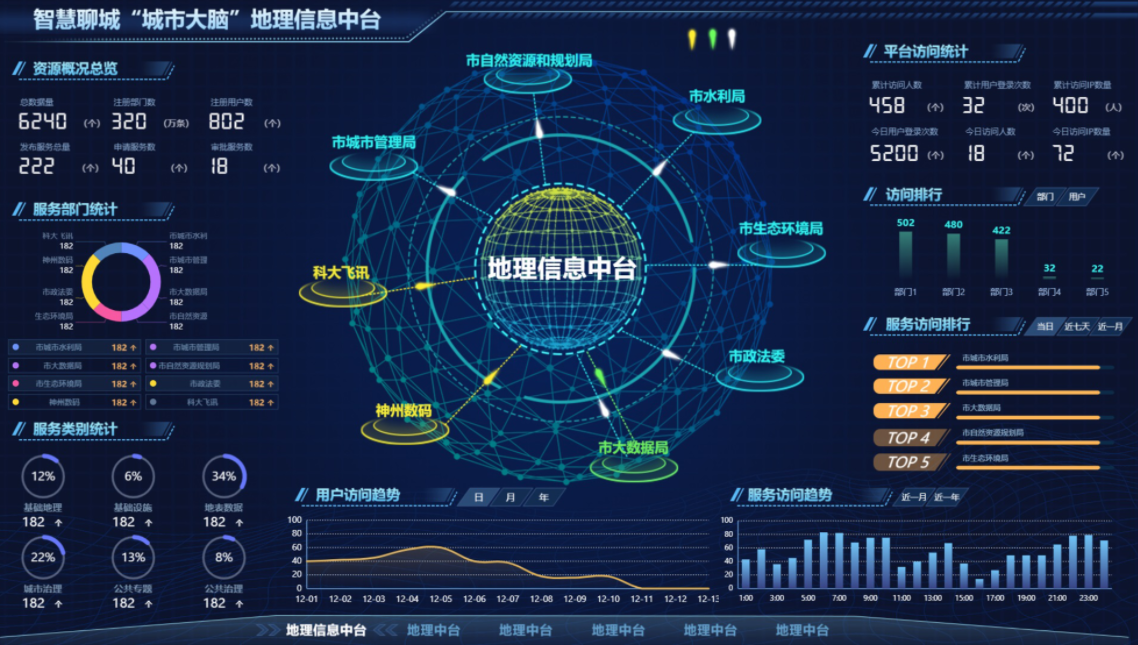
一、什么是数据处理
在数字孪生中,数据处理是指对采集到的实时或历史数据进行整理、清洗、分析和转化的过程。数据处理是数字孪生的基础,它将原始数据转化为有意义的信息,用于模型构建、仿真和决策支持。
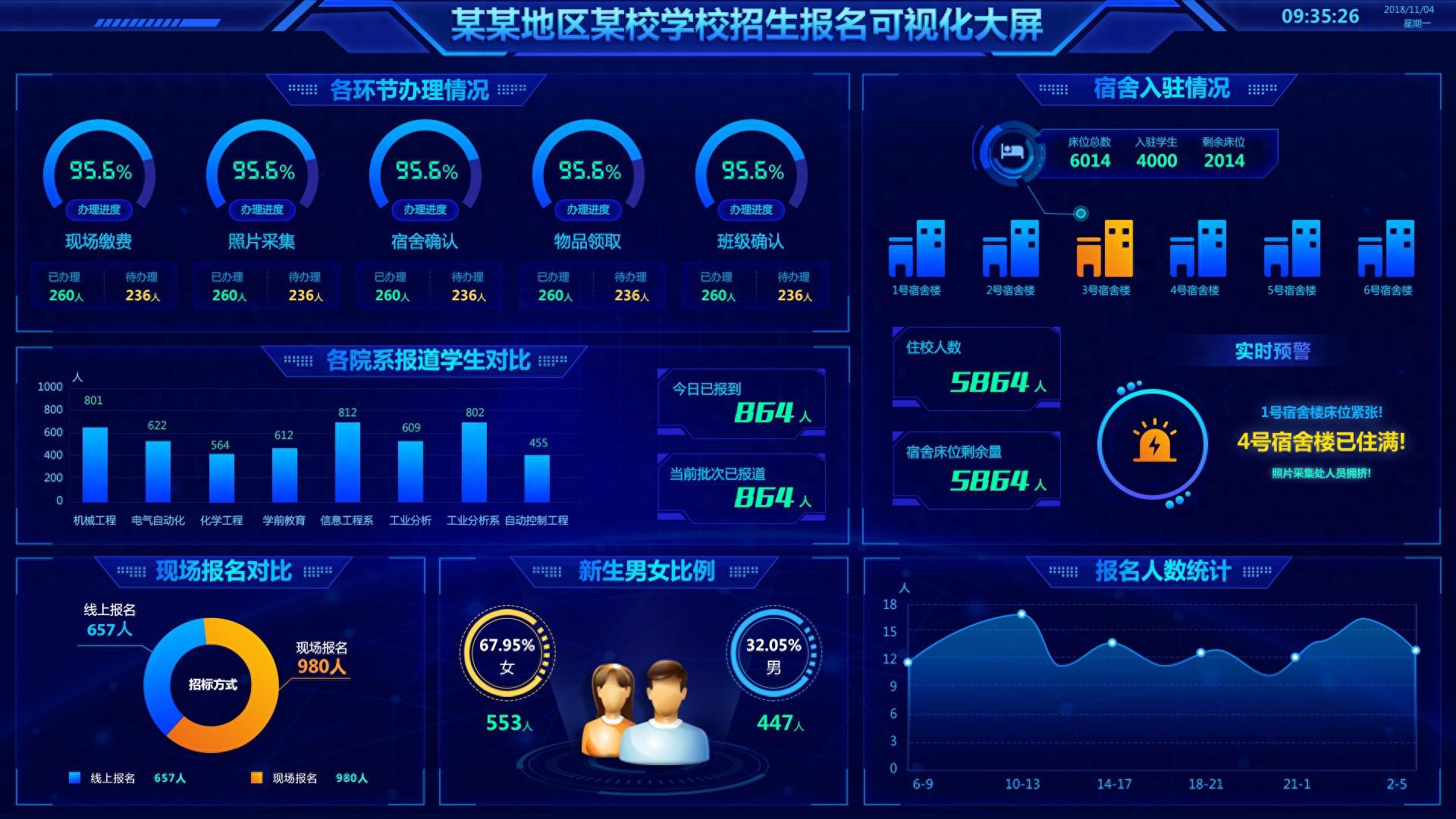
数据处理是为了提高数据质量、整合数据、转换数据、分析数据、展示数据和支持决策等目的而进行的重要步骤。通过数据处理,可以使原始数据更具有可用性和可解释性,为后续的数据分析和应用提供可靠的基础。
二、数据处理的六步骤
数据处理在数字孪生中扮演着重要的角色,它包括以下几个方面:
数据清洗
对采集到的数据进行清洗和预处理,包括去除噪声、填补缺失值、处理异常值等。清洗后的数据更加准确和可靠,有利于后续的分析和建模。
数据集成
将来自不同数据源的数据进行整合和融合,以便于综合分析和建模。数据集成可以涉及数据的转换、映射、合并等操作,确保数据的一致性和完整性。

数据分析
对处理后的数据进行统计分析、机器学习、数据挖掘等方法,提取数据的特征、规律和模式。数据分析可以帮助发现数据背后的隐藏信息和洞察,为数字孪生的建模和仿真提供支持。
数据转化
将分析得到的数据转化为数字孪生模型所需的输入参数或状态变量。这可以包括将数据映射到模型的参数空间、转化为合适的数据格式、进行数据归一化等操作。

数据存储和管理
将处理后的数据进行存储和管理,以便于后续的访问、查询和使用。数据存储可以使用数据库、数据仓库、云存储等技术,确保数据的安全性和可靠性。
数据可视化
将分析得到的数据以可视化的方式呈现,如图表、图形、地图等。数据可视化可以帮助人们更好地理解和解释数据,从中获取洞察和决策支持。

三、数据处理的注意事项
在进行数据处理时,有一些注意事项可以帮助确保数据的准确性和一致性,以及提高数据处理的效率和质量。以下是一些常见的注意事项:
- 数据质量:在进行数据处理之前,需要对数据进行质量检查和清洗。这包括检查数据的完整性、准确性、一致性和合法性,并处理缺失值、重复值和异常值等问题。
- 数据安全:在处理敏感数据时,需要确保数据的安全性和隐私保护。采取适当的安全措施,如数据加密、访问控制和身份验证,以防止未经授权的访问和数据泄露。
- 数据集成:在数据集成过程中,需要确保不同数据源的数据能够正确地整合和融合。这可能涉及到数据转换、映射和合并等操作,需要仔细考虑数据的结构、格式和语义,以避免数据集成错误和不一致性。
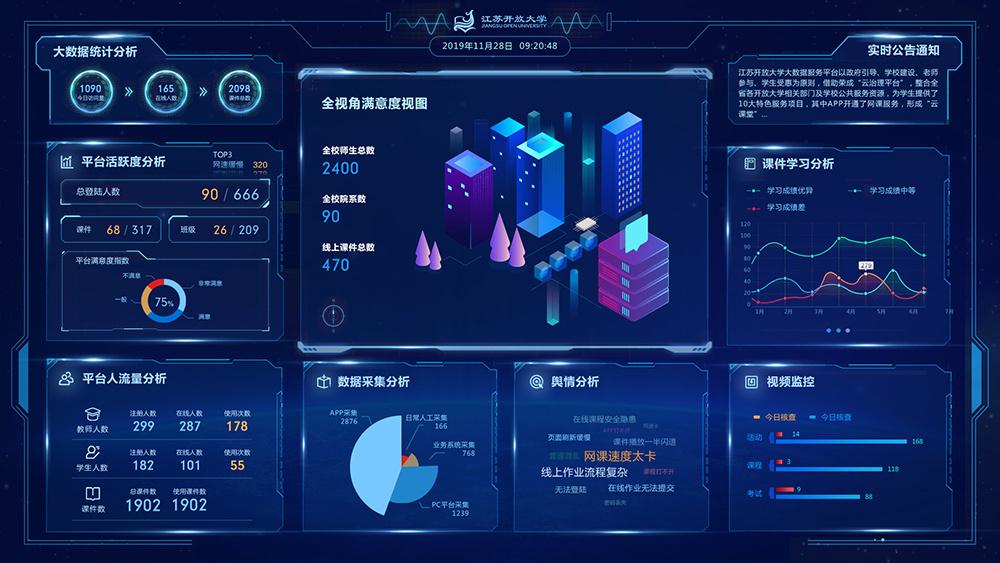
- 数据处理流程:在进行数据处理时,需要建立清晰的数据处理流程和规范。这包括定义数据处理的步骤、方法和工具,以及记录和文档化数据处理的过程和结果。这有助于保持数据处理的一致性和可追溯性。
- 数据备份和恢复:在进行数据处理之前,需要制定数据备份和恢复策略。这包括定期备份数据,以防止数据丢失或损坏,并确保能够快速恢复数据,以便在需要时进行回滚或恢复操作。
- 数据保留和合规性:在进行数据处理时,需要遵守相关的法律法规和行业规定,如数据保护法、隐私法和数据安全标准等。确保数据的合规性和合法性,同时遵循数据保留和销毁的规定。

- 数据验证和验证:在完成数据处理之后,需要对处理后的数据进行验证和验证。这包括对数据进行统计分析、模型评估和可视化,以确保处理结果的准确性和可靠性。
综上所述,数据处理需要综合考虑数据质量、安全性、一致性、流程、备份、合规性等方面的注意事项。通过遵循这些注意事项,可以提高数据处理的效率和质量,并确保数据的可靠性和可用性。
四、数据处理常用工具软件
在数据处理的过程中,可以使用各种技术和软件来完成不同的任务。以下是一些常用的技术和软件:
- 数据清洗和预处理:在数据清洗和预处理阶段,可以使用Python编程语言中的库和工具,如Pandas、NumPy和Scikit-learn。这些库提供了各种功能,如数据清洗、缺失值处理、异常值检测和处理等。
- 数据集成:数据集成涉及到将来自不同数据源的数据整合在一起。在这个过程中,可以使用ETL(Extract, Transform, Load)工具,如Talend、Informatica和Pentaho。这些工具提供了数据抽取、转换和加载的功能,使得数据集成更加高效和方便。

- 数据存储和管理:数据存储和管理可以使用各种数据库管理系统(DBMS),如MySQL、Oracle、SQL Server和MongoDB等。这些DBMS提供了数据的存储、查询和管理功能,可以根据数据的特点和需求选择合适的数据库。
- 数据分析和挖掘:在数据分析和挖掘阶段,可以使用各种统计分析和机器学习的工具和库。例如,Python中的SciPy、StatsModels、Scikit-learn和TensorFlow等库提供了各种统计分析、机器学习和深度学习的功能。
- 数据可视化:数据可视化可以使用各种工具和软件来实现。常用的可视化工具包括Python中的Matplotlib、Seaborn和Plotly库,以及商业化软件如Tableau和Power BI等。这些工具可以生成各种图表、图形和地图,以便更好地展示和解释数据。
除了上述技术和软件,还有许多其他的工具和平台可以用于数据处理,具体选择取决于数据的特点、需求和预算。同时,随着技术的不断发展,新的工具和软件也在不断涌现,为数据处理提供更多的选择和可能性。