Jenkins支持的JDK版本17、21,通过java -version查看当前JDK版本,确认是否匹配
- 打开网址https://www.jenkins.io/download
点击下载,选择mac版本
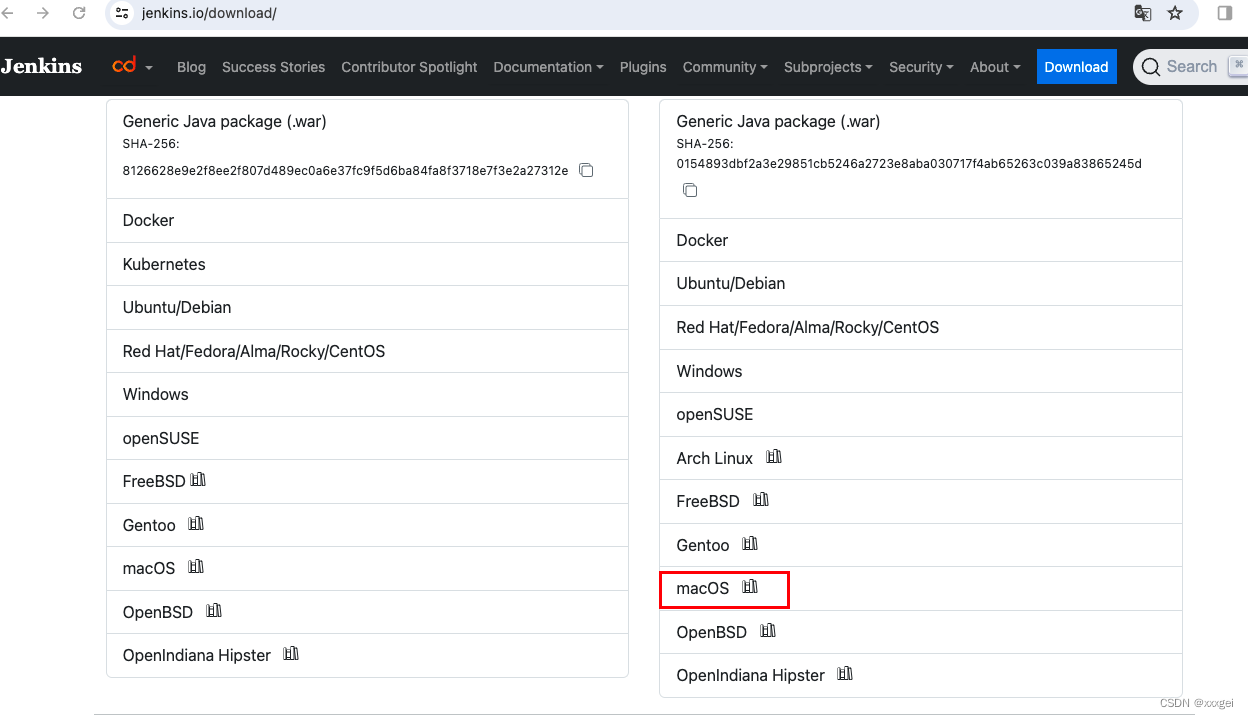
- commend+空格打开终端,输入安装命令
brew install jenkins
安装完成后输入brew services start jenkins启动jenkins
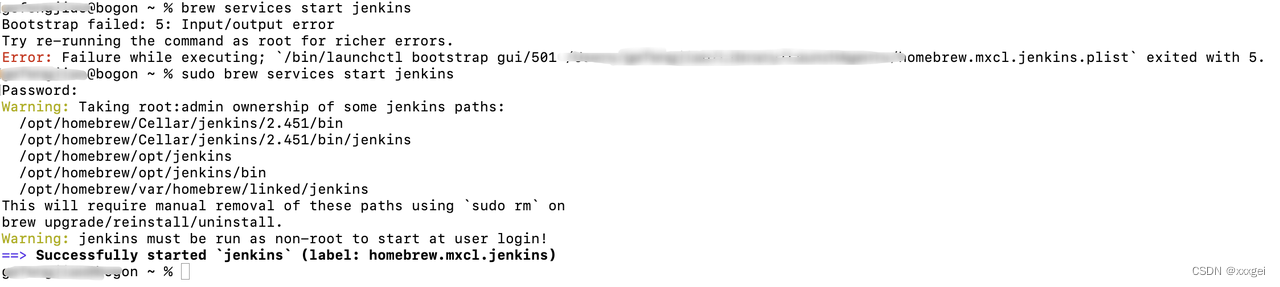
我在启动时报IO error,可尝试用管理者启动,命令:sudo brew services start jenkins
如果还不行,尝试使用另一个启动命令: brew services restart jenkins-lts
-
提示成功后,浏览器打开localhost:8080会进到登录页面
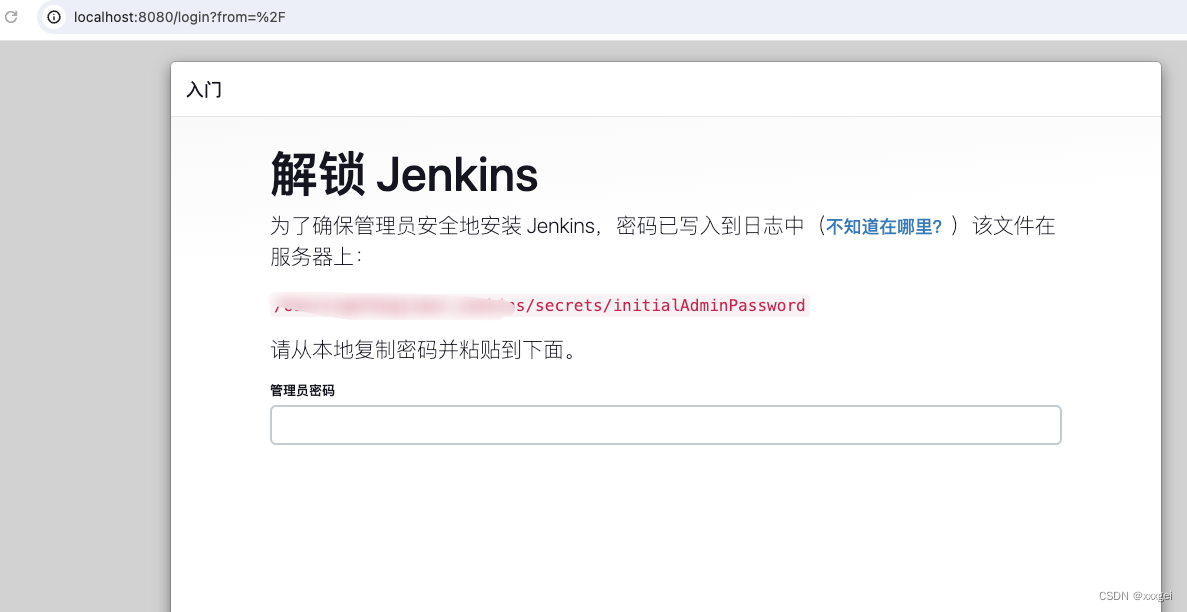
-
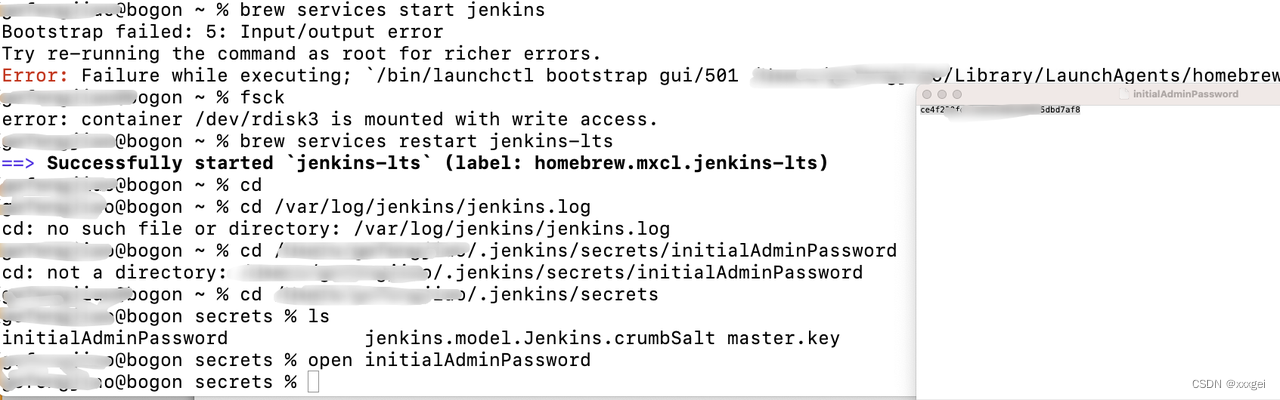
进入日志文件中,获取密码
cd /Users/xxxx/.jenkins/secrets
