背景
写hive监听器时候需要拿到hive对象但hive是在集群linux主机上运行的。通过jdbc提交的sql具体执行过程不会再idea中运行。所以如果需要拿到hive对象有可能存在两个思路:
(1)想办法写个钩子或者监听器,将需要的内容写成json字符串,在复制出来,在IDE中反序列化,然后回放。这个过程有个缺陷,如org.apache.hadoop.hive.ql.QueryPlan虽然继承了java.io.Serializable但是实际使用中需要内部各个成员变量都支持序列化,java没法做到编译检查。所以不可行。
(2)使用remote debug功能,可能社区版Community的IDEA没有此功能。
使用方法
先help看下:
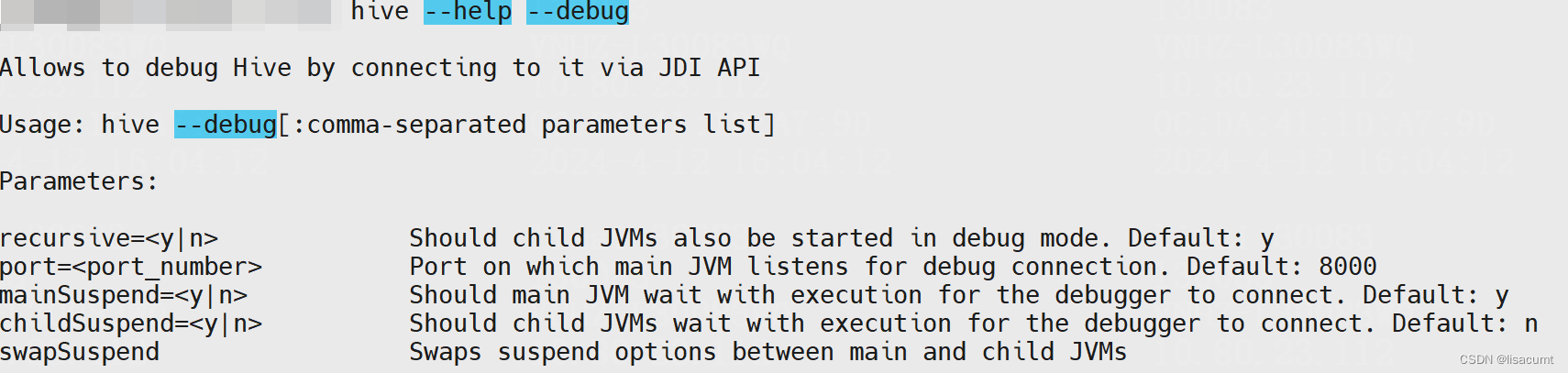
hiveserver2启动方法:
# 默认开启本地8000端口号,日志里边有显示
$HIVE_HOME/bin/hive --debug --service hiveserver2 &
