Spark 键值对 RDD
Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。例如,PairRDD提供了reduceByKey()方法,可以分别规约每个键对应的数据,还有join()方法,可以把两个RDD中键相同的元素组合在一起,合并为一个RDD。
如何创建键值对RDD
在Spark中有许多创建pairRDD的方式,很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的pairRDD。此外当需要把一个普通RDD转换为pairRDD时,可以调用map()函数。
Scala
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
Java
JavaRDD<String> lines = sc.textFile("data.txt");
JavaPairRDD<String, Integer> pairs = lines.mapToPair(s -> new Tuple2(s, 1));
JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
Python
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
常见的键值对RDD操作
常用的键值对转换操作包括reduceByKey()、groupByKey()、sortByKey()、join()、cogroup()等,下面我们通过实例来介绍。
reduceByKey(func)
合并具有相同键的值
Scala
scala> val pairs = sc.parallelize(List((1,2),(3,4),(3,6)))
pairs: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[7] at parallelize at <console>:29
scala> val pair = pairs.reduceByKey((x,y)=>x+y)
pair: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[9] at reduceByKey at <console>:30
scala> println(pair.collect().mkString(","))
(1,2),(3,10)
Python
>>> list = ['Hadoop','Spark','Hive','Hadoop','Kafka','Hive','Hadoop']
>>> rdd = sc.parallelize(list)
>>> pairRDD = rdd.map(lambda word:(word,1))
>>> pairRDD.reduceByKey(lambda a,b:a+b).foreach(print)
[Stage 0:> (0 + 4) / 4]('Kafka', 1)
('Spark', 1)
('Hadoop', 3)
('Hive', 2)
groupBykey()
对具有相同键的值进行分组
Scala
scala> val pair = pairs.groupByKey()
pair: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[10] at groupByKey at <console>:30
scala> println(pair.collect().mkString(","))
(1,CompactBuffer(2)),(3,CompactBuffer(4, 6))
pairRDD.mapValues() :对pairRDD中每个值应用一个函数而不改变键,此时值只能是单个值
scala> val pair = pairs.mapValues(x =>x+1)
pair: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[11] at mapValues at <console>:30
scala> println(pair.collect().mkString(","))
(1,3),(3,5),(3,7)
Python
>>> pairRDD.groupByKey()
PythonRDD[10] at RDD at PythonRDD.scala:48
>>> pairRDD.groupByKey().foreach(print)
('Spark', <pyspark.resultiterable.ResultIterable object at 0x7fcbd6448a58>)
('Hive', <pyspark.resultiterable.ResultIterable object at 0x7fcbcb74d9b0>)
('Hadoop', <pyspark.resultiterable.ResultIterable object at 0x7fcbcb74d9b0>)
('Kafka', <pyspark.resultiterable.ResultIterable object at 0x7fcbcb74dba8>)
>>>
flatMapValues(func)
对pairRDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值的键值对记录,通常用于符号化。
scala> val pair = pairs.flatMapValues(x =>(x to 5))
pair: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[12] at flatMapValues at <console>:30
scala> println(pair.collect().mkString(","))
(1,2),(1,3),(1,4),(1,5),(3,4),(3,5)
