📖 前言:在大数据系统的开发中,数据收集工作无疑是开发者首要解决的一个难题,但由于生产数据的源头丰富多样,其中包含网站日志数据、后台监控数据、用户浏览网页数据等,数据工程师要想将它们分门别类的采集到HDFS系统中,就可以使用Apache Flume(数据采集)系统。

目录
- 🕒 1. Flume概述
- 🕒 2. Flume运行机制
- 🕒 3. Flume日志采集系统结构
- 🕒 4. Flume的部署
- 🕒 5. Flume的采集方案
- 🕒 6. Flume的可靠性保证
- 🕒 7. Flume拦截器
🕒 1. Flume概述
Flume原是Cloudera公司提供的一个高可用的、高可靠的、分布式海量日志采集、聚合和传输系统,而后纳入到了Apache旗下,作为一个顶级开源项目。Apache Flume不仅只限于日志数据的采集,由于Flume采集的数据源是可定制的,因此Flume还可用于传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息以及几乎任何可能的数据源。
Flume自发展以来,分为两个版本,分别是Flume 0.9x版本,称为Flume-og(original generation,原始一代)和Flume 1.x版本,称为Flume-ng(next generation,下一代)。Flume-og版本由于早期设计时,存在不易扩展、代码臃肿等一系列问题,在被纳入到Apache软件基金会之后,开发人员便对其代码进行了重构,使Flume更易于使用和扩展,于是便出现了Flume-ng版本,采用三层架构,分别为agent,collector``和storage`,每一层均可以水平扩展。Flume-ng版本在实际开发中应用最为广泛,接下来,主要基于Flume-ng版本对Flume进行讲解。
🕒 2. Flume运行机制
Flume的核心是把数据从数据源(例如Web服务器)通过数据采集器(Source)收集过来,再将收集的数据通过缓冲通道(Channel)汇集到指定的接收器(Sink)。
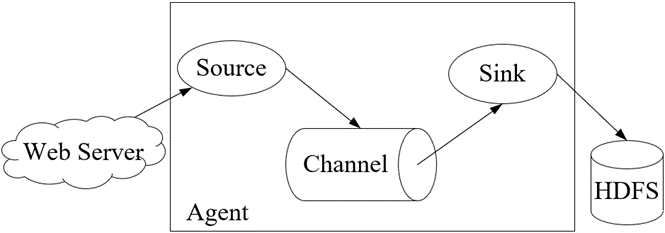
Flume基本架构中有一个Agent(代理),它是Flume的核心角色,Flume Agent是一个JVM进程,它承载着数据从外部源流向下一个目标的三个核心组件:Source、Channel和Sink。
Source:用于采集数据源的数据,并将数据写入到Channel。一个Source可以连接一个或多个Channel。Channel:用于缓存Source写入的数据,并将数据写入到Sink,待Sink将数据写入到存储设备或者下一个Source之后,Flume会删除Channel中缓存的数据。Sink:用于接收Channel写入的数据,并将数据写入到存储设备。
在整个数据传输过程,即Source→Channel→Sink,Flume将流动的数据封装到一个事件(Event)中,它是Flume内部数据传输的基本单元。
🕒 3. Flume日志采集系统结构
在实际开发中, Flume需要采集数据的类型多种多样,同时还会进行不同的中间操作,所以根据具体需求,可以将Flume日志采集系统分为简单结构和复杂结构。
简单结构通常应用于采集数据的数据源单一,数据内容简单,并且采集数据的存储设备单一,这时在Flume日志采集系统中,可以直接使用一个Agent来实现。
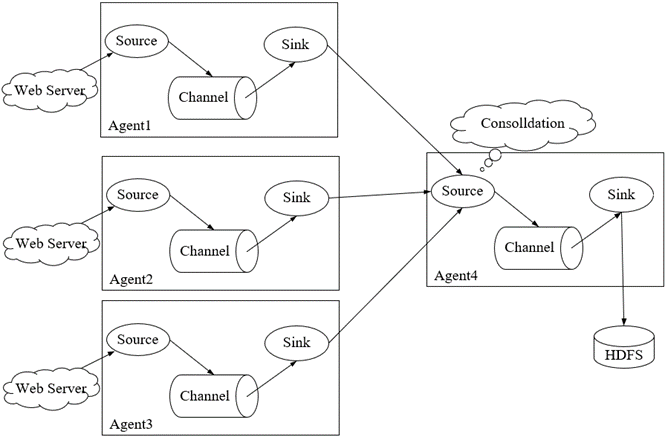
Flume复杂结构–多Agent:在某些实际应用场景中,Flume日志采集系统需要采集数据的数据源分布在不同的服务器上,可以再分配一个Agent来采集其他Agent从Web Server采集的日志,对这些日志进行汇总后写入到存储系统。
🕒 4. Flume的部署
🕘 4.1 安装与配置
在Ubuntu中直接打开网站下载:
🔎 Flume官网
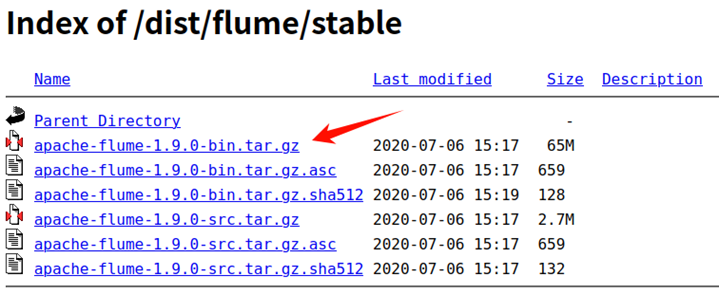
建议下载稳定版本apache-flume-1.9.0-bin.tar.gz
