文章目录
1. 有了HTTP协议为什么还要有RPC?
假设我们现在需要从A电脑的进程发一段数据到B电脑的进程,我们一般会在代码里面使用socket进行编程,现在我们的传输层协议一般只能选择TCP和UDP两种,TCP可靠但是UDP不可靠,所以只要稍微对可靠性有些要求,我们一般都会选择TCP协议来作为传输层协议,一个纯裸的TCP连接就可以做到收发数据,但是还是远远不够的。TCP是有三个特点的,分别是面向连接,可靠的以及基于字节流,而在这里我们需要关注的是面向字节流。
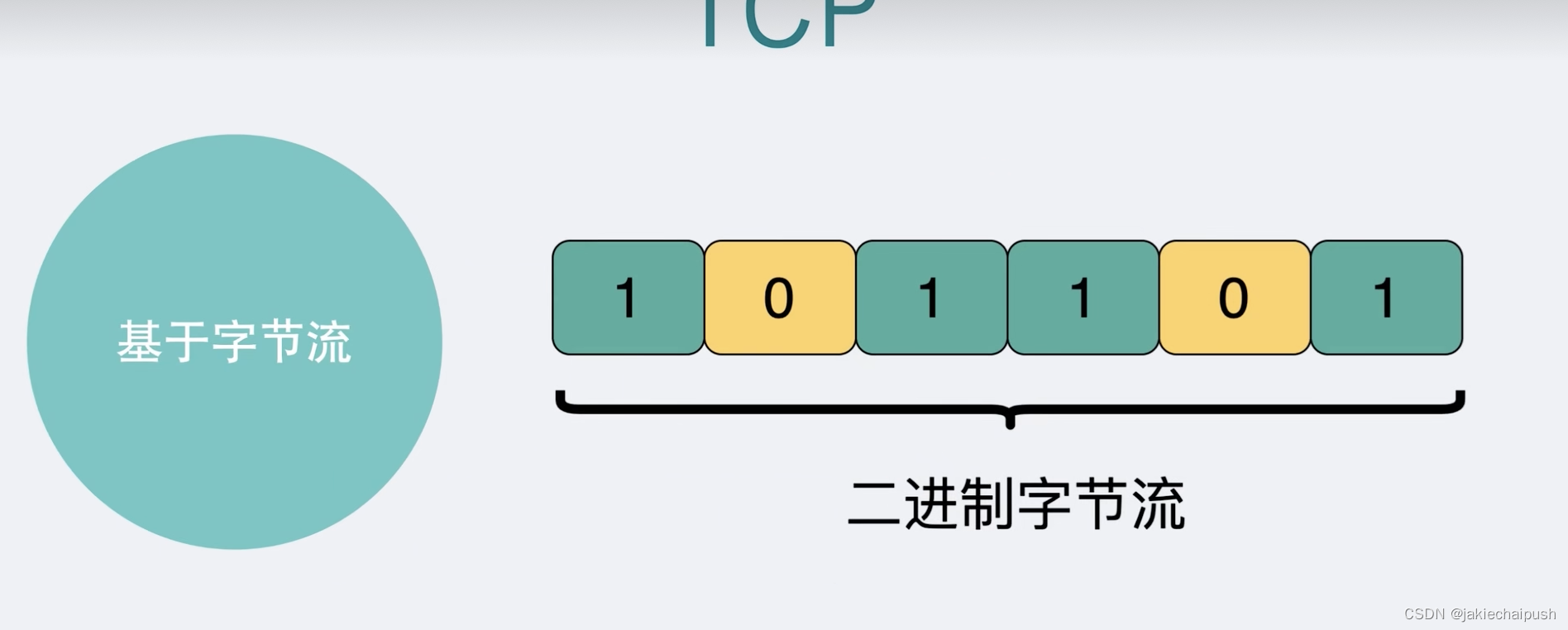
二进制字节流可以理解为一个双向的通道里流淌的数据,这个数据就是我们常说的二进制数据(一大堆01串),纯裸的这些01串之间是没有任何边界的,根本无法确认从哪个地方才算一个完整的消息。比如我们使用TCP发送“夏洛特烦恼”数据的时候,就会出现下面的情况:
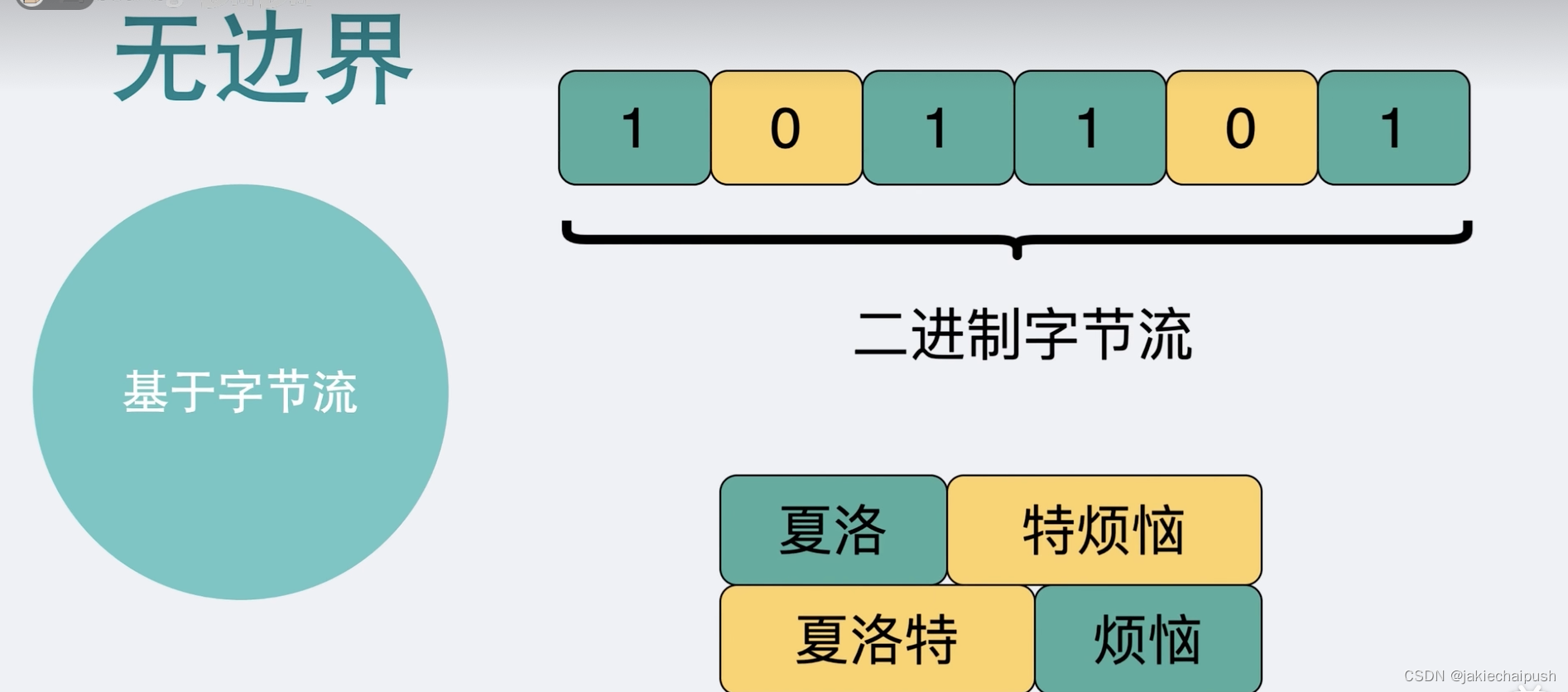
接收端无法知道你是想表达夏洛和特烦恼还是夏洛特和烦恼,这就是所谓的TCP粘包问题,所以为了解决粘包问题,我们就需要加入一些自定义的规则,用于区分消息的边界,比如给每个消息加入消息头,消息头里面写清楚该条消息的具体长度,当然这些消息头除了放消息长度之外,还可以放各种东西,例如消息体是否被压缩过和消息体格式之类的东西,只要上下游都约定好了,互相都认识就可以了,这就是所谓的协议。每个使用TCP的项目都可以定义一套类似这里的协议解析标准,它们可能有区别但是原理都类似,所以基于TCP就衍生了非常多的协议,就例如HTTP和RPC协议。TCP是传输层的协议,而基于TCP造出来的HTTP和各类RPC协议说白了它们都只是定义了不同消息格式的应用层协议而已,HTTP协议又叫做超文本传输协议:
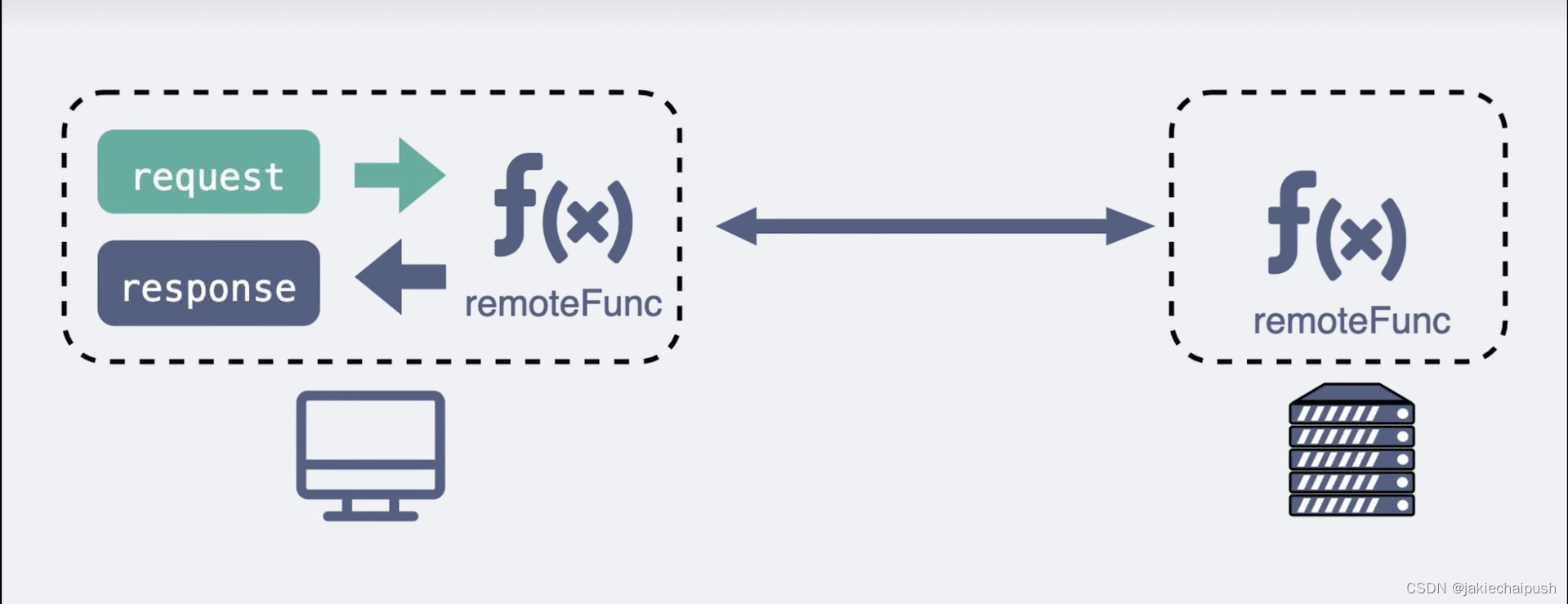
RPC(remote procedure call)远程过程调用,它本身并不是一个具体的协议,而是一种调用方式,例如我们平时调用一个本地方法
res=localFunc(req)
如果现在这不是一个本地方法,而是一个远端服务器暴露出来的一个方法,如果我们还能像调用本地方法那样去调用它,这样就可以屏蔽掉一些网络细节,用起来更方便。所以PRC就是希望像调用本地方法那样调用远端方法,基于这个思路,很多大佬就造出了非常多款式的RPC协议,比如比较有名的就是grpc thrift。
值得注意的是,虽然大多RPC底层使用的是TCP协议,但这并不是必选项,其实改用UDP或者HTTP也可以做到类似的功能。所以为什么有了HTTP还需要RPC?
其实TCP是70年代出来的协议,HTTP是90年代才开始流行的,因为直接使用裸TCP协议会有粘包问题,可想而之这相差的20多年会有多少自定义的协议,而这里面就有80年代出来的RPC协议,所以这里的问题不应该是既然有HTTP协议,为什么要有RPC,而是为什么有RPC还要HTTP?
现在电脑上装的各种文件,比如某某管家它们都作为客户端需要跟服务端建立连接发送消息,此时都会用到应用层协议,在这种CS架构下,它们可以使用自家造的RPC协议,因为他只管连自己公司的服务器即可,但有个软件就不用了,浏览器它们不仅要能访问自家公司的服务器还需要访问其他公司的服务器,因此它们需要有一个统一的标准,不然大家没法交流,于是HTTP就是那个时代用于统一B/S架构的协议,也就是说多年前HTTP主要用于B/S架构,而RPC更多用于C/S架构,但现在已经分的没有那么清楚了,B/S个C/S在慢慢融合,很多软件同时支持多端,比如某度云盘既要支持网页版,也要支持手机端和PC端,如果通信协议都用HTTP的话,那服务器只需要用一套即可,而RPC开始退居幕后,一般用于公司内部集群里各个微服务之间的通讯,那这么说的话都用HTTP就好了为什么还要RPC?
- 首先是服务发现,要向某个服务器发送请求,你需要先建立连接,而建立连接的前提是你得知道ip地址和端口,这个找到服务对应的IP端口的过程就是服务发现,在HTTP中你知道服务的域名就一通过DNS服务去解析,得到它背后的ip地址,默认80端口,而RPC就有些区别,一般会有专门的中间服务去保存服务名和IP信息,比如consul或者nacos甚至是redis,想要访问某个服务,就去这些中间服务中获取Ip和端口信息,由于DNS也是服务发现的一种,所以也有基于DNS去做服务发现的组件,比如coreDNS。可以发现服务发现这一块两种是有区别的,但不太能分高低
- 其次是底层连接协议:以主流的HTTP1.1协议为例,他默认在建立底层TCP连接之后,会一直保持这个连接(keep-alive),之后的请求和响应都会复用这条连接。而PRC协议也和HTTP类似,也是通过建立TCP长连接进行数据交互,但不同的地方在于RPC协议一般还会建立一个连接池,在请求量大的时候建立多条连接放在池内。要发数据的时候就从池中取出一个连接用完后放回去下次再使用,由于连接池有益于提升网络请求性能,所以不少编程语言的网络库中都会给HTTP加个连接池,比如GO就是这么干的,可以看出这块两者也没有什么太大的区别。
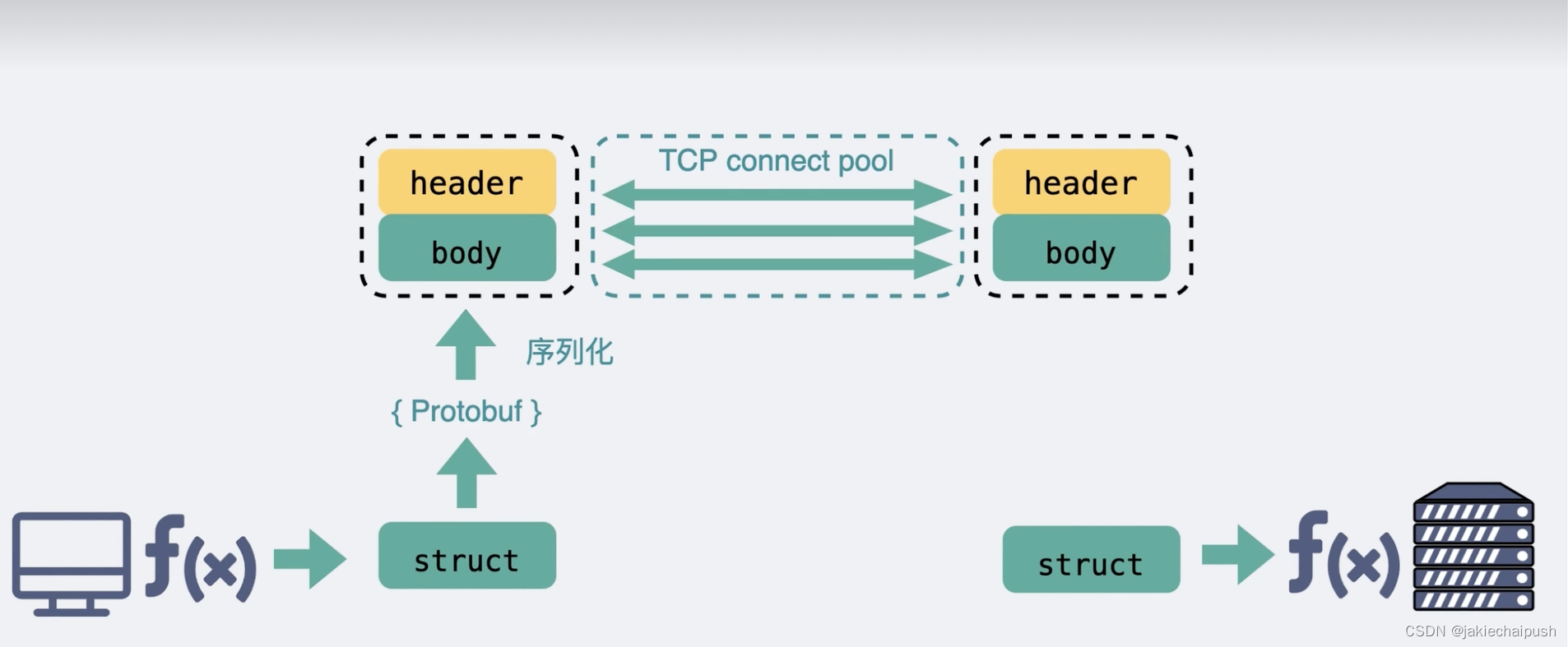
- 第三点也是最重要的一点也就是传输的内容:基于TCP传输的消息说到底无非都是消息头header和消息体body,header用于标记一些特殊信息,其中最重要的是消息体长度,body则是真正需要传输的内容,而这些内容只能是二进制01串。所以TCP传字符串和数字问题都不大,因为字符串可以转成编码再变成01串,而数字本身也能转化为二进制,但类呢?我们需要像办法也将其转化为01串,这样的方案现在也有很多现成的,比如Json,protobuf等,这个将类转化为二进制数组的过程就叫
序列化,反过来就是反序列化,对于主流的HTTP1.1,虽然它叫做超文本传输协议,支持音频视频,但HTTP设计出是用于做网页文本展示的,所以它传的内容以字符串为主,header和body都是如此,在body这块它使用Json来序列化类数据,而RPC因为它定制化程度更高,可以采用体积更小的protobuf或其它序列化协议去保存类数据,同时也不需要像HTTP那样考虑各种浏览器行为,比如302重定向跳转啥的,因此性能会更好一些,这也是公司内部微服务中抛弃HTTP,选择使用RPC的最主要的原因,当然上面所说的http都指http1.1,http2在http1.1基础上做了很多改进,性能甚至比RPC性能更好,例如GPRC底层直接使用的是HTTP 2,那么问题又来了为什么有了HTTP 2还需要RPC,这个就和出现时间有关系了,http2是2015年出来的,那时候很多公司内部都用的RPC协议,基于历史原因也没有必要去换了。









