文章目录
2. Java基本语法
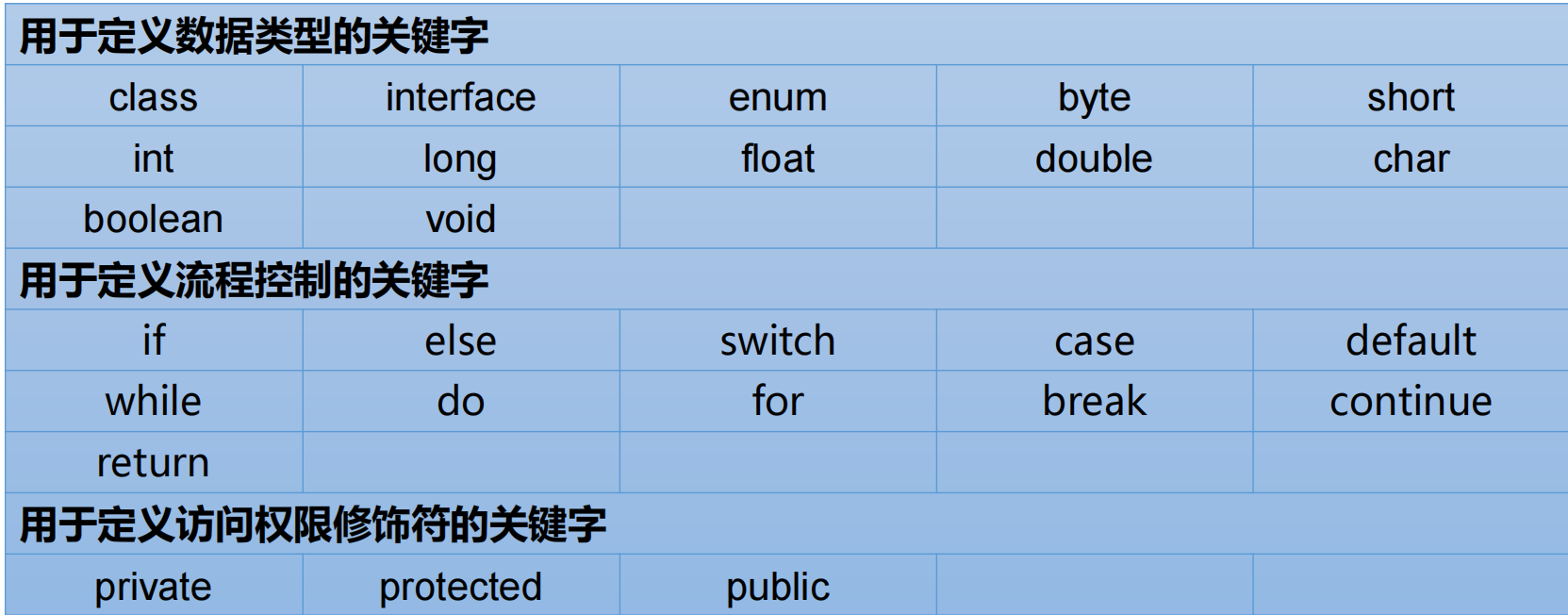
2.1 关键字保留字
2.1.1 关键字
关键字(keyword)的定义和特点
-
定义:被Java语言赋予了特殊含义 ,用做专门用途的字符串
-
特点:关键字中所有字母都为小写
官方地址: https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html

2.1.2 保留字
Java保留字:现有Java版本尚未使用,但以后版本可能会作为关键字使用。自己命名标识符时要避免使用这些保留字goto 、const
2.1.3 标识符
自己定义的名称称为标识符
标识符命名规则:
26英文,0-9,_,或$- 数字不可以开头
- 不可以使用关键字和保留字,
- 严格区分大小写,无长度限制
- 标识符不包含空格
2.1.4 Java中的名称命名规范
Java中的名称命名规范:
-
包名:所有字母都小写:xxxyyyzzz
-
类名、接口名:所有单词的首字母大写:XxxYyyZzz
-
变量名、方法名:第一个单词首字母小写,其余每个单词首字母大写:xxxYyyZzz
-
常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
注意1:在起名字时,为了提高阅读性,要尽量有意义,“见名知意”。
注意2:java采用unicode字符集,因此标识符也可以使用汉字声明,但是不建议使用。
2.2 变量
2.2.1 分类
-
按数据类型分类(八种基本数据类型)

-
按声明位置分类

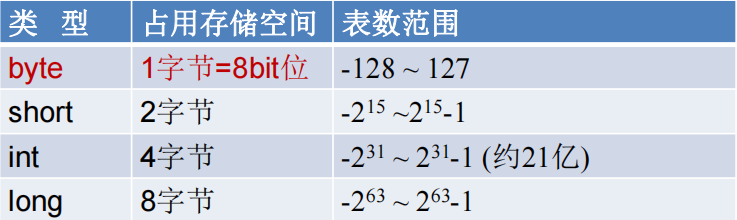
2.2.2 整型变量
-
java程序中变量通常声明为int型,约21亿。更大的数据类型用long
-
java的整型常量默认为 int 型,声明long型常量须后加
l或L不加会报错吗?有时会有时不会,为什么?
2.2.3 浮点型
-
float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
-
double:双精度,精度是float的两倍。通常采用此类型。

-
Java 的浮点型常量默认为double型,声明float型常量,须后加
f或F。 那么在定义float变量时,不加f会报错码,会!
那么问题来了,long定义有时候可以不加l,但float定义就一定要加上f,为什么?因为int到long型数据不会丢失,但double到float类型就会数据丢失!这才是关键,所以说语言设计的真的很妙。
2.2.4 字符型 char
-
Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符(日文等)。
-
直接使用 Unicode 值来表示字符型常量:‘\uXXXX’。其中,XXXX代表一个十六进制整数。如:\u000a 表示 \n。
-
字符型用单引号来赋值,但也可以根据ascll码值进行直接赋值。
如
char c1=97//c1='a' -
char类型是可以进行运算的。因为它都对应有Unicode码。
2.2.5 Unicode编码
-
乱码:世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
-
Unicode:一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,使用 Unicode 没有乱码的问题。
-
Unicode 的缺点:Unicode 只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储:无法区别 Unicode 和 ASCII:计算机无法区分三个字节表示一个符号还是分别表示三个符号。另外,我们知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费。
2.2.6 UTF-8
-
UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。
-
UTF-8 是一种变长的编码方式。它可以使用 1-6 个字节表示一个符号,根据不同的符号而变化字节长度。
-
UTF-8的编码规则:
- 对于单字节的UTF-8编码,该字节的最高位为0,其余7位用来对字符进行编码(等同于ASCII码)。
- 对于多字节的UTF-8编码,如果编码包含 n 个字节,那么第一个字节的前 n 位为1,第一个字节的第 n+1 位为0,该字节的剩余各位用来对字符进行编码。在第一个字节之后的所有的字节,都是最高两位为"10",其余6位用来对字符进行编码
2.2.7 boolean类型
-
boolean类型数据只允许取值true和false。
-
不可以使用0或非 0 的整数替代false和true,这点和C语言不同
-
Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示。———《java虚拟机规范 8版》
-
底层是转化成int类型,占用8个字节。在oracle的java虚拟机中,java语言中的boolean数组被编码为java虚拟机中的字节数组。 每个boolean元素使用8位,1个字节来表示。 java虚拟机中使用1表示真,0表示假,来对boolean进行编码。
-
boolean类型不可以转换为其它的数据类型。
2.3 基本数据类型转换
2.3.1 自动类型转换
数据类型按容量大小排序为

