HTTP——Cookie
我们之前了解了HTTP协议,如果还有小伙伴还不清楚HTTP协议,可以点击这里:
我们今天来稍微了解一下HTTP里面一个很小的部分:Cookie:
什么是Cookie
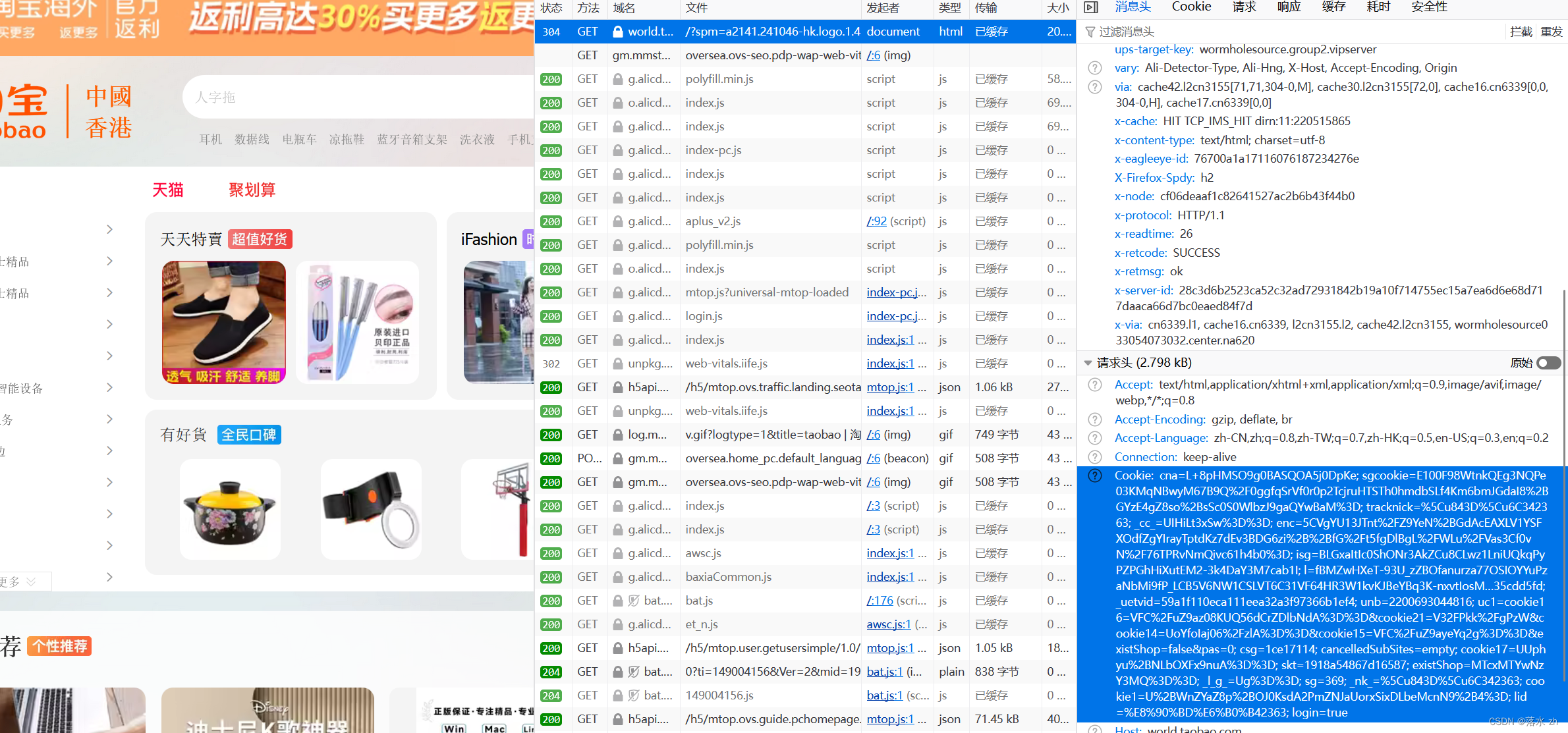
比如我现在在写博客,如果我们是第一次打开这个网页,我们可以打开浏览器的检查功能,找到“网络”,然后点进去一个GET请求:
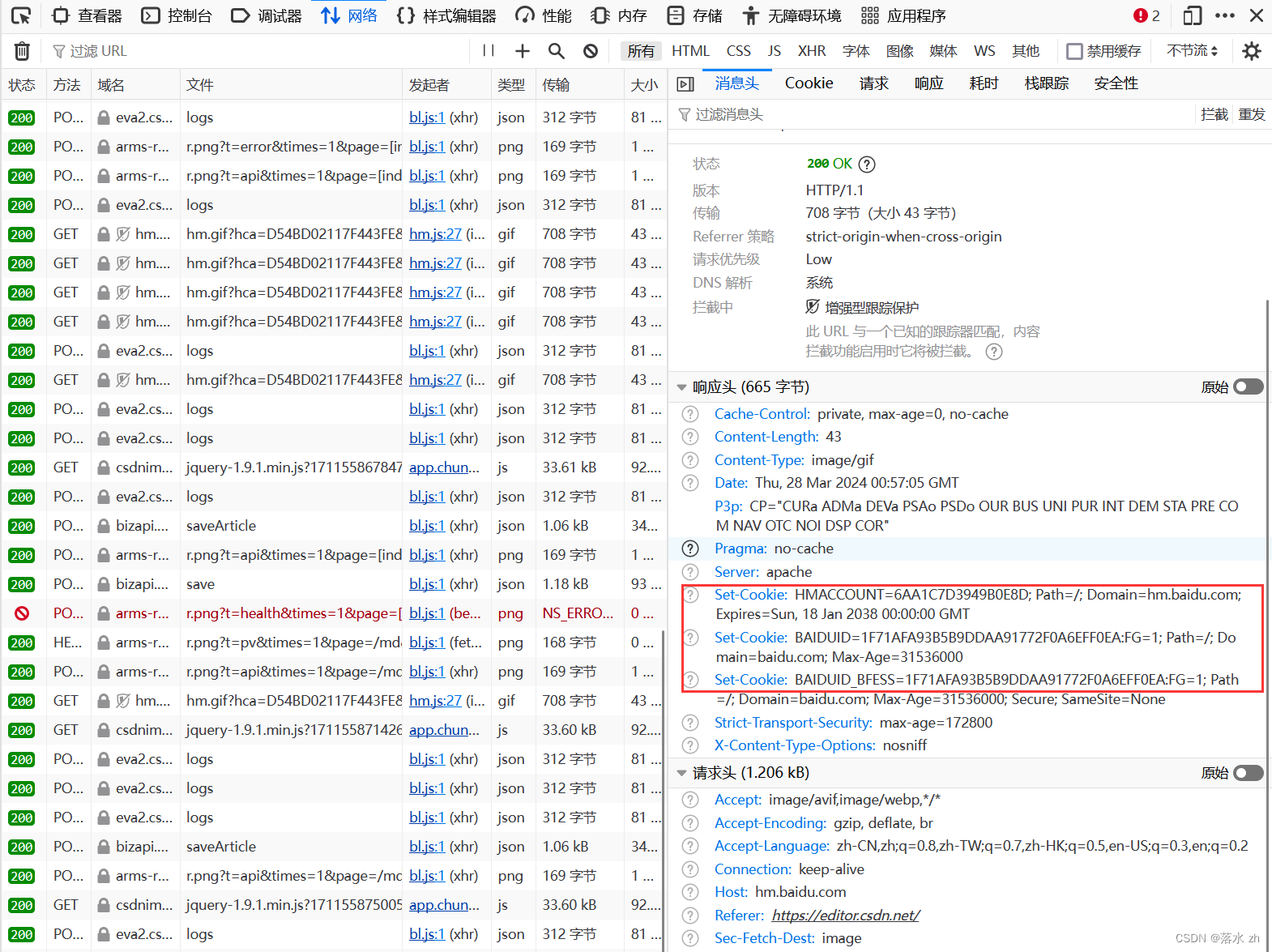
关闭再次打开,这个时候我们可以再次点击检查,再次查看请求头:
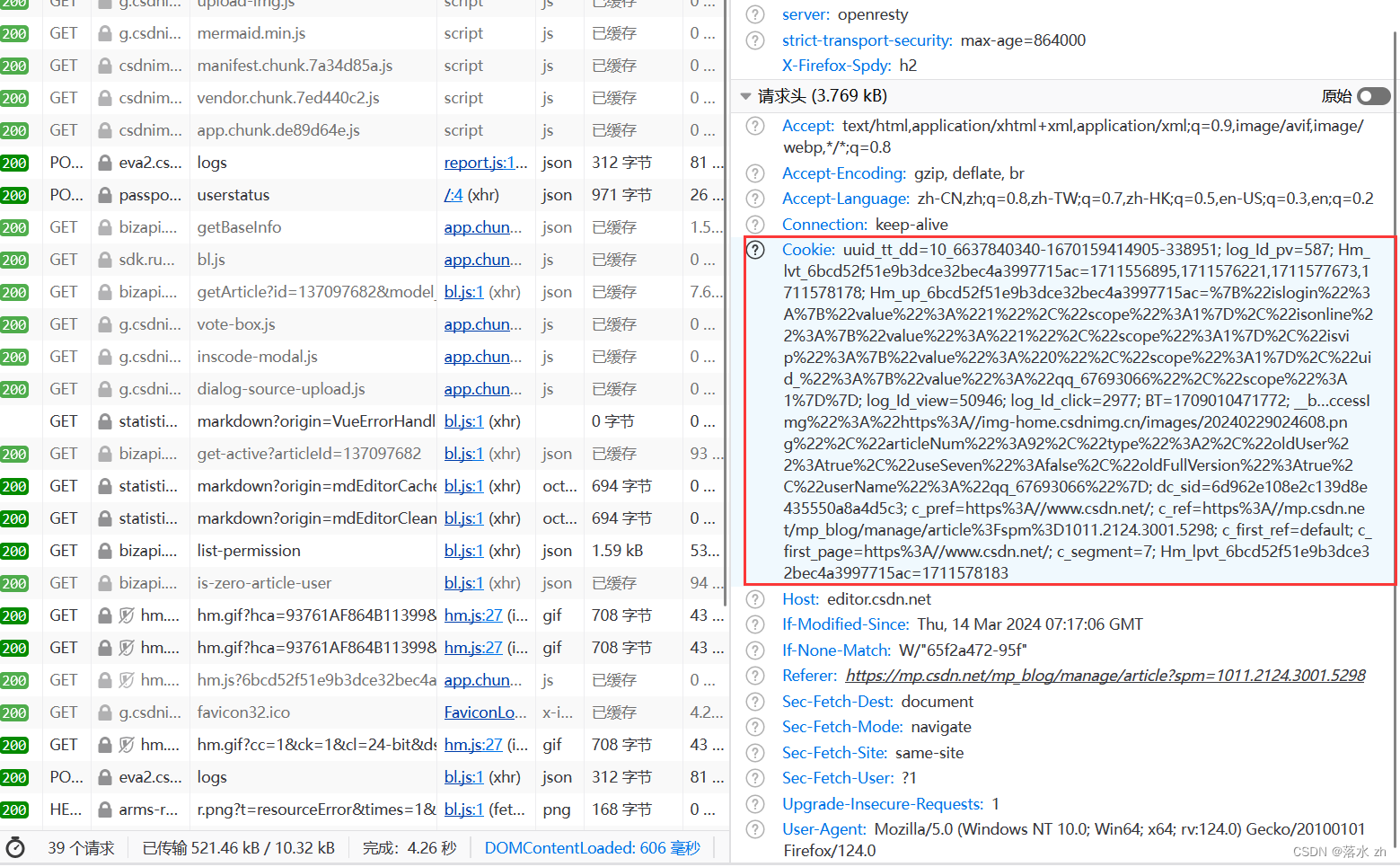
这个时候我们的浏览器就有了Cookie,这个Cookie帮我们存储了一些信息:
这些字段只是Cookie字符串中的一部分,实际上还有其他字段。这些字段通常用于跟踪用户的行为、分析用户的兴趣和偏好,以及提供个性化的服务。
通过Cookie访问网站
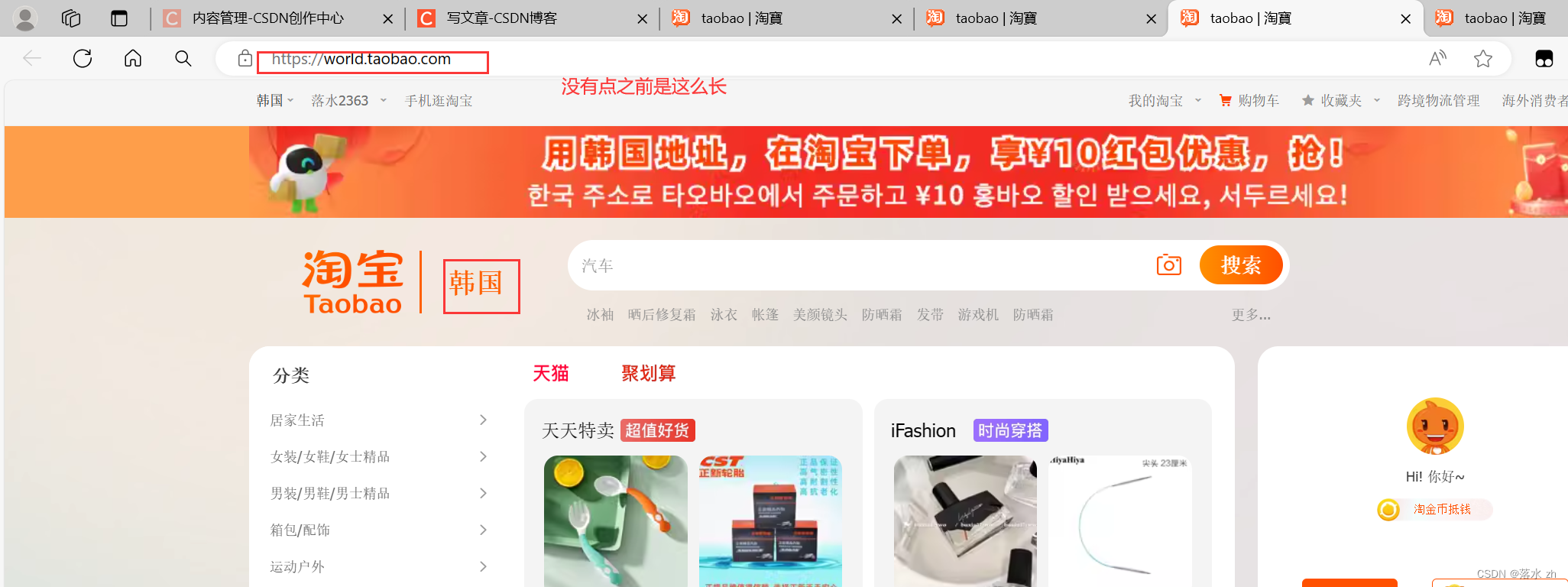
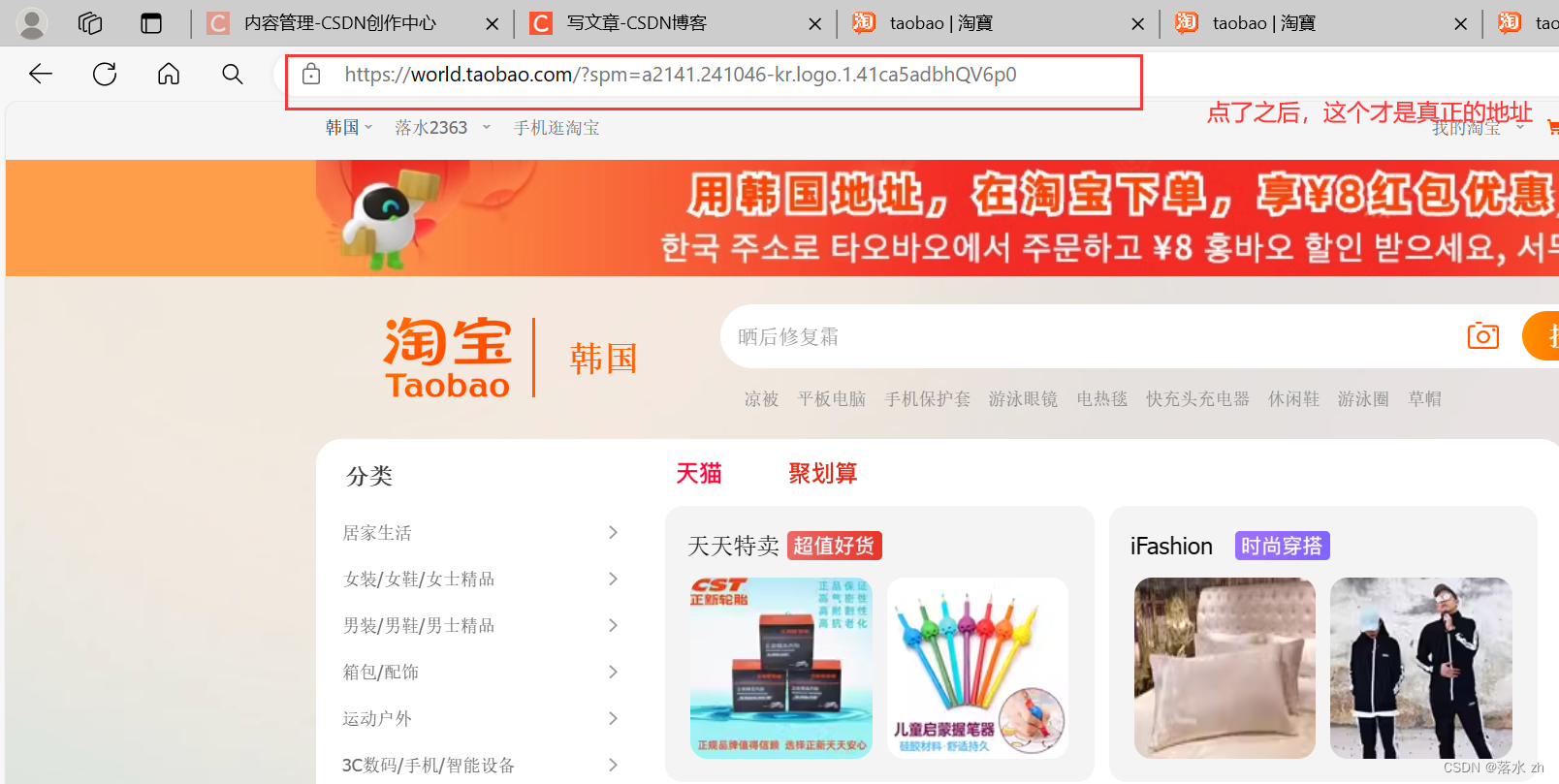
我们这里通过Cookie来访问香港的淘宝,进入淘宝(香港版):
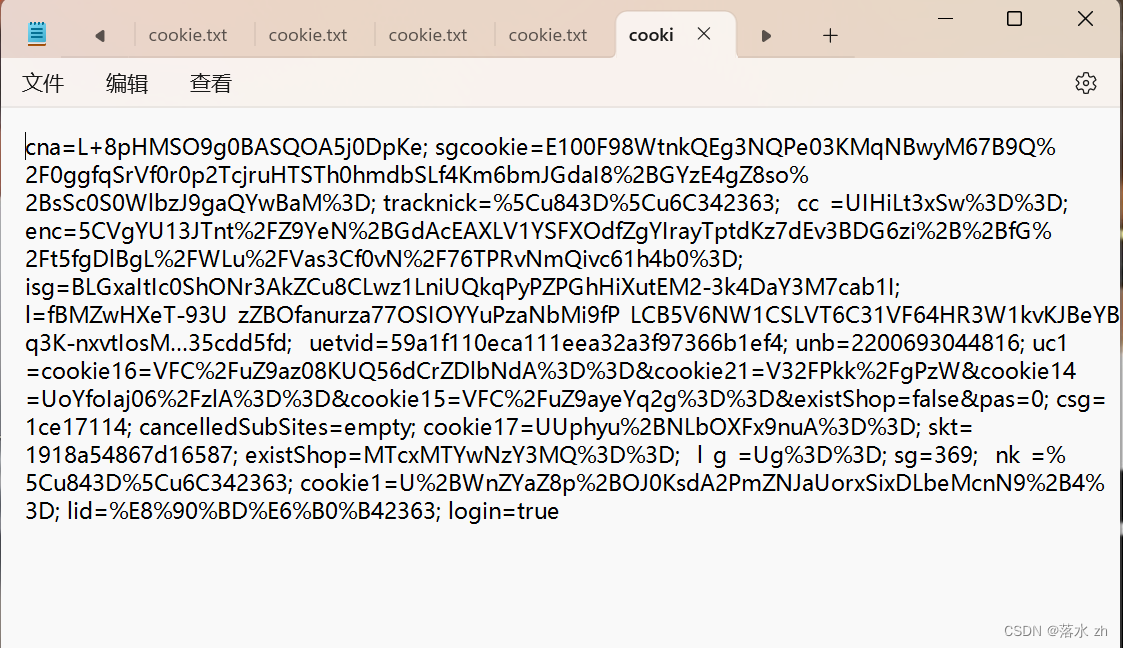
