深入解析大语言模型显存占用:训练与推理
本篇文章将帮助你优雅又快速地拒绝老板。看完本篇《深入解析大语言模型显存占用:训练与推理》,你将对模型占用显存的问题有个透彻的理解。主要介绍:
如何有效估算一个模型加载后的显存值?
文章脉络
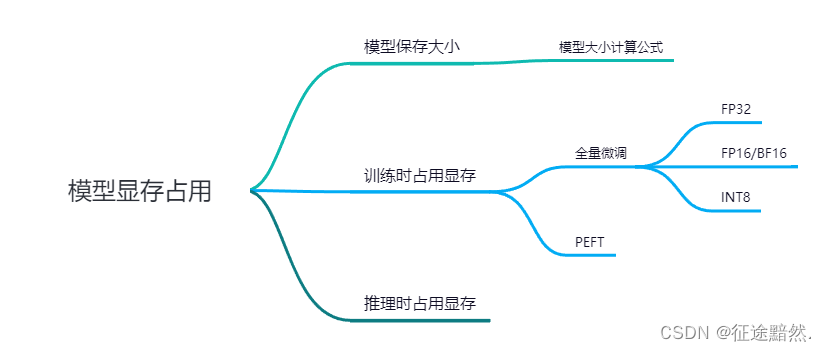
如上面的图1所示,本文将从三个方面介绍大语言模型显存占用估算方法。
第一部分是模型保存大小。以BERT模型举例,BERT的预训练参数保存为.bin文件后的大小是可以用公式估算出来的。
第二部分是模型在训练时占用显存的估算。估算模型在训练时占用的显存是每个NLPer必备的能力。这部分会介绍全量参数微调时占用的显存,而且由于PEFT技术(LoRA、P-Tuning)最近比较火,还会介绍使用PEFT方法训练时的显存估算。
第三部分是模型在推理时占用显存的估算。
估算模型保存大小
话不多说先上公式:
模型大小 ( G B ) = 模型参数量 ∗ 参数类型所占字节数 102 4 3 模型大小(GB) = \frac{模型参数量 * 参数类型所占字节数}{1024^3} 模型大小(GB)=10243模型参数量∗参数类型所占字节数
在上面的公式中,模型的参数量我们一般事先会知道(参数量大概成为现在各大AI公司的吹点了),如果实在不知道参数量,在代码里面加载一下模型,然后打印一下也能很快知道,打印模型参数量的代码示例如下:
from transformers import AutoModelForSeq2SeqLM
# 导入模型
model = AutoModelForSeq2SeqLM.from_pretrained(pretrained_path)
print(f'The model has {sum(p.numel() for p in model.parameters() if p.requires_grad):,} trainable parameters')
"""
会得到类似于这样的输出:The model has 582,401,280 trainable parameters
"""
在上面的公式中,不同的参数类型所占的字节有个对比表,如下:
| 类型 | 所占字节 |
|---|---|
| FP32 | 4 |
| FP16 | 2 |
| INT8 | 1 |
不同参数类型往往代表着资源的消耗,理想情况下,我们用FP16训练模型,可以比FP32少用整整一半的显存,确实很香。但是FP16会损失一定的精度,降低模型的表现与效果。而INT8就只能在推理的时候用用了,而且效果也很不理想。
所以说,模型精度和模型速度是个取乎平衡的问题。虽然用FP16训练模型会更快,但是所有组织都会开源FP32的模型参数,甚至我们用混合精度训练模型最终保存的参数也是FP32格式的,这是因为用FP32的模型效果更好。所以一般我们在计算模型保存的大小时,就默认每个参数所占字节为4就好了。
同样以BERT模型举例,它大概是1亿1千万个参数,然后是以FP32形式保存的,每个参数占4个字节,那么BERT模型的参数保存下来占的大小为:
0.40978 ( G B ) = 419.62 ( M B ) = 11000 , 0000 ∗ 4 102 4 3 0.40978(GB) =419.62(MB)= \frac{11000,0000 * 4}{1024^3} 0.40978(GB)=419.62(MB)=1024311000,0000∗4
可以看到图2中BERT模型的bin文件的大小为420MB,和我们预测的419.62MB是差不多的。

同理,mT5模型的参数量大概有58200,0000,所以它的大小为:
2.168 ( G B ) = 58200 , 0000 ∗ 4 102 4 3 2.168(GB) = \frac{58200,0000 * 4}{1024^3} 2.168(GB)=1024358200,0000∗4
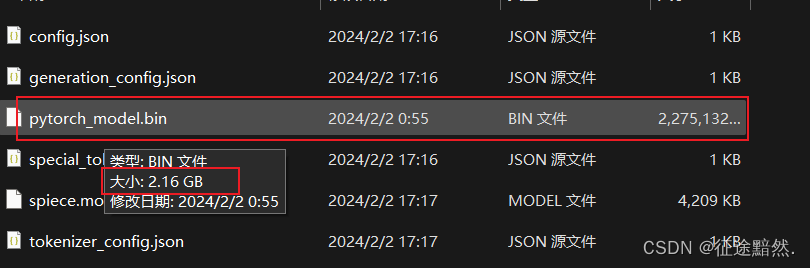
图3中mT5模型的bin文件的大小为2.16GB,和我们预测的2.168GB是差不多的。
估算模型在训练时占用显存的大小
这个部分我们分全量参数训练和PEFT训练两个部分来讲,先讲最基本的全量参数训练。
全量参数训练
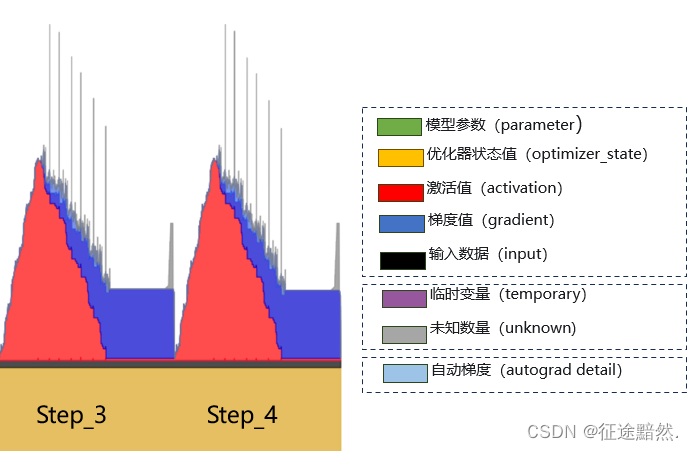
如图4所示,通常来说,模型在训练阶段,显存开销主要有四个部分:模型本身参数(图中绿色)、优化器状态(图中黄色)、梯度(图中蓝色)、正向传播的中间计算结果(图中红色、黑色)。
模型本身参数:静态值,训练时保持不变。模型参数需要加载到显存中参与计算,此部分开销为1倍模型参数量。根据模型的参数类型,最后在算字节的时候,FP32要乘4,FP16要乘2。
优化器状态:静态值,训练时保持不变。主要看优化器的种类,通常Adamw再带一阶动量的话则需要1倍模型参数量,带二阶动量则需要2倍模型参数量。默认用的Adam都是带2阶动量的。根据优化器状态的参数类型,最后在算字节的时候,FP32要乘4,FP16要乘2。
梯度:动态值,训练时呈现波状。一个参数对应一个梯度值,所以是1倍。根据梯度的参数类型,最后在算字节的时候,FP32要乘4,FP16要乘2。
正向传播的中间计算结果:动态值,训练时呈现波状。反向传播中需要对中间层的计算图求导,所以中间层的输出不会被释放。这里的占用资源显然与batch大小、seq长度有关,但难以计算,常用的方法是改batch、seq看显存差值然后去估算。
还有其他零零散散的部分就不纳入考虑了。
于是我们可以粗略的估算出,在FP32的情况下,mT5有58000,0000个参数,那么光是模型本身+优化器+梯度,就要4倍参数的显存大小,也就是8.672GB。那么正常的60系显卡(8GB显存)就玩不动了。
8.672 ( G B ) = 58200 , 0000 ∗ 4 102 4 3 ∗ 4 8.672(GB) = \frac{58200,0000 * 4}{1024^3} * 4 8.672(GB)=1024358200,0000∗4∗4
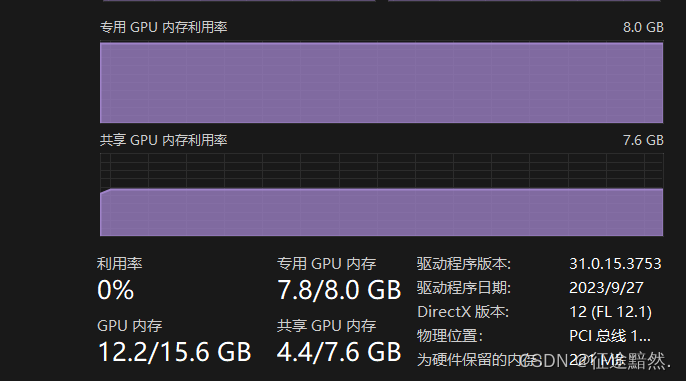
然后再来看下正向传播的中间计算结果大概占用的显存,参考图5,我设置batch=32,seq=10,在翻译任务训练时显存保持在12.2GB,那么减去8.672可以得到正向传播的中间计算结果占用3.528GB的显存。
PEFT训练
GPT-2、T5以及后续的语言模型都已经证明了,在模型的输入中加入前缀,能够让模型去适应不同的任务,完成NLP界的“大一统”。
具体来说,像T5模型,加上前缀“translate English to German”,会自动输出英德翻译的结果,加上前缀“Answer the following yes/no question.”即可完成二分类任务,还有其他的前缀此处不再举例。感兴趣的可以在T5模型页右侧接口API那里自己玩一下https://huggingface.co/google/flan-t5-base。
PEFT 是 “Prompt Engineering for Few-shot Tuning” 的缩写,是一种做few-shot微调的技术,比较火热有Prefix Tuning、P-Tuning、LoRA等。
举个形象生动的例子:拿BERT来举例,常规的全量微调是在BERT最后接入一个fc层并且更新所有的参数来做文本分类;但是PEFT是在BERT内部插入一些fc层,再在BERT最后接入一个fc层,同时冻结BERT的参数,训练这些额外增加的fc层参数。
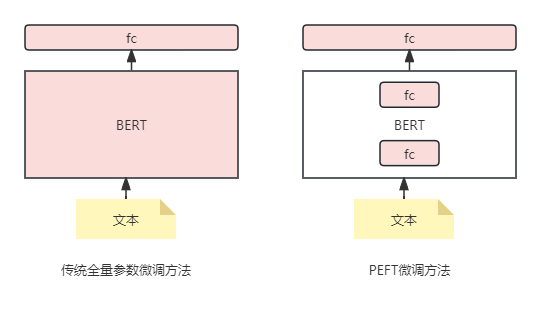
如图6所示,图中红色的部分表示参与梯度更新,白色表示冻结参数,各种PEFT的方法都证明了图6中的方法可以达到很好的效果,而且语言模型本身的参数被冻结了,训练成本将极低。当然PEFT技术并不是简单的在LLM内部插入一些fc层,这里只是举个例子,技术细节还是推荐去看对应的论文。
OK!回归正题,在这种情况下,模型在训练时占用显存的大小如何呢?
同样的,对于一次FP32全量参数微调,假设使用Adam二阶动量,使用了PEFT之后,会增加N个可以训练的参数,原始模型的K个参数会冻结住,那么:
模型本身参数:为K+N。虽然原始模型参数已经被冻结,但是还是需要加载到显存中的。
优化器状态:2N。只有新增的参数可以梯度更新,并采用二阶动量。
梯度:N。只有新增的参数有梯度。
因此,与全量参数训练相比,PEFT节省了3K-4N个可训练参数。
我自己实验了一下,对于mT5模型来说,K=58200,0000,使用了Lora后N=884,736,所以两者显存差值(3K-4N >> 6.49GB),所以PEFT对于资源的节省还是非常非常可观的。
对于正向传播的中间计算结果大概占用的显存,仍然是把实验跑起来,人工来计算,采用与之前相同的配置,用PEFT的LoRA方法实验结果如下图7所示。在翻译任务训练时显存保持在5.3GB,那么减去PEFT方法占用的显存(K+4N >> 2.18GB)可以得到正向传播的中间计算结果占用3.12GB的显存。
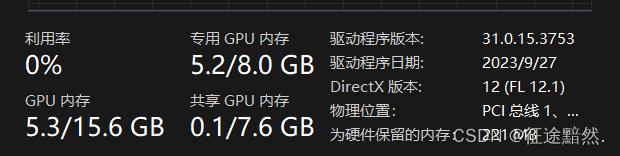
综合来看,PEFT能显著减少优化器状态和梯度这两个方面的显存开销,在正向传播的中间计算结果显存开销略微减少。
估算模型在推理时占用显存的大小
在推理时,占用显存的只有模型本身参数、正向传播的中间计算结果。
我用图7中的mT5模型PEFT方法训练好的模型进行了batch=1的推理,观测到显存最大占用为3.3GB。
说明,推理时正向传播的中间计算结果的显存=3.3-2.18=1.12GB。所以推理时正向传播的中间计算结果的显存也不能简单的拿训练时的占用情况来除以batch_size。可能还是有缓存(Flash Attention之类的)、波束搜索等等其他原因,这要看transformers库的具体实现代码了。
总之,推理时显存占用是很少的。
总结
🏆在这篇博客中,我们深入探讨了大型语言模型在训练和推理过程中对显存的占用问题。
⭐介绍了如何估算模型保存后的大小。
⭐讨论了全量参数训练和PEFT训练两种情况下模型显存占用的估算方法。并且以BERT和mT5模型为例子,解释了如何计算模型参数量和不同参数类型所占的字节数。
⭐最后分析了模型在推理时占用显存的大小。










