开源地址:gitee | github
详细介绍:MyData 基于 Web API 的数据集成平台
部署文档:用 Docker 部署 MyData
使用手册:MyData 使用手册
试用体验:https://demo.mydata.work
交流Q群:430089673
介绍
本篇基于 数据集成之任务流程 介绍任务分批传输的使用场景和配置操作。
使用场景
mydata使用API方式集成数据,当一次请求或响应 传输数据量较多时 可能无法完成、或容易对服务端造成影响,因此需要分为多次处理;
例如 常见的分页查询、导入大量数据时分批处理、集成对接时的全量同步等;
分批传输数据
业务系统与mydata集成时,在提供数据和消费数据这两个方向上分别实现分批传输;
提供数据
由mydata调用应用的API获取数据,通过配置分批参数 实现一次任务内多次调用API获取完整数据,有以下两种基本的配置模式:
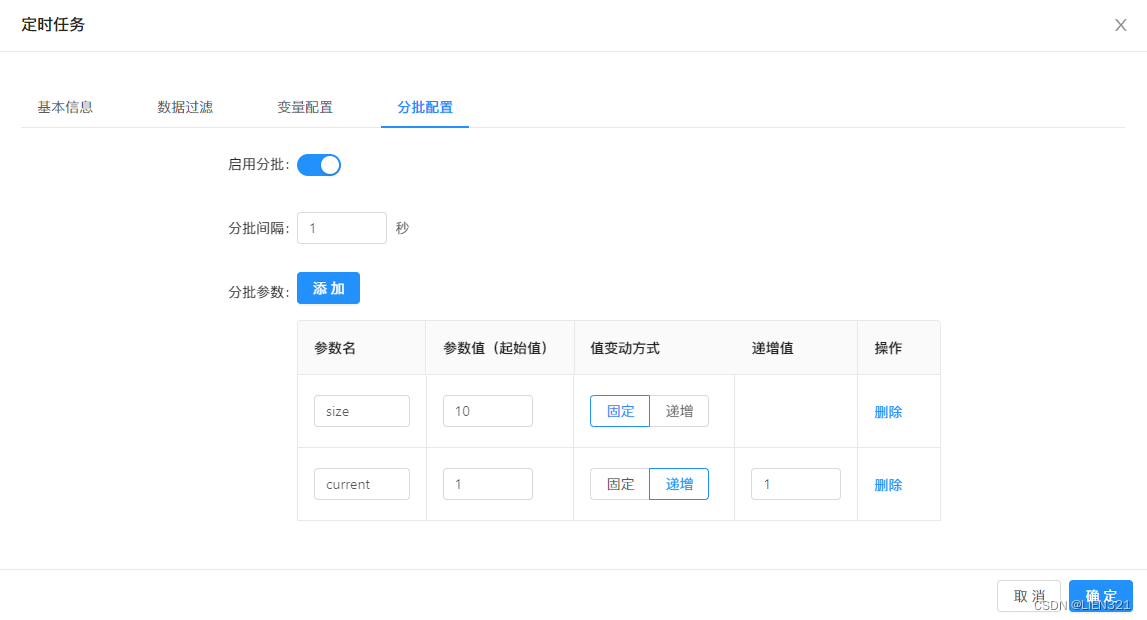
- 配置了
固定参数size=10、递增参数current从1开始每次递增1、每次间隔1秒的任务;
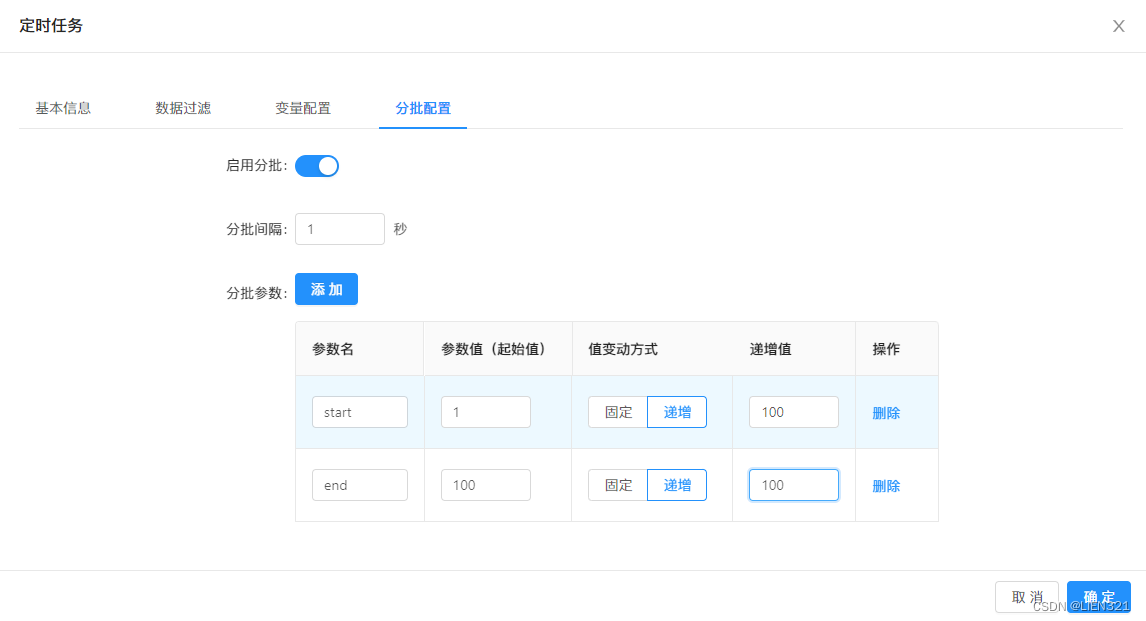
- 配置了
递增参数start从1开始每次递增100、递增参数end从100开始每次递增100、每次间隔1秒的任务;
执行过程如下代码,要点有:
-
通过do-while结构 兼容单次和分批;
-
用
lastProduceData记录上一次数据,用于和本次对比数据,若重复 则结束,避免死循环(理论上很少有2次完全一样的数据); -
若分批有异常,则复用任务3次出错 自动结束并发送邮件通知的功能;
-
执行完一次后,自动计算递增参数值;
// 提供数据
case MdConstant.DATA_PRODUCER:
// 分批模式 记录上一次数据,用于对比两次数据,若重复 则结束,避免死循环
List<Map> lastProduceData = null;
do {
// 若启用分批,则将分批参数加入请求参数中
if (taskInfo.isBatch()) {
Map<String, Object> batchParam = jobBatchService.parseToMap(taskInfo);
Map<String, Object> reqParams = MapUtil.union(taskInfo.getReqParams(), batchParam);
taskInfo.setReqParams(reqParams);
}
// 调用api 获取json
String json = ApiUtil.read(taskInfo);
// 将json按字段映射 解析为业务数据
jobDataService.parseData(taskInfo, json);
// 若没有返回数据,则结束处理
if (CollUtil.isEmpty(taskInfo.getProduceDataList())) {
break;
}
// 对比上一次数据
if (lastProduceData != null) {
if (CollUtil.isEqualList(lastProduceData, taskInfo.getProduceDataList())) {
// 异常任务失败,邮件通知用户检查任务
throw new RuntimeException("分批获取数据异常,最后两次获取的数据相同!");
}
}
lastProduceData = taskInfo.getProduceDataList();
// 根据条件过滤数据
jobDataFilterService.doFilter(taskInfo);
// 保存业务数据
jobDataService.saveTaskData(taskInfo);
// 更新环境变量
jobVarService.saveVarValue(taskInfo, json);
// 递增分批参数
jobBatchService.incBatchParam(taskInfo);
// 若启用分批,则等待间隔
if (taskInfo.isBatch()) {
ThreadUtil.sleep(taskInfo.getBatchInterval(), TimeUnit.SECONDS);
}
} while (taskInfo.isBatch());
break;
消费数据
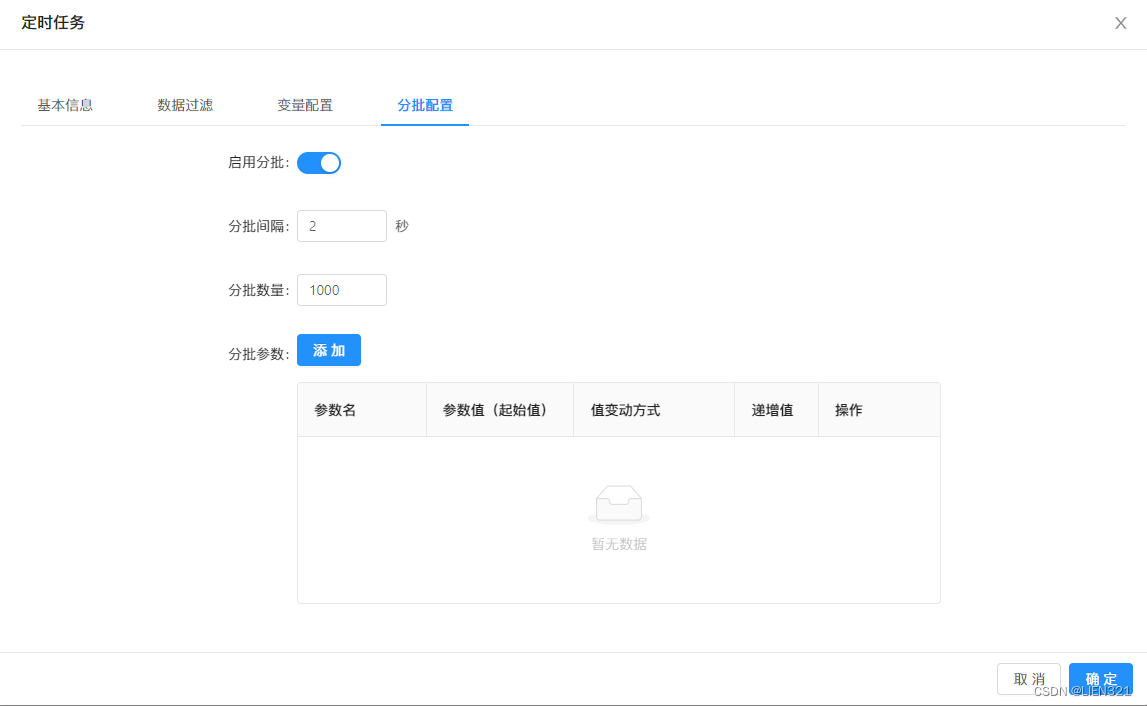
由mydata通过API向应用发送数据,通过配置分批参数 限制每次向API发送的数据量,从而减少数据查询量和请求处理时间;
如下图,配置了分批数量为1000的任务,分批参数为选填,mydata将按1000为限制查询符合条件的数据,通过API请求发送给应用;
执行过程如下代码,要点有:
- 通过do-while结构 兼容单次和分批;
- 自动管理分页参数,执行分页查询数据,发送给API;
- 直到分页查询没有数据 自动结束;
// 消费数据
case MdConstant.DATA_CONSUMER:
String dataCode = taskInfo.getDataCode();
if (StrUtil.isEmpty(dataCode)) {
break;
}
List<BizDataFilter> filters = taskInfo.getDataFilters();
if (CollUtil.isNotEmpty(filters)) {
// 解析过滤条件值中的 自定义字符串
parseFilterValue(filters);
// 排除值为null的条件
filters = filters.stream().filter(filter -> filter.getValue() != null).collect(Collectors.toList());
}
int round = 0;
Long skip = null;
Integer limit = taskInfo.isBatch() ? taskInfo.getBatchSize() : null;
do {
if (taskInfo.isBatch()) {
skip = (long) round * taskInfo.getBatchSize();
}
// 根据过滤条件 查询数据
List<Map> dataList = bizDataDAO.list(MdUtil.getBizDbCode(taskInfo.getTenantId(), taskInfo.getProjectId(), taskInfo.getEnvId()), dataCode, filters, skip, limit);
if (CollUtil.isEmpty(dataList)) {
break;
}
taskInfo.setConsumeDataList(dataList);
// 根据字段映射转换为api参数
jobDataService.convertData(taskInfo);
// 调用api传输数据
ApiUtil.write(taskInfo);
round++;
// 若启用分批,则等待间隔
if (taskInfo.isBatch()) {
ThreadUtil.sleep(taskInfo.getBatchInterval(), TimeUnit.SECONDS);
}
}
while (taskInfo.isBatch());
break;