将Cookie的文本内容存放在txt文件中,这里我保存在桌面上:
然后在pycharm中编写以下代码:
import requests
from urllib.parse import unquote
import urllib.parse
# 打开txt文件并读取内容
url = 'https://world.taobao.com/?spm=a2141.241046-hk.logo.1.41ca5adbDMl5rh' # 香港淘宝地址
with open('C:\\Users\\luoshui\\Desktop\\cookie.txt','r',encoding='utf-8') as file:
cookie_str = file.read().strip() # 读取内容并去除两端的空白字符
decoded_cookie_str = unquote(cookie_str)
# 使用分号将字符串分割成单独的Cookie
decoded_cookie_str = decoded_cookie_str.split(';')
# 创建一个字典来存储Cookie键值对
cookies_dict = {}
# 遍历分割后的Cookie列表,并添加到字典中
for cookie in decoded_cookie_str:
# 去除每个Cookie两端的空格,并使用等号分割键和值
key, value = cookie.strip().split('=', 1)
# 在循环内解码值
value = urllib.parse.quote(value.encode('utf-8'))
# 将Cookie添加到字典中
cookies_dict[key] = value
# 打印分割后的Cookie字典
print(cookies_dict)
# 发起请求
response = requests.get(url, cookies= cookies_dict)
# 检查请求是否成功
if response.status_code == 200:
# 请求成功,可以处理响应内容
print("请求成功!")
