文章目录
简介
论文链接https://arxiv.org/pdf/2106.09685v2.pdf
本文将先介绍论文中的LoRA技术,然后以BERT为例在IMDB数据集上代码实现运用这项微调技术。
代码+数据
LoRA文章主要贡献
文章的主要贡献是提出了一种名为LoRA(Low-Rank Adaptation)的方法,用于在不牺牲模型质量的前提下,高效地对大型预训练语言模型进行微调。LoRA的核心思想是在Transformer架构的每一层注入可训练的低秩分解矩阵,同时冻结预训练模型权重,从而大幅减少下游任务中的可训练参数数量。
具体来说,LoRA的主要贡献包括:
高效的参数更新:LoRA通过低秩矩阵更新模型权重,而不是对整个模型进行微调。这种方法大幅减少了所需的训练参数数量和GPU内存需求。例如,与GPT-3 175B模型的全参数微调相比,LoRA可以将可训练参数减少10,000倍,GPU内存需求减少3倍。
保持模型质量:尽管LoRA使用的可训练参数远少于全参数微调,但它在多个模型(如RoBERTa、DeBERTa、GPT-2和GPT-3)上的表现与全参数微调相当或更好。
提高训练效率:LoRA降低了硬件门槛,因为它不需要计算大多数参数的梯度或维护优化器状态。此外,LoRA的设计允许在部署时将训练的矩阵与冻结的权重合并,从而不会引入额外的推理延迟。
实证研究:文章提供了关于语言模型适应性中秩不足性的实证研究,这有助于解释LoRA的有效性。
总的来说,LoRA提出了一种创新的方法来解决大型语言模型在特定任务上的适应问题,同时保持了模型的性能,降低了资源消耗,并提高了操作效率。这对于需要在资源受限的环境中部署和使用大型模型的应用场景尤为重要。
LoRA技术模型图
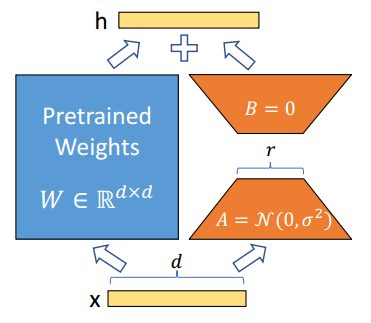
正所谓大智若愚,LoRA这项技术的模型图就是这么简洁明了,x表示数据输入,左边表示预训练大模型的参数(冻结),右边表示两个低秩矩阵(训练),当大模型微调的时候,不再是全参数微调,而是仅仅微调右边的低秩矩阵。
这样一来,就能大大减少我们微调时候的工作量和需要的资源,并且使用这种方法微调模型的性能和全参数微调差不多,从而实现四两拨千斤的效果。
技术细节
假设预训练模型要进行常规全参数微调
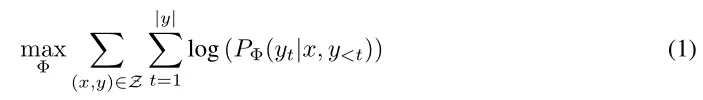
其中Φ表示模型的参数,x表示输入,y表示输出
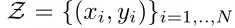
表示进行微调任务的数据集
此时我们需要调整的参数就是全参数:
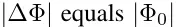
如果是175B的模型,微调一个下游任务的模型,每次都要调整这么多参数,工作量巨大。
但是使用LoRA技术的话
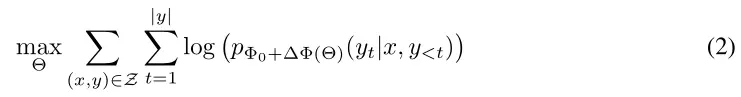