-
有多种类型的数据混合运算时,系统首先自动将所有数据类型转换成容量最大的那种数据类型,然后再进行计算。
-
byte,short,char之间不会相互转换,他们三者在计算时首先转换为int类型。
-
boolean类型不能与其它数据类型运算。
-
当把任何基本数据类型的值和字符串(String)进行连接运算时(+),基本数据类型的值将自动转化为字符串(String)类型。(字符串类型:String。String不是基本数据类型,属于引用数据类型)
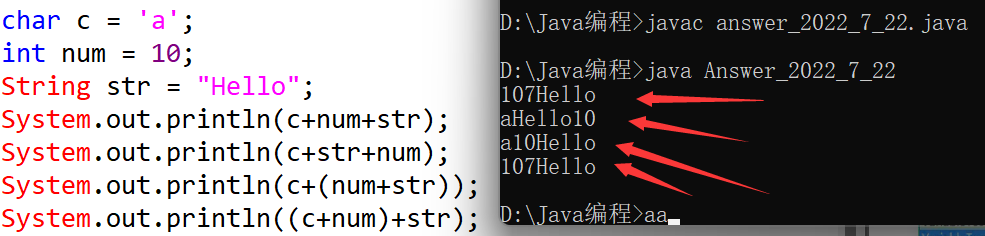
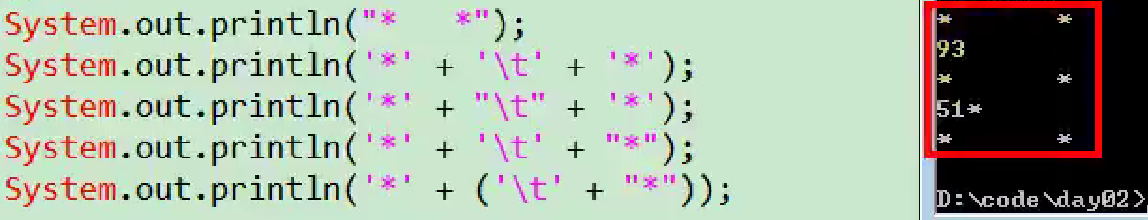
String str2=3.5+"";//合法写法
2.2.2 强制类型转换
自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符:(),但可能造成精度降低或溢出,格外要注意。
-
通常,字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型。 如:
String a = “43”; int i = Integer.parseInt(a); -
boolean类型不可以转换为其它的数据类型。
2.4 进制
-
二进制(binary):0,1 ,满2进1,以0b或0B开头。
-
十进制(decimal):0-9 ,满10进1。
-
**八进制(octal):**0-7 ,满8进1, 以数字0开头表示。
-
**十六进制(hex):**0-9及A-F,满16进1. 以0x或0X开头表示。此处的A-F不区分大小写。如:0x21AF +1= 0X21B0

2.4.1 128强转byte为什么是-128?
数字在计算机底层均用二进制的补码形式存储。下面是求负数的补码基本过程。

128在int(4个字节里面)为00000000 00000000 00000000 100000000
强转为byte类型后,截断取后八位得100000000,但最左边的1在byte类型存储里面表示符号位,表示负数。根据补码的换算即为-128。
2.4.2 为什么数据类型的范围是-2n~2n-1?
这里以byte为例子,最高位为符号位。所以表示数值的位数就是后面七位,最大的就是28-1,也就是127。对于正数,最大值最高位为零,0111 1111,表示127。
但对于最小值(负数)为1000 0000(符号位为1,其余为0表示最小负数)
所以和其他基本数据类型一样,负数范围比正数大1的原因就是-0的存在,所以数据类型的范围是-2n~2n-1。可以说是补码的编码方式决定了范围就是最大值和最小值的绝对值相差1。
-
那么为什么要使用原码、反码、补码表示形式呢?
2.4.3 进制之间转换
首先二进制和十进制之间的转换:注意符号位,和数据存储形式位补码!

