
python高级进阶全知识知识笔记总结完整教程(附代码资料)主要内容讲述:操作系统,虚拟机软件。ls命令选项,mkdir和rm命令选项。压缩和解压缩命令,文件权限命令。编辑器 vim,软件安装。获取进程编号,进程执行带有参数的任务。线程执行带有参数的任务,线程的注意点。死锁,进程和线程的对比。TCP 网络应用程序开发流程,TCP 客户端程序开发。案例-多任务版TCP服务端程序开发,socket之send和recv原理剖析。HTTP 请求报文,HTTP响应报文。静态Web服务器-返回指定页面数据,静态Web服务器-多任务版。静态Web服务器-命令行启动动态绑定端口号,html 的介绍。表单标签,表单提交。css 属性,JavaScript的介绍。操作标签元素属性,数组及操作方法。选择集转移,获取和设置元素内容。ajax,数据库。命令行客户端MySQL的使用,as和distinct关键字。聚合函数,分组查询。数据库设计之三范式,外键SQL语句的编写。创建表并给某个字段添加数据,修改goods表结构。闭包,闭包的使用。带有参数的装饰器,类装饰器的使用。路由列表功能开发,装饰器方式的添加路由。logging日志,property属性。深拷贝和浅拷贝,正则表达式的概述。匹配多个字符,匹配开头和结尾。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:
案例-多任务版TCP服务端程序开发
学习目标
- 能够说出多任务版TCP服务端程序的实现过程
1. 需求
目前我们开发的TCP服务端程序只能服务于一个客户端,如何开发一个多任务版的TCP服务端程序能够服务于多个客户端呢?
完成多任务,可以使用线程,比进程更加节省内存资源。
2. 具体实现步骤
- 编写一个TCP服务端程序,循环等待接受客户端的连接请求
- 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞
- 把创建的子线程设置成为守护主线程,防止主线程无法退出。
3. 多任务版TCP服务端程序的示例代码:
import socket
import threading
# 处理客户端的请求操作
def handle_client_request(service_client_socket, ip_port):
# 循环接收客户端发送的数据
while True:
# 接收客户端发送的数据
recv_data = service_client_socket.recv(1024)
# 容器类型判断是否有数据可以直接使用if语句进行判断,如果容器类型里面有数据表示条件成立,否则条件失败
# 容器类型: 列表、字典、元组、字符串、set、range、二进制数据
if recv_data:
print(recv_data.decode("gbk"), ip_port)
# 回复
service_client_socket.send("ok,问题正在处理中...".encode("gbk"))
else:
print("客户端下线了:", ip_port)
break
# 终止和客户端进行通信
service_client_socket.close()
if __name__ == '__main__':
# 创建tcp服务端套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,让程序退出端口号立即释放
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 绑定端口号
tcp_server_socket.bind(("", 9090))
# 设置监听, listen后的套接字是被动套接字,只负责接收客户端的连接请求
tcp_server_socket.listen(128)
# 循环等待接收客户端的连接请求
while True:
# 等待接收客户端的连接请求
service_client_socket, ip_port = tcp_server_socket.accept()
print("客户端连接成功:", ip_port)
# 当客户端和服务端建立连接成功以后,需要创建一个子线程,不同子线程负责接收不同客户端的消息
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
# 设置守护主线程
sub_thread.setDaemon(True)
# 启动子线程
sub_thread.start()
# tcp服务端套接字可以不需要关闭,因为服务端程序需要一直运行
# tcp_server_socket.close()
执行结果:
客户端连接成功: ('172.16.47.209', 51528)
客户端连接成功: ('172.16.47.209', 51714)
hello1 ('172.16.47.209', 51528)
hello2 ('172.16.47.209', 51714)
4. 小结
- 编写一个TCP服务端程序,循环等待接受客户端的连接请求
while True:
service_client_socket, ip_port = tcp_server_socket.accept()
- 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞
while True:
service_client_socket, ip_port = tcp_server_socket.accept()
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
sub_thread.start()
- 把创建的子线程设置成为守护主线程,防止主线程无法退出。
while True:
service_client_socket, ip_port = tcp_server_socket.accept()
sub_thread = threading.Thread(target=handle_client_request, args=(service_client_socket, ip_port))
sub_thread.setDaemon(True)
sub_thread.start()
socket之send和recv原理剖析
学习目标
- 能够知道send和recv的底层工作原理
1. 认识TCP socket的发送和接收缓冲区
当创建一个TCP socket对象的时候会有一个发送缓冲区和一个接收缓冲区,这个发送和接收缓冲区指的就是内存中的一片空间。
2. send原理剖析
send是不是直接把数据发给服务端?
