train阶段就是正常的学习
validation是知道正确答案是啥,检查正确率
test是不知道正确答案是啥,看看有啥结果
训练的时候记得model.train
测试(后面两种都是)的时候要model.eval
(有些模型两种阶段做的事不一样)
测试的时候记得with torch.no_grad(),一来省算力,一来防止自己学起来了
save,load
数据处理
生成式的神经网络就是要网络生成一系列结果,让这个结果与已有的数据对比,确保他们相似度高,不会出现离谱的结果。用G代表生成网络,D代表鉴别器网络
其实就是gan(生成对抗网络)分为生成器与鉴别器。生成器会产生“假数据”,鉴别器需要对比真假数据,看出他们是真是假(也就是看出他们的解空间的差异,李宏毅老师所讲的divergence)
“
这是一个生成器和判别器博弈的过程。生成器生成假数据,然后将生成的假数据和真数据都输入判别器,判别器要判断出哪些是真的哪些是假的。判别器第一次判别出来的肯定有很大的误差,然后我们根据误差来优化判别器。现在判别器水平提高了,生成器生成的数据很难再骗过判别器了,所以我们得反过来优化生成器,之后生成器水平提高了,然后反过来继续训练判别器,判别器水平又提高了,再反过来训练生成器,就这样循环往复,直到达到纳什均衡。
”
LG=H(1,D(G(z)))
这是生成网络的损失函数。z是随机输入的x,H()是判断二者距离,1代表真
可见生成网络的目标就是让D尽量以为自己是真的(与数据集相近的)
LD=H(1,D(x))+H(0,D(G(z)))
这是判别网络的损失函数,0代表假。D(x)是鉴别器对真实数据的结果。
可见生成网络要尽量做到看出真的,认出假的。可以发现这其实就是一个二元分类器的经典loss函数。
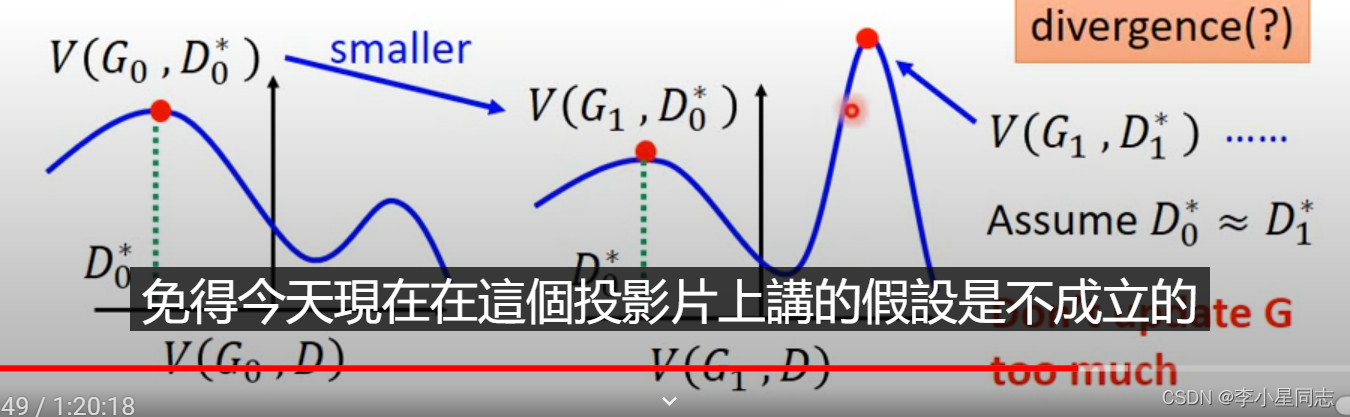
可以看到,在训练(更新)D的时候要练到底,保证找到最大的divergence(差别),确认了这个G最大有多大的问题后,再更新G,这个G就不能更新太多次了,因为G变化太大可能导致D难以辨别,对应的原来那个点可能就不是divergence最大的那个点了。如图: