
一、概念解析
1、什么是微调(Fine-tuning)?
大模型微调,也称为Fine-tuning,是指在已经预训练好的大型语言模型基础上(一般称为“基座模型”),使用特定的数据集进行进一步的训练,让模型适应特定任务或领域。
经过预训练的基座模型其实已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,并没有一个模型可以解决所有的问题,尤其是行业内的专业问答、关于某个组织自身的信息等,是通用大模型所无法触及的。在这种情况下,就需要使用特定的数据集,对合适的基座模型进行微调,以完成特定的任务、回答特定的问题等。在这种情况下,微调就成了重要的手段。
解析大语言模型训练三阶段这篇文章可以看到,得益于ChatGPT的成功,目前大模型微调一般可以分为SFT(有监督的微调,Supervised-Finetuning)和RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback)。在实际应用中,由于大模型的参数量非常大,训练成本非常高,因此通常不会从头开始训练一个全新的模型,而是选择在预训练模型的基础上进行微调,这样不仅可以节省大量的时间和资源,还能快速迁移到新的任务上。

为了方便大家更好地理解微调的概念,下面有两个例子:
- 例1:情感分类
- 例2:图像分类
这两个例子都展示了fine-tuning的基本步骤:首先在大量的数据上预训练一个模型,然后在特定的任务数据上继续训练模型。
2、为什么需要微调?
大语言模型为什么要微调的原因主要包括以下几点:
3、大模型微调有哪些常见方法?
大模型微调的方法多样,随着技术的发展,涌现出越来越多的大语言模型,且模型参数越来越多,除了传统的SFT外,还有Adapter Tuning、PET、Prefix Tuning、P-Tuning、LoRA、QLoRA等(后面我会专门写一篇博客介绍)。这些方法各有优缺点,适用于不同的场景和需求。
例如,LoRA和QLoRA是目前主流的大模型微调方法之一,它们通过冻结预训练模型的大部分参数,只微调一小部分额外的参数,从而避免灾难性遗忘,并且快速迁移到新的任务上。此外,还有PEFT(参数高效调整)和FFT(全参数调整)两种微调方法,前者主要针对预训练模型中的某些部分参数进行调整,后者则是对所有层都参与微调。
4、SFT流程及示例
SFT意味着使用有标签的数据来调整一个已预训练好的语言模型,使其更适应某一特定任务。通常LLM的预训练是无监督的,但微调过程往往是有监督的。当进行有监督微调时,模型权重会根据与真实标签的差异进行调整。通过这个微调过程,模型能够捕捉到标签数据中特定于某一任务的模式和特点。使得模型更加精确,更好地适应某一特定任务。
以一个简单的例子来说,假设已经有一个已经预训练好的LLM。当输入“我不能登录我的账号,我该怎么办?”时,它可能简单地回答:“尝试使用‘忘记密码’功能来重置你的密码。”
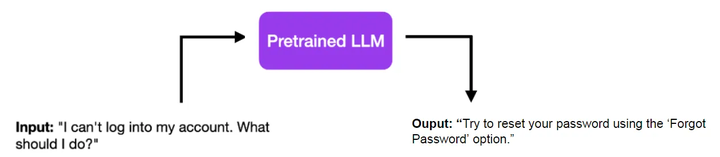
这个回答很直接,适用于一般问题,但如果是客服场景,可能就不太合适了。一个好的客服回答应该更有同情心,并且可能不会这么直接,甚至可能包含联系信息或其他细节。这时候,有监督微调就显得非常重要了。

经过有监督微调后,模型可以提供更加符合特定指导原则的答案。例如,经过一系列专业的培训示例后,模型可以更有同情心地回答客服问题。
二、微调步骤
1、选择基座模型
模型微调的第一步是选择合适的基座模型,如果你们公司自研了基座模型,那就可以从已有的基座模型中选择和应用场景匹配的基模,比如你们有7B、13B、70B这3种参数大小的模型,而每种模型可能又有4k、8k、16k等不同规格的上下文窗口,并非选择参数最大、上线文窗口最大是最合适的,需要根结合具体的业务、模型效果和性价比等因素来综合考虑。
当然你也可以从huggingface、Github这类网站获取开源的大语言模型,然后准备训练数据,自己搭建训练流程,此方法有一定技术门槛。如果你只是想了解一下大模型的微调流程,可以选择一个大模型开放平台来体验。
比如,百度的千帆大模型平台,可供SFT的基座模型有以下几种:

Tips:如何选择合适长度的模型?
文本长度在不同的模型版本中有所差异。选择合适的模型版本能够有效处理特定长度的文本,从而提高模型的整体性能。具体可以:
2、准备数据集
数据集的质量对模型微调至关重要,毫不夸张的说,微调后的模型效果80%取决于SFT训练数据,少量高质的数据要比大量低质或者普通的数据要好很多。你可以根据微调策略和上述基础模型的选择,按照不同的说明来格式化这个数据集。为了评估训练运行的效果,你应该将数据集分割为训练集和验证集。
(1)数据形式
SFT数据一般以问答形式呈现,如下所示:
问答格式可以处理成多种文件格式, 例如JSONL、Excel File、CSV,核心是要保持两个独立的字段, 即问题和答案。除了人工编写SFT数据外,我们也可以从互联网获取开源的数据集(详细可以参考:大语言模型开源数据集)。
(2)Prompt优化
(3)数据规模、数据多样性
在SFT上数据规模的重要性低于数据质量,通常1万条左右的精标数据即可发挥良好的效果。在扩充数据规模时需要注意数据多样性,多样性的数据可以提高模型性能。
多样性除了从原始数据中获取,也可以通过prompt_template方式构建,对prompt指令进行数据增强,比如中文翻译英文的指令可以拓展为,中译英,翻译中文为英文等相同语义的指令。
在不扩大提示多样性的情况下扩大数据量时,收益会大大减少,而在优化数据质量时,收益会显著增加。
(4)数据质量
挑选质量较高的数据,可以有效提高模型的性能。
数据质量用户需尽量自己把控,避免出现一些错误,或者无意义的内容。虽然有些平台也可以提供数据质量筛选的能力,但不可避免出现错筛的情况。数据质量可以通过ppl、reward model,文本质量分类模型等方式进行初步评估,经过人工进行后续筛选。

