random.rand(1, d).astype(np.float32)
# 量化器的示例
test_lsq()
# 暴力检索的示例
index = faiss.IndexFlat(d, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("Flat索引 最近邻的距离:", D)
print("Flat索引 最近邻的索引:", I)
print("Flat索引 耗时:", cost1, cost2)
# LSQ索引的示例
index = faiss.IndexLocalSearchQuantizer(d, M, nbits, faiss.METRIC_L2)
D, I, cost1, cost2 = test_index()
print("LSQ索引 最近邻的距离:", D)
print("LSQ索引 最近邻的索引:", I)
print("LSQ索引 耗时:", cost1, cost2)
# IVF+LSQ的示例
quantizer = faiss.IndexFlat(d, faiss.METRIC_L2)
index = faiss.IndexIVFLocalSearchQuantizer(quantizer, d, nlist, M, nbits, faiss.METRIC_L2, faiss.ResidualQuantizer.ST_norm_qint8)
D, I, cost1, cost2 = test_index()
print("IVF+LSQ索引 最近邻的距离:", D)
print("IVF+LSQ索引 最近邻的索引:", I)
print("IVF+LSQ索引 耗时:", cost1, cost2)(3)加法量化(Additive Quantizer)
Faiss中的AdditiveQuantizer是将残差量化或者局部量化的结果加起来作为向量的量化结果,不过用的不是很多,就不介绍了。
Faiss中还有一些量化器,是上面这些量化器的排列组合,看名字就知道功能,使用频率也不是很高:
类名 | 描述 |
faiss.AdditiveQuantizer | 加法量化 |
faiss.AdditiveQuantizerFastScan | 使用了FastScan的加法量化 |
faiss.ProductLocalSearchQuantizer | 乘积量化+局部检索量化 |
faiss.ProductResidualQuantizer | 乘积量化+残差量化 |
faiss.ProductResidualQuantizerFastScan | 使用了FastScan的乘积量化+残差量化 |
faiss.ProductLocalSearchQuantizerFastScan | 使用了FastScan的乘积量化+局部检索量化 |
最后一句话总结,如果向量维度不是很大(1024以内),数据量也不是很多(100w以内),内存允许的情况下可以使用Flat暴力搜索,效率其实可以接受;如果维度和数据量都很大,还是老老实实用量化吧,比如IndexIVFPQ还是很香的。
Faiss中的量化器就介绍到这里,欢迎点赞、收藏,关注不迷路(*^__^*)
关注订阅号了解更多精品文章