预训练模型的参数都冻结,不调整
只是额外加一组小小的参数
也能做到和下游任务适配
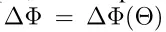
而此时需要调整的参数远远小于预训练模型的参数
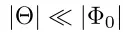
也就是说此时需要调整的参数很小。
文章主要聚焦于将LoRA在transformer注意力机制上进行使用,因为这也是transformer的精髓
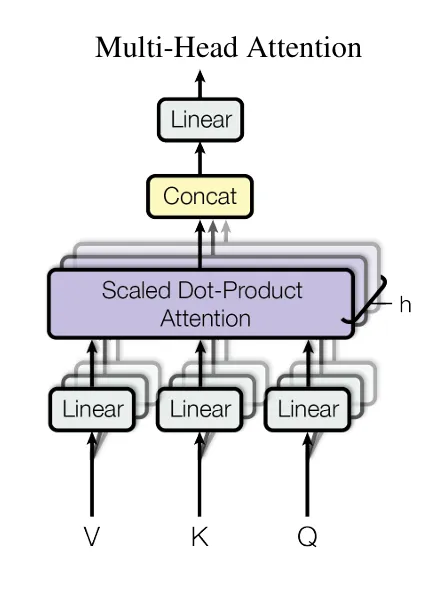
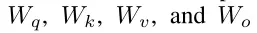
分别用于表示四个线性层的参数。
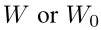
用于表示预训练模型的参数
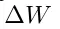
是自适应过程中的累积梯度更新
r就是低秩矩阵的秩
例如我们在
W 0上加个LoRA
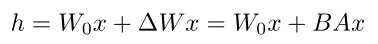
假设 W 0为512*512
就单单只看这部分的话
全参数微调需要调整512*512 = 262144个参数
使用LoRA后,这262144个参数就冻结了
此时增加两个低秩矩阵 例如5122和2512
那么此时需要调整的参数大小就为5122+2512 = 2048个参数
2048 / 262144 = 0.0078125
此时要训练的参数就减少了许多
而且,当我们面对不同的下游任务时,因为原本的预训练模型是冻结的,所以预训练模型用一个就行,只需要保存的参数就是加入的低秩矩阵,这样的话,也能节省大量的存储空间。
可以看个伪代码:
class LowRankMatrix(nn.Module):
def __init__(self, weight_matrix, rank, alpha=1.0):
super(LowRankMatrix, self).__init__()
self.weight_matrix = weight_matrix
self.rank = rank
self.alpha = alpha / rank # 将缩放因子与秩相关联
# 初始化低秩矩阵A和B
self.A = nn.Parameter(torch.randn(weight_matrix.size(0), rank), requires_grad=True)
self.B = nn.Parameter(torch.randn(rank, weight_matrix.size(1)), requires_grad=True)
def forward(self, x):
# 计算低秩矩阵的乘积并添加到原始权重上
# 应用缩放因子
updated_weight = self.weight_matrix + self.alpha * torch.mm(self.B.t(), self.A)
return updated_weight
α和r用于缩放矩阵,帮助更好的训练
A矩阵使用随机高斯初始化
B矩阵初始化为0
论文实验结果
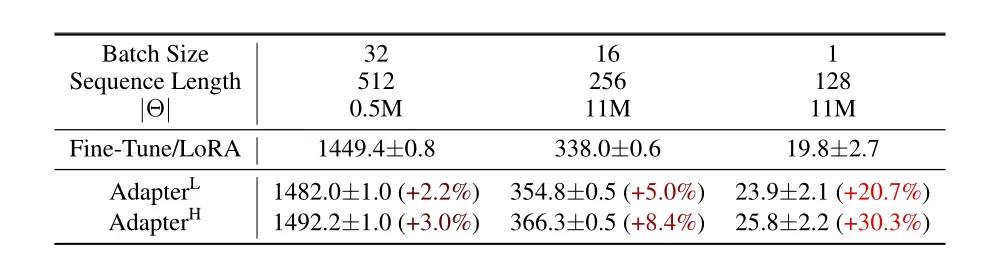
LoRA相较于Adapter不会增加推理的时间。
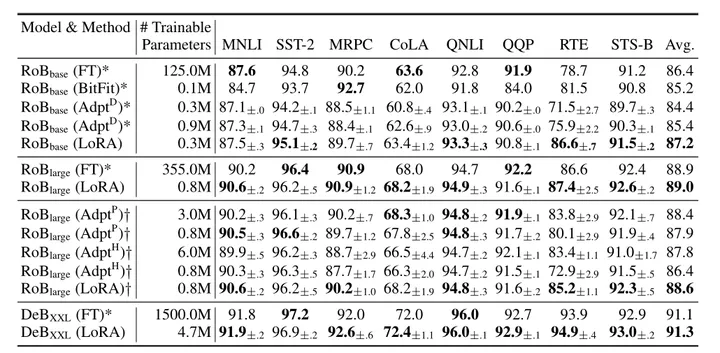

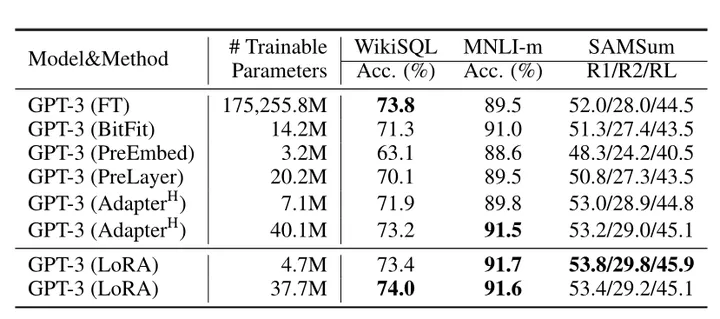
LoRA效果好
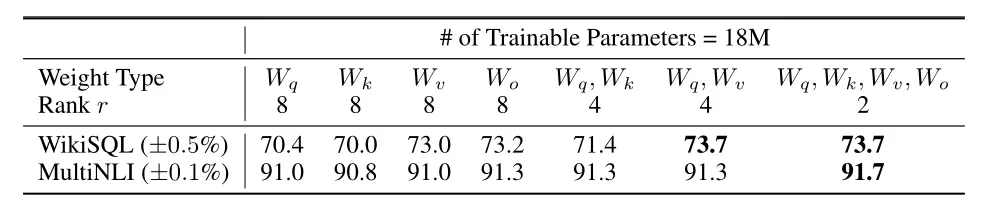
LoRA一起用到Wq和Wv效果比较好
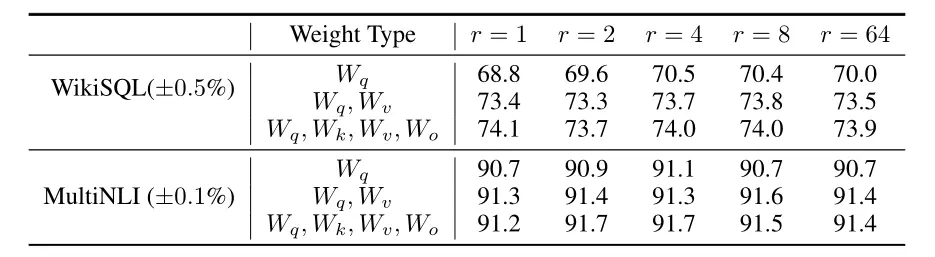
低秩已足够
LoRA在bert的运用
这里主要以bert-base-uncased为例来实现LoRA微调技术的运用。
bert-base-uncased的参数量为110M也就是1.1亿个参数
LoRA核心代码
主要使用文章提出的开源loralib来对bert的注意力机制线性层进行LoRA层的增加
def get_lora_bert_model(model, r=8, lora_layer=["q", 'k', 'v', 'o']):
encoder_layers = list(model.encoder.layer)
for layer_index, encoder_layer in enumerate(encoder_layers):
# 访问多头自注意力层
attention = encoder_layer.attention
# 获取Q、K、V线性层
q_linear = attention.self.query
k_linear = attention.self.key
v_linear = attention.self.value
# 获取O线性层(实际上,O是V经过加权求和后的结果,通常不单独存储)
o_linear = attention.output.dense
for l in lora_layer:
if l == 'q':
new_q_proj = lora.Linear(q_linear.in_features, q_linear.out_features, r=r)
model.encoder.layer[layer_index].attention.self.query = new_q_proj
elif l == 'k':
new_k_proj = lora.Linear(k_linear.in_features, k_linear.out_features, r=r)
model.encoder.layer[layer_index].attention.self.key = new_k_proj