pairRDD.keys: 返回一个仅包含键的RDD
scala> val pair = pairs.keys
pair: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[13] at keys at <console>:30
scala> println(pair.collect().mkString(","))
pairRDD.values :返回一个仅包含值的RDD
scala> val pair = pairs.values
pair: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[14] at values at <console>:30
scala> println(pair.collect().mkString(","))
2,4,6
sortByKey()
返回一个根据键排序的RDD
scala> val pair = pairs.sortByKey()
pair: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[17] at sortByKey at <console>:30
scala> println(pair.collect().mkString(","))
(1,2),(3,4),(3,6)
对两个RDD的转化操作
假设 pars = {(1,2),(3,4),(3,6)} ,other={(3,9)}
pairRDD.subtractByKey(other)
删掉pairRDD中键与otherRDD中的键相同的元素
scala> val pair = pairs.subtractByKey(other)
pair: org.apache.spark.rdd.RDD[(Int, Int)] = SubtractedRDD[19] at subtractByKey at <console>:32
scala> println(pair.collect().mkString(","))
(1,2)
join(other)
对两个RDD进行内连接
scala> val pair = pairs.join(other)
pair: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[22] at join at <console>:32
scala> println(pair.collect().mkString(","))
(3,(4,9)),(3,(6,9))
pairRDD.rightOuterJoin(other)
对两个RDD进行连接操作,确保第一个RDD的键存在(右外连接)
scala> val pair = pairs.rightOuterJoin(other)
pair: org.apache.spark.rdd.RDD[(Int, (Option[Int], Int))] = MapPartitionsRDD[25] at rightOuterJoin at <console>:32
scala> println(pair.collect().mkString(","))
(3,(Some(4),9)),(3,(Some(6),9))
leftOuterJoin(other)
对两个RDD进行连接操作,确保第二个RDD的键必须存在(左外连接)
scala> val pair = pairs.leftOuterJoin(other)
pair: org.apache.spark.rdd.RDD[(Int, (Int, Option[Int]))] = MapPartitionsRDD[28] at leftOuterJoin at <console>:32
scala> println(pair.collect().mkString(","))
(1,(2,None)),(3,(4,Some(9))),(3,(6,Some(9)))
pairRDD.cogroup :将两个RDD中拥有相同键的数据分组到一起
scala> val pair = pairs.cogroup(other)
pair: org.apache.spark.rdd.RDD[(Int, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[30] at cogroup at <console>:32
scala> println(pair.collect().mkString(","))
(1,(CompactBuffer(2),CompactBuffer())),(3,(CompactBuffer(4, 6),CompactBuffer(9)))
键值对RDD的转化操作汇总
基本RDD转化操作在此同样适用。但因为键值对RDD中包含的是一个个二元组,所以需要传递的函数会由原来的操作单个元素改为操作二元组。
下表总结了针对单个键值对RDD的转化操作,以 { (1,2) , (3,4) , (3,6) } 为例,f表示传入的函数。
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| reduceByKey(f) | 合并具有相同key的值 | rdd.reduceByKey( ( x,y) => x+y ) | { (1,2) , (3,10) } |
| groupByKey() | 对具有相同key的值分组 | rdd.groupByKey() | { (1,2) , (3, [4,6] ) } |
| mapValues(f) | 对键值对中的每个值(value)应用一个函数,但不改变键(key) | rdd.mapValues(x => x+1) | { (1,3) , (3,5) , (3,7) } |
| combineBy Key( createCombiner, mergeValue, mergeCombiners, partitioner) | 使用不同的返回类型合并具有相同键的值 | 下面有详细讲解 | - |