稳定版下载地址:http://archive.apache.org/dist/flume/stable/
1、打开终端,解压安装包至路径 /opt,命令如下:
sudo tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt
2、将解压的文件夹重命名为flume并添加flume的权限
sudo mv apache-flume-1.9.0-bin/ ./flume
sudo chown -R hadoop flume
3、配置环境变量
将flume目录添加到path中,这样,启动flume就无需到/opt/flume目录下,大大的方便了flume的使用。编辑bashrc文件。
vim ~/.bashrc
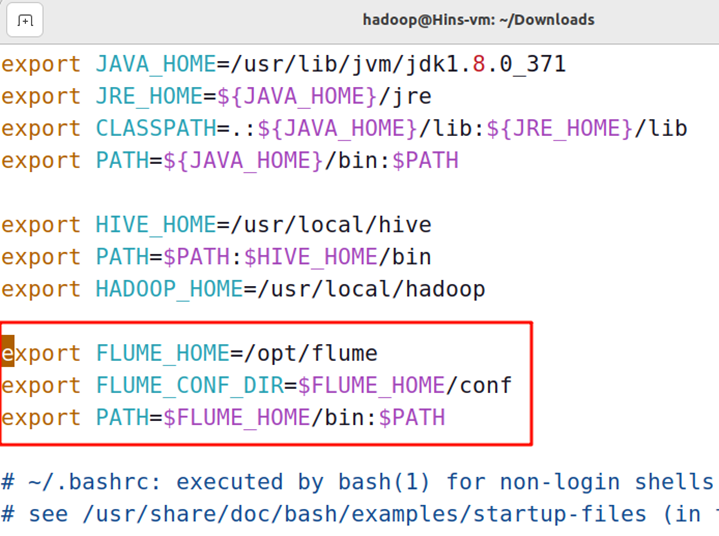
请在bashrc文件中添加如下内容,如果以前添加过JDK请勿重复添加:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export FLUME_HOME=/opt/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$FLUME_HOME/bin:$PATH
4、保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
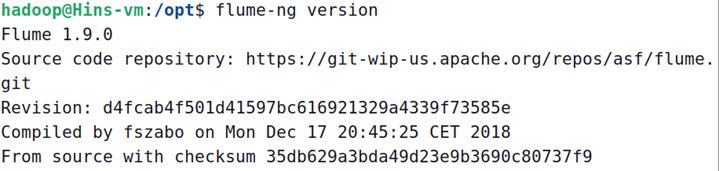
5、启动flume,查看flume版本,确定flume是否安装成功,命令如下:
flume-ng version
🕘 4.2 Flume信息采集实例
1、使用Flume接收来自AvroSource的信息
AvroSource可以发送一个给定的文件到Flume,Flume接收以后可以进行处理后显示到屏幕上。
1)在/opt/flume/conf目录下创建Agent配置文件avro.conf,命令如下。
sudo vim /opt/flume/conf/avro.conf
2)在avro.conf文件中写入如下内容
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.channels=c1
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=4141
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
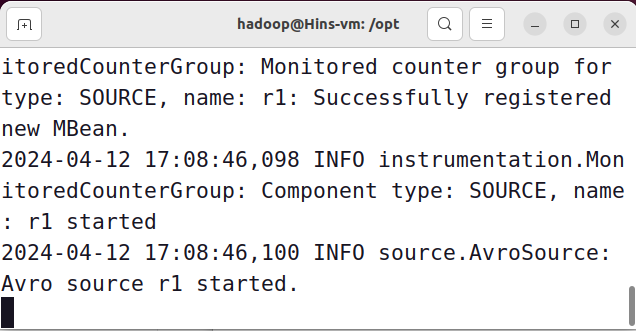
3)启动Flume Agent a1,执行如下命令启动日志控制台
flume-ng agent -c . -f /opt/flume/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
4)打开另外一个Linux终端,在/opt/flume目录下创建一个文件log.01,并在文件中加入一行内容“Hello Flume”,命令如下:
sudo sh -c 'echo "Hello Flume"'> /opt/flume/log.01
5)再打开另外一个Linux终端,执行如下命令:
flume-ng avro-client --conf conf -H localhost -p 4141 -F /opt/flume/log.01
在该命令中,4141是前面文件avro.conf里自定义的端口号。
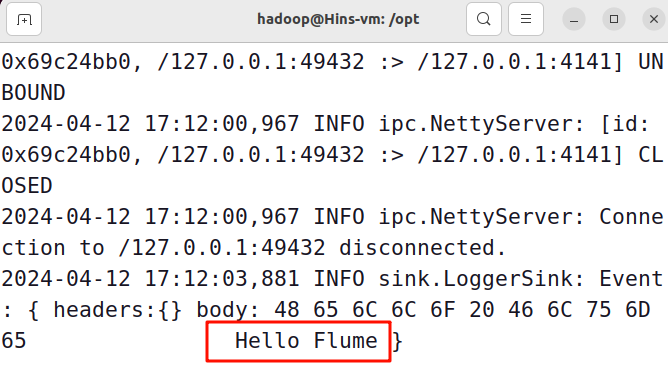
执行该命令后,AvroSource就向Flume发送了一个文件log.01,切换到第3)步的日志控制台端口,就可以看到Flume已经接收到了信息,如下图所示,通过最后一行可以看出Flume已经成功接收到了“Hello Flume”。
2、使用Flume接收来自NetSource的信息
NetcatSource可以把用户实时输入的信息持续不断地发给Flume,Flume处理后可以显示到输出屏幕上。
1)执行如下命令,在/opt/flume/conf目录下新建test.conf代理配置文件,并写入如下内容:
sudo vim /opt/flume/conf/test.conf
写入如下内容:
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444 # 后面会用到该端口号
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
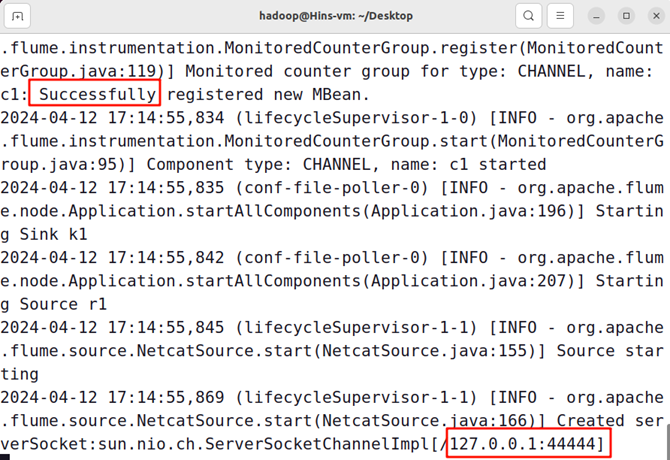
2)执行如下命令启动Flume Agent a1日志控制台
flume-ng agent --conf /opt/flume/conf --conf-file /opt/flume/conf/test.conf --name a1 -Dflume.root.logger=INFO,console
3)再打开一个终端,输入如下命令:
telnet localhost 44444
该命令中的44444是前面自定义的test.conf文件中的端口号。执行后,出现如下图所示信息:

这个终端窗口称为“NetcatSource”终端窗口,在这个终端窗口中可以输入任意字符,该字符会被实时发送到Flume Agent a1,另外一个终端窗口“日志控制台”就会同步显示输入的内容,例如,在“NetcatSource”终端窗口输入“Hello Flume by HinsCoder”,如下图所示。
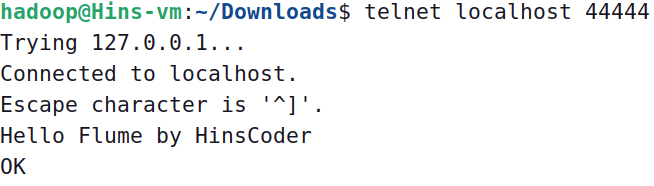
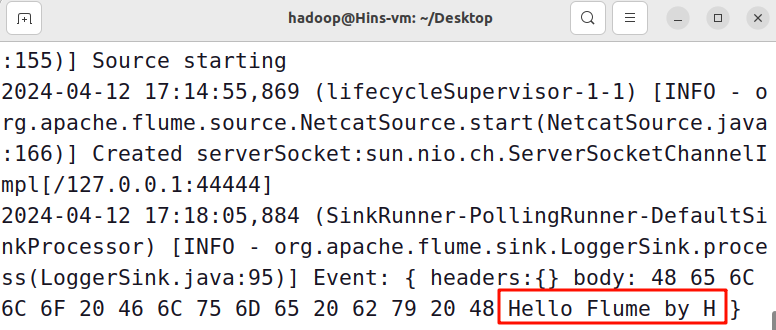
4)日志控制台终端窗口就会同步显示输入的内容,如下图所示。
🕒 5. Flume的采集方案
🕘 5.1 Flume Sources
在编写Flume采集方案时,首先必须明确采集的数据源类型、出处;接着,根据这些信息与Flume已提供支持的Flume Sources进行匹配,选择对应的数据采集器类型(即sources.type);再根据选择的数据采集器类型,配置必要和非必要的数据采集器属性,Flume提供并支持的Flume Sources种类如下所示。
| Avro Source | Thrift Source | Exec Source |
|---|---|---|
| JMS Source | Spooling Directory Source | Twitter 1% firehose Source |
| Kafka Source | NetCat TCP Source | NetCat UDP Source |
| Sequence Generator Source | Syslog TCP Source | Multiport Syslog TCP Source |
| Syslog UDP Source | HTTP Source | Stress Source |
| Avro Legacy Source | Thrift Legacy Source | Custom Source |
| Scribe Source | Taildir Source |
监听Avro端口并从外部Avro客户端流中接收event数据,当与另一个Flume Agent上的Avro Sink配对时,可创建分层集合拓扑,利用Avro Source可以实现多级流动、扇出流、扇入流等效果,Avro Source常用配置属性如下。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channels | – | |
| type | – | 组件类型名需必须是avro |
| bind | – | 要监听的主机名或IP地址 |
| port | – | 要监听的服务端口 |
| threads | – | 要生成的工作线程的最大数目 |
| ssl | FALSE | 将此设置为true以启用SSL加密,则还必须指定“keystore”和“keystore-password” |
| keystore | – | SSL所必需的通往Java秘钥存储路径 |
| keystore-password | – | SSL所必需的Java密钥存储的密码 |
Spooling Directory Source允许对指定磁盘上的文件目录进行监控来提取数据,它将查看文件的指定目录的新增文件,并将文件中的数据读取出来。
Spooling Directory Source常用配置属性如下表所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channels | – | |
| type | – | 组件类型名需必须是spooldir |
| spoolDir | – | 从中读取文件的目录 |
| fileSuffix | .COMPLETED | 附加到完全摄取的文件后缀 |
| deletePolicy | never | 何时删除已完成的文件:never或immediate |
| fileHeader | FALSE | 是否添加存储绝对路径文件名的标头 |
| includePattern | ^.*$ | 正则表达式,指定要包含的文件 |
| ignorePattern | ^$ | 正则表达式指定要忽略的文件 |
Taildir Source用于观察指定的文件,几乎可以实时监测到添加到每个文件的新行。如果文件正在写入新行,则此采集器将重试采集它们以等待写入完成,Source常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channels | – | |
| type | – | 组件类型名需必须是TAILDIR |
| filegroups | – | 以空格分隔的文件组列表 |
| filegroups. | – | 文件组的绝对路径 |
| idleTimeout | 120000 | 关闭非活动文件的时间(毫秒) |
| writePosInterval | 3000 | 写入位置文件上每个文件的最后位置的间隔时间 |
| batchSize | 100 | 一次读取和发送到通道的最大行数 |
| backoffSleepIncrement | 1000 | 当最后一次尝试未找到任何新数据时,每次重新尝试轮询新数据之间的最大时间延迟 |
| fileHeader | FALSE | 是否添加存储绝对路径文件名的标头 |
| fileHeaderKey | file | 将绝对路径文件名附加到event header时使用的header关键字 |
HTTP Source可以通过HTTP POST和GET请求方式接收event数据,GET通常只能用于测试使用,POST请求发送的所有的events都被认为是一个批次,会在一个事务中插入channel,Taildir Source常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channels | – | |
| type | 组件类型名需必须是http | |
| port | – | 采集源要绑定的端口 |
| bind | 0.0.0.0 | 要监听绑定的主机名或IP地址 |
| handler | org.apache.flume.source.http.JSONHandler | handler类的全路径名 |
🕘 5.2 Flume Channels
Channels通道是event在Agent上暂存的存储库,Source向Channel中添加event,Sink在读取完数据后再删除它。在配置Channels时,需要明确的就是将要传输的sources数据源类型;根据这些信息结合开发中的实际需求,选择Flume已提供的支持的Flume Channels;再根据选择的Channel类型,配置必要和非必要的Channel属性,Flume提供并支持的Flume Channels种类如下所示。
| Memory Channel | JDBC Channel | Kafka Channel |
