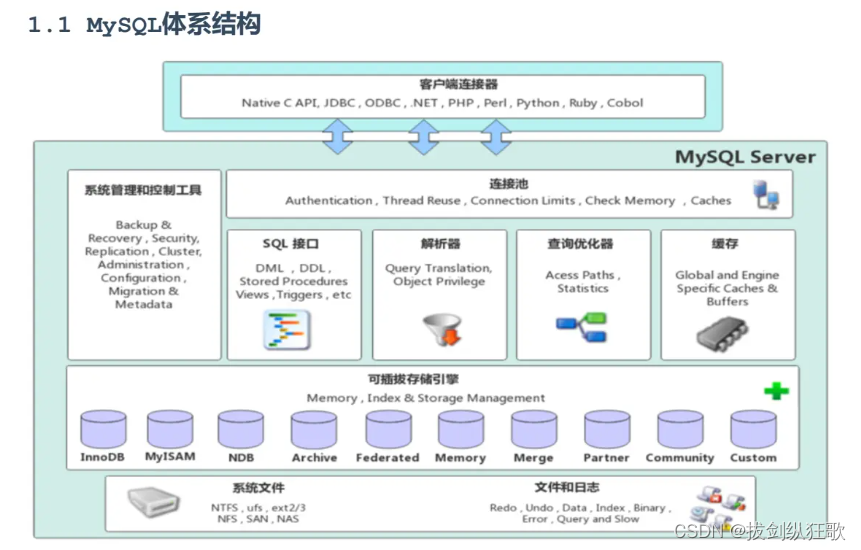
MySQL体系结构
- 连接层:提供一些mysql的数据连接对象、用户校验、权限认证等服务
- 服务层:在本层实现了一些核心功能,如SQL接口,缓存查询(8.0之后的版本已取消该功能)、SQL分析和优化,部分内置函数的执行。所有的跨存储引擎的功能都在这一层实现,如:过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树(语法解析树等),并对其完成相应的优化如确定表的查询的顺序,是否利用索引等,最后生成相应的执行操作。
- 引擎层:存储引擎层真正负责了MySQL中数据的人存储和提取,服务器通过API和促成农户引擎进行通信。不同的存储引擎实现了不同的功能,我们可以根据自己的需要来选取合适的存储引擎。
- 存储层:实际负责数据的存储,将数据保存成各种各样的文件,持久化到本地中。
MySQL常见的引擎及特点
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。我们可以在创建表的时候,来指定选择的存储引擎,如果没有指定将自动选择默认的存储引擎。
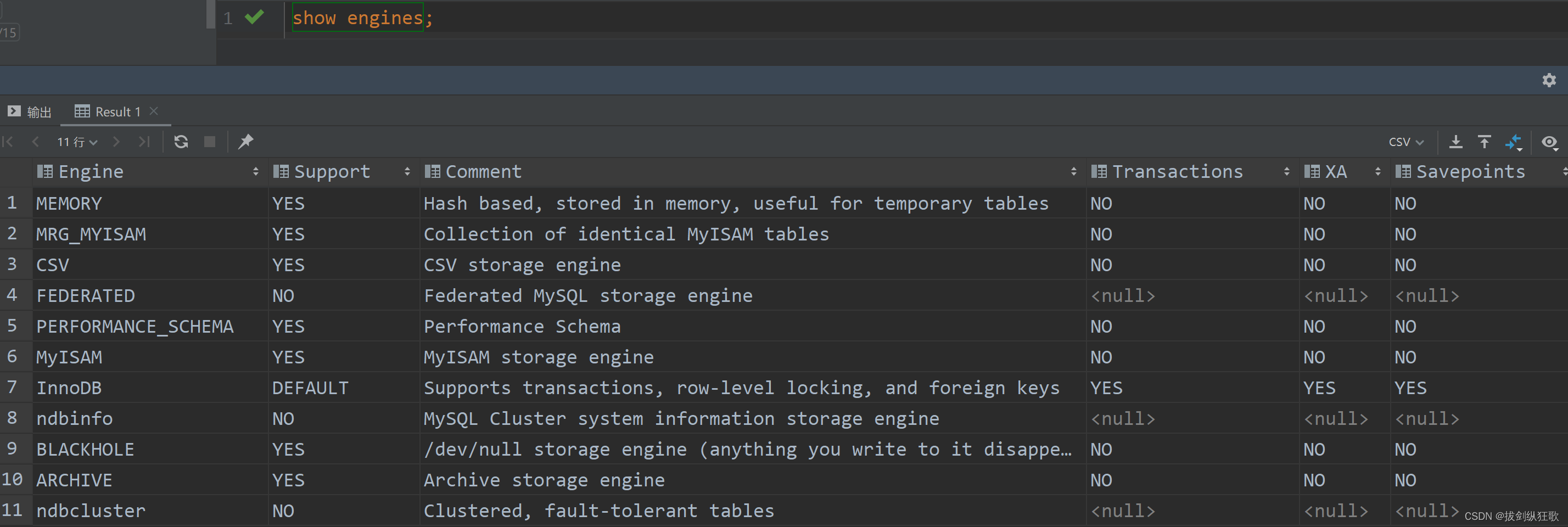
当我们使用show engines时,可以发现mysql当中支持的引擎有11种,但其实我们经常使用到的大概有3种,分别为Memory、MyISAM、InnoDB。其中:
- Memory:存储内存当中,读写速度较快,数据不会进行持久化存储,一旦mysql服务停止,数据会发生丢失。
- MyISAM:mysql5.5版本之前的默认存储引擎,不支持事务;支持表锁,不支持行锁;访问速度快;
- InnoDB:mysql5.5版本之后的默认存储引擎,兼顾高可靠性和高性能的通用存储引擎,相较于MyISAM来说,其DML遵循ACID模型,支持事务;支持行级锁,提高并发访问的性能;支持外键FORGIN KEY约束,保证数据的完整性和正确性,是我们最常用的存储引擎。
存储引擎的选择:
- InnoDB:如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是一个比较合适的选择。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。例如:一些网站的浏览历史。
- Memory:将所有的数据保存在内存中,访问速度快,通常用于临时表及缓存。缺陷是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
索引
1.介绍
索引是帮助MySQL高效获取数据的数据结构,有了索引我们便可以高效地进行数据的查找,而无需进行全表扫描。也就是,在数据本身之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法,这样的数据结构就是索引。

在不同的存储引擎中,索引具有不同的实现方式。以下是索引常见的实现方式
- B+Tree
- Hash
其中InnoDB索引的实现是基于B+Tree的,Memory索引的实现是基于Hash的,这两种实现索引的方式互有利弊。如果索引是使用B+Tree实现,在查找数据时,检索的速度相较于hash实现慢一些,需要遍历多个索引项才能找到目标索引的值但是支持范围数据的查询;如果使用hash实现索引,在查找数据时,只需要一次检索即可,查询速度快,但是不支持范围查询。
2.索引分类
索引按照声明方式(具体类型)分为:
- 主键索引 自动创建只能有一个
- 唯一索引
- 普通索引
- 联合索引
在InnoDB中,索引按照存储形式可以分为:
- 聚集索引 【将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据】
- 二级索引 【将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键】
一张表中必有有且只有一个聚集索引,如果有主键索引,则主键索引是聚集索引;如果没有主键索引,则唯一索引是聚集索引;如果既没有主键索引,也没有唯一索引,则InnoDB引擎会创建一个默认索引rowid作为聚集索引。
不是聚集索引的其他索引构成二级索引。
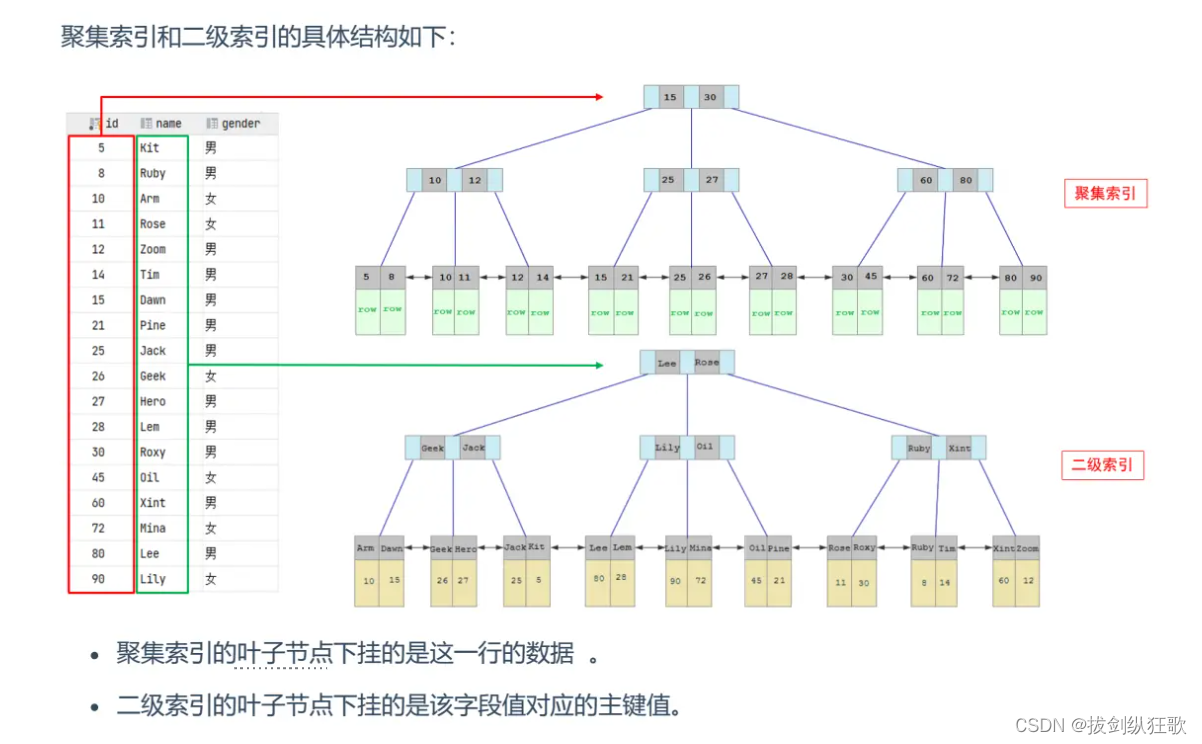
其中,聚集索引构成的B+Tree的非叶子结点下的数据是这一行的所有字段的记录,二级索引下构成的B+Tree的非叶子结点下的数据是这一行的主键值。
3.相关语法
show index from table_name;
create index index_name on table_name(column_name,.....);
drop index index_name on table_name;
4.索引的使用
在使用索引的时候,要遵循以下原则:
- 使用联合索引时,遵循最左前缀法则
- 当使用联合索引进行范围查询时要使用>=或者<=,而不要使用>或者<
- 不要对索引列进行运算
- 如果索引是字符串时,要在作为查询条件是带上' '
- 在进行模糊查询的时候,要尽可能地使用右模糊,而不是左模糊,保证左边数据的有效性
- 使用or作为连接条件时,连接条件的左右两侧都要有索引,如果一边有一边没有,会导致索引的失效
- 尽可能使用覆盖索引,减少直接使用select *作为查询结果
- 当我们的查询条件是字符串并且需要对字符串建立索引的时候,如果字符串过长,我们可以对字符串的前缀建立索引。
- 如果我们查询条件为多个的话,可以针对多个查询条件建立联合索引。
如何快速理解使用索引的原则:
理解索引使用的过程,实际上是理解聚集索引、二级索引如何构建B+Tree的结构和如何减少回表查询操作的过程。接下来,我会结合自己的理解,帮助大家快速掌握如何正确使用索引。以下序号和使用索引所遵循的原则的序号相对应。
- 最左前缀法则仅仅适用于联合索引,最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。例如,我们的联合索引涉及三个字段,分别为:profession、age、status。构建B+Tree的索引项为profession-age-status。如果我们的查询条件正好为profession、age、status时,会根据索引快速检测到索引项,获取主键值;如果我们的查询条件正好profession、age,这时候,mysql并不会放弃根据联合索引去检索数据的机会,而是会根据professoin和age定位对应主键值的大致范围,然后进行回表查询,通过主键值获取记录的gender是否符合我们的查询条件,如果符合,则作为最终的返回结果;如果我们的查询条件正好profession、status,这时候,mysql也不会放弃根据联合索引去检索数据的机会,但仅仅会根据professoin定位对应主键值的大致范围,然后进行回表查询,通过主键值获取记录的age、gender是否符合我们的查询条件,如果符合,则作为最终的返回结果。注意,如果我们直接以age、status作为查询条件,MySQL对直接放弃使用索引进行查询。
- 如果我们在使用联合索引进行范围查询的时候,没有使用>=或者<=,那么mysql就无法根据查询条件去进行索引项的检索,这会导致我们的索引直接失效,查询过程变为全表扫描。
- 对索引项运算后的结果和利用索引构建的B+Tree的索引项之间和很大的区别,运算后的结果自然无法和索引项之间进行比对,直接导致索引项失效。(我们不可能要求我们对索引项运算后,就要求索引项构建的B+Tree进行同样的运算,来满足我们的检索,难以实现,也没有必要)
- 对于字符串类型的查询条件,我们加不加引号,其实对最终的运算结果没有任何的影响,因为mysql底层会帮助我们进行类型的转化,但是对于这条sql的查询效率却有很大区别的。索引项的值一定是基于数据类型的,由于我们的字符串查询条件没有带引号,导致数据库隐式转化后的类型与索引项构建的B+Tree不配对。这时候,mysql为了查询结果的正确性,会直接放弃走索引,选择全表扫描。
- 当我们使用左模糊时,由于无法确定字符串左边的值,难以进行索引项的配对,这时候会直接放弃走索引。
- or作为连接条件时,要求左右两边都需要有索引,否则索引失效。
- 覆盖索引是指查询时使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。尽可能地使用覆盖索引,实际上就是减少回表查询的操作。也就是我们要尽可能地在二级索引构建的B+Tree树中获取我们的想要返回的结果。
- 当字符串类型的字段作为索引时,如果字符串的长度过长,这时候构建B+Tree的叶子结点就会消耗大量的资源,并且也不利于构建完成后的查询操作。这时候我们为了节约系统资源,会选择只将字符串的部分作为索引。我们如何确定字符串的前缀部分的长度呢?答案,尽可能地平衡字符串前缀的唯一性和长度值。我们可以通过一个公式来帮助我们确定字符串的长度。我们将字符串截取后的唯一性同原有的总数量进行比值,截取后的字符串长度约小,比值越靠近1,说明我们建立的前缀索引效果越好。 【select count(distinct substring(email,1,5)) / count(*) from tb_user ;】
- 查询条件为多个时,针对查询条件建立索引,实际上也是为了减少回表查询,满足覆盖索引的条件。
5.索引设计原理
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。