print(response.text) # 打印网页的HTML内容
else:
# 请求失败,打印错误信息
print(f"请求失败,状态码:{response.status_code}")
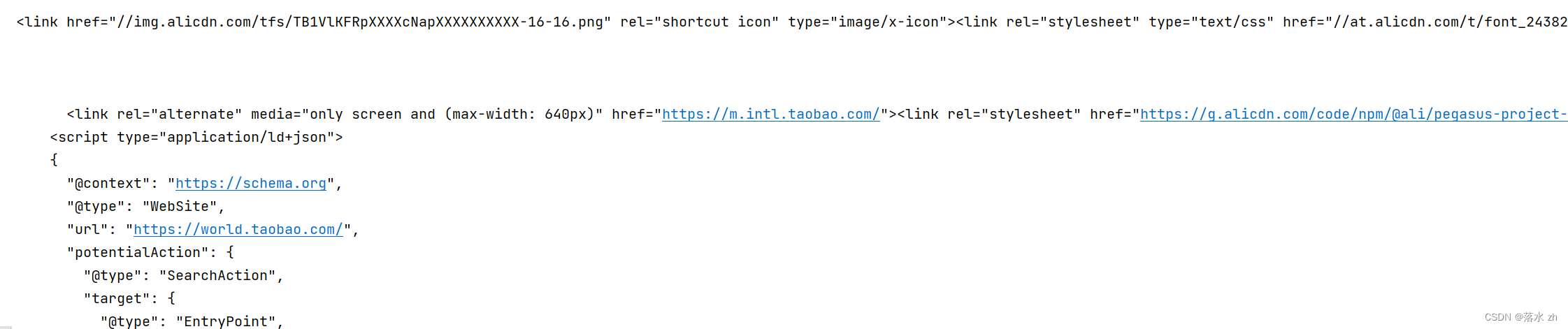
运行:
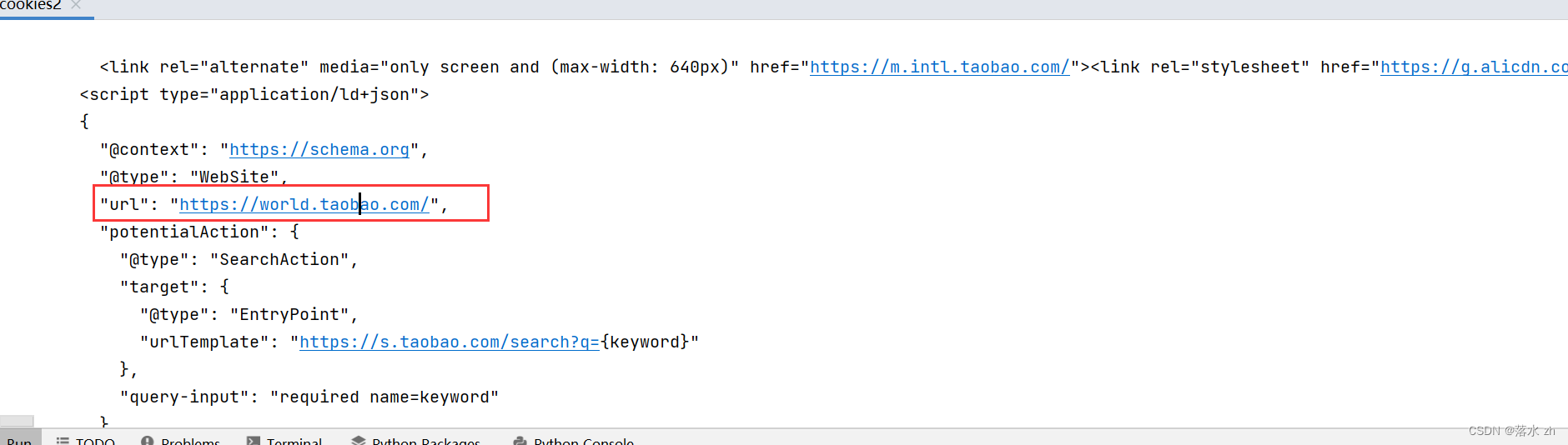
点击url:
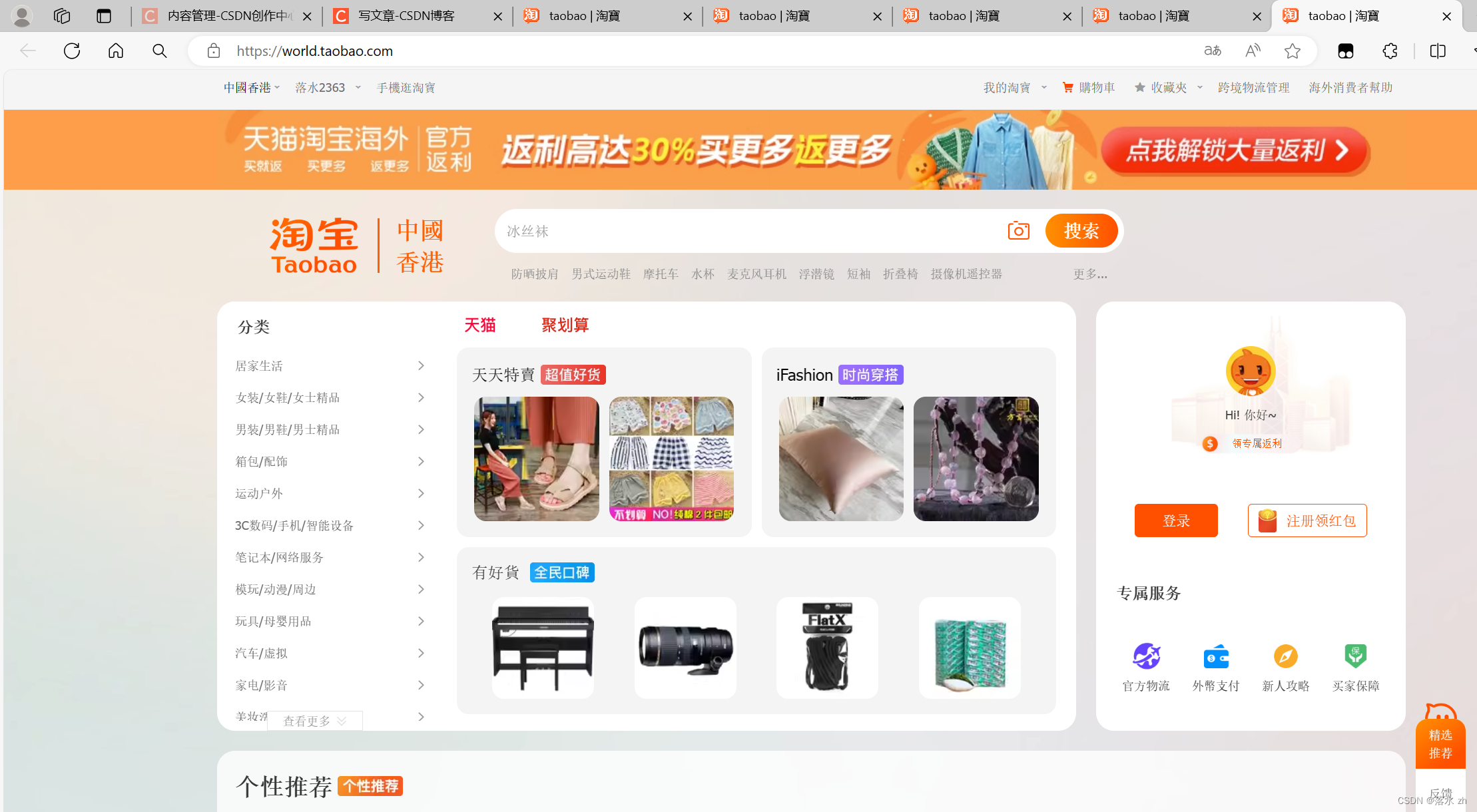
我们还可以切换地址到韩国,访问韩国的淘宝(把url地址换为韩国的,同时cookie也换成韩国的):
import requests
from urllib.parse import unquote
import urllib.parse
# 打开txt文件并读取内容
url = 'https://world.taobao.com/?spm=a2141.241046-kr.logo.1.41ca5adbMdFW4f' # 地址换为韩国的
with open('C:\\Users\\luoshui\\Desktop\\cookie.txt','r',encoding='utf-8') as file:
cookie_str = file.read().strip() # 读取内容并去除两端的空白字符
decoded_cookie_str = unquote(cookie_str)
# 使用分号将字符串分割成单独的Cookie
decoded_cookie_str = decoded_cookie_str.split(';')
# 创建一个字典来存储Cookie键值对
cookies_dict = {}
# 遍历分割后的Cookie列表,并添加到字典中
for cookie in decoded_cookie_str:
# 去除每个Cookie两端的空格,并使用等号分割键和值
key, value = cookie.strip().split('=', 1)
# 在循环内解码值
value = urllib.parse.quote(value.encode('utf-8')).replace('%3B', ';').replace('%3D', '=')
# 将Cookie添加到字典中
cookies_dict[key] = value
# 打印分割后的Cookie字典
print(cookies_dict)
# 发起请求
response = requests.get(url, cookies= cookies_dict)
# 检查请求是否成功
if response.status_code == 200:
# 请求成功,可以处理响应内容
print("请求成功!")