|---|---|---|
| File Channel | Spillable Memory Channel | Pseudo Transaction Channel |
| Custom Channel |
Memory Channel会将event存储在具有可配置最大尺寸的内存队列中,适用于需要更高吞吐量的流量,但在Agent发生故障时会丢失部分阶段数据,下表为Memory Channel常用配置属性。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| type | – | 组件类型名需必须是memory |
| capacity | 100 | 存储在channel中的最大event数 |
| transactionCapacity | 100 | channel从source接收或向sink传递的每个事务中最大event数 |
| keep-alive | 3 | 添加或删除event的超时时间(秒) |
| byteCapacityBufferPercentage | 20 | 定义byteCapacity与channel中所有event所占百分比 |
| byteCapacity | 等于JVM可用的最大内存的80% | 允许此channel中所有event的的最大内存字节数总和 |
File Channel是Flume的持久通道,它将所有event写入磁盘,因此不会丢失进程或机器关机、崩溃时的数据。File Channel通过在一次事务中提交多个event来提高吞吐量,做到了只要事务被提交,那么数据就不会有丢失,File Channel常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| type | – | 组件类型名需必须是file |
| checkpointDir | 1~/.flume/file-channel/checkpoint | 检测点文件所存储的目录 |
| useDualCheckpoints | FALSE | 备份检测点如果设置为true,backupChec kpointDir必须设置 |
| backupCheckpointDir | – | 备份检查点目录。此目录不能与数据目录或检查点目录相同 |
| dataDirs | ~/.flume/file-channel/data | 数据存储所在的目录设置 |
| transactionCapacity | 10000 | 事务容量的最大值设置 |
| checkpointInterval | 30000 | 检测点之间的时间值设置(单位微秒) |
| maxFileSize | 2146435071 | 一个单一日志的最大值设置(以字节为单位) |
| capacity | 1000000 | channel的最大容量 |
| transactionCapacity | 10000 | 事务容量的最大值设置 |
🕘 5.3 Flume Sinks
Flume Soures采集的数据通过Channels通道流向Sink中,此时Sink类似一个集结的递进中心,它需要根据需求进行配置,从而最终选择发送目的地。
配置Sinks时,明确将要传输的数据目的地、结果类型;然后根据实际需求信息,选择Flume已提供支持的Flume Sinks;再根据选择的Sinks类型,配置必要和非必要的Sinks属性。Flume提供并支持的Flume Sinks种类如下所示。
| HDFS Sink | Hive Sink | Logger Sink |
|---|---|---|
| Avro Sink | Thrift Sink | IRC Sink |
| File Roll Sink | Null Sink | HBaseSink |
| AsyncHBase Sink | MorphlineSolr Sink | ElasticSearch Sink |
| Kite Dataset Sink | Kafka Sink | HTTP Sink |
