Trie树
也叫前缀树,或者单词查找树,键树。是一种树形结构,一种哈希树的变种。
典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
前缀树的基本结构
用一张图可以比较形象的表示出来
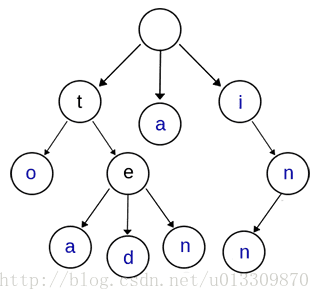
上图是一棵Trie树,表示了关键字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”}
从上图可知Trie树的特点
根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符互不相同。
从第一字符开始有连续重复的字符只占用一个节点,比如上面的to,和ten,中重复的单词t只占用了一个节点。
代码实现
数据结构定义
每个节点定义
class TrieNode {
TrieNode[] children;
boolean isEnd;
public TrieNode() {
children = new TrieNode[26]; // 假设只包含小写字母
isEnd = false;
}
}
可知,如果只包含小写字符串,可以设置子节点为new TrieNode[26];
定义增删查
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
//每次都要从头部开始查
TrieNode node = root;
for (char ch : word.toCharArray()) {
//字符串的减去a后的值是数字值,例如a是97,b是98
int index = ch - 'a';
//如果这个值在索引上没有值,那就需要重新开辟一个TrieNode
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
//继续往下迭代
node = node.children[index];
}
//迭代结束设置一个标识,这个地方可以有很多扩展
node.isEnd = true;
}
//查找类似上面的新增
public boolean search(String word) {
TrieNode node = root;
for (char ch : word.toCharArray()) {
int index = ch - 'a';
if (node.children[index] == null) {
return false;
}
node = node.children[index];
}
//迭代的最后一个字符串需要有个结束字符才能代表当前已经有个一样的字符串了
return node != null && node.isEnd;
}
public boolean startsWith(String prefix) {
TrieNode node = root;
for (char ch : prefix.toCharArray()) {
int index = ch - 'a';
if (node.children[index] == null) {
return false;
}
node = node.children[index];
}
//这里就不需要有结束的标识了
return node != null;
}
public boolean delete(String word) {
return delete(root, word, 0);
}
private boolean delete(TrieNode node, String word, int index) {
if (index == word.length()) {
if (!node.isEnd) {
return false; // 如果单词不存在于Trie中,返回false
}
node.isEnd = false; // 将当前节点标记为非终止节点
// 如果当前节点的子节点数组都为空,说明可以删除这个节点
return allChildNull(node);
}
int ch = word.charAt(index) - 'a';
if (node.children[ch] == null) {
return false; // 单词不存在于Trie中,返回false
}
boolean shouldDeleteCurrentNode = delete(node.children[ch], word, index + 1);
// 如果子节点返回true,表示可以删除当前节点
if (shouldDeleteCurrentNode) {
node.children[ch] = null;
// 如果当前节点的子节点数组都为空,且当前节点不是终止节点,返回true,表示可以删除当前节点
return allChildNull(node) && !node.isEnd;
}
return false; // 如果子节点返回false,则不能删除当前节点
}
private boolean allChildNull(TrieNode node) {
for (TrieNode child : node.children) {
if (child != null) {
return false;
}
}
return true;
}
}
前缀树的复杂度与应用
设平均查询的query词长n, 白名单m条记录,平均长度k,简单单词查询:一个query,需要遍历每一个白名单,调用query是否contains方法,contains方法遍历前词,找到头元素一致,再遍历判断尾序列,contains的复杂度是O(n),整体复杂度是O(mn)
前缀树查询: 一个query,将这个query从头到尾遍历,每个元素在前缀树中判断,操作都是取下一个节点和判断是否是end,时间复杂度是O(1),整体时间复杂度是O(n)
这个比较简单,就简单列下:
前缀匹配
字符串检索, 比如 敏感词过滤,黑白名单等
词频统计
字符串排序
还可以压缩–》基数树
空间复杂度更低的树–》双数组Trie树(DoubleArrayTrie)
节选自:
https://pdai.tech/md/algorithm/alg-basic-tree-trie.html