open initialAdminPassword
-
选择自定义,等待安装完成即可,如果有失败的直接跳过,后面可以再安装
![[图片]](https://file.cfanz.cn/uploads/png/2024/04/02/11/ddc0556QV2.png)
-
创建管理员账号
![[图片]](https://file.cfanz.cn/uploads/png/2024/04/02/11/2Y8CMFW4HN.png)
-
设置URL地址
![[图片]](https://file.cfanz.cn/uploads/png/2024/04/02/11/3O0dd9Ld10.png)
-
全部配置完成,进入jenkins主页面
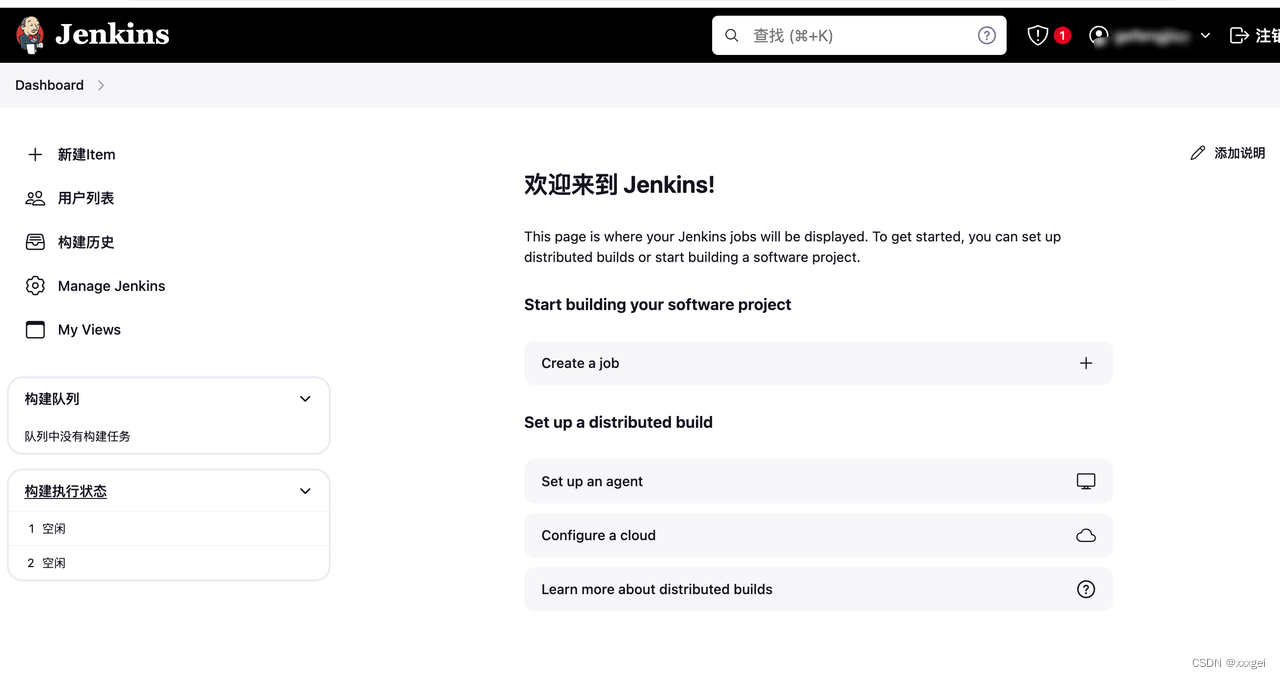
以上就是Jenkins的下载和安装啦~~
下面是集成jmeter并生成测试报告的操作步骤
一、使用自由模式集成jmeter串行执行多个压测脚本并生成测试报告
-
点击【新建任务】,输入任务名称,选择“自由风格”,点击确认按钮
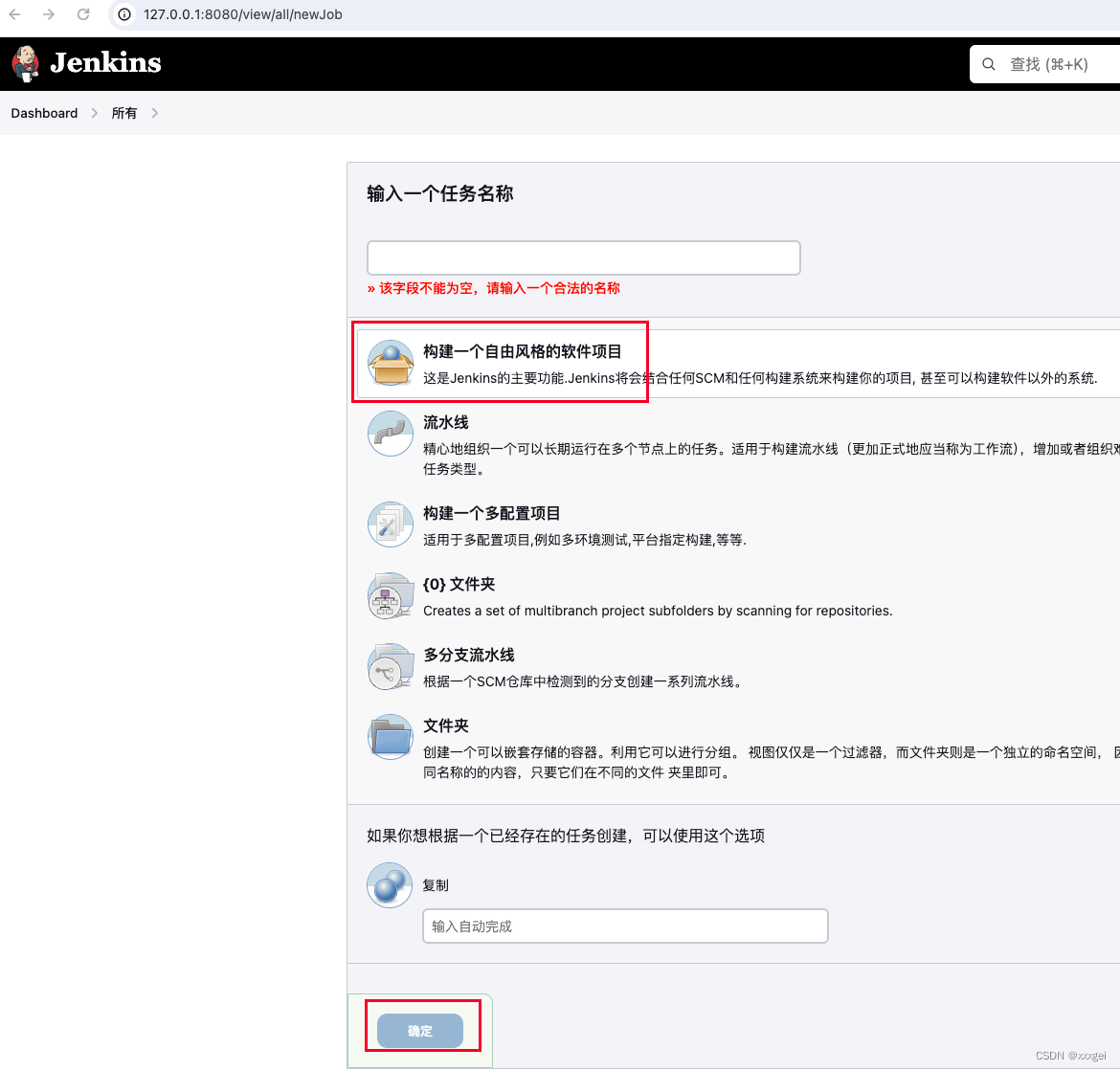
-
进入配置页面,选择【添加构建步骤-执行shell】
脚本如下,先进入到本地jmeter安装路径的bin目录下,把上次执行的结果csv文件和report全部删除,再执行第一个压测脚本,执行后将进程置于后台,并获取进程id,等待进程ID释放,执行完成后再启动第二个压测脚本,这样保证了每个脚本是独立执行互不干扰的
cd /Users/xxx/downloads/apache-jmeter-5.6.2/bin
find /Users/xxx/downloads/autotest/script/ -type f -name "*.csv" -exec rm {} \;
rm -rf /Users/xxx/downloads/autotest/script/report/*
./jmeter.sh -n -t /Users/xxx/downloads/autotest/script/script1.jmx -Jnum_threads=1 -Jramp_up_time=1 -Jduration=5 -l /Users/xxx/downloads/autotest/script/script1_result.csv -e -o /Users/xxx/downloads/autotest/script/report/script1
pid1=$!