| Custom Sink |
HDFS Sink将event写入Hadoop分布式文件系统(HDFS),它目前支持创建文本和序列文件,以及两种类型的压缩文件,下表为HDFS Sink常用配置属性。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channel | – | |
| type | – | 组件类型名需必须是hdfs |
| hdfs.path | – | HDFS目录路径 |
| hdfs.filePrefix | FlumeData | 为在hdfs目录中由Flume创建的文件指定前缀 |
| hdfs.round | FALSE | 是否应将时间戳向下舍入 |
| hdfs.roundValue | 1 | 舍入到此最高倍数,小于当前时间 |
| hdfs.roundUnit | second | 舍入值的单位 - 秒、分钟或小时 |
| hdfs.rollInterval | 30 | 滚动当前文件之前等待的秒数 |
| hdfs.rollSize | 1024 | 触发滚动的文件大小,以字节为单位 |
| hdfs.rollCount | 10 | 在滚动之前写入文件的事件数 |
Logger Sink用于记录INFO级别event,它通常用于调试。Logger Sink接收器的不同之处是它不需要在“记录原始数据”部分中说明额外的配置,Logger Sink常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channel | – | |
| type | – | 组件类型名需必须是logger |
| maxBytesToLog | 16 | 要记录的event body的最大字节数 |
Avro Sink形成Flume分层收集支持的一半,发送到此接收器的Flume event转换为Avro event,并发送到对应配置的主机名/端口,event将从配置的channel中批量获取配置的批处理大小,Avro Sink常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| channel | – | |
| type | – | 组件类型名需必须是avro |
| hostname | – | 要监听的主机名或IP地址 |
| port | – | 要监听的服务端口 |
| batch-size | 100 | 要一起批量发送的event数 |
| connect-timeout | 20000 | 允许第一次(握手)请求的时间量(ms) |
| request-timeout | 20000 | 在第一个之后允许请求的时间量(ms) |
🕒 6. Flume的可靠性保证
🕘 6.1 负载均衡
配置的采集方案是通过唯一一个Sink作为接收器接收后续需要的数据,但会出现当前Sink故障或数据收集请求量较大的情况,这时单一Sink配置可能就无法保证Flume开发的可靠性。因此,Flume 提供Flume Sink Processors解决上述问题。
Sink处理器允许定义Sink groups,将多个sink分组到一个实体中,Sink处理器就可通过组内多个sink为服务提供负载均衡功能。
负载均衡接收器处理器(Load balancing sink processor)提供了在多个sink上进行负载均衡流量的功能,它维护一个活跃的sink索引列表,需在其上分配负载,还支持round_robin(轮询)和random(随机)选择机制进行流量分配,默认选择机制为round_robin。Load balancing sink processor提供的配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| sinks | – | 以空格分隔的参与sink组的sink列表 |
| processor.type | default | 组件类型名需必须是load_balance |