 此时需要在IDE(这里以IDEA举例说明)连接此端口,hiveserver2才会继续运行,否则将一直阻塞(docker里测试不生效不知道为啥)
此时需要在IDE(这里以IDEA举例说明)连接此端口,hiveserver2才会继续运行,否则将一直阻塞(docker里测试不生效不知道为啥)
如果集群有多个hiveserver2,选择一个hiveserver2即可。idea连接指定好host即可。
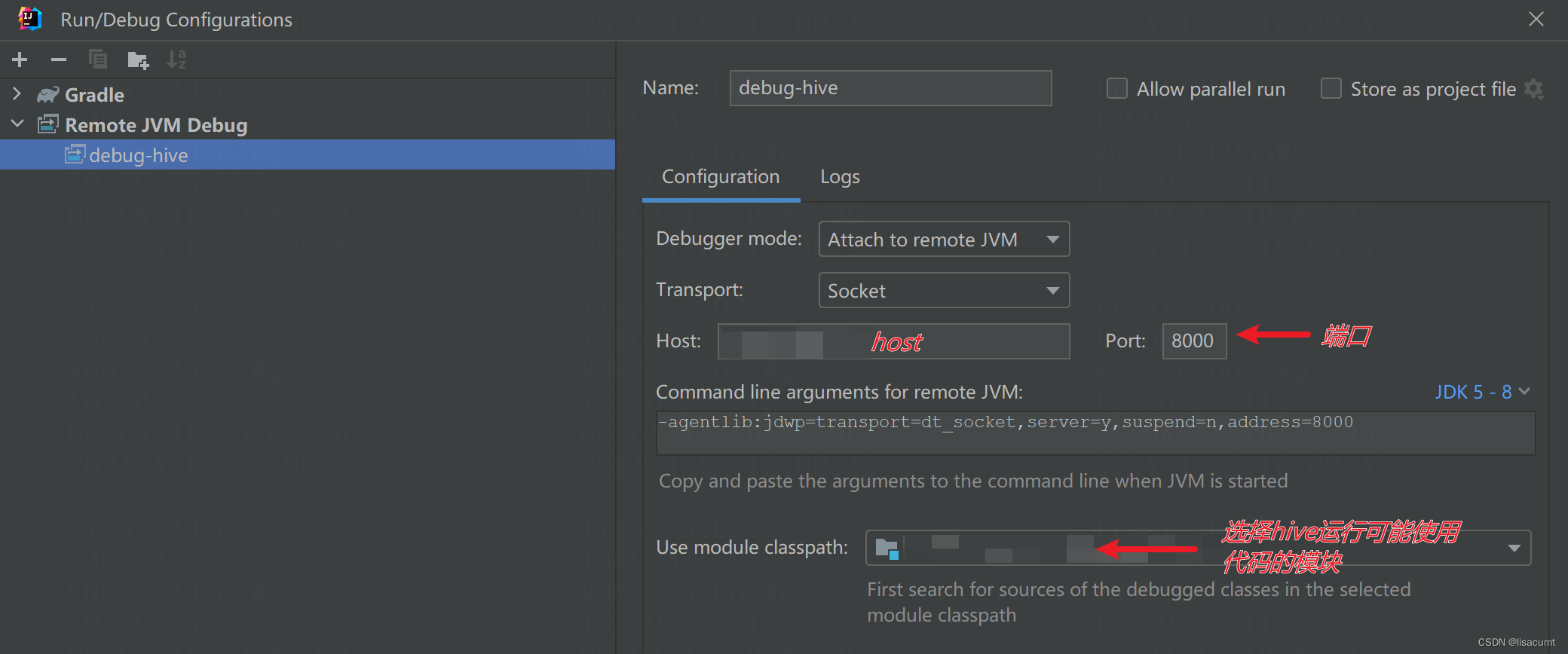
 IDEA连接了远程端口后,远端的hiveserver2就会继续运行了。
IDEA连接了远程端口后,远端的hiveserver2就会继续运行了。
以下以钩子为例:org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext
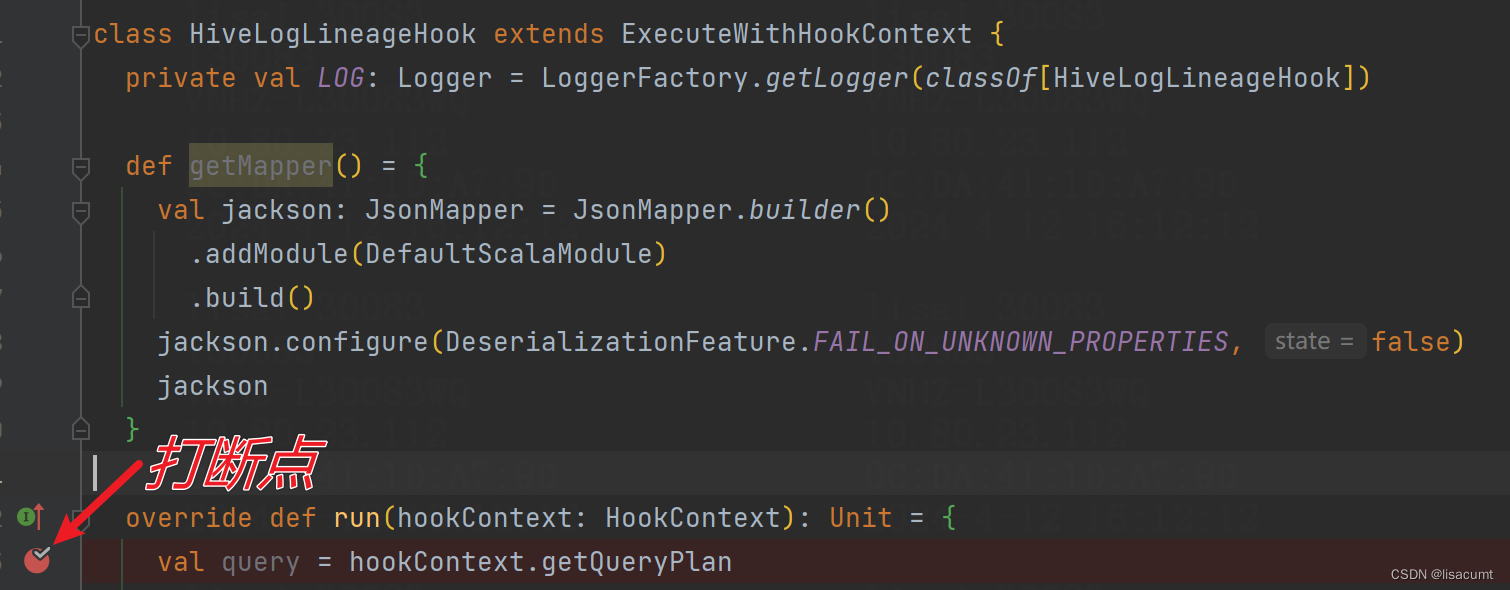
在hive中执行大多数操作都会触发此断点。
如:show tables; use database ...; insert into table ...;
当然断点也可以打到hive自己的类上。