不是,要想发数据,必须得通过网卡发送数据,应用程序是无法直接通过网卡发送数据的,它需要调用操作系统接口,也就是说,应用程序把发送的数据先写入到发送缓冲区(内存中的一片空间),再由操作系统控制网卡把发送缓冲区的数据发送给服务端网卡。
3. recv原理剖析
recv是不是直接从客户端接收数据?
不是,应用软件是无法直接通过网卡接收数据的,它需要调用操作系统接口,由操作系统通过网卡接收数据,把接收的数据写入到接收缓冲区(内存中的一片空间),应用程序再从接收缓存区获取客户端发送的数据。
4. send和recv原理剖析图
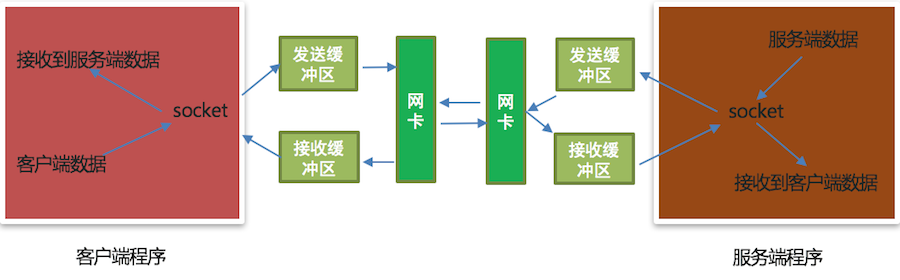
说明:
- 发送数据是发送到发送缓冲区
- 接收数据是从接收缓冲区 获取
5. 小结
不管是recv还是send都不是直接接收到对方的数据和发送数据到对方,发送数据会写入到发送缓冲区,接收数据是从接收缓冲区来读取,发送数据和接收数据最终是由操作系统控制网卡来完成。
HTTP 协议
学习目标
- 能够知道 HTTP 协议的作用
1. HTTP 协议的介绍
HTTP 协议的全称是(HyperText Transfer Protocol),翻译过来就是超文本传输协议。
超文本是超级文本的缩写,是指超越文本限制或者超链接,比如:图片、音乐、视频、超链接等等都属于超文本。
HTTP 协议的制作者是蒂姆·伯纳斯-李,1991年设计出来的,HTTP 协议设计之前目的是传输网页数据的,现在允许传输任意类型的数据。
传输 HTTP 协议格式的数据是基于 TCP 传输协议的,发送数据之前需要先建立连接。
2. HTTP 协议的作用
它规定了浏览器和 Web 服务器通信数据的格式,也就是说浏览器和web服务器通信需要使用http协议。
3. 浏览器访问web服务器的通信过程
通信效果图:
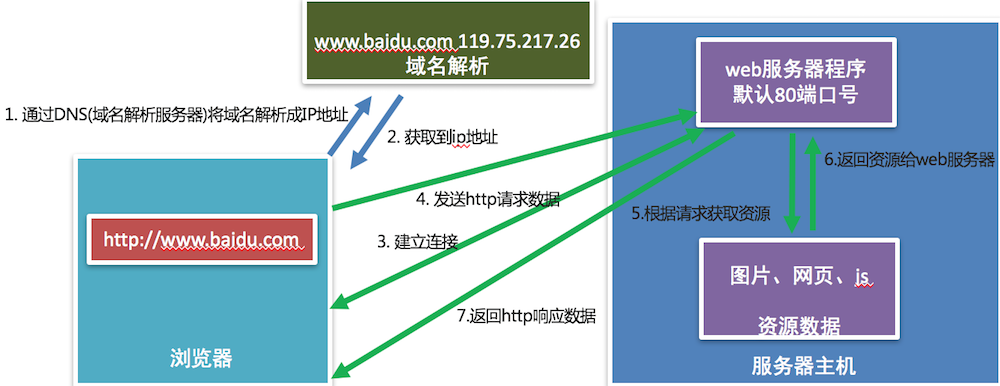
4. 小结
- HTTP协议是一个超文本传输协议
- HTTP协议是一个基于TCP传输协议传输数据的
- HTTP协议规定了浏览器和 Web 服务器通信数据的格式
URL
学习目标
- 能够知道URL的组成部分
1. URL的概念
URL的英文全拼是(Uniform Resoure Locator),表达的意思是统一资源定位符,通俗理解就是网络资源地址,也就是我们常说的网址。
2. URL的组成
URL的样子:
[
URL的组成部分:
- 协议部分: [
- 域名部分: news.163.com
- 资源路径部分: /18/1122/10/E178J2O4000189FH.html
域名:
域名就是IP地址的别名,它是用点进行分割使用英文字母和数字组成的名字,使用域名目的就是方便的记住某台主机IP地址。
URL的扩展:
[
- 查询参数部分: ?page=1&count=10
参数说明:
- ? 后面的 page 表示第一个参数,后面的参数都使用 & 进行连接
3. 小结
-
URL就是网络资源的地址,简称网址,通过URL能够找到网络中对应的资源数据。
-
URL组成部分
- 协议部分
- 域名部分
- 资源路径部分
- 查询参数部分 [可选]
查看HTTP协议的通信过程
学习目标
- 能够使用谷歌浏览器的开发者工具查看HTTP协议的通信过程
1. 谷歌浏览器开发者工具的使用
首先需要安装Google Chrome浏览器,然后Windows和Linux平台按F12调出开发者工具, mac OS选择 视图 -> 开发者 -> 开发者工具或者直接使用 alt+command+i 这个快捷键,还有一个多平台通用的操作就是在网页右击选择检查。