而八进制和二进制,十六进制和二进制之间的转换类似。二进制转换成八进制,三位一看。二进制转换成十六进制,四位一看。反过来八进制和十六进制转换为二进制也是如此,三位和四位一看
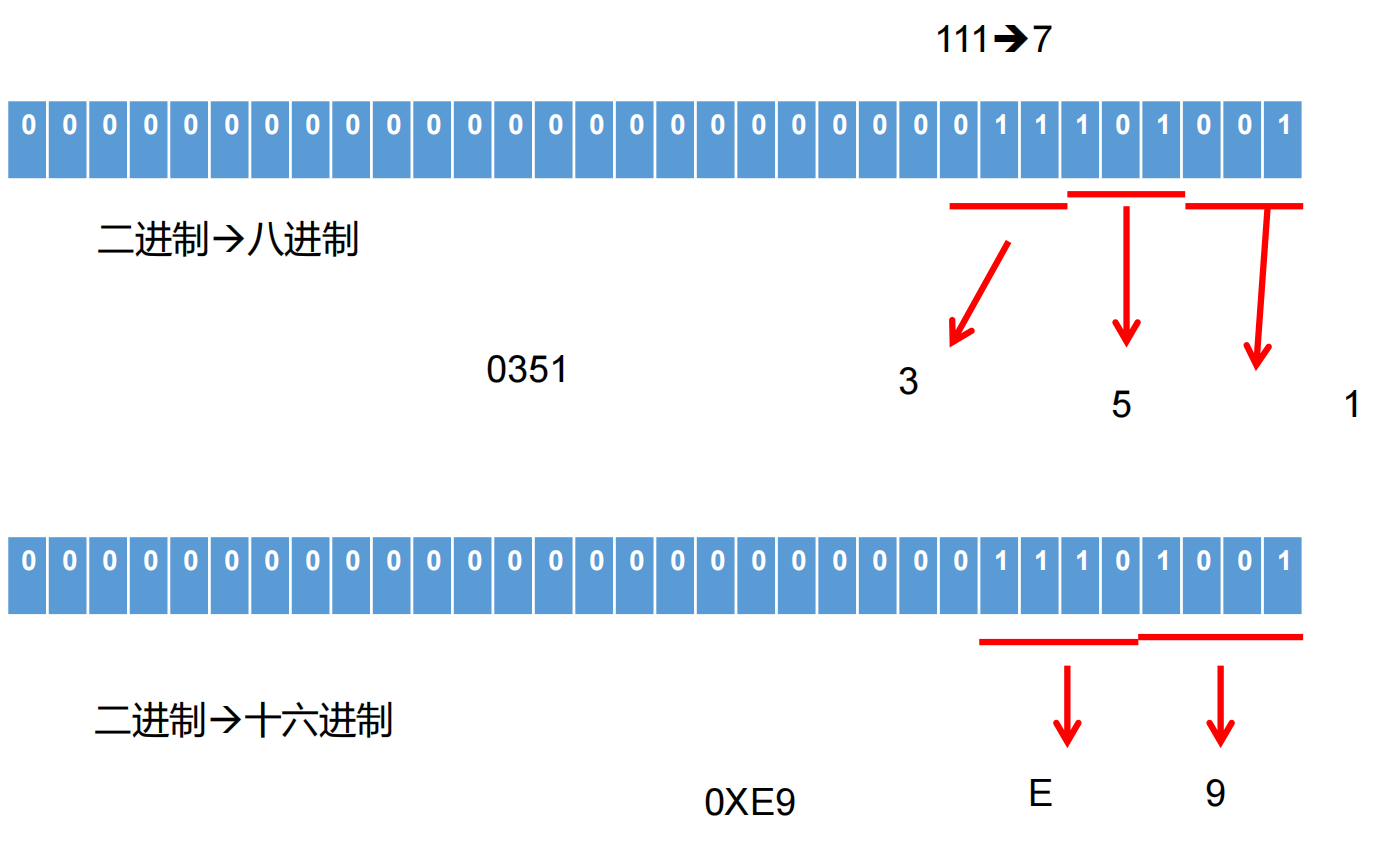
而二进制,八进制,十进制,十六进制之间的转换,我们可以统一转换成二进制再进行转换。
在java中提供的进制转换的方法:
- toBinaryString(int n)
- toOctalString(int n )
- toHexString(int n )
2.5.运算符
2.5.1 算术运算符
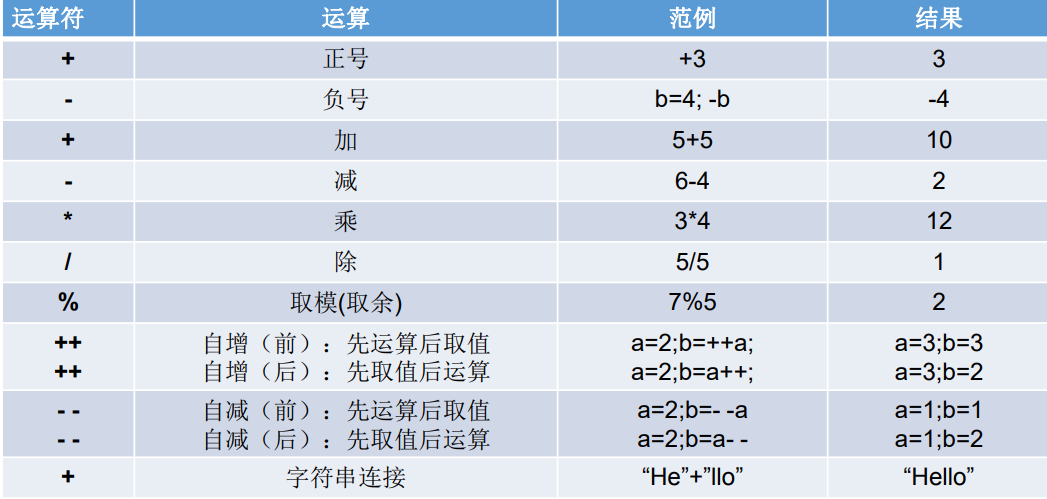
-
求余运算符
结果符号与被模数的符号是相同的(前面的那个)并且求余是允许浮点数求余的。

