学习transformer模型-用jupyter演示如何计算attention,不含multi-head attention,但包括权重矩阵W。
input embedding:文本嵌入
每个字符用长度为5的向量表示:

注意力公式:


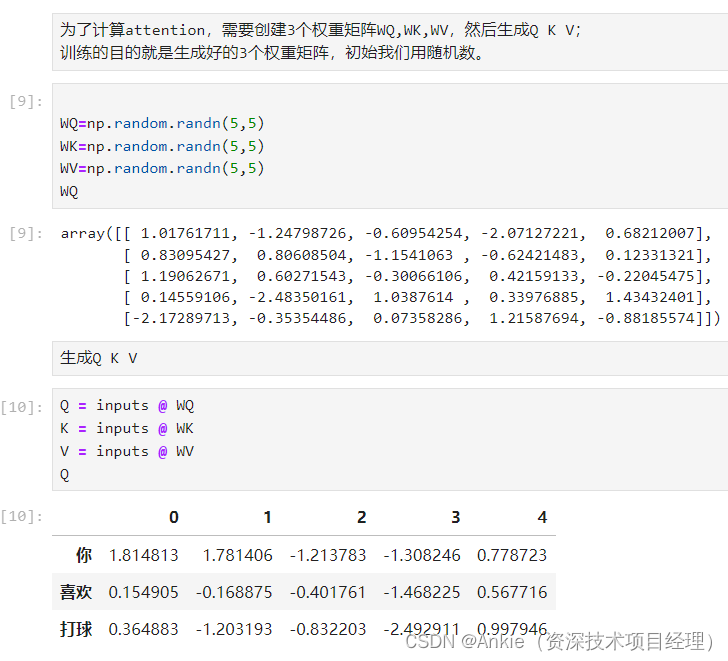
1,准备Q K V:
先 生成权重矩阵WQ,WK,WV。权重矩阵W*是训练的目标。
再生成 Q K V。
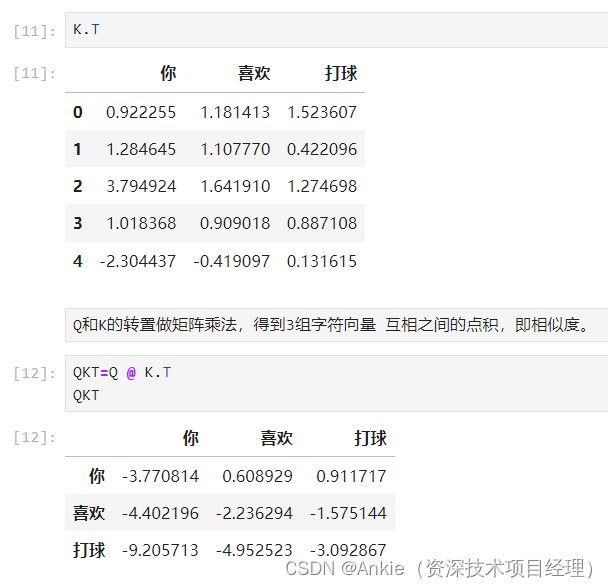
2,计算Q和K的点积,即相似度。
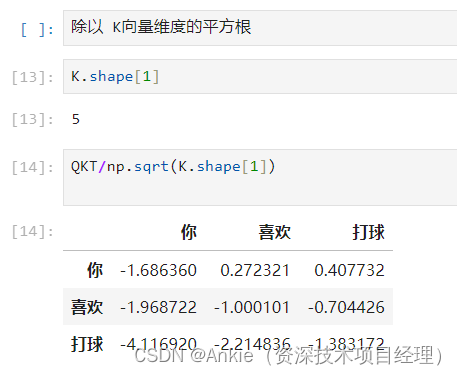
3, 除以 K向量维度的平方根,好做softmax,不然比例计算会失衡。
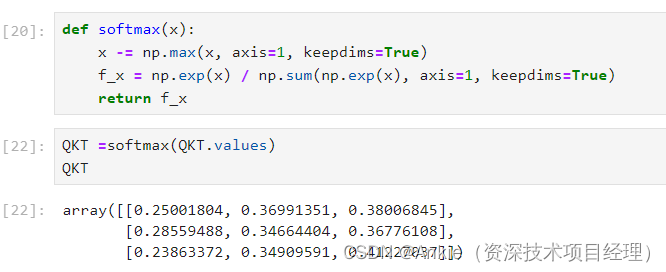
4,做softmax,得出百分比。
5,百分比再跟V相乘,得出attention











