在之前的文章中,我们学习了如何在spark中使用键值对中的fullOuterJoin,zip,combineByKey三种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(13)-CSDN博客文章浏览阅读735次,点赞22次,收藏12次。今天开始的文章,我会带给大家如何在spark的中使用我们的键值对方法,今天学习键值对方法中的fullOuterJoin,zip,combineByKeyy三种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。
目录
一、知识回顾
上一篇文章中我们学习了键值对的三种方法,分别是fullOuterJoin,zip,combineByKey。
fullOuterJoin是我们的全外连接,保留两个RDD中所有键与它的值的连接结果。

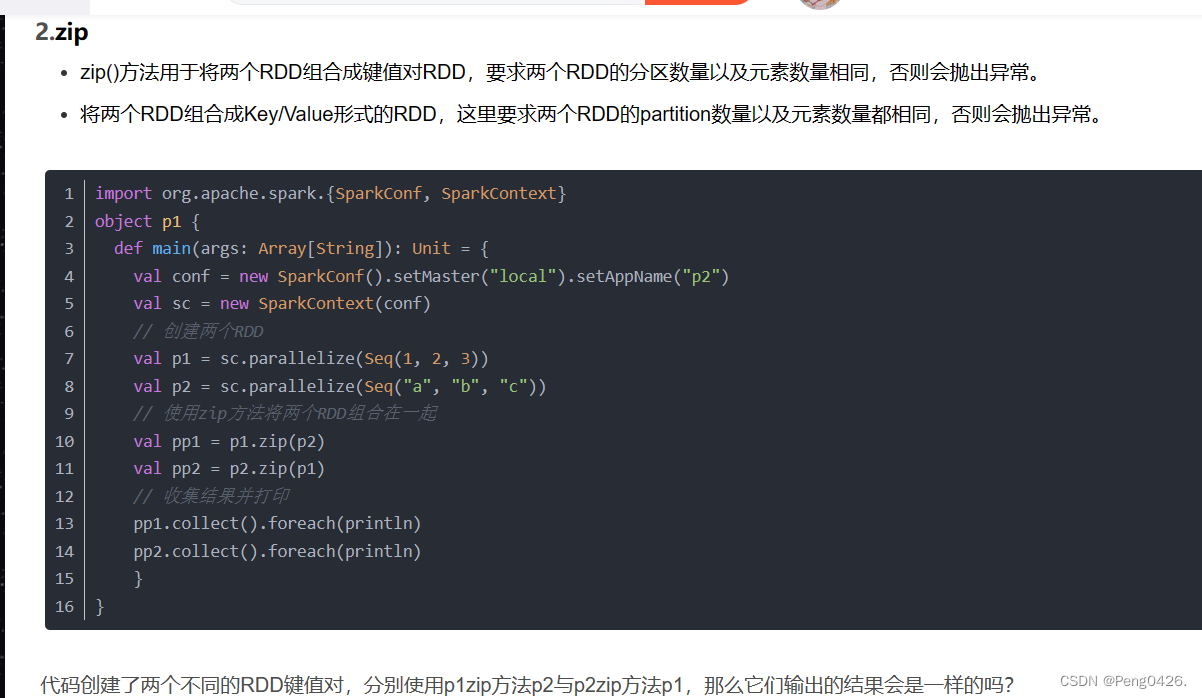
zip方法用于将两个RDD组合成键值对RDD
combineByKey()方法就比较复杂了,推荐还是去上一篇文章中复习一下,这边展示一下用法。
 现在开始今天的学习吧~
现在开始今天的学习吧~
二、键值对方法
1.lookup
- lookup(key:K)方法作用于键值对RDD,返回指定键的所有值。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("p2")
val sc = new SparkContext(conf)
// 创建一个包含键值对的RDD作为查找表
val p = sc.parallelize(Seq(("key1", "value1"), ("key2", "value2"), ("key3", "value3"))).collectAsMap()
// 创建另一个RDD,其中我们想要查找键对应的值
val pp = sc.parallelize(Seq("key1", "key2", "key4"))
// 使用map和lookupMap实现lookup功能
val ppp= pp.map(key => (key, p.get(key)))
// 收集结果并打印
ppp.collect().foreach(println)
}
}我们创建了两个RDD一个名为p包含了我们的键值对,一个名为pp包含了我们需要查找的键。然后使用 map来实现我们的lookoup方法。
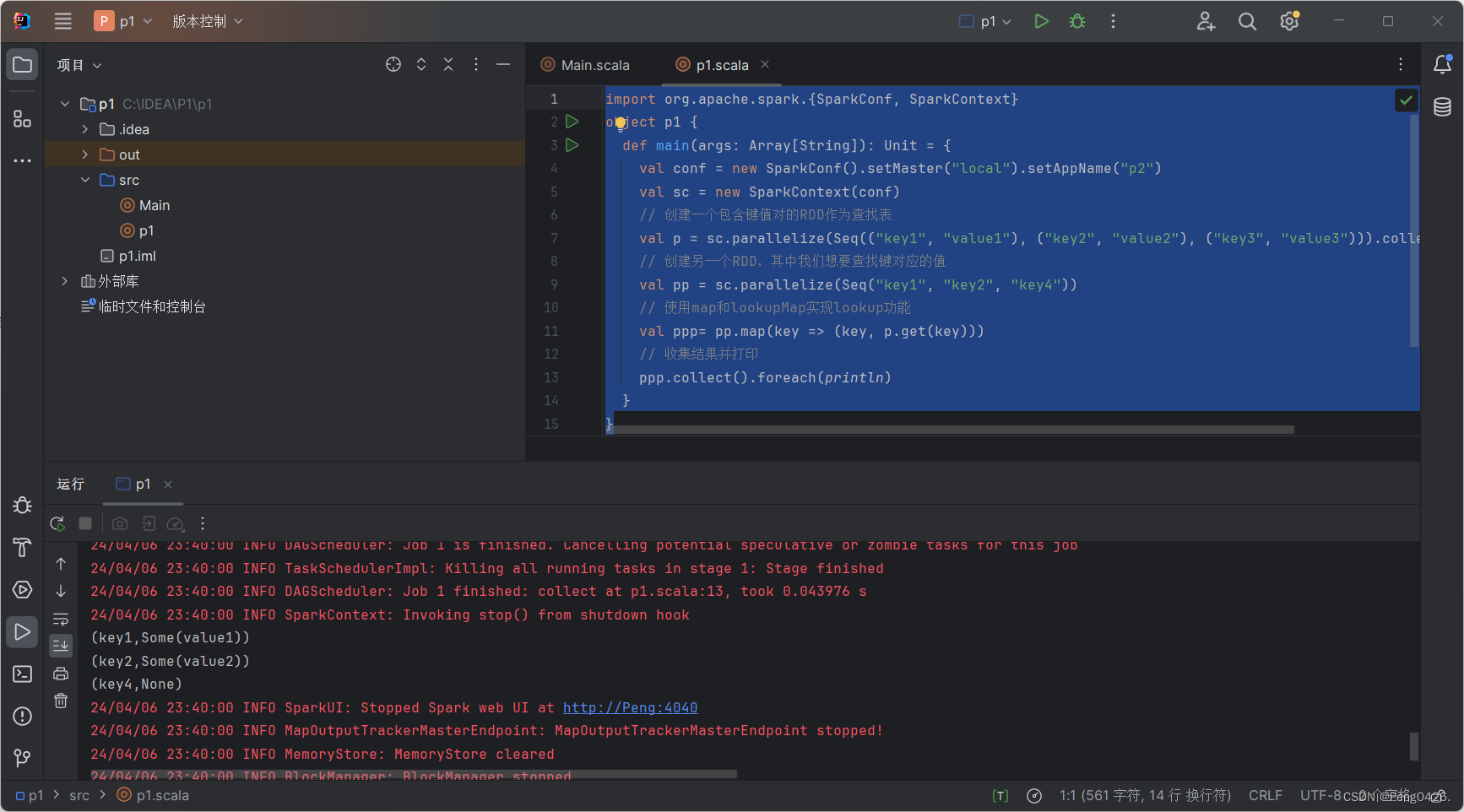
通过运行结果,我们可以看出返回了我们需要的key1,2,4但是key4中没有值,他就返回为None
2.cogroup
- cogroup是一种常见的join操作,用于合并两个或多个数据组中具有相同键的数据。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("p2")