-
自增自减
-
java编译器只能做自动类型提升,强制类型转换需显示说明。另外整型常量默认为int,浮点型常量默认为double类型。下面是错误例子:

-
第二个,了解本质,判断数据溢出的问题

b1在底层是01111111,加以后为10000000,即为-128。
-
值得注意,后置自增自减和C++一样返回的临时变量,不容许修改!所以b++++;是不被允许的。因为前面的b++放回临时变量,临时变量++不被允许。
-
2.5.2 赋值运算符
byte b1=10;
b1+=2;//+=不改变数据类型
这样的写法是正确的!b1=b1+1;还是有区别的。
//对变量加1操作
byte b=5;
//方法一 b++;
//方法二 b+=1; 推荐写法
//方法三 b=byte(b+1); 这种写法注意强制类型转换需要显示转换
//在java中对变量的修改,如对变量b加2操作
byte a=5;
//方法一 a=a+2;错误写法,只有int类型这么些是对的
//方法二 a+=2; 推荐写法
//方法三 a++++; 错误写法,临时变量不容许修改
综上所述,+=、-=是修改变量值的推荐写法
例子思考



2.5.3 比较运算符
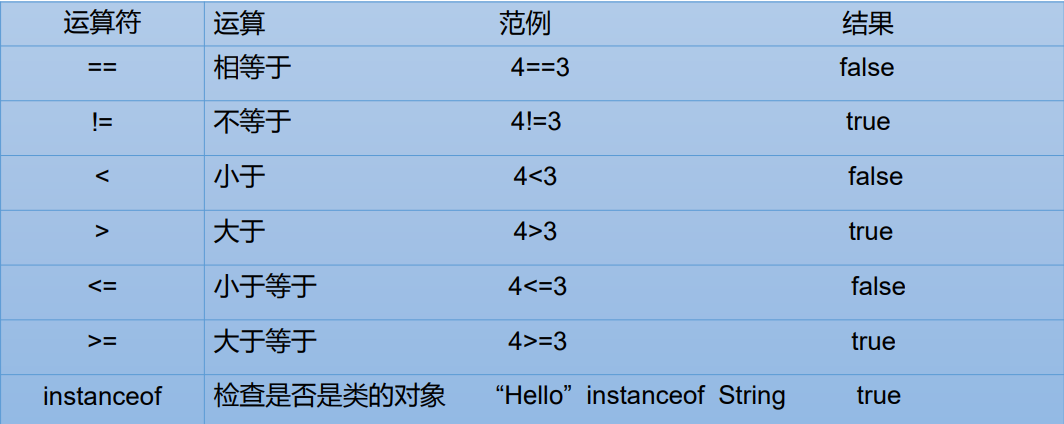
比较运算符结果都是boolean值,只有true和false
2.5.4 逻辑运算符
&逻辑与 |逻辑或 !逻辑非 ^ 逻辑异或
&& 短路与 || 短路或

逻辑与和短路与的区别是什么?

首先结果的逻辑值来说是没有区别的,逻辑与和短路与操作实际上均为与操作,但由于判断的时候自左向右,当前面出现false,那么就是结果就是false。逻辑与就是计算完所有式子。而短路与则是后面的语句便不再执行。所以就出现了m2数值没有发生变化的情况。
逻辑或和短路或的区别?
类似短路或和逻辑或,短路或遇到true便不再计算后面的式子。

2.5.5 位运算符
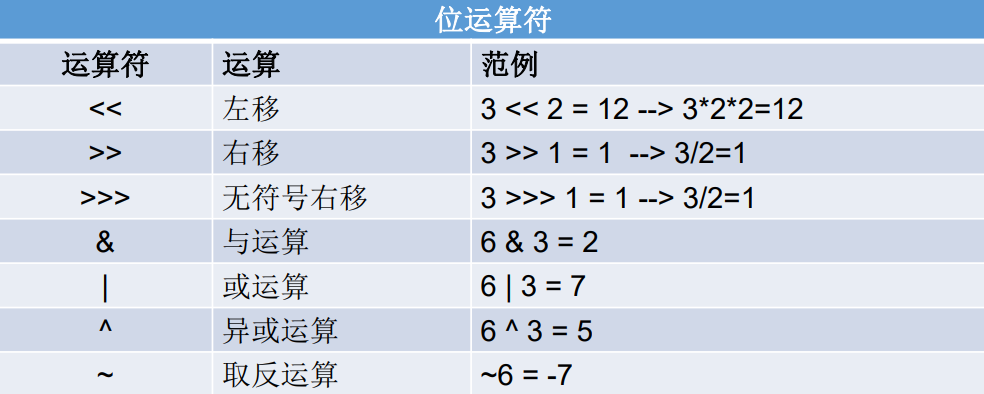

<<:左移,将数的二进制左移指定的位数,低位补0。<<<:在Java中并没有<<<操作符,这是一个错误的表达方式。(因为只有右移才涉及符号问题,左移没有这方面的需求)>>:右移,将数的二进制右移指定的位数,高位补符号位(即最高位的值保持不变)。>>>:无符号右移,将数的二进制右移指定的位数,高位位补0。
需要注意的是,位移操作符只能用于整数类型的数据,包括 byte、short、int、long 和对应的包装类。对于负数,带符号右移操作符 >> 会在高位补符号位,而无符号右移操作符 >>> 会在高位补0。因此,在使用位移操作符时,需要考虑符号位对结果的影响。
2.5.6 三元运算符

int a=(m1>m2)?2.0:2;
//错误: 不兼容的类型: 从double转换到int可能会有损失
double b=(m1>m2)?2.0:2;
//自动类型提升,正确
此外三元运算符是允许嵌套的!但可读性差些。
string b=(m1>m2)?"m1大":((m1==m2)?"m1和m2一样大":"m2大");
凡是能使用三目运算符的都可以改写成ifelse,如果程序既可以使用三目运算符又能使用ifelse,推荐使用三元运算符,特别是方法内return+三目运算符,很简练
2.5.7 运算符的优先级和结合性
结合性:**只有单目运算符、三元运算符、 赋值运算符是从右向左运算的。**所以像加减等二目运算符都是从左向右的。
优先级: 运算符有不同的优先级,所谓优先级就是表达式运算中的运算顺序。如右表,上一行运算 符总优先于下一行。

2.6程序流程控制
2.6.1 顺序结构
2.6.2 分支结构
-
ifelse语句细节:
- if和else之间的是不允许出现其他的句式

- if语句中括号中要求是boolean类型
-
switch语句细节:
- switch括号中要求是以下六种数据类型常量:byte、short、char、int、枚举类型(JDK5.0新增)、String类型(JDK7.0新增)
- default子句是可任选的,位置也是灵活的。当没有匹配的case时, 执行default。因为switch语句是分支结构,按括号内的常量决定执行的语句是什么。但注意一般我们将default放在最后我们可以不加break,因为是最后一个语句了。但是如果我们将default放在语段中间,那么就要加上break了,因为如果default满足,他会一直向下执行的!
2.6.3 循环结构
-
for循环结构
求最大公约数的方法有循环遍历,但有个更加好的方法:
//辗转相除法:求a和b的最大公约数等价于求b与a%b的最大公约数 //若m,n为两个正整数,则 //1、当m>n时,m和n和最大公约数等于n与m%n的最大公约数; //2、当n=0时,m与n的最大公约数等于m;//两个数中一个为零,另一个数(大数)就是最大公约数 //简而言之:(A>B)A和B的最大公约数等于B和A%B的最大公约数(此时B>A%B) int gcd(int a,int b)//a>b { return a%b==0?b:gcd(b,a%b); } -
while语句和dowhile语句很简单,不在此描述
2.6.4 用Scanner类来获取键盘中的信息
- 导包:
import java.util.Scanner; - Scanner类实例化:
Scanner scan=new Scanner(System.in); - 调用Scanner类的相关方法,来获取所指定类型的变量。
注意Scanner没有提供提取char类型的数据,可以通过nextString来进行。
如果输入的数据和函数类型不匹配且不满足自动类型提升要求,那么就会报错:java.util.InputMismatchException
2.6.5 Math.random() 随机数生成
利用Math类提供的函数

Math.random()返回一个正值double类型,范围是[0.0-1.0)

//对于生成一个[min,max]的随机数
int num=(int)(Math.random()*(max-min+1)+min);
//math.random()*(max-min+1)+min范围是[min,max+1),取整后即[min,max]
//熟练记下,其中是否加1以及加1位置的关键在于目标范围左右边界是否取得到,灵活变化!
2.6.6 输出0~100质数
这里先讲讲计算时间的函数currentTimeMilles():返回距离1970年一月一日 零时零分零秒的毫秒数(long类型)

方法一:循环遍历用质数的定义,符合条件就输出。但算法不优,可以用上面计算时间的函数观察与下面方法的区别
//方法一:
Boolean isFlag=true;
long start=System.currentTimeMillis();
for(int i=2;i<=10000;i++){
for(int j=2;j<i & isFlag;j++){
if(i%j==0)isFlag=false;//如果有一个整除,说明不是质数
}
if(isFlag)System.out.println(i);
isFlag=true;
}
long end=System.currentTimeMillis();
System.out.println("time : "+(end-start));
//time : 73
方法二: 优化算法
- 循环中只要找到一个因数,就break
- 判断i是否是质数,只需要计算到根号i即可。怎么理解呢?如果存在比根号i大的数字被整除,那么对应的一定会有一个数小于根号i也被整除,所以只需要检测到根号i即可。
Boolean isFlag=true;
long start=System.currentTimeMillis();
for(int i=2;i<=10000;i++)
{
//优化2:Math.sqrt(i),只需要计算到根号i即可!理解哦
for(int j=2;j<Math.sqrt(i);j++)
{
if(i%j==0)
{
isFlag=false;//如果有一个整除,说明不是质数
break;//优化一,发现一个因数就推出
}
}
if(isFlag)System.out.println(i);
isFlag=true;
}
long end=System.currentTimeMillis();
System.out.println("time : "+(end-start));
//time : 6
方法三:用到continue,代码简略些,但不如遍历来的快
long start=System.currentTimeMillis();
label:for(int i=2;i<=100000;i++)
{
//优化2:Math.sqrt(i),只需要计算到根号i即可!整除一定是成对出现的,理解哦
for(int j=2;j<Math.sqrt(i);j++)
{
if(i%j==0)
{
continue label;
}
}
System.out.println(i);
}
long end=System.currentTimeMillis();
System.out.println("time : "+(end-start));
//time:22
2.6.7 break的使用
-
break语句用于终止当前循环体的执行
{... break; } -
break语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是 哪一层语句块(如果没有标签,结束的是当次循环)
label1: { …… label2: { …… label3: { …… break label2;//结束指定标识的语句块 …… } } }
8.continue的使用
- continue只能使用在循环结构中
- continue语句用于跳过其所在循环语句块的一次执行,继续下一次循环
- continue语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环
label1:for(;;){ ……
label2:for(;;){ ……
label3:for(;;){ ……
continue label2;//结束指定标识的一层循环
//意思就是如果执行党该语句,下一步就跳到label2对应的位置再次进入循环,懂吧?
……
}
}
}
9.return的使用
结束方法+返回数据










