文章目录
什么是ES?
Elasticsearch是基于 Apache Lucene【lusen】的搜索引擎,支持Restful API风格【可以使用常见的HTTP请求来访问】,并且搜索速度很快,可以提供实时的搜索服务。
其实Elasticsearch的功能有很多,比如分布式存储、实时数据分析等很多方面。使用ES的好处有几点:
- 系统解耦。使用ES之后,我们的搜索功能就完全独立于数据库了,这样就不会影响到其他业务的性能。
- 数据分析。深度分析用户行为,用户对于哪个社区感兴趣,对于哪一条帖子感兴趣,对我们来说至关重要。
- 可以达到毫秒级的查询。因为使用的是倒排索引。
什么是倒排索引?
倒排索引创建流程
- 倒排索引会首先将文档(索引中的记录)进行分词,得到多组数组,类似于<词条,文档ID>;
- 然后将词条和文档ID关联,记录当前词条在多少个文档中存在。
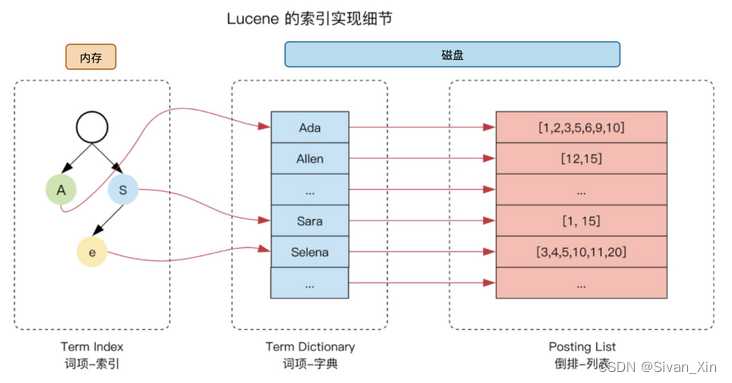
倒排索引检索流程
- 通过Term Index定位:首先,系统使用Term Index(以FST(有限状态转换器)的形式保存在内存中)来快速定位到词典中可能包含目标词项的区块(Block)。由于Term Index只存储词项的前缀信息,并且使用了高效的FST结构,这一步的查找速度非常快,并且内存消耗很低。
- 在词典中查找:一旦定位到了可能的区块,系统就可以在词典(Term Dictionary)中按照其内部的数据结构(如排序数组、B树等)进行精确的查找。由于这一步的查找范围已经大大缩小,因此查找速度也很快。
通过这种方式,词项索引(Term Index)和词典(Term Dictionary)的结合使用可以在不消耗大量内存的情况下实现高效的词典查找,从而支持全文检索系统中的快速查找操作。
倒排索引数据结构
倒排索引由Trem Index, 字典和倒排列表组成。
- Trem Index在内存中,保存前缀词,用FST这种数据结构维护。
- 词汇表就是使用分词器拆分出来的词语,一般用B + 树来维护;
- 倒排列表就是包含这个词语的文档信息集合。【文档信息包括:文档ID、词语出现频率、词语出现位置、词语开始结束位置等信息】
为什么叫做倒排索引?
想象一个场景,我们想要在很多篇文章中找到每一个关键词,常规的寻找方法是遍历每一篇文章,找有没有该关键词。是由文档指向词汇的。
但是在倒排索引中,我们记录了该词汇在哪些文档中出现过,是词汇指向文档的,所以叫做倒排索引。
分词器的使用
分词器是搜索引擎的一个核心组件,负责对文档内容进行分词(在 ES 里面被称为 Analysis),也就是将一个文档转换成 单词词典(Term Dictionary) 。单词词典是由文档中出现过的所有单词构成的字符串集合。为了满足不同的分词需求,分词器有很多种,不同的分词器分词逻辑可能会不一样。
● IK Analyzer: 最常用的开源中文分词器,Github 地址:https://github.com/medcl/elasticsearch-analysis-ik。









