哈希
1. unordered_set/unordered_map
1.1 背景
之前我们不是学习了以红黑树为底层的容器set和map吗,那是C++98提供的关联式容器,而我们今天要学习的unordered_set/unordered_map是在C++11引入的新容器,看名字就知道和set、map的关系匪浅。set、map的查询效率可以达到log2(N),但是在数据很多的时候,效率也不是很理想。所以就引入了这两个容器。那这两个容器能把效率提高多少呢,看完这篇文章就知道了。
1.2 unordered_set
1.2.1 特性
1.2.2 常用方法
1.3 unordered_map
1.3.1 特性
1.3.2 常用方法
2. 哈希
2.1概念
在前面学习过的数据结构中,存放的关键值和存储的位置没有任何关联,所以查找一个元素必须要经过多次的比较才能得到该元素。那么有没有一种方法可以实现元素之间不用比较也能查找到该元素呢?哈希的思想就引入进来了。
几个名词:
- 哈希函数(散列函数)(将关键码转换成位置的方法)
- 哈希表(散列表)(使用上述方法构造出来的结构)
一个例子:
数据{1,9,16,10,8,0}
哈希函数 hash(key) = key % 10;

相信大家看了这个例子,可以体会到哈希的妙,但这出现了一个问题,两个元素映射到了同一个地方,这种情况叫哈希冲突,解决该问题也是我们研究的一个重要问题。
2.2 哈希冲突
2.2.1哈希函数
产生这种情况的原因可能是哈希函数设计的不够合理。
一些常见哈希函数
2.2.2 解决哈希冲突
解决该冲突常见的两种方法是开散列和闭散列。
2.2.2.1 闭散列
- 线性探测:如果发现插入元素的位置已经有元素了,那就依次往后找空位放进去,比如上述例子的0元素应该放在2位置上。
代码实现:
enum State
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY; // 标记
};
//将关键字转化成无符号整型,这样才能进行取余操作
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
// 特化
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto e : s)
{
hash += e;
hash *= 131;
}
return hash;
}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:
HashTable(size_t size = 10)
{
_tables.resize(size);
}
HashData<K, V>* Find(const K& key)
{
Hash hs;
// 线性探测
size_t hashi = hs(key) % _tables.size();
while (_tables[hashi]._state != EMPTY)
{
if (key == _tables[hashi]._kv.first
&& _tables[hashi]._state == EXIST)
{
return &_tables[hashi];
}
++hashi;
hashi %= _tables.size();
}
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
return false;
//哈希表应满足元素个数和空间的比率,
//如果 ((double)_n / (double)_tables.size() >= 0.7)就该扩容了。
if (_n * 10 / _tables.size() >= 7)
{
HashTable<K, V, Hash> newHT(_tables.size() * 2);
// 遍历旧表,插入到新表
for (auto& e : _tables)
{
if (e._state == EXIST)
{
newHT.Insert(e._kv);
}
}
_tables.swap(newHT._tables);
}
Hash hs;
// 线性探测
size_t hashi = hs(kv.first) % _tables.size();
while (_tables[hashi]._state == EXIST)
{
++hashi;
hashi %= _tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n;
return true;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
_n--;
ret->_state = DELETE;
return true;
}
else
{
return false;
}
}
private:
vector<HashData<K, V>> _tables;
size_t _n = 0; // 实际存储的数据个数
使用这种方式解决冲突虽然很简单,但是如果冲突验证,那么查询的效率会降低很多。
2.2.2.2 开散列
开散列法又叫链地址法(开链法),将冲突的元素通过链表链接起来,将链表的头保存在哈希表中,每个链表也叫桶。
还是上面的例子,用开散列法看看
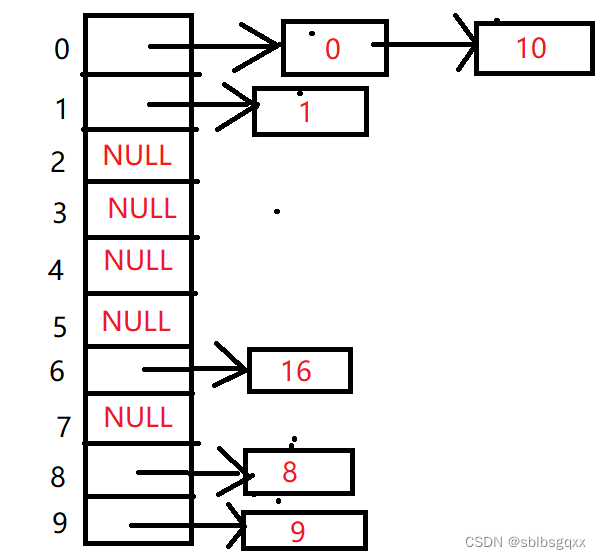
这种结构的插入、删除、查找操作就是链表的基本操作,这里我们就不多说了,直接看代码。
//将关键字映射成整型
template<class K>
struct HashFunC
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
//模版特化,string常作为key
template<>
struct HashFunC<string>
{
//将字符串每个字母的ASCII乘一个系数然后累加
size_t operator()(const string& key)
{
size_t hash = 0;
for (char c : key)
{
hash += c;
hash *= 131;
}
return hash;
}
};
template<class K,class V>
struct HashBucketNode
{
HashBucketNode(const pair<K,V>& value)
:_value(value)
,next(nullptr)
{}
pair<K, V> _value;
HashBucketNode<K, V>* next;
};
template<class K,class V,class Hash = HashFunC<K>>
class HashBucket
{
typedef struct HashBucketNode<K,V> Node;
public:
HashBucket(size_t size = 10)
:_table(size,nullptr)
,_size(0)
{}
~HashBucket()
{
Clear();
}
// 哈希桶中的元素不能重复
Node* Insert(const pair<K, V>& value)
{
if (!Find(value.first))
{
CheckCapacity();
size_t hashi = HashFunc(value.first);
//头插
Node* newnode = new Node(value);
newnode->next = _table[hashi];
_table[hashi] = newnode;
_size++;
return newnode;
}
}
// 删除哈希桶中为data的元素(data不会重复)
bool Erase(const K& key)
{
if (Find(key))
{
size_t hashi = HashFunc(key);
Node* pre = nullptr;
Node* cur = _table[hashi];
while (cur)
{
if (cur->_value.first == key)
{
//头删单独处理
if (!pre)
_table[hashi] = cur->next;
else
pre->next = cur->next;
delete cur;
_size--;
return true;
}
pre = cur;
cur = cur->next;
}
}
return false;
}
Node* Find(const K& key)
{
size_t hashi = HashFunc(key);
Node* cur = _table[hashi];
while (cur)
{
if (cur->_value.first == key)
return cur;
cur = cur->next;
}
return nullptr;
}
void Swap(HashBucket<K,V,Hash>& ht)
{
_table.swap(ht._table);
swap(_size, ht._size);
}
void Clear()
{
for (auto& e : _table)
{
if (e)
{
Node* cur = e;
while (cur)
{
Node* next = cur->next;
delete cur;
cur = next;
}
e = nullptr;
}
}
}
size_t Size()const
{
return _size;
}
bool Empty()const
{
return 0 == _size;
}
private:
size_t HashFunc(const K& key)
{
Hash hash;
return hash(key) % _table.size();
}
void CheckCapacity()
{
//当装填因子为1
if (_size == _table.size())
{
HashBucket<K, V,Hash> newHashBucket(_table.size() * 2);
for (int i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while(cur)
{
Node* next = cur->next;
newHashBucket.Insert(cur->_value);
cur = next;
}
}
Swap(newHashBucket);
}
}
private:
vector<Node*> _table;
size_t _size;
};