| processor.backoff | FALSE | 设置失败的sink进入黑名单 |
| processor.selector | round_robin | 选择机制 |
| processor.selector.maxTimeOut | 30000 | 失败sink放置在黑名单的超时时间 |
🕘 6.2 故障转移
故障转移接收器处理器(Failover Sink Processor)维护一个具有优先级的sink列表,保证在处理event时,只需有一个可用的sink即可。
故障转移机制工作原理是将故障的sink降级到故障池中,在池中为它们分配一个冷却期,在重试之前冷却时间会增加,当sink成功发送event后,它将恢复到活跃池中。Failover Sink Processor提供的配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| sinks | – | 以空格分隔的参与sink组的sink列表 |
| processor.type | default | 组件类型名需必须是failover |
| processor.priority. | – | 设置sink的优先级取值 |
| processor.maxpenalty | 30000 | 失败sink的最大退避时间 |
🕒 7. Flume拦截器
Flume Interceptors(拦截器)用于对Flume系统数据流中event的修改操作。使用Flume拦截器时,只需参考官方配置属性在采集方案中选择性的配置即可,当涉及到配置多个拦截器时,拦截器名称间需用空格分隔,且拦截器配置顺序就是拦截顺序。Flume 1.9.0版本中,Flume提供并支持的拦截器有很多,具体如下所示。
| Timestamp Interceptor | Host Interceptor | Static Interceptor |
|---|---|---|
| Remove Header Interceptor | UUID Interceptor | Morphline Interceptor |
| Search and Replace Interceptor | Regex Filtering Interceptor | Regex Extractor Interceptor |
Timestamp Interceptor(时间戳拦截器)将流程执行时间插入到event的header头部,此拦截器插入带有timestamp键的标头,其值为对应时间戳。若配置中已存在时间戳时,此拦截器可保留现有时间戳,Timestamp Interceptor提供的常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| type | – | 组件类型名需必须是timestamp |
| header | timestamp | 用于放置生成的时间戳的标头的名称 |
| preserveExisting | FALSE | 如果时间戳已存在,是否应保留, true或false |
Static Interceptor(静态拦截器)允许用户将具有静态值的静态头附加到所有event。当前不支持一次指定多个header头,但是用户可定义多个Static Interceptor来为每一个拦截器都追加一个header,Static Interceptor提供的常用配置属性如下所示。
| 属性名称 | 默认值 | 相关说明 |
|---|---|---|
| type | – | 组件类型名需必须是static |
| preserveExisting | TRUE | 如果配置的header已存在,是否应保留 |
| key | key | 应创建的header的名称 |
| value | value | 应创建的header对应的静态值 |
OK,以上就是本期知识点“Flume日志采集系统”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~