val sc = new SparkContext(conf)
val p1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("a", 3)))
val p2 = sc.parallelize(Seq(("a", 4), ("b", 5), ("c", 6)))
// 使用 cogroup 方法将两个 RDD 中具有相同键的元素组合在一起
val pp = p1.cogroup(p2)
// 收集结果并打印
pp.collect().foreach(println)
}
}通过代码可以看到我们创建了两个RDD, 使用cogroup方法将它们相同键的数据进行合并,那么ac都是共同的元素,可是却没有c,运行代码还是会和之前的方法一样返回None吗?运行代码看看结果。

可以看到和以往不同,这次直接没有返回。
快去试试吧。
拓展-方法参数设置
| 方法 | 参数 | 描述 | 例子 |
|---|---|---|---|
| lookup | key | 在给定的键值对RDD中查找指定的键对应的值。 | 假设有一个键值对RDD:rdd = sc.parallelize([(1, 'a'), (2, 'b'), (3, 'c')]),则rdd.lookup(1)将返回['a']。 |
| 如果键不存在,则返回空列表。 | rdd.lookup(4)将返回[]。 | ||
| cogroup | 其他RDDs | 对多个RDD中的相同键进行分组,并返回一个新的键值对RDD,其中键是原始键,值是来自不同RDD的迭代器列表。 | 假设有两个RDD:rdd1 = sc.parallelize([(1, 'a'), (2, 'b')]) 和 rdd2 = sc.parallelize([(1, 'x'), (3, 'y')]),则rdd1.cogroup(rdd2)将返回[(1, (<iterator at 0x7f...>, <iterator at 0x7f...>)), (2, (<iterator at 0x7f...>,)), (3, (, <iterator at 0x7f...>))]。 |
| 迭代器列表中的每个迭代器对应一个输入RDD,并按输入RDD的顺序排列。 | 在上面的例子中,对于键1,第一个迭代器包含rdd1中的值'a',第二个迭代器包含rdd2中的值'x'。 | ||
| 如果某个键在某个RDD中不存在,则对应的迭代器为空。 | 在上面的例子中,对于键2,只有来自rdd1的迭代器包含值'b',而来自rdd2的迭代器为空。同样地,对于键3,只有来自rdd2的迭代器包含值'y',而来自rdd1的迭代器为空。 |