开发者工具的效果图:
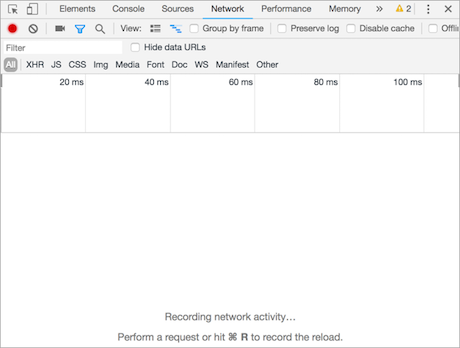
开发者工具的标签选项说明:
- 元素(Elements):用于查看或修改HTML标签
- 控制台(Console):执行js代码
- 源代码(Sources):查看静态资源文件,断点调试JS代码
- 网络(Network):查看http协议的通信过程
开发者工具使用效果图:
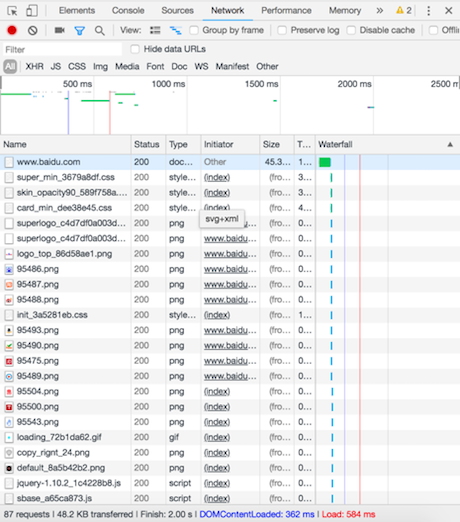
开发者工具的使用说明:
- 点击Network标签选项
- 在浏览器的地址栏输入百度的网址,就能看到请求百度首页的http的通信过程
- 这里的每项记录都是请求+响应的一次过程
2. 查看HTTP协议的通信过程
查看http请求信息效果图:
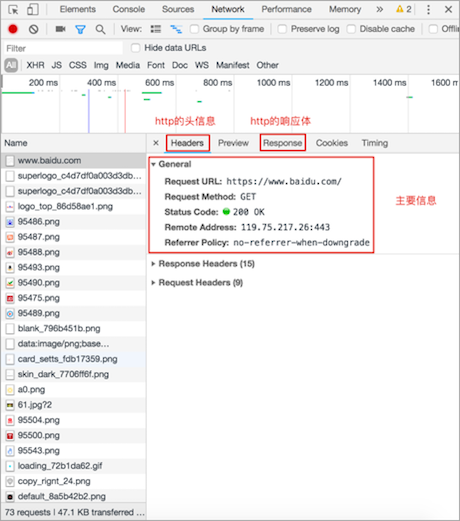
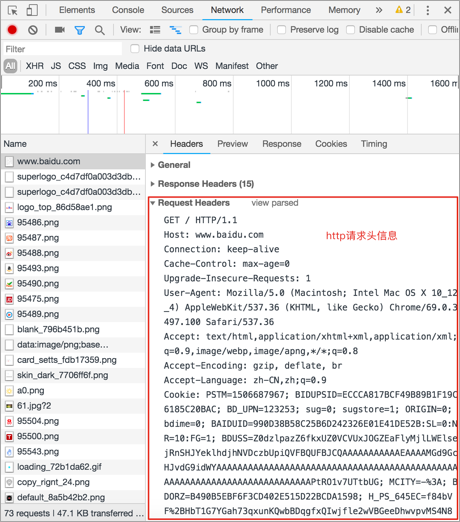
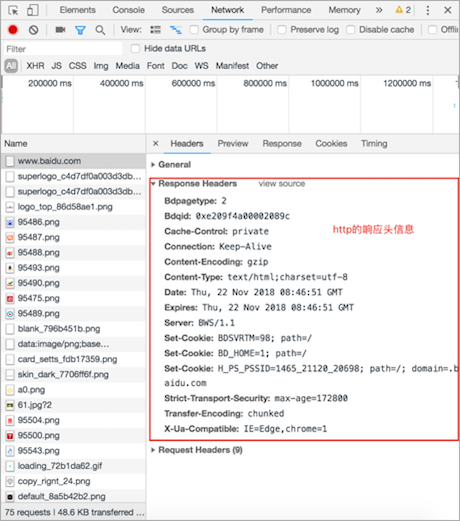
查看http响应信息效果图:
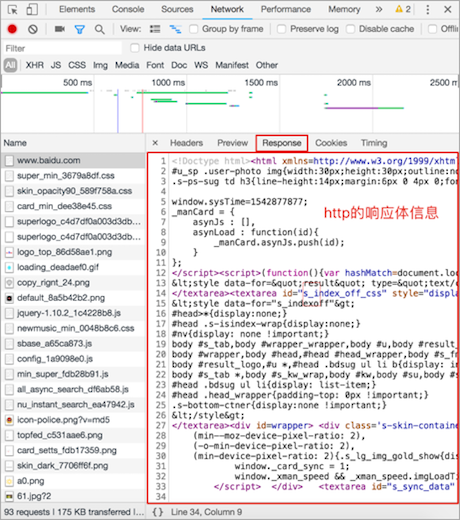
3. 小结
-
谷歌浏览器的开发者工具是查看http协议的通信过程利器,通过Network标签选项可以查看每一次的请求和响应的通信过程,调出开发者工具的通用方法是在网页右击选择检查。
-
开发者工具的Headers选项总共有三部分组成:
- General: 主要信息
- Response Headers: 响应头
- Request Headers: 请求头
-
Response选项是查看响应体信息的










