Redis 作为一门主流技术,应用场景非常多,很多大中小厂面试都列为重点考察内容
前几天有星球小伙伴学习时,遇到下面几个问题。
考虑到这些问题比较高频,工作中经常会遇到,这里写篇文章系统讲解下
问题描述:
回复:
分布式缓存作为性能加速器,在系统优化中承担着非常重要的角色。相比本地缓存,虽然增加了一次网络传输,大约占用不到 1 毫秒外,但是却有集中化管理的优势,并支持非常大的存储容量。
分布式缓存领域,目前应用比较广泛的要数 Redis 了,该框架是纯内存储存,单线程执行命令,拥有丰富的底层数据结构,支持多种维度的数据存储和查找。
当然,数据量一大,各种问题就出现了,比如:数据倾斜、数据热点等
什么是数据倾斜?
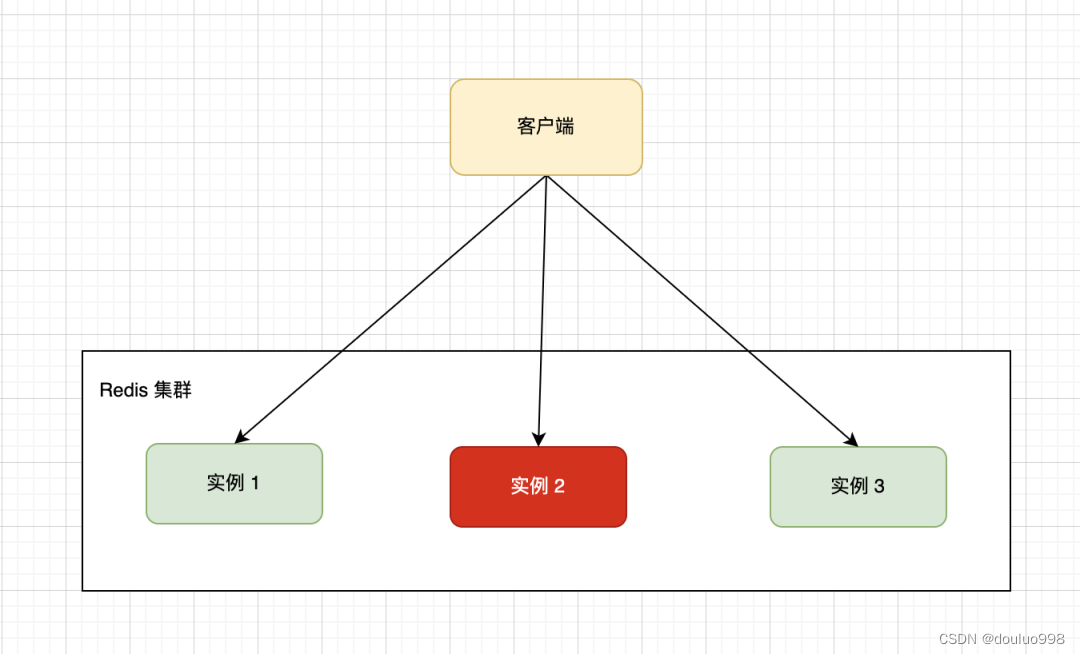
单台机器的硬件配置有上限制约,一般我们会采用分布式架构将多台机器组成一个集群,下图的集群就是由三台Redis单机组成。客户端通过一定的路由策略,将读写请求转发到具体的实例上。
由于业务数据特殊性,按照指定的分片规则,可能导致不同的实例上数据分布不均匀,大量的数据集中到了一台或者几台机器节点上计算,从而导致这些节点负载多大,而其他节点处于空闲等待中,导致终整体效率低下。
数据倾斜有哪些原因呢?
1、存在大key
比如存储一个或多个 String 类型的 bigKey 数据,内存占用很大。
Tom哥之前排查过这种问题,有同事开发时为了省事,采用JSON格式,将多个业务数据合并到一个 value,只关联一个key,导致了这个键值对容量达到了几百M。
频繁的大key读写,内存资源消耗比较重,同时给网络传输带了极大的压力,进而导致请求响应变慢,引发雪崩效应,后系统各种超时报警。
解决方案:
办法非常简单,采用化整为零的策略,将一个bigKey拆分为多个小key,独立维护,成本会降低很多。当然这个拆也讲究些原则,既要考虑业务场景也要考虑访问场景,将关联紧密的放到一起。
比如:有个RPC接口内部对 Redis 有依赖,之前访问一次就可以拿到全部数据,拆分将要控制单值的大小,也要控制访问的次数,毕竟调用次数增多了,会拉大整体的接口响应时间。
浙江的政府机构都在提倡优化流程,多跑一次,都是一个道理。

2、HashTag 使用不当
Redis 采用单线程执行命令,从而保证了原子性。当采用集群部署后,为了解决mset、lua 脚本等对多key 批量操作,为了保证不同的 key 能路由到同一个 Redis 实例上,引入了 HashTag 机制。
用法也很简单,使用{}大括号,指定key只计算大括号内字符串的哈希,从而将不同key的健值对插入到同一个哈希槽。
举个例子:
192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764check 下业务代码,有没有引入HashTag,将太多的key路由到了一个实例。结合具体场景,考虑如何做下拆分。
就像 RocketMQ 一样,很多时候只要能保证分区有序,就可以满足我们的业务需求。具体实战中,要找到这个平衡点,而不是为了解决问题而解决问题。
3、slot 槽位分配不均
如果采用 Redis Cluster 的部署方式,集群中的数据库被分为16384个槽(slot),数据库中的每个健都属于这16384个槽的其中一个,集群中的每个节点可以处理的0个或多16384个槽。
你可以手动做迁移,将一个比较大的 slot 迁移到稍微空闲的机器上,保证存储和访问的均匀性。
什么是缓存热点?
缓存热点是指大部分甚至所有的业务请求都命中同一份缓存数据,给缓存服务器带来了巨大压力,甚至超过了单机的承载上限,导致服务器宕机。
解决方案:
1、复制多份副本
我们可以在key的后面拼上有序编号,比如key#01、key#02。。。key#10多个副本,这些加工后的key位于多个缓存节点上。
客户端每次访问时,只需要在原key的基础上拼接一个分片数上限的随机数,将请求路由不到的实例节点。
注意:缓存一般都会设置过期时间,为了避免缓存的集中失效,我们对缓存的过期时间尽量不要一样,可以在预设的基础上增加一个随机数。
至于数据路由的均匀性,这个由 Hash 算法来保证。
2、本地内存缓存
把热点数据缓存在客户端的本地内存中,并且设置一个失效时间。对于每次读请求,将首先检查该数据是否存在于本地缓存中,如果存在则直接返回,如果不存在再去访问分布式缓存的服务器。
本地内存缓存彻底“解放”了缓存服务器,不会对缓存服务器有任何压力。
缺点:实时感知新的缓存数据有点麻烦,会产生数据不一致的情况。我们可以设置一个比较短的过期时间,采用被动更新。当然,也可以用监控机制,如果感知到数据已经发生了变化,及时更新本地缓存。
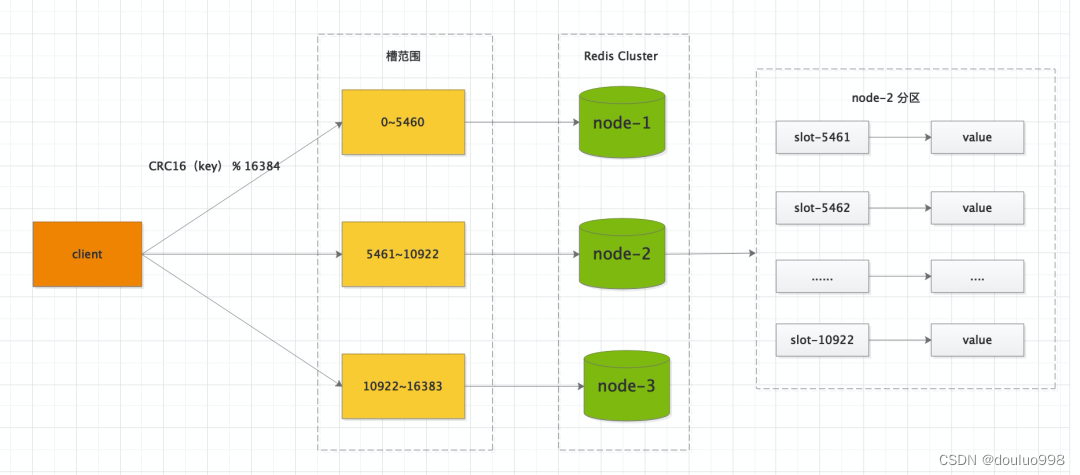
Redis Cluster 为什么不用一致性Hash?
Redis Cluster 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 node-1 包含 0 到 5460 号哈希槽,node-2 包含 5461 到 10922 号哈希槽,node-3包含 10922 到 16383 号哈希槽。
一致性哈希算法是 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
一致性哈希算法本质上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模。
其取模的结果必然是在 [0, 2^32-1] 这个区间中的整数,从圆上映射的位置开始顺时针方向找到的个节点即为存储key的节点

一致性哈希算法大大缓解了扩容或者缩容导致的缓存失效问题,只影响本节点负责的那一小段key。如果集群的机器不多,且平时单机的负载水位很高,某个节点宕机带来的压力很容易引发雪崩效应。
举个例子:
Redis 集群 总共有4台机器,假设数据分布均衡,每台机器承担 四分之一的流量,如果某一台机器突然挂了,顺时针方向下一台机器将要承担这多出来的 四分之一 流量,终要承担 二分之一 的流量,还是有点恐怖。
但是如果采用 CRC16计算后,并结合槽位与实例的绑定关系,无论是扩容还是缩容,只需将相应节点的key做下数据平滑迁移,广播存储新的槽位映射关系,不会产生缓存失效,灵活性很高。
另外,如果服务器节点配置存在差异化,我们可以自定义分配不同节点负责的 slot 编号,调整不同节点的负载能力,非常方便。