elif l == 'v':
new_v_proj = lora.Linear(v_linear.in_features, v_linear.out_features, r=r)
model.encoder.layer[layer_index].attention.self.value = new_v_proj
elif l == 'o':
new_o_proj = lora.Linear(o_linear.in_features, o_linear.out_features, r=r)
model.encoder.layer[layer_index].attention.output.dense = new_o_proj
return model
可以看到对每层注意注意力机制层的q k v o的线性层都添加了LoRA层
def mark_only_LLM_lora_as_trainable(model: nn.Module, bias: str = 'none', LLM_name: str = 'default_value') -> None:
if LLM_name == 'default_value':
for n, p in model.named_parameters():
if 'lora_' not in n:
p.requires_grad = False
if bias == 'none':
return
elif bias == 'all':
for n, p in model.named_parameters():
if 'bias' in n:
p.requires_grad = True
elif bias == 'lora_only':
for m in model.modules():
if isinstance(m, LoRALayer) and \
hasattr(m, 'bias') and \
m.bias is not None:
m.bias.requires_grad = True
else:
raise NotImplementedError
else:
for n, p in model.named_parameters():
if 'lora_' not in n and LLM_name in n:
# and "bert.pooler" not in
p.requires_grad = False
if bias == 'none':
return
elif bias == 'all':
for n, p in model.named_parameters():
if 'bias' in n:
p.requires_grad = True
elif bias == 'lora_only':
for m in model.modules():
if isinstance(m, LoRALayer) and \
hasattr(m, 'bias') and \
m.bias is not None:
m.bias.requires_grad = True
else:
raise NotImplementedError
添加LoRA层后,每次训练模型的时候,就只需要训练bert加入的LoRA层,此时我们就需要用到mark_only_LLM_lora_as_trainable()来帮助我们实现,考虑到可能我们基于bert的分类模型可能还会涉及到我们自己加入的某些结构,这些部分是需要进行训练的,所以对于这种情况就这么来使用:
mark_only_LLM_lora_as_trainable(model, LLM_name='bert')
实战分析
本文采用IMDB影评情感分析数据集测试训练集各25000条来进行实验。
因为bert才1.1B,可能在bert上使用这个东西有点小题大做了,但是一屋不扫何以扫天下,现在的大模型架构基本都是基于transformer架构的(bert可以说是第一个),其实本质上都是差不多的,只不过我感觉可能更大一些的模型LoRA的效果会更加显著,模型越大,这个方法的优越性就会越强。
之前对bert全参数微调的准确率是93%,而使用LoRA微调技术得出的结果大约是86%左右,确实有一定的差距,我个人感觉可能是因为模型不够大,只有1.1B,因为低秩势必导致信息的损失,只有当你的模型够大的时候,这些损失才能够忽略不计。
但是使用LoRA技术,对于训练速度、显存占用有了巨大的提升。
首先来看显存占用量(同样是batch_size=64):

这是全参数微调的显存占用。

这是使用LoRA后的显存占用(q k v o都使用,r=8)
可以看到,使用了LoRA后,显存占用少了16G左右,节约了约31.5%的显存使用。
再看看训练速度有什么区别:
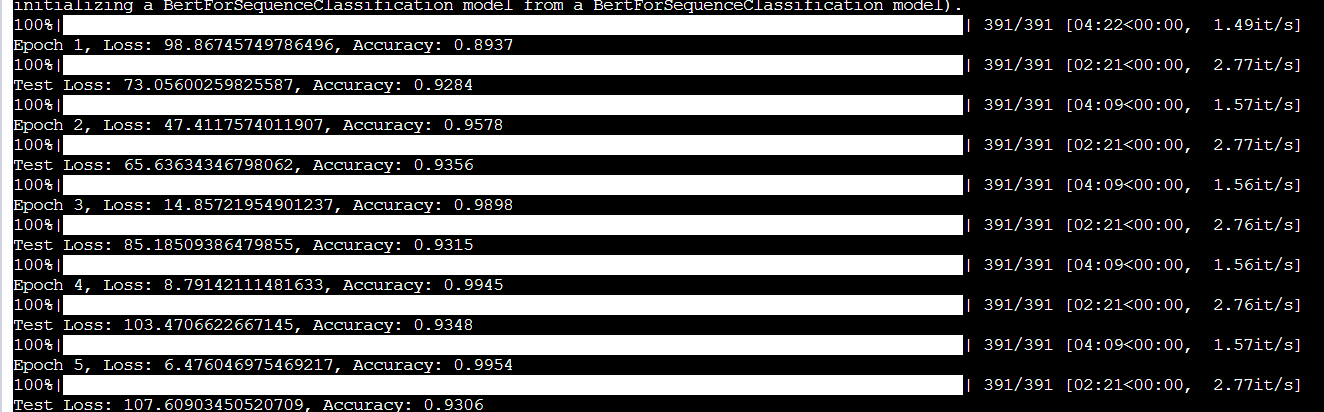
这是全参数微调的结果,可以看到准确率确实挺高的,但是训练一个epoch需要4分钟
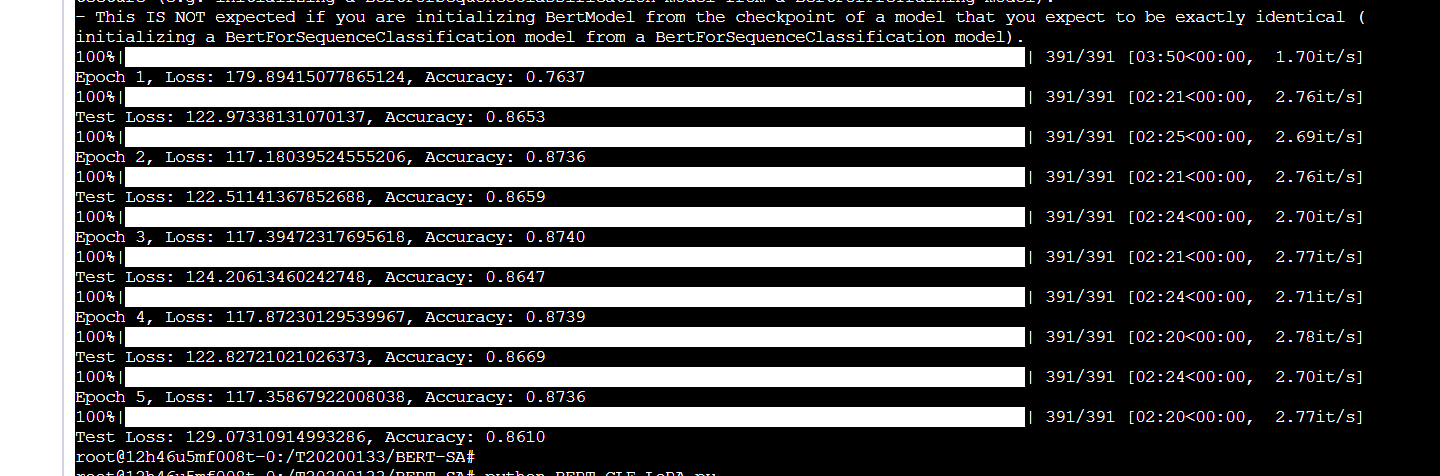
这是使用LoRA之后的,可以看到除了第一个epoch可能涉及数据加载、GPU预热等情况稍微慢点,其余epoch都是2.5分钟不到就完成了,节约了大概43%的训练时间。
不过准确率也下降了,从93%掉到了86%,准确率大约下降了7.5%。
如果对更大的模型使用LoRA技术,训练时间和显存占用的节省会更多,而性能的下降则会更少,确实是一项很不错的技术。
由此可见,LoRA这项技术确实十分有意义,能够大大降低模型微调的成本,同时不会增加推理的时间延迟,我们可以看到模型评估的时间都是一模一样的。
所以,这项技术其实一定程度上让大模型的门槛降低了一些,让大模型的使用成本大大降低,虽然性能上可能有些损失,但是,至少落地的可能性变大了。