3、模型训练
以千帆平台为例,在选择了基座模型后,需要进一步配置训练参数,训练任务的算法选择、参数及相关配置,训练配置参数影响训练速度及模型效果。

(1)超参数配置
以Baichuan2-7B-Chat模型为例,该模型单条数据支持4096 tokens。Baichuan2-7B-Chat是在大约1.2万亿tokens上训练的70亿参数模型。
- 训练方法配置:
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置:
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| Packing | 将多条训练样本拼接到一个seqLen长度内。 |
| 学习率调整计划 | 用于调整训练中学习率的变动方式。 |
| 学习率预热步数占比 | 指训练初始阶段,在学习率较低的情况下逐渐增加学习率的比例或速率,能够帮助模型更好地适应数据,提高训练的稳定性和性能。 |
| 权重衰减数值 | 是一种正则化技术,用于帮助控制神经网络模型的复杂性以及减少过拟合的风险。 |
| Checkpoint保存个数 | 训练过程最终要保存的Checkpoint个数,Checkpoint保存会增加训练时长。 |
| Checkpoint保存间隔数 | 训练过程中保存Checkpoint的间隔Step数。 |
| loraRank | 训练方式选择LoRA时填写,LoRA策略中rank,数值越大lora参数越多。 |
| loraAlpha | 训练方式选择LoRA时填写,LoRA微调中的缩放系数,系数越大lora影响力越大。 |
| loraDropout | 训练方式选择LoRA时填写,LoRA微调中的Dropout系数,用于防止lora训练中的过拟合。 |
| 序列长度 | 单条样本的最大长度。如果训练数据较短,减少此项可以加快训练速度。 |
其中:
(2)数据配置
训练任务的选择数据及相关配置,大模型微调任务需要匹配已有的数据集,平台至少需要100条数据才可发起训练。
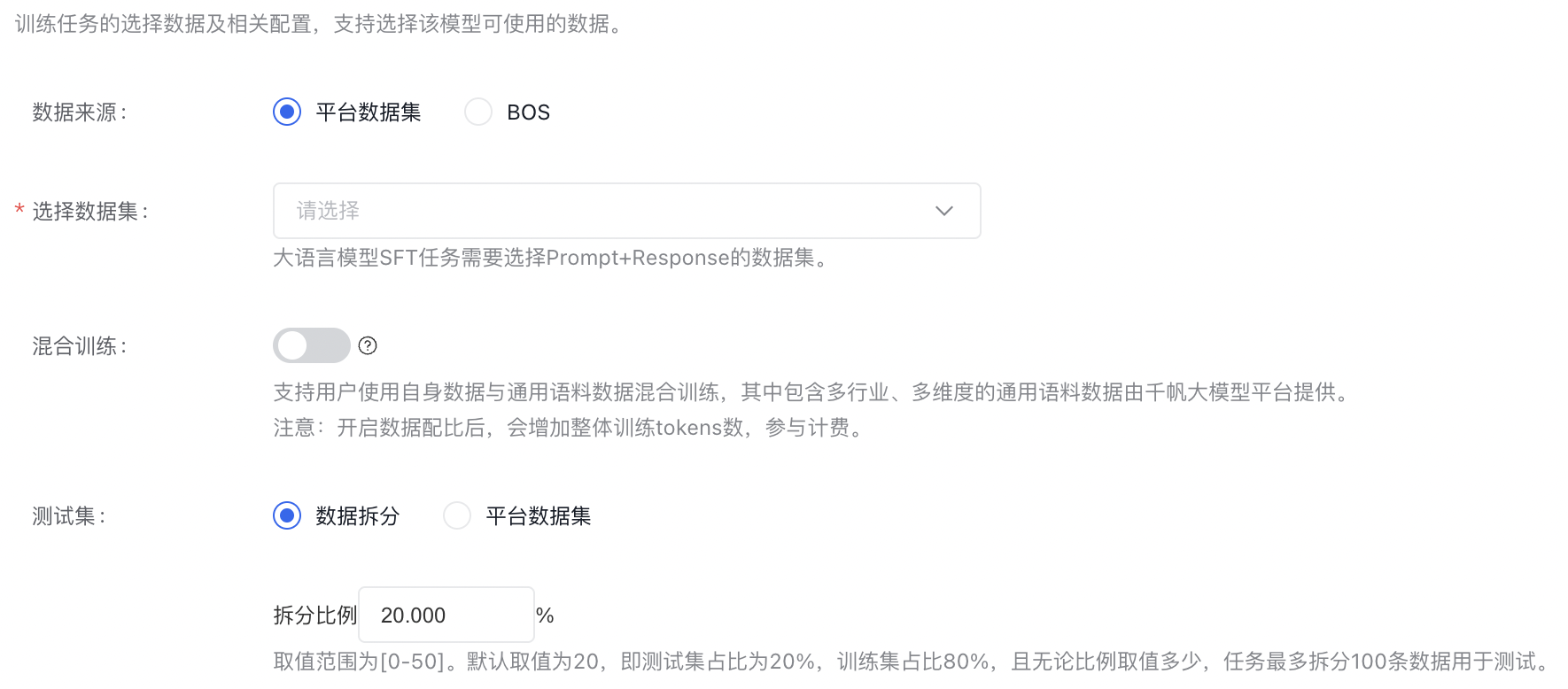
数据集来源可以为千帆平台已发布的数据集版本或者预置数据集,如果选择两个及以上的数据集,支持数据配比,数据占比总和等于100%。

通过提高采样率,来提升数据集的占比。 采样率:对数据集进⾏随机采样,取值范围为[0.01-10]。当数据集过⼤或质量不⾼,可以利⽤⽋采样(采样率⼩于1)来缩减训练数据的⼤⼩;当数据集过⼩或质量较⾼,可以利⽤过采样(采样率⼤于1)来增加训练数据的⼤⼩,数值越⼤训练时对该部分数据的关注度越⾼,但训练时⻓及费⽤越⾼,推荐过采样率范围为[1-5]。
混合训练:支持用户使用自身数据与通用语料数据混合训练,其中包含多行业、多维度的通用语料数据由平台提供。
通用语料数据共四百万条问答对,可以根据自身数据量进行配比,推荐默认选择的数据配比为混合语料:用户数据=1:5。

测试集:可以选择对上面已选择的数据集进行拆分作为测试集,或者指定数据作为测试集。
Reference
1. https://medium.com/mantisnlp/supervised-fine-tuning-customizing-llms-a2c1edbf22c3
2. https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
3. SFT调优快速手册 - 千帆大模型平台 | 百度智能云文档
4. SFT最佳实践 - 千帆大模型平台 | 百度智能云文档
5. 创建SFT任务 - 千帆大模型平台 | 百度智能云文档










