前言
阿里巴巴近日震撼开源其最新力作——Qwen1.5-32B大语言模型。在当前AI领域,大模型的开发与应用已成为评估技术进步的重要标尺。Qwen1.5-32B的问世,不仅再次证明了阿里在AI技术研发领域的深厚实力,更是在性能与成本之间找到了一个新的平衡点。
Qwen1.5-32B模型简介
Qwen1.5-32B继承了Qwen系列模型的卓越传统,拥有320亿参数,是在Qwen1.5系列中规模适中、性价比极高的模型。这一新成员不仅在多项评测中轻松超越了此前最强的开源大模型Mixtral 8×7B MoE,甚至在某些方面接近或超过了720亿参数的Qwen1.5-72B模型,展现出了非凡的性能。

核心优势
Qwen1.5-32B模型的最大亮点在于其卓越的性价比。与参数量更大的模型相比,Qwen1.5-32B所需的显存仅为一半,这意味着在维持高性能输出的同时,大幅降低了使用门槛。这一特点使得Qwen1.5-32B不仅适用于研究机构的深入研究,也能够被广大AI爱好者及小型团队应用于实际项目中,极大地扩展了其使用范围。
Qwen1.5-32B模型的技术创新主要体现在两方面:首先是其高效的模型架构,使得在较低的计算资源消耗下依然能保持高性能输出;其次是在训练过程中引入的grouped query attention (GQA)技术,进一步提高了推理效率。此外,Qwen1.5-32B模型还采用了基于人类反馈的强化学习对齐训练,显著提升了模型在多轮对话中的表现能力。
模型效果
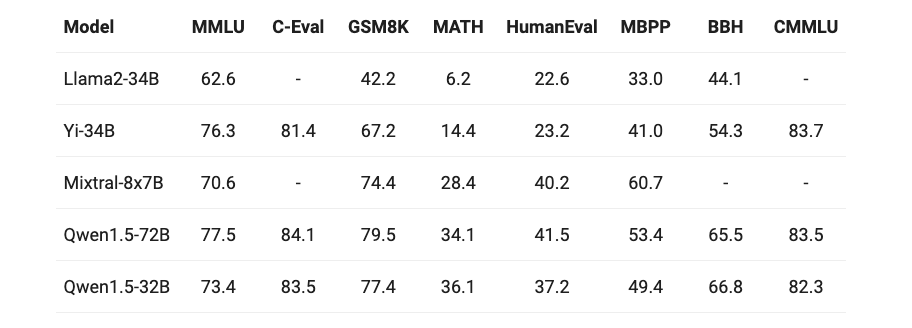
在多项业界标准评测中,Qwen1.5-32B的性能均表现卓越。它在多模态语言理解(MMLU)、数学问题求解(Math)、编程问题生成(HumanEval)等基准测试中取得了高分,甚至在某些领域超越了同类中规模更大的模型。特别是在GSM8K测试中,Qwen1.5-32B以77.4%的得分显著超过了其他300亿参数规模的模型,验证了其在处理数学问题上的出色能力。
Qwen1.5-32B的多语言能力进行了测试,涵盖了包括阿拉伯语、西班牙语、法语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语和印尼语在内的12种语言,涉及考试、理解、数学及翻译等多个领域。具体结果如下所示:
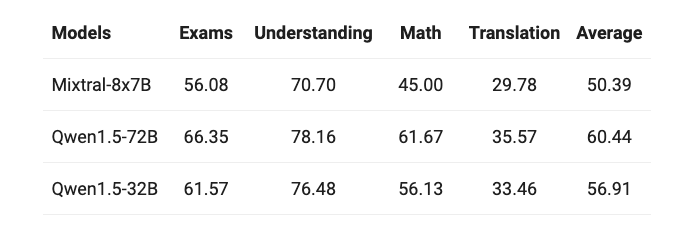
与其他Qwen1.5模型相似,32B版本同样具备出色的多语言能力,其表现略逊于72B模型。
最后,我们关注其在长文本评估任务“大海捞针”中的表现,令人欣喜的是,该模型能够在长达32K tokens的上下文中实现了优秀的表现。

应用前景
Qwen1.5-32B模型的发布,不仅是阿里巴巴在AI领域的又一次技术展示,也为AI的研究与应用提供了更多可能性。该模型的高性能与低资源消耗,使其在多种应用场景下都有广泛的应用前景,包括但不限于语言理解、自然语言生成、对话系统等。
结论
阿里巴巴此次开源的Qwen1.5-32B模型,以其卓越的性能、高效的资源利用率和开放的使用条件,为全球的AI研究者和开发者提供了一个宝贵的资源。期待Qwen1.5-32B模型在未来能够助力更多的技术创新和应用突破。
获取更多最新大模型资讯,可关注我们(微信公众号:努力犯错玩AI)期待您的到来!