print(response.text) # 打印网页的HTML内容
else:
# 请求失败,打印错误信息
print(f"请求失败,状态码:{response.status_code}")
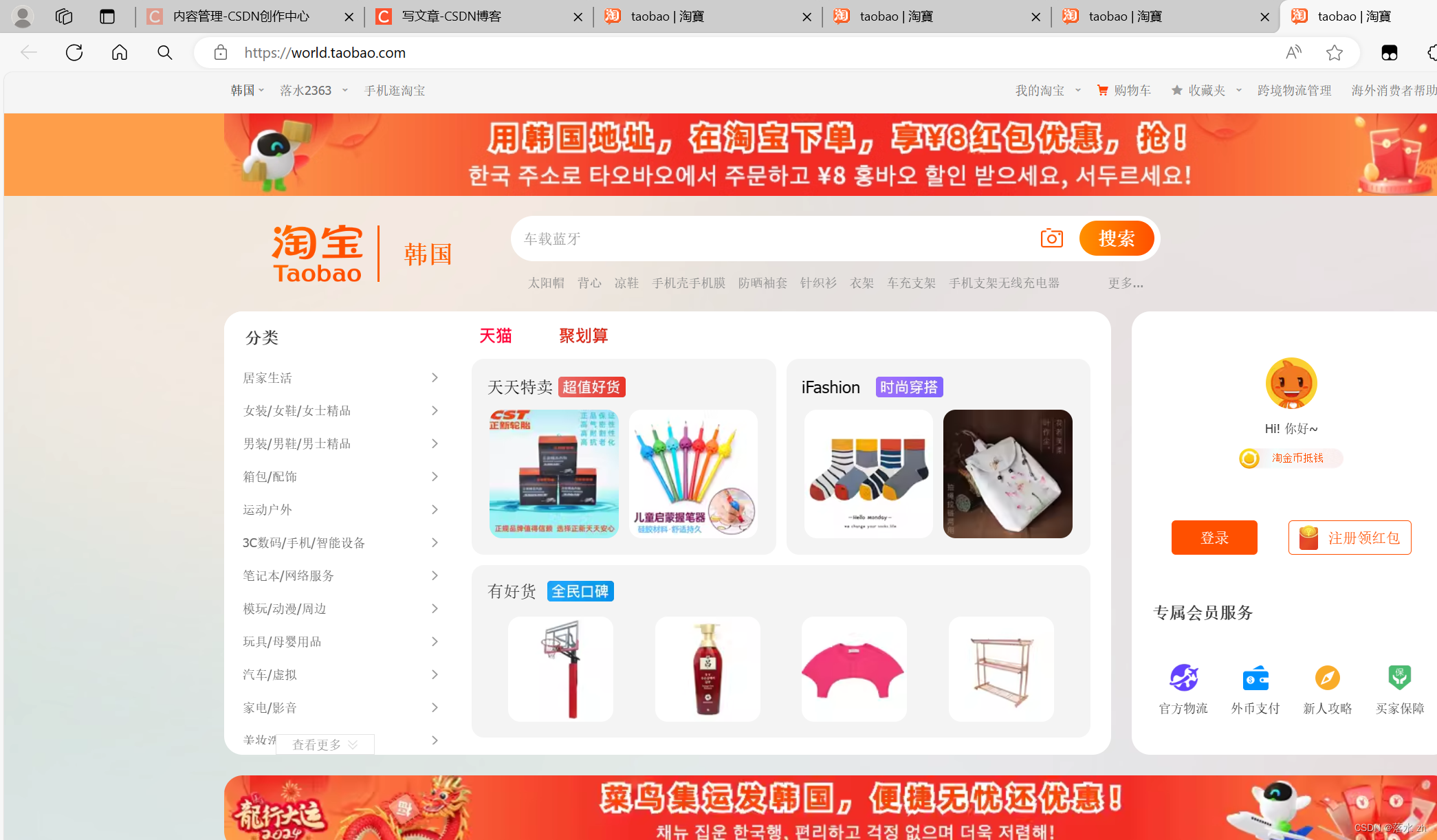
如果不行,大家记得点一下“淘宝”旁边的名字: