目录
1. 前言
在上一篇文章中,我们谈到了路由的定义,通过URLPattern路由路径对象和RoutePattern路径匹配对象完成的。
将路由路径转化为RoutePattern对象,再将RoutePattern和视图函数转化为URLPattern对象
在这篇文章中,我们依旧会使用到URLPattern和RoutePattern的一些方法,来完成整个路由匹配的过程
2. 路由匹配全过程分析
2.1 请求的入口
如果我们使用的是同步请求(不涉及到异步),那么,请求的入口就是WSGI,也就是wsgi.py
application = get_wsgi_application()
这个语句便是WSGI的开始,用于处理HTTP的请求,我们ctrl+左键点击查看源码
def get_wsgi_application():
django.setup(set_prefix=False) # 初始化环境,启动django程序
return WSGIHandler()返回了一个WSGIHandler对象,我们进入其中:
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.load_middleware()
def __call__(self, environ, start_response):
set_script_prefix(get_script_name(environ))
signals.request_started.send(sender=self.__class__, environ=environ)
request = self.request_class(environ)
response = self.get_response(request)
response._handler_class = self.__class__
status = "%d %s" % (response.status_code, response.reason_phrase)
response_headers = [
*response.items(),
*(("Set-Cookie", c.output(header="")) for c in response.cookies.values()),
]
start_response(status, response_headers)
if getattr(response, "file_to_stream", None) is not None and environ.get(
"wsgi.file_wrapper"
):
# If `wsgi.file_wrapper` is used the WSGI server does not call
# .close on the response, but on the file wrapper. Patch it to use
# response.close instead which takes care of closing all files.
response.file_to_stream.close = response.close
response = environ["wsgi.file_wrapper"](
response.file_to_stream, response.block_size
)
return response2.2 request的封装
我们可以先去除一部分暂时性不需要的

这里做了一些前置处理:
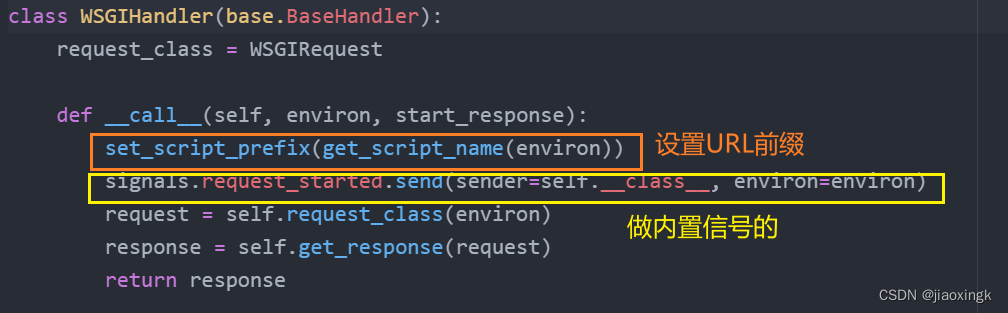
- 设置URL的前缀(URL中与Django相关的部分),保证能找到相对应的视图。
- 发送Django内置信号
现在,代码简洁很多了:
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest
def __call__(self, environ, start_response):
set_script_prefix(get_script_name(environ))
signals.request_started.send(sender=self.__class__, environ=environ)
request = self.request_class(environ)
response = self.get_response(request)
return responseok,我们现在来分析request:
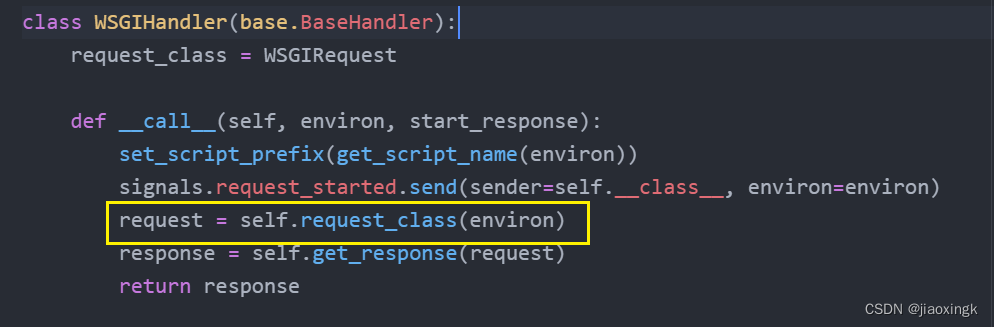
self.request_class(environ):其实就是对environ进行了再次封装,封装为了request对象,以便后续使用更加方便
我们可以先来看看request_class的内部实现:
request_class就是一个WSGIRequest对象
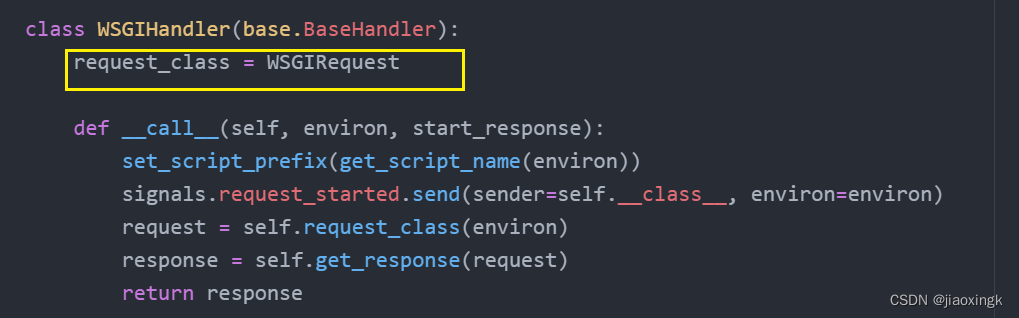
所以,他的内部:
class WSGIRequest(HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
# If PATH_INFO is empty (e.g. accessing the SCRIPT_NAME URL without a
# trailing slash), operate as if '/' was requested.
path_info = get_path_info(environ) or "/"
self.environ = environ
self.path_info = path_info
# be careful to only replace the first slash in the path because of
# http://test/something and http://test//something being different as
# stated in RFC 3986.
self.path = "%s/%s" % (script_name.rstrip("/"), path_info.replace("/", "", 1))
self.META = environ
self.META["PATH_INFO"] = path_info
self.META["SCRIPT_NAME"] = script_name
self.method = environ["REQUEST_METHOD"].upper()
# Set content_type, content_params, and encoding.
self._set_content_type_params(environ)
try:
content_length = int(environ.get("CONTENT_LENGTH"))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ["wsgi.input"], content_length)
self._read_started = False
self.resolver_match = None
简单来讲,就是将environ的一些信息做了处理,然后重新封装给request对象,后续调用更加方便
2.3 response的源头
ok,现在是最重要的一步了
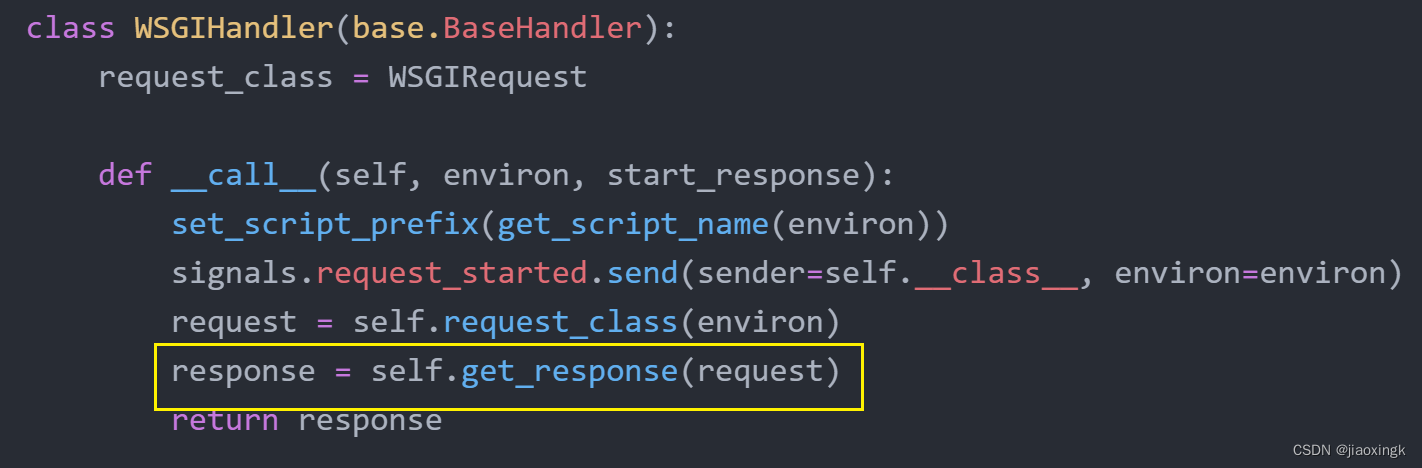
我们传递了请求到来的request参数,通过get_response进行处理,最后返回响应,说明在get_response中就已经做好了路由匹配。
现在,我们详细看看get_response里面的源码内容:
def get_response(self, request):
"""Return an HttpResponse object for the given HttpRequest."""
# Setup default url resolver for this thread
set_urlconf(settings.ROOT_URLCONF)
response = self._middleware_chain(request)
response._resource_closers.append(request.close)
if response.status_code >= 400:
log_response(
"%s: %s",
response.reason_phrase,
request.path,
response=response,
request=request,
)
return response- 先来看第一句
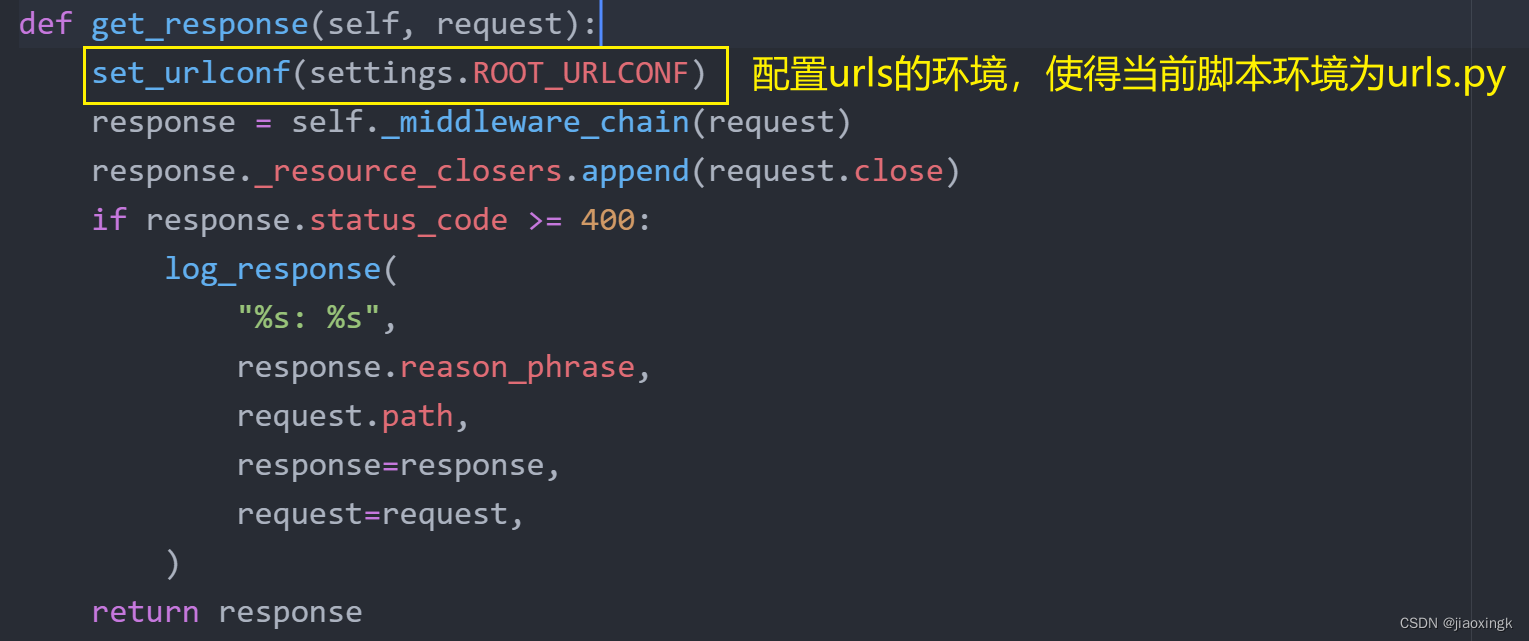

这就是urls的路径,设置好路径,后续方便寻找urlpatterns
- 最关键的就是这句,这个函数最终返回了response
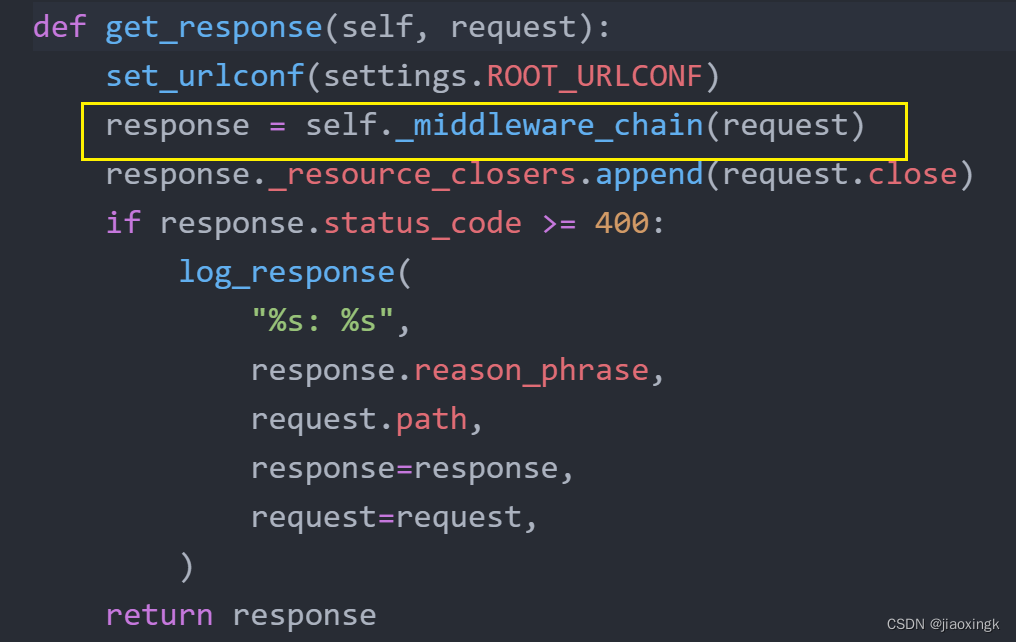
所以,我们剔除其他:
def get_response(self, request):
set_urlconf(settings.ROOT_URLCONF)
response = self._middleware_chain(request)
return response2.4 handler的获取
我们点击查看_middleware_chain
可以看到如下源码:
def load_middleware(self, is_async=False):
"""
Populate middleware lists from settings.MIDDLEWARE.
Must be called after the environment is fixed (see __call__ in subclasses).
"""
self._view_middleware = []
self._template_response_middleware = []
self._exception_middleware = []
get_response = self._get_response_async if is_async else self._get_response
handler = convert_exception_to_response(get_response)
handler_is_async = is_async
for middleware_path in reversed(settings.MIDDLEWARE):
middleware = import_string(middleware_path)
middleware_can_sync = getattr(middleware, "sync_capable", True)
middleware_can_async = getattr(middleware, "async_capable", False)
if not middleware_can_sync and not middleware_can_async:
raise RuntimeError(
"Middleware %s must have at least one of "
"sync_capable/async_capable set to True." % middleware_path
)
elif not handler_is_async and middleware_can_sync:
middleware_is_async = False
else:
middleware_is_async = middleware_can_async
try:
# Adapt handler, if needed.
adapted_handler = self.adapt_method_mode(
middleware_is_async,
handler,
handler_is_async,
debug=settings.DEBUG,
name="middleware %s" % middleware_path,
)
mw_instance = middleware(adapted_handler)
except MiddlewareNotUsed as exc:
if settings.DEBUG:
if str(exc):
logger.debug("MiddlewareNotUsed(%r): %s", middleware_path, exc)
else:
logger.debug("MiddlewareNotUsed: %r", middleware_path)
continue
else:
handler = adapted_handler
if mw_instance is None:
raise ImproperlyConfigured(
"Middleware factory %s returned None." % middleware_path
)
if hasattr(mw_instance, "process_view"):
self._view_middleware.insert(
0,
self.adapt_method_mode(is_async, mw_instance.process_view),
)
if hasattr(mw_instance, "process_template_response"):
self._template_response_middleware.append(
self.adapt_method_mode(
is_async, mw_instance.process_template_response
),
)
if hasattr(mw_instance, "process_exception"):
# The exception-handling stack is still always synchronous for
# now, so adapt that way.
self._exception_middleware.append(
self.adapt_method_mode(False, mw_instance.process_exception),
)
handler = convert_exception_to_response(mw_instance)
handler_is_async = middleware_is_async
# Adapt the top of the stack, if needed.
handler = self.adapt_method_mode(is_async, handler, handler_is_async)
# We only assign to this when initialization is complete as it is used
# as a flag for initialization being complete.
self._middleware_chain = handler实际上,最后所执行的就是handler函数
我们自底向上看:
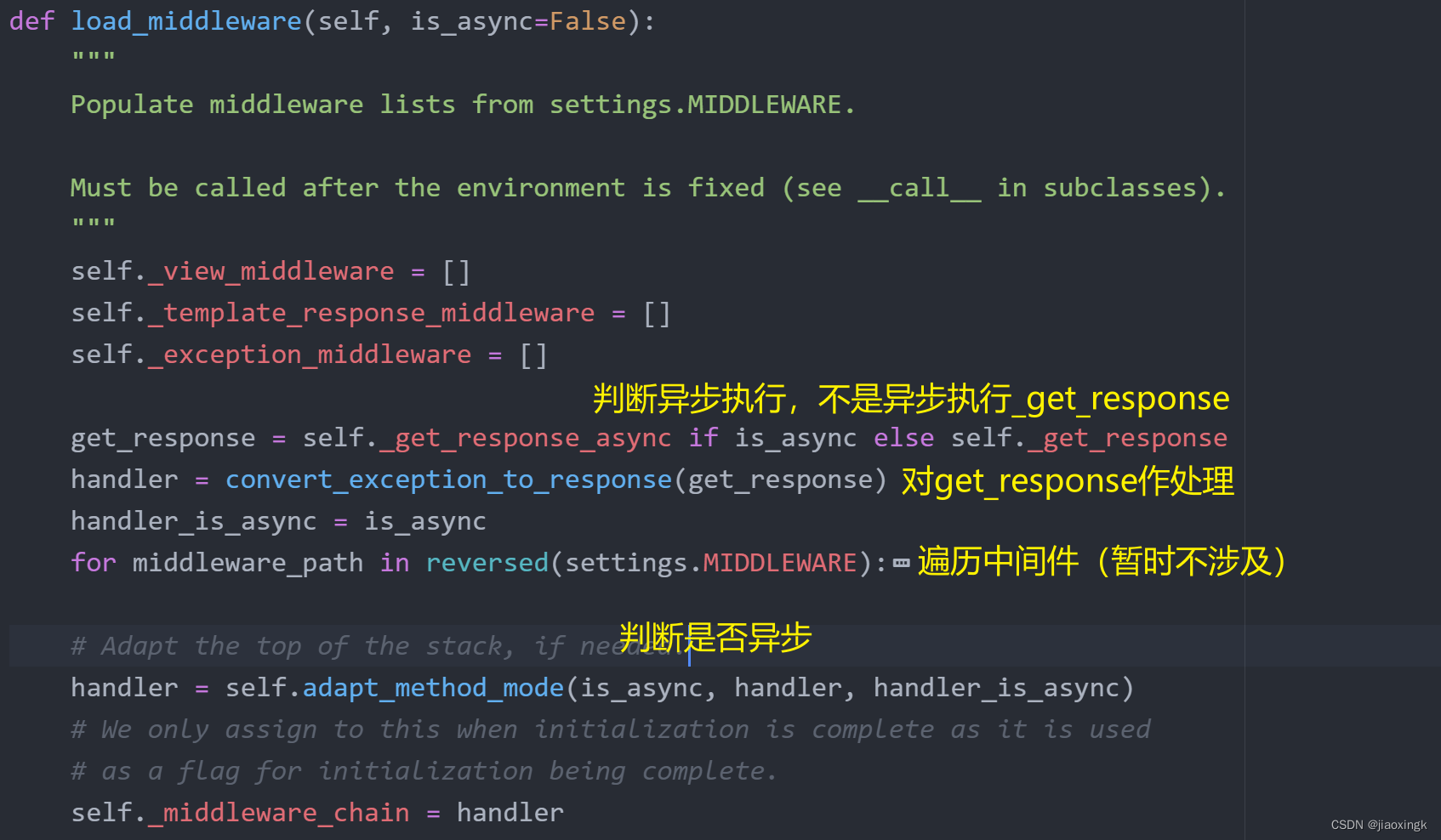
源码中,有一些对异步请求进行了判断,目前我们并不涉及,所以并不需要
我们需要知道在哪儿进行的路由匹配,肯定要从response入手,于是我们直接查看_get_response
这是简化后的的代码:
def load_middleware(self, is_async=False):
get_response = self._get_response
handler = convert_exception_to_response(get_response)
self._middleware_chain = handler2.5 获取resolver对象
我们继续开始,以下是_get_response的代码
def _get_response(self, request):
"""
Resolve and call the view, then apply view, exception, and
template_response middleware. This method is everything that happens
inside the request/response middleware.
"""
response = None
callback, callback_args, callback_kwargs = self.resolve_request(request)
# Apply view middleware
for middleware_method in self._view_middleware:
response = middleware_method(
request, callback, callback_args, callback_kwargs
)
if response:
break
if response is None:
wrapped_callback = self.make_view_atomic(callback)
# If it is an asynchronous view, run it in a subthread.
if iscoroutinefunction(wrapped_callback):
wrapped_callback = async_to_sync(wrapped_callback)
try:
response = wrapped_callback(request, *callback_args, **callback_kwargs)
except Exception as e:
response = self.process_exception_by_middleware(e, request)
if response is None:
raise
# Complain if the view returned None (a common error).
self.check_response(response, callback)
# If the response supports deferred rendering, apply template
# response middleware and then render the response
if hasattr(response, "render") and callable(response.render):
for middleware_method in self._template_response_middleware:
response = middleware_method(request, response)
# Complain if the template response middleware returned None
# (a common error).
self.check_response(
response,
middleware_method,
name="%s.process_template_response"
% (middleware_method.__self__.__class__.__name__,),
)
try:
response = response.render()
except Exception as e:
response = self.process_exception_by_middleware(e, request)
if response is None:
raise
return response其实有用的,也就一句:
callback, callback_args, callback_kwargs = self.resolve_request(request)
因为这个地方,返回了一个callback,其实就是最后匹配的视图函数
resolve_request
这个方法,才是重点,我们开始逐步分析:
def resolve_request(self, request):
"""
Retrieve/set the urlconf for the request. Return the view resolved,
with its args and kwargs.
"""
# Work out the resolver.
if hasattr(request, "urlconf"):
urlconf = request.urlconf
set_urlconf(urlconf)
resolver = get_resolver(urlconf)
else:
resolver = get_resolver()
# Resolve the view, and assign the match object back to the request.
resolver_match = resolver.resolve(request.path_info)
request.resolver_match = resolver_match
return resolver_match我们这里执行的是: get_resolver()
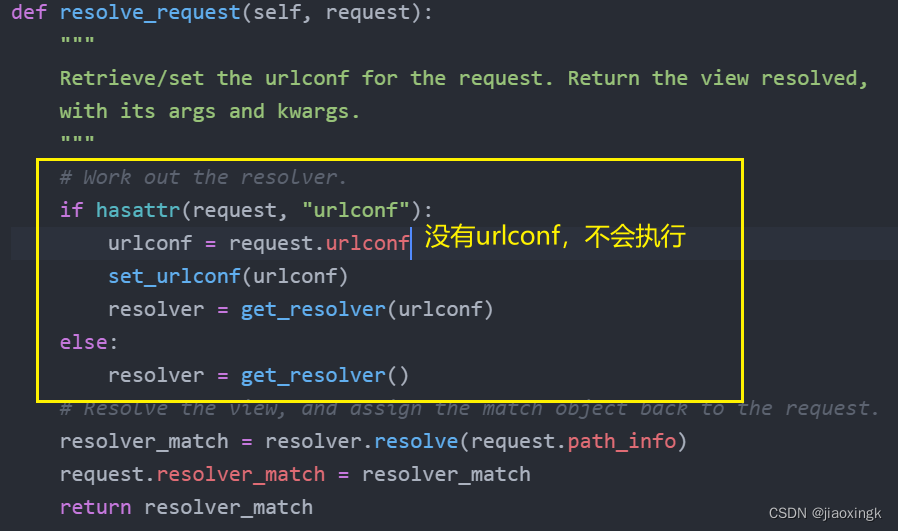
简化后:
def resolve_request(self, request):
resolver = get_resolver()
# Resolve the view, and assign the match object back to the request.
resolver_match = resolver.resolve(request.path_info)
request.resolver_match = resolver_match
return resolver_match我们接着往下看,通过get_resolver , 成功返回了URLResolver的一个对象
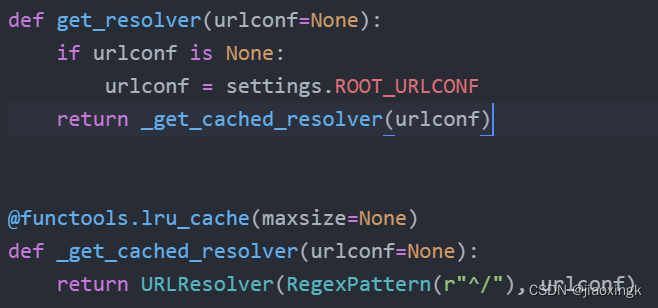
所以,我们小结一下:
这里的resolver对象就是:URLResolver
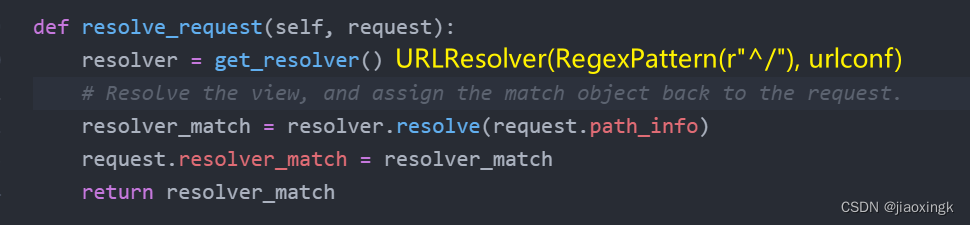
2.6 路由进行匹配
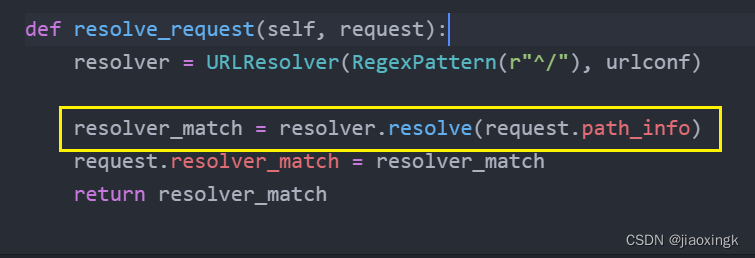
这一句代码便是最终的匹配结果,最终返回了匹配结果对象,并保存给request
我们可以先打印看看:
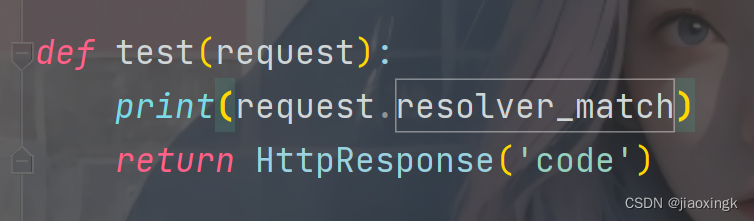
ResolverMatch(func=app01.views.test, args=(), kwargs={}, url_name=None, app_names=[], namespaces=[], route='test/')
可以看到,最后的匹配结果对象是一个ResolverMatch对象
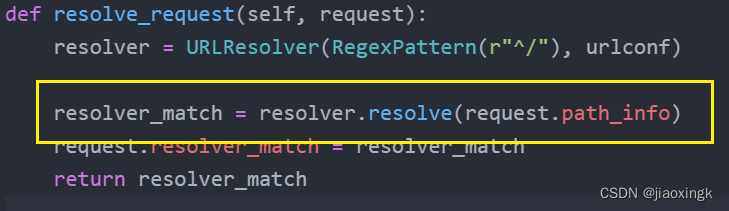
这里开始进行匹配,path_info就是路由路径:比如login/
调用URLResolver的resolve方法:
def resolve(self, path):
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path)
if match:
new_path, args, kwargs = match
for pattern in self.url_patterns:
try:
sub_match = pattern.resolve(new_path)
except Resolver404 as e:
self._extend_tried(tried, pattern, e.args[0].get("tried"))
else:
if sub_match:
# Merge captured arguments in match with submatch
sub_match_dict = {**kwargs, **self.default_kwargs}
# Update the sub_match_dict with the kwargs from the sub_match.
sub_match_dict.update(sub_match.kwargs)
# If there are *any* named groups, ignore all non-named groups.
# Otherwise, pass all non-named arguments as positional
# arguments.
sub_match_args = sub_match.args
if not sub_match_dict:
sub_match_args = args + sub_match.args
current_route = (
""
if isinstance(pattern, URLPattern)
else str(pattern.pattern)
)
self._extend_tried(tried, pattern, sub_match.tried)
return ResolverMatch(
sub_match.func,
sub_match_args,
sub_match_dict,
sub_match.url_name,
[self.app_name] + sub_match.app_names,
[self.namespace] + sub_match.namespaces,
self._join_route(current_route, sub_match.route),
tried,
captured_kwargs=sub_match.captured_kwargs,
extra_kwargs={
**self.default_kwargs,
**sub_match.extra_kwargs,
},
)
tried.append([pattern])
raise Resolver404({"tried": tried, "path": new_path})
raise Resolver404({"path": path})最重要的其实就是这个for循环了,可以看到我们遍历的是urls.py里面的我们提前定义url_patterns
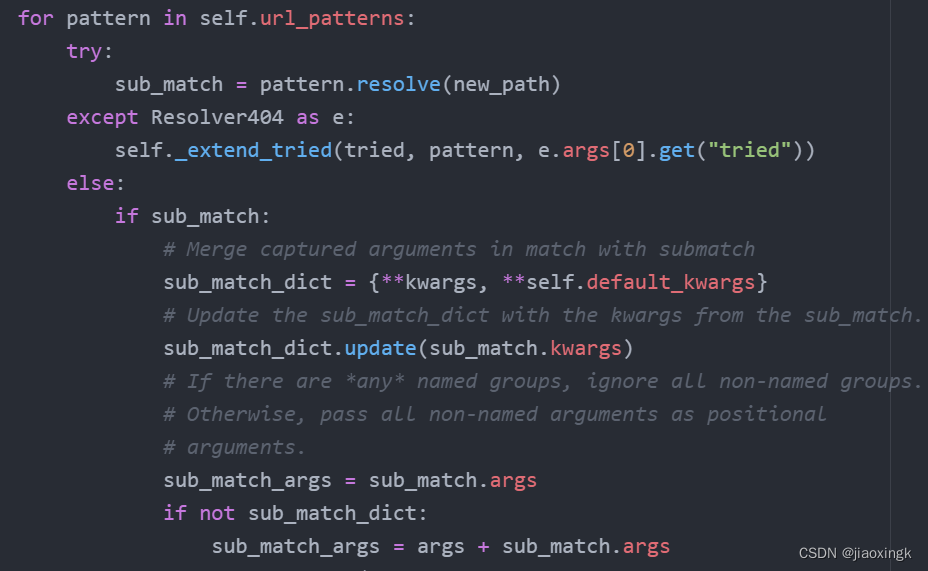
下面这个地方,就是我在上一篇文章中聊到的路由定义了,每一个路由都是一个URLPattern对象,里面有一个resolve方法,通过不同的Pattern(常规、正则)来进行匹配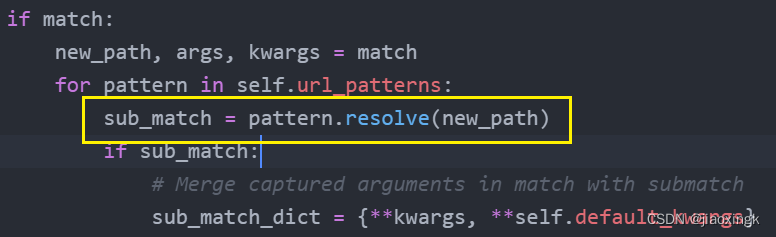
最后谁能够匹配成功,我们就返回ResolverMatch对象
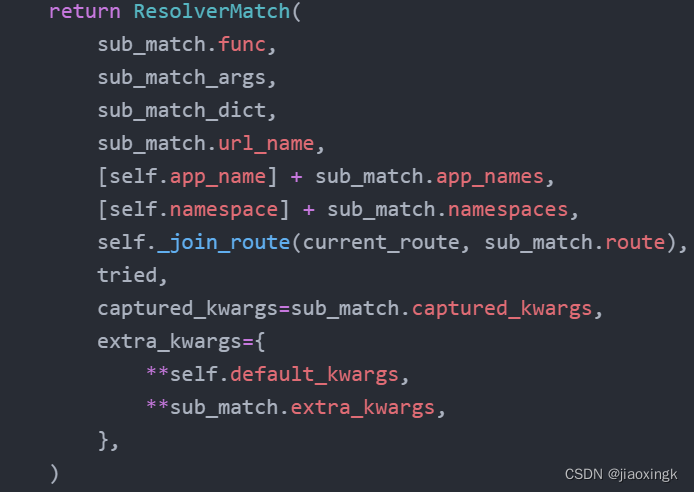
这就是最后匹配的结果了,第一个func其实就是相对应的视图函数
3. 小结
大概的源码如下所示,其中删除了一些暂时不需要看的东西,会更加清楚明了
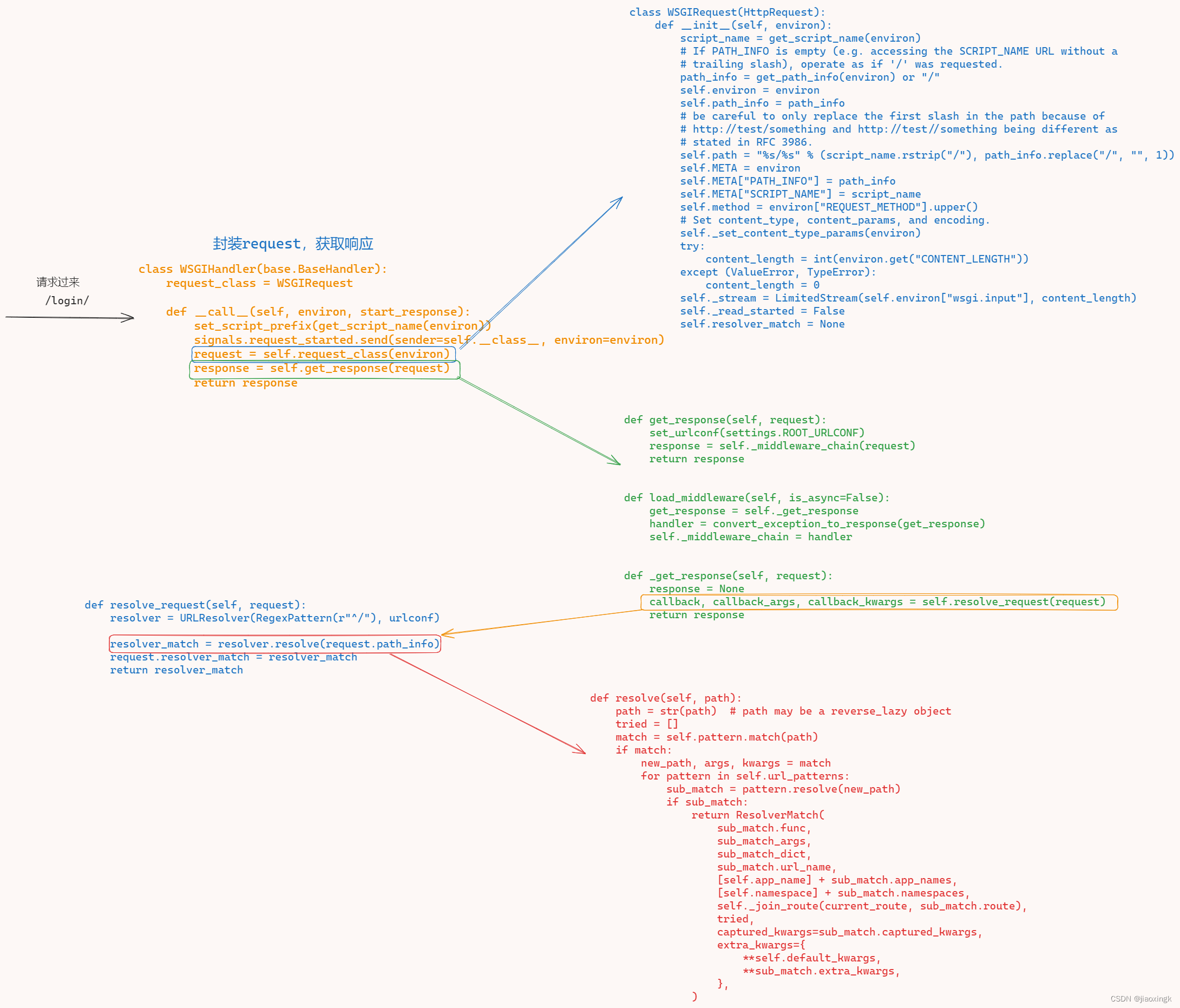
本篇文章,做了路由匹配的分析, 结合上一篇文章路由的本质,我们更加清楚路由是如何进行匹配的。
学习路由匹配,可以更好的掌握Django框架,学习源码编写的思想,可以帮助我们自己写出更健硕、更容易维护和扩展的代码。