wait $pid1
./jmeter.sh -n -t /Users/xxx/downloads/autotest/script/script2.jmx -Jnum_threads=20 -Jramp_up_time=1 -Jduration=2 -l /Users/xxx/downloads/autotest/script/script2_result.csv -e -o /Users/xxx/downloads/autotest/script/report/script2
-
Jnum_threads字段在jmx中通过表达式${__P(num_threads)}引用,其他字段同理,如图
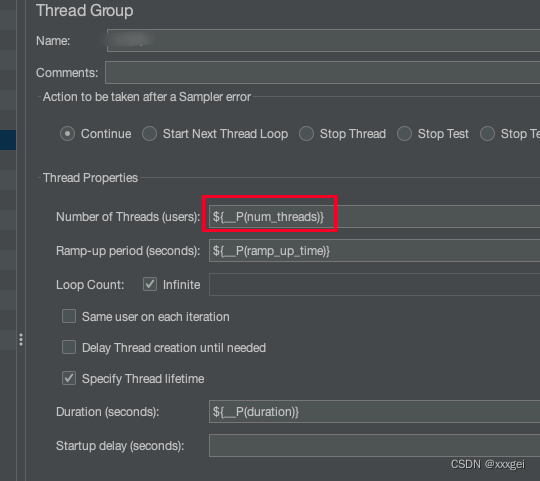
-
添加构建后操作生成report,选择【增加构建后操作步骤-Publich HTML reports】
HTML directory to archive:填写本地存放测试报告的空文件夹路径
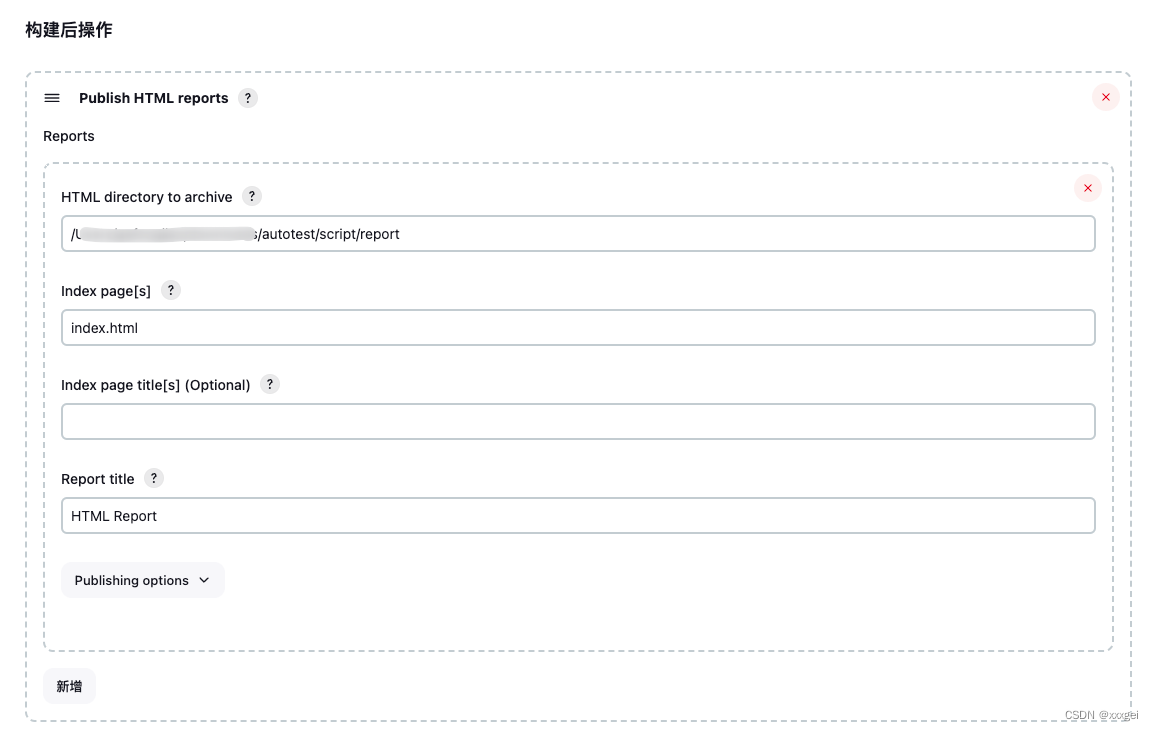
如果没有对应插件可以去下载,【系统管理-插件管理】
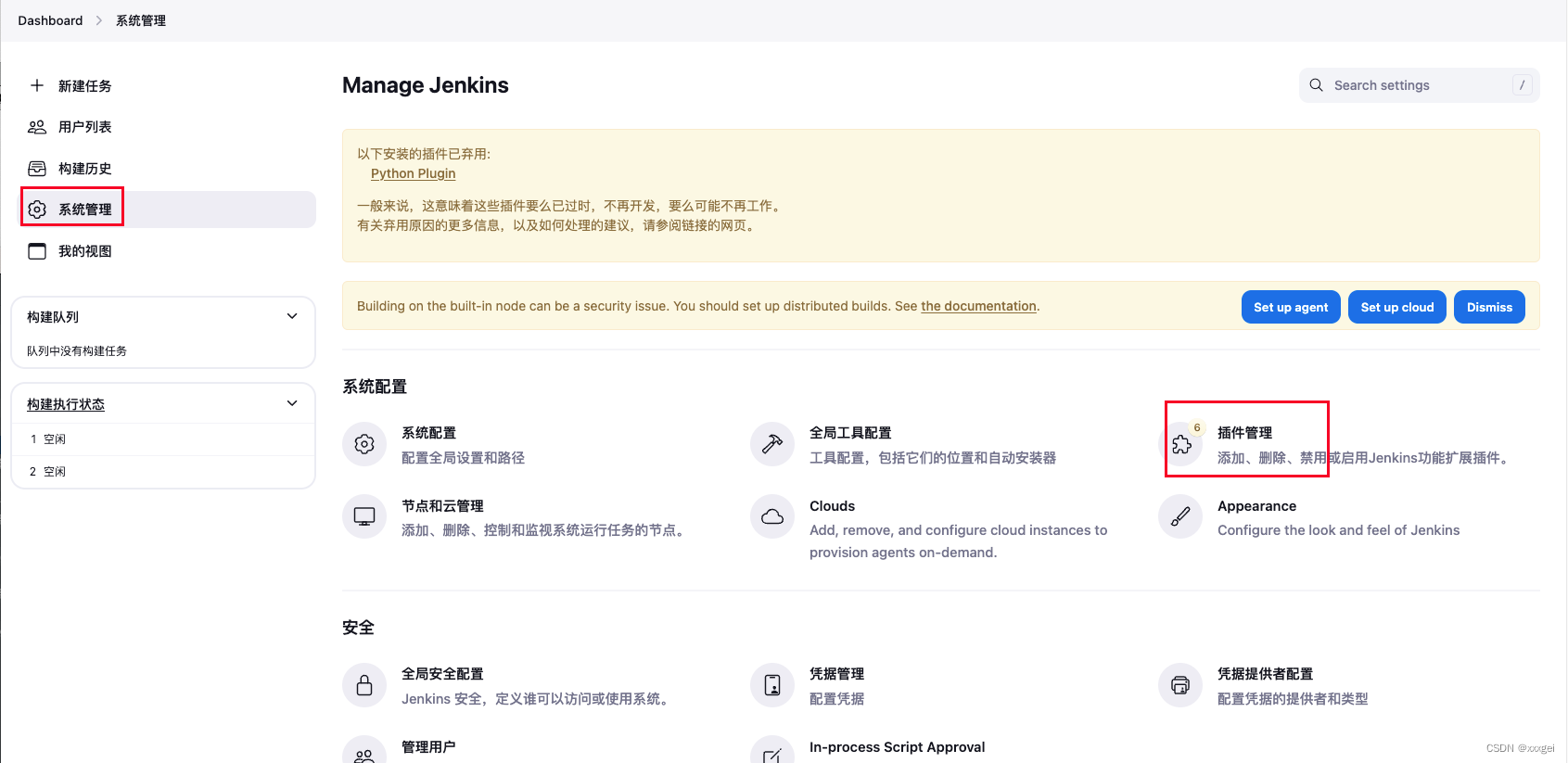
点击【可用插件】,搜索需要的插件,然后勾选安装即可
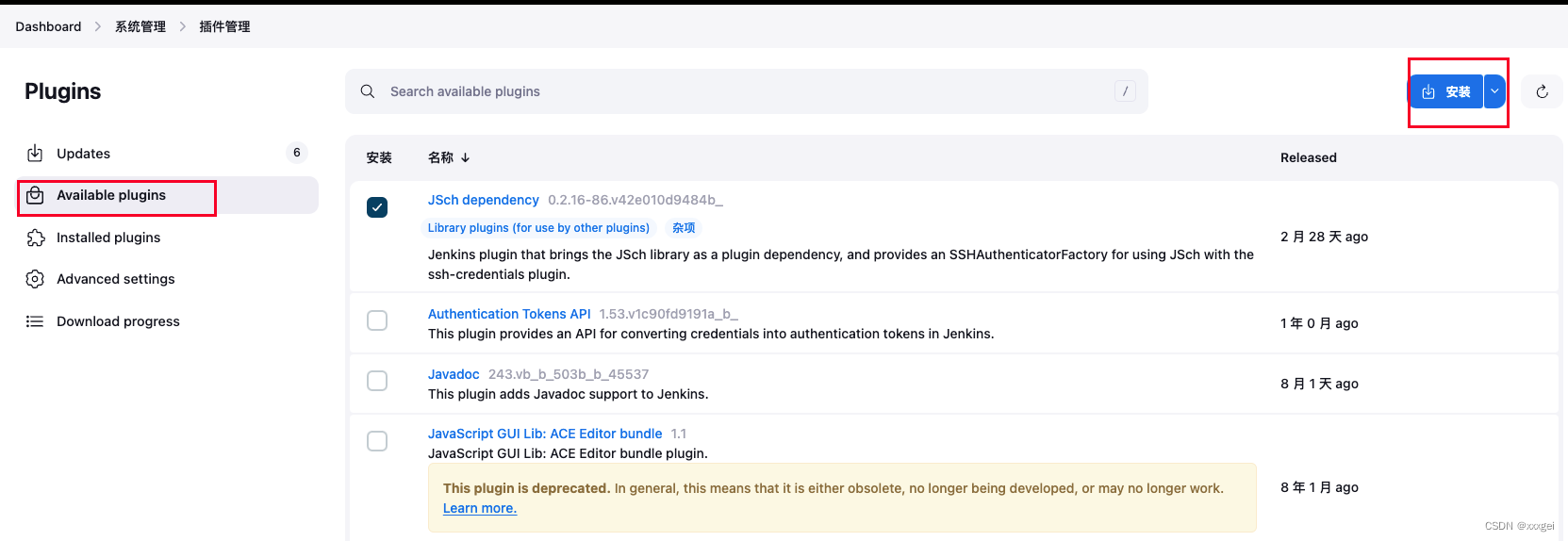
-
全部配置完成,点击保存,在项目目录下,点击【立即构建】即可执行脚本并生成测试报告,点击构建历史可进入对应详情页
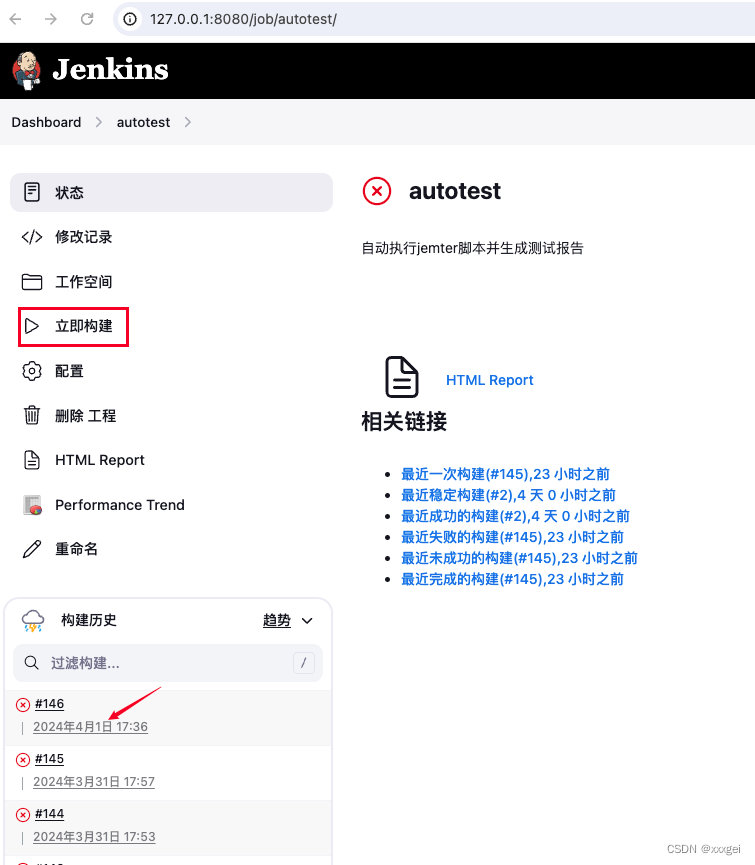
-
点击【控制台输出】可查看日志
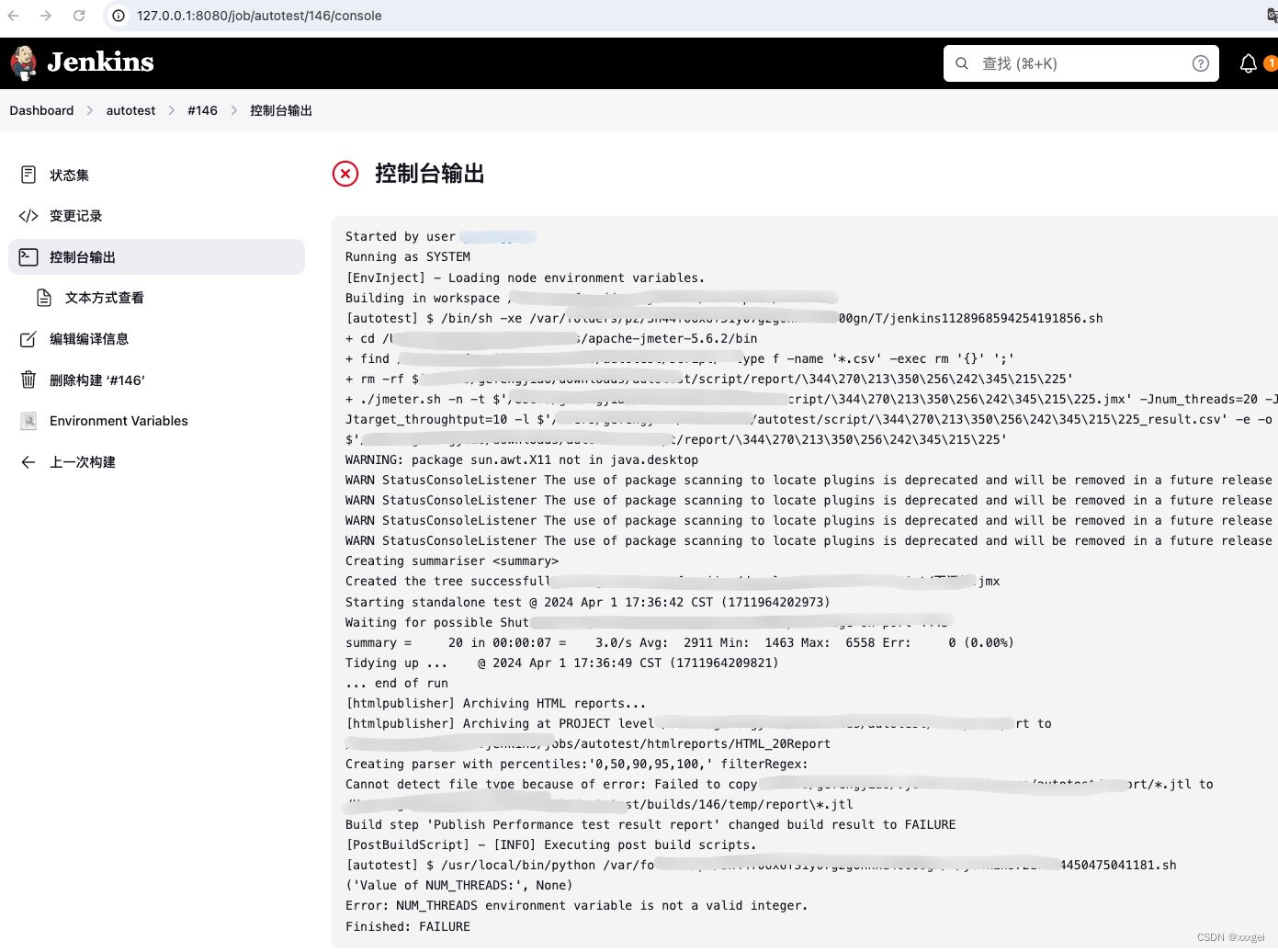
-
html格式的测试报告也会生成到指定文件夹下
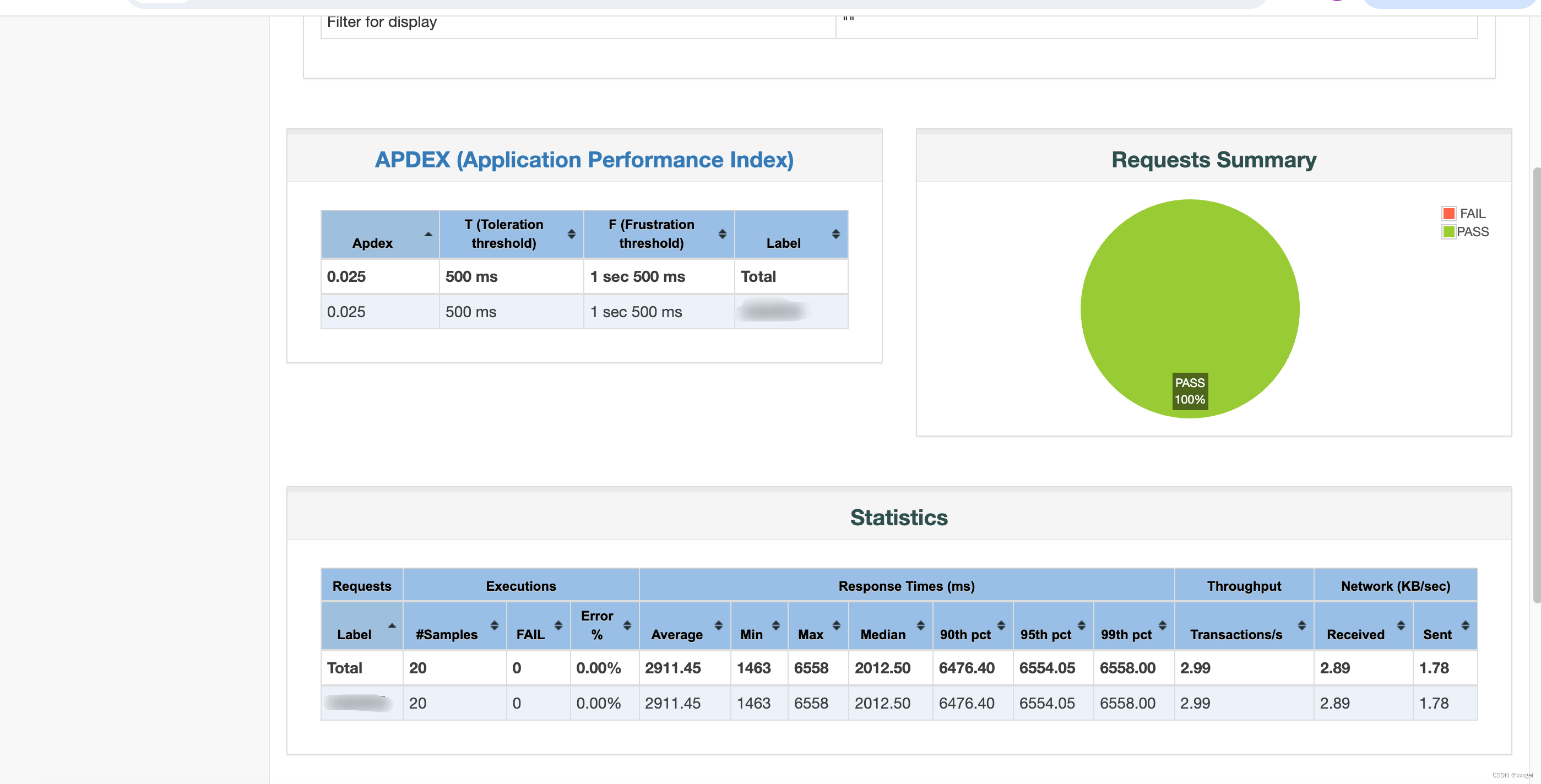
经过多次测试发现:
Jmeter中聚合报告里的吞吐量计算存在误差,如果是单接口误差较小,多接口的话误差较大,不具备参考价值,因此需要手动计算,公式=线程数/平均响应时间,线程数是用户手动设置的Num
of Threads(users),并非测试报告中的样本数量
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
二、 使用自由模式-参数化构建过程执行单个压测脚本并将结果写入本地CSV
在此方法中,将执行的详细结果写入csv中,通过添加构建后操作使用python脚本获取并计算正确的吞吐量
-
进入项目的配置页面,勾选【参数化构建过程-文本参数】,输入线程数名称如:Jnum_threads,可设置多个参数
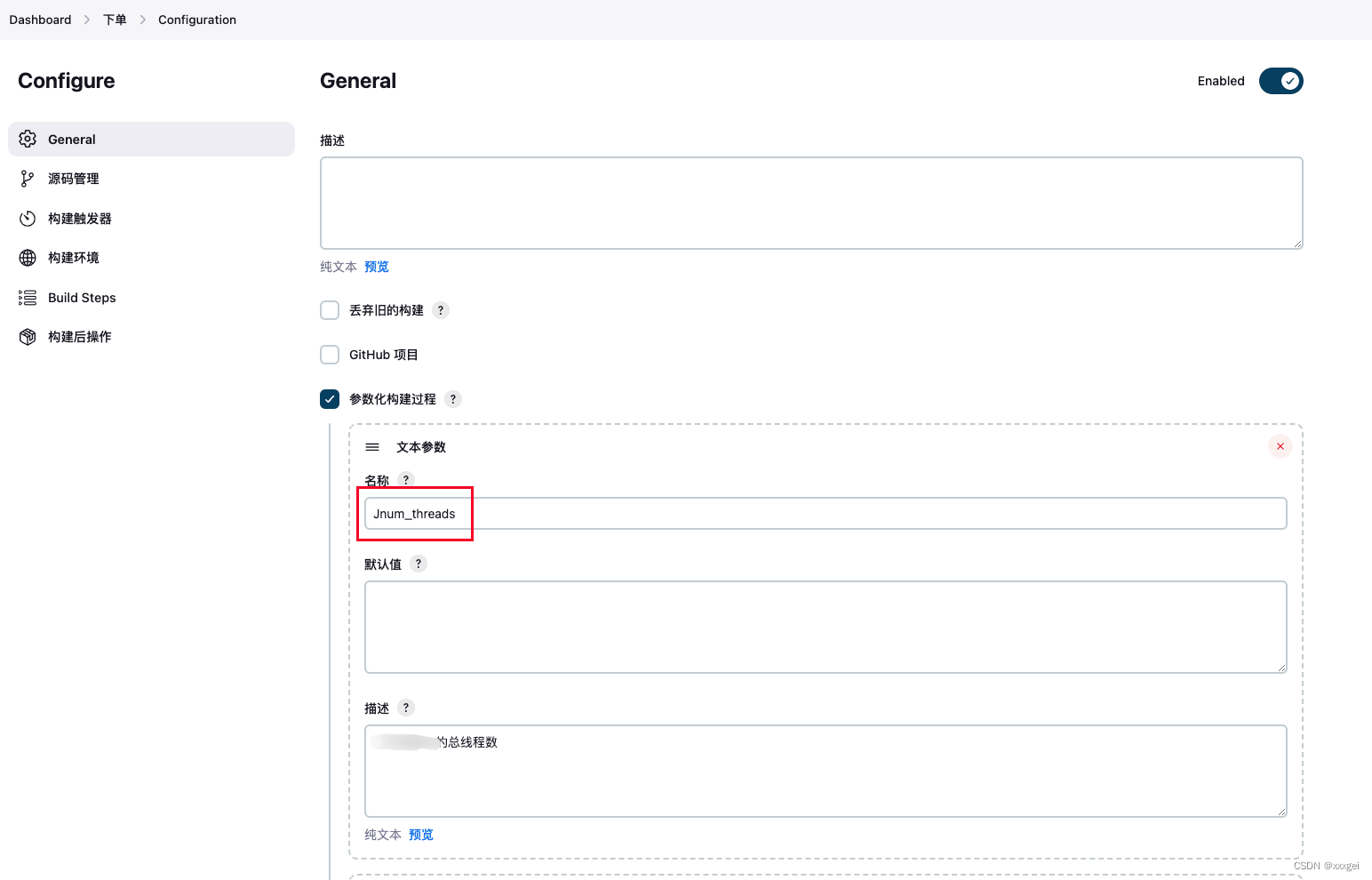
-
选择【添加构建步骤-执行shell】 脚本中通过-Jnum_threads=${Jnum_threads}来获取上面设置的参数
cd /Users/xxx/downloads/apache-jmeter-5.6.2/bin
find /Users/xxx/downloads/autotest/script/ -type f -name "*.csv" -exec rm {} \;
rm -rf /Users/xxx/downloads/autotest/script/report/*
./jmeter.sh -n -t /Users/xxx/downloads/autotest/script/script1.jmx -Jnum_threads=${Jnum_threads} -Jramp_up_time=${Jramp_up_time} -Jduration=${Jduration} -l /Users/xxx/downloads/autotest/script/script1_result.csv -e -o /Users/xxx/downloads/autotest/script/report/script1
- 选择【增加构建后操作步骤-Execute scripts-执行shell】
构建步骤中已经通过命令-l /Users/xxx/downloads/autotest/script/script1_result.csv将压测详细结果写入csv中,供这一步计算QPS使用
以下脚本将压测的接口地址、全部样本的状态码及个数、压测接口的平均响应时间、QPS打印到csv中
#!/usr/local/bin/python #使用which python命令获取python路径
# -*- coding: utf-8 -*-
import sys
import csv
import os
def read_csv(file_path):
response_code_count = {}
elapsed_sum = 0
elapsed_count = 0
url_count = 0
# 根据Python版本选择不同的open函数参数
if sys.version_info.major == 2:
with open(file_path, 'rb') as file:
reader = csv.DictReader(file)
for row in reader:
response_code = row['responseCode']
elapsed = float(row['elapsed'])
response_code_count[response_code] = response_code_count.get(response_code, 0) + 1
#多接口情况下,获取指定接口url的个数,用于计算平均响应时间
if row['URL'] == 'http://baidu.com:808/x/x/x':
elapsed_sum += elapsed
elapsed_count += 1
url_count += 1
elif sys.version_info.major == 3:
with open(file_path, 'r', newline='', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
response_code = row['responseCode']
elapsed = float(row['elapsed'])
response_code_count[response_code] = response_code_count.get(response_code, 0) + 1
if row['URL'] == 'http://baidu.com:808/x/x/x':
elapsed_sum += elapsed
elapsed_count += 1
url_count += 1
return response_code_count, elapsed_sum, elapsed_count, url_count
def write_to_csv(file_path, data):
with open(file_path, 'w') as file:
writer = csv.writer(file)
writer.writerow(["URL", "全部线程的状态码及个数","平均响应时间(S)","实际QPS"])
writer.writerow(data)
def main():
#将压测的详细结果写入指定目录下的csv中
file_path = '/Users/xxx/downloads/autotest/script/script1_result.csv'
#将手动计算的结果写入指定目录的csv中
output_file_path = '/Users/xxx/downloads/autotest/script/result.csv'
# 输出环境变量的值
num_threads_str = os.environ.get('Jnum_threads')
target_throughtput = os.environ.get('Jtarget_throughtput')
print("Value of NUM_THREADS:", num_threads_str)
# 将 NUM_THREADS 转换为整数
try:
total_requests = int(num_threads_str)
except (ValueError, TypeError):
print("Error: NUM_THREADS environment variable is not a valid integer.")
return
response_code_count, elapsed_sum, elapsed_count, url_count = read_csv(file_path)
# 计算 QPS
qps = 0
avg_elapsed_seconds = None
if elapsed_count > 0:
avg_elapsed_seconds = elapsed_sum / elapsed_count / 1000 # 将毫秒转换为秒
if avg_elapsed_seconds != 0:
qps = total_requests / avg_elapsed_seconds
# 将结果写入 CSV 文件
avg_elapsed_seconds_formatted = '{:.2f}'.format(avg_elapsed_seconds)
qps_formatted = '{:.2f}'.format(qps)
#结果csv的要写入的具体值
write_to_csv(output_file_path, ["http://baidu.com:808/x/x/x", response_code_count,avg_elapsed_seconds_formatted,qps_formatted])
if __name__ == "__main__":
main()
保存构建后选择【Build with Parameters】输入对应参数点击【Build】就开始构建了,最终的执行结果也会写会写入指定的csv中