| flatMapValues(f) | 对键值对RDD中每个值应用返回一个迭代器的函数,然后对每个元素生成一个对应的键值对。常用语符号化 | rdd.flatMapValues(x => ( x to 5 )) | { (1, 2) , (1, 3) , (1, 4) , (1, 5) , (3, 4) , (3, 5) } |
| keys() | 获取所有key | rdd.keys() | {1,3,3} |
| values() | 获取所有value | rdd.values() | {2,4,6} |
| sortByKey() | 根据key排序 | rdd.sortByKey() | { (1,2) , (3,4) , (3,6) } |
下表总结了针对两个键值对RDD的转化操作,以rdd1 = { (1,2) , (3,4) , (3,6) }, rdd2 = { (3,9) } 为例。
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| subtractByKey | 删掉rdd1中与rdd2的key相同的元素 | rdd1.subtractByKey(rdd2) | { (1,2) } |
| join | 内连接 | rdd1.join(rdd2) | {(3, (4, 9)), (3, (6, 9))} |
| leftOuterJoin | 左外链接 | rdd1.leftOuterJoin (rdd2) | {(3,( Some( 4), 9)), (3,( Some( 6), 9))} |
| rightOuterJoin | 右外链接 | rdd1.rightOuterJoin(rdd2) | {(1,( 2, None)), (3, (4, Some( 9))), (3, (6, Some( 9)))} |
| cogroup | 将两个RDD钟相同key的数据分组到一起 | rdd1.cogroup(rdd2) | {(1,([ 2],[])), (3, ([4, 6],[ 9]))} |
combineByKey
combineByKey( createCombiner, mergeValue, mergeCombiners, partitioner,mapSideCombine)
combineByKey( createCombiner, mergeValue, mergeCombiners, partitioner)
combineByKey( createCombiner, mergeValue, mergeCombiners)
函数功能
聚合各分区的元素,而每个元素都是二元组。功能与基础RDD函数aggregate()差不多,可让用户返回与输入数据类型不同的返回值。
combineByKey函数的每个参数分别对应聚合操作的各个阶段。所以,理解此函数对Spark如何操作RDD会有很大帮助。
参数解析
createCombiner:分区内 创建组合函数
mergeValue:分区内 合并值函数
mergeCombiners:多分区 合并组合器函数
partitioner:自定义分区数,默认为HashPartitioner
mapSideCombine:是否在map端进行Combine操作,默认为true
工作流程
- combineByKey会遍历分区中的所有元素,因此每个元素的key要么没遇到过,要么和之前某个元素的key相同。
- 如果这是一个新的元素,函数会调用createCombiner创建那个key对应的累加器初始值。
- 如果这是一个在处理当前分区之前已经遇到的key,会调用mergeCombiners把该key累加器对应的当前value与这个新的value合并。
代码例子
//统计男女个数
val conf = new SparkConf ().setMaster ("local").setAppName ("app_1")
val sc = new SparkContext (conf)
val people = List(("男", "李四"), ("男", "张三"), ("女", "韩梅梅"), ("女", "李思思"), ("男", "马云"))
val rdd = sc.parallelize(people,2)
val result = rdd.combineByKey(
(x: String) => (List(x), 1), //createCombiner
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1), //mergeValue
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2)) //mergeCombiners
result.foreach(println)
//代码输出结果
(男, ( List( 张三, 李四, 马云),3 ) )
(女, ( List( 李思思, 韩梅梅),2 ) )
流程分解
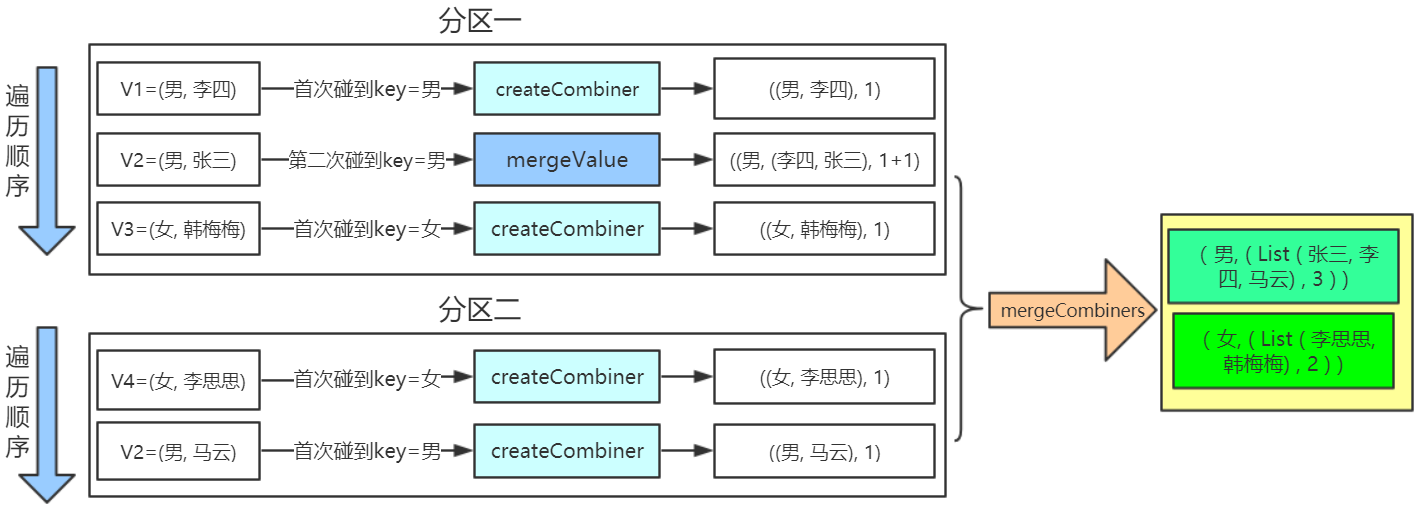
解析:两个分区,分区一按顺序V1、V2、V3遍历
V1,发现第一个key=男时,调用createCombiner,即
(x: String) => (List(x), 1)
V2,第二次碰到key=男的元素,调用mergeValue,即
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1)
V3,发现第一个key=女,继续调用createCombiner,即
(x: String) => (List(x), 1)
… …
待各V1、V2分区都计算完后,数据进行混洗,调用mergeCombiners,即
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2))










