论文链接:Lost in the Middle: How Language Models Use Long Contexts
中文翻译链接:https://yiyibooks.cn/arxiv/2307.03172v3/index.html
论文标题:Lost in the Middle: How Language Models Use Long Contexts

推荐大家可以使用 通义智文 通过对话方式阅读论文。
一、论文 AI 解读
1.1 论文概括
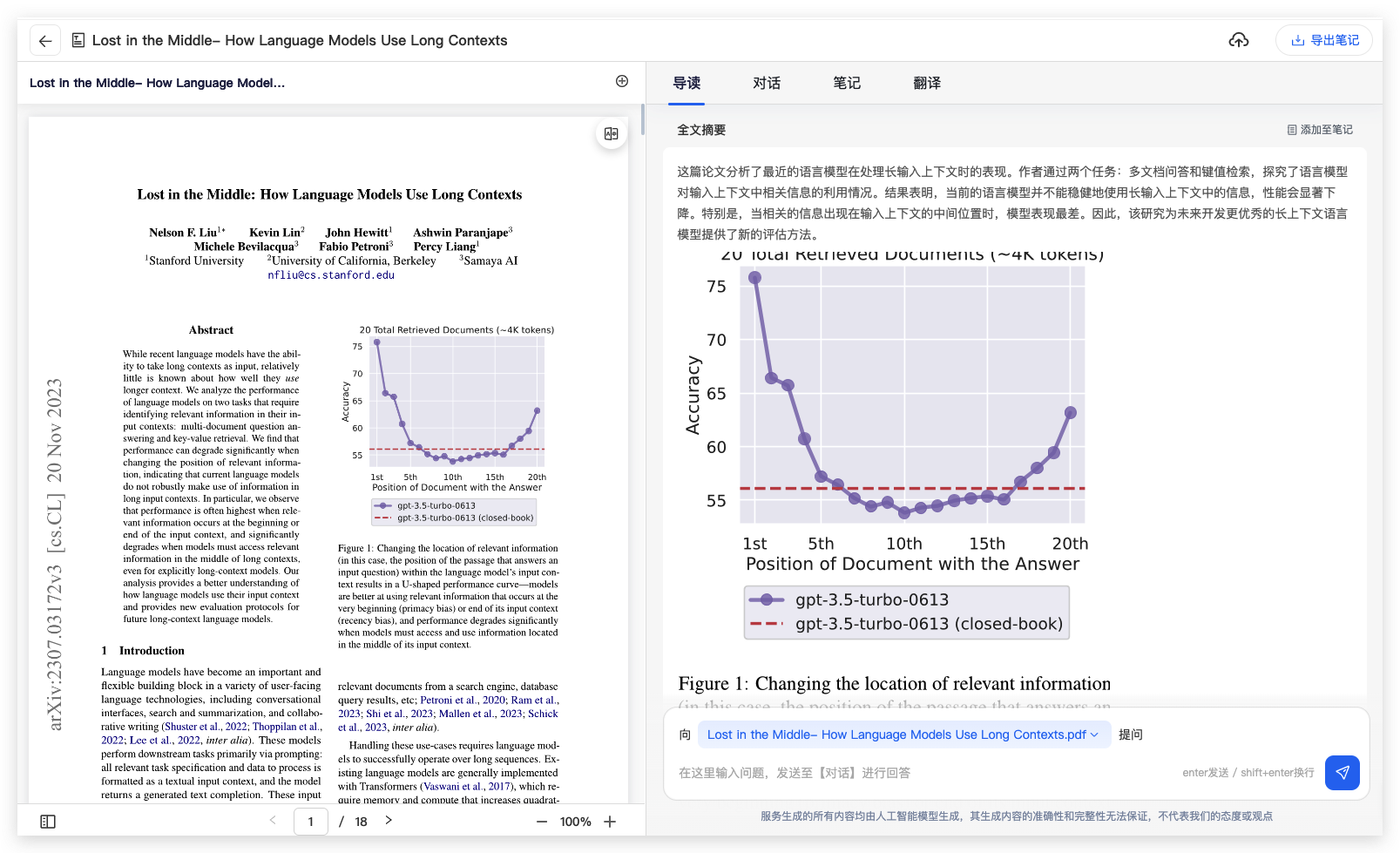
本文通过实验研究了当前先进的语言模型如何处理和利用长文本上下文。研究发现,尽管这些模型能够处理长文本输入,但它们在从长上下文中检索和使用相关信息方面存在显著不足。

特别是,当相关信息位于输入上下文的中间部分时,模型的性能会显著下降。
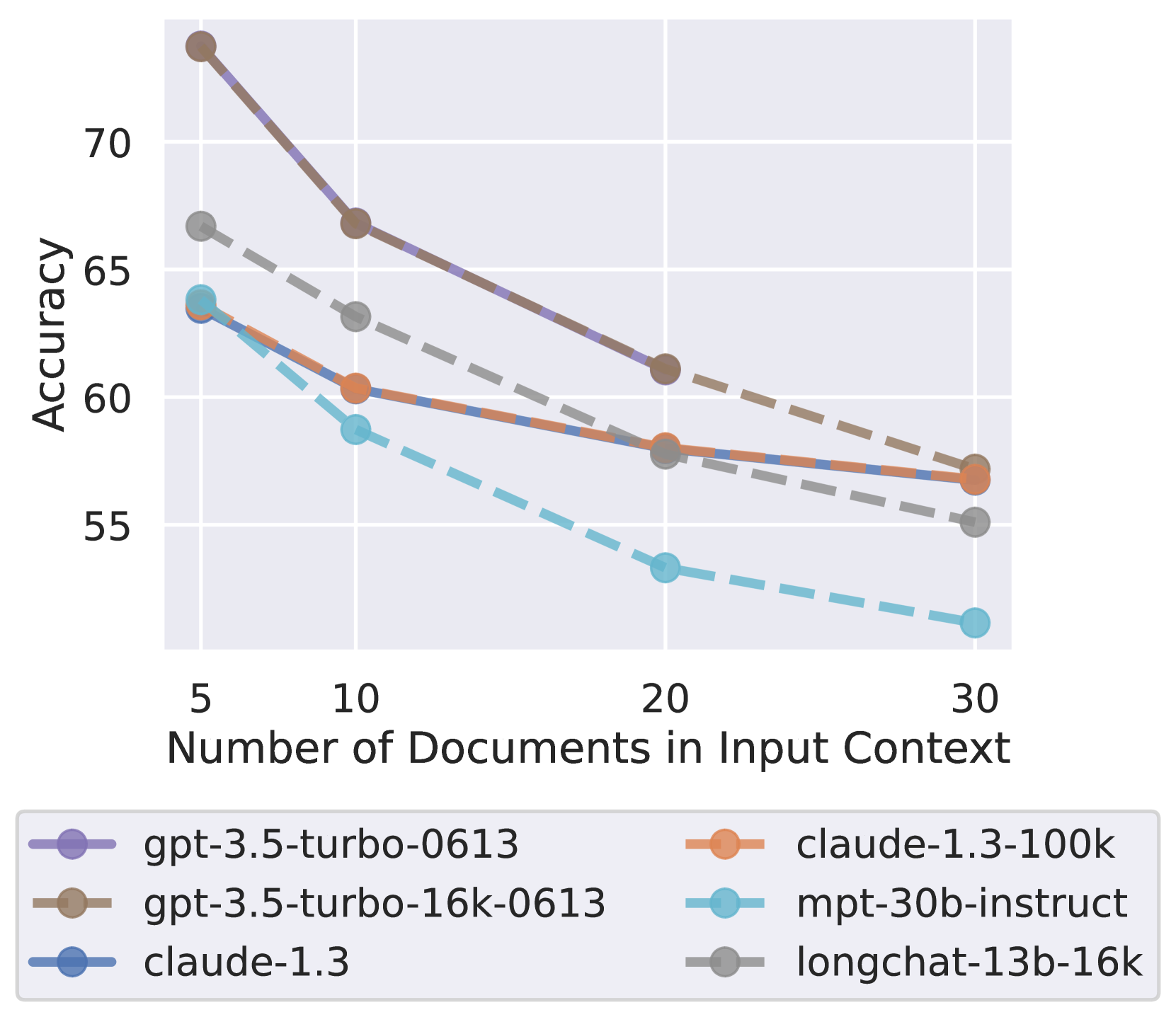
此外,随着输入上下文变长,即使对于明确的长上下文模型,性能也会大幅下降。
论文通过一系列受控实验,分析了多文档问答和键值检索任务中的模型性能,并探讨了模型架构、查询感知上下文化和指令微调等因素对模型使用上下文的影响。
1.2 论文详情
1.2.1 论文解决什么问题
论文解决的问题是当前语言模型在处理长文本上下文时的性能不足,尤其是在需要从上下文中间部分检索和使用信息时的效率问题。
1.2.2 论文用了什么方法
论文使用了受控实验的方法,通过改变输入上下文的长度和相关信息的位置,来评估语言模型在多文档问答和键值检索任务中的性能。此外,论文还研究了模型架构、查询感知上下文化和指令微调等因素对模型性能的影响。
1.2.3 论文的主要创新点是什么?
- 揭示了当前语言模型在长上下文中的性能瓶颈,特别是在处理中间位置信息时的不足。
- 提出了一种新的评估协议,用于评估未来长上下文语言模型的性能。
- 通过实验研究了不同因素(如模型架构、查询感知上下文化和指令微调)对语言模型使用长上下文的影响。
- 通过开放域问答的案例研究,提供了关于提供更多上下文是否总是有益的实证见解。
1.2.4 论文的主要观点或者结论是什么?
- 语言模型在长上下文中的性能会随着相关信息位置的变化而显著变化。
- 模型性能在相关信息位于上下文的开始或结束时最高,而在中间部分时性能显著下降,呈现出U形性能曲线。
- 扩展上下文模型并不一定比非扩展上下文模型更有效地使用输入上下文。
- 编码器-解码器模型相对于解码器模型在处理输入上下文中的位置变化时更为稳健,但仅在训练时序列长度内。
- 查询感知上下文化可以显著提高键值检索任务的性能,但对多文档问答任务的性能趋势影响较小。
- 指令微调过程并未显著改变模型对输入上下文位置的敏感性。
- 提供更多的上下文信息并不总是有益的,因为模型的性能会随着上下文长度的增加而饱和,甚至下降。
- 有效的检索文档重排序或截断可能有助于改善语言模型对检索上下文的使用。
二、关于论文的几个问题
2.1 为什么信息位于输入上下文的中间部分时,模型的性能会显著下降?
根据论文《Lost in the Middle: How Language Models Use Long Contexts》的分析,信息位于输入上下文的中间部分时,模型性能显著下降的原因主要包括以下几点:
-
位置偏见(Position Bias):
- 论文观察到的U形性能曲线表明,模型对于上下文开始(primacy bias)和结束(recency bias)的信息更为敏感,而对中间部分的信息处理能力较弱。这可能是因为模型在处理输入时,对于序列的起始和结束部分分配了更多的注意力或权重。
-
注意力分配(Attention Distribution):
- 尽管Transformer模型的自注意力机制能够理论上关注任何位置的上下文信息,但在实际应用中,模型可能会在长序列中遇到注意力分配的困难。特别是当信息位于长上下文的中间时,模型可能无法有效地捕捉和整合这些信息。
-
上下文管理(Context Management):
- 长上下文需要模型具备有效的信息管理能力,以便在大量信息中找到并使用相关的部分。当信息位于中间部分时,模型可能难以区分哪些信息是关键的,哪些是不相关的,从而导致性能下降。
-
计算资源限制(Computational Constraints):
- 处理长上下文需要更多的计算资源。随着上下文长度的增加,模型的计算和内存需求呈二次方增长,这可能导致模型在处理中间部分信息时资源不足,影响性能。
-
训练数据和微调(Training Data and Fine-Tuning):
- 模型在训练和微调过程中可能更多地接触到短序列或特定位置的信息,导致模型对于长上下文中间部分的处理不够优化。
-
模型架构(Model Architecture):
- 不同的模型架构可能对长上下文的处理有不同的适应性。论文中提到,编码器-解码器模型在处理长上下文时相对更稳健,但仅在训练时序列长度内。这表明,当序列长度超出模型在训练期间见过的长度时,性能会下降。
-
信息过载(Information Overload):
- 在长上下文中,模型可能面临信息过载的问题,尤其是当信息量非常大时。模型可能难以从大量的上下文中提取和利用位于中间部分的关键信息。
这些因素共同作用,导致模型在处理位于输入上下文中间部分的信息时性能显著下降。未来的研究需要进一步探索如何优化模型架构和训练策略,以提高模型在长上下文中对信息的全面利用能力。
2.2 为什么语言模型难以使用其整个输入上下文?
基于论文《Lost in the Middle: How Language Models Use Long Contexts》的内容,语言模型难以使用其整个输入上下文的原因可以归结为以下几点:
-
位置偏见(Position Bias):论文中的实验结果表明,语言模型在处理长上下文时,对于信息的位置非常敏感。具体来说,模型在相关信息出现在输入上下文的开始(primacy bias)或结束(recency bias)时表现最佳,而在中间部分时性能显著下降。这种位置偏见意味着模型可能无法均衡地利用整个上下文信息。
-
注意力机制的局限性:尽管Transformer模型的自注意力机制理论上可以处理任何位置的信息,但实际上,模型在长上下文中的性能受到注意力分布和计算效率的限制。特别是在长序列中,模型可能更倾向于关注局部信息而不是全局信息。
-
训练数据的偏差:语言模型在训练过程中可能更多地接触到短序列或特定位置的信息,这可能导致模型在处理长上下文时,对于序列的不同部分有不同的敏感度。
-
计算资源的限制:长上下文的处理需要更多的计算资源,包括内存和计算能力。随着上下文长度的增加,模型的内存和计算需求呈二次方增长,这可能导致模型在实际应用中难以处理极长的上下文。
-
模型架构的影响:论文中提到,编码器-解码器模型在处理长上下文时相对更稳健,尤其是当评估的序列长度在训练时的上下文窗口内时。这表明,当前的一些流行模型架构可能不是为处理长上下文设计的,或者它们的设计没有充分考虑长上下文的需求。
-
信息过载:在长上下文中,模型可能面临信息过载的问题,难以区分和优先处理最重要的信息。这可能导致模型在需要从大量信息中检索和使用特定信息时表现不佳。
-
缺乏有效的上下文管理策略:有效的上下文管理对于模型使用长上下文至关重要。然而,当前的语言模型可能缺乏有效的策略来管理和利用长上下文中的信息,特别是在需要从上下文的中间部分检索信息时。
2.3 语言模型如何使用上下文?
基于论文《Lost in the Middle: How Language Models Use Long Contexts》的研究,语言模型使用上下文的方式可以通过以下几点来理解:
-
位置敏感性(Position Sensitivity):
- 语言模型在使用上下文时表现出对信息位置的敏感性,尤其是在长上下文中。
- 模型性能在相关信息出现在上下文的开始(primacy bias)或结束(recency bias)时最高,而在中间部分时性能显著下降。
-
长上下文的挑战(Challenges with Long Contexts):
- 尽管语言模型被设计为能够处理长序列输入,但它们在实际使用长上下文时仍面临挑战。
- 模型在长上下文中的性能可能会因为上下文长度的增加而下降,特别是在需要从上下文中间部分检索信息时。
-
模型架构的影响(Effect of Model Architecture):
- 不同的模型架构对上下文的使用有不同的影响。
- 编码器-解码器模型在处理上下文信息位置变化时相对更稳健,尤其是当评估的序列长度在模型训练时的上下文窗口内时。
-
查询感知上下文化(Query-Aware Contextualization):
- 将查询或问题放置在上下文的前后可以提高模型对相关信息的敏感性和检索能力。
- 这种查询感知上下文化的方法在键值检索任务中表现出近乎完美的性能,但在多文档问答任务中对性能趋势的影响较小。
-
指令微调的作用(Role of Instruction Fine-Tuning):
- 经过指令微调的模型可能会对输入上下文的开始部分给予更多的关注,因为任务说明和指令通常放在输入的开始部分。
- 指令微调过程可能会影响模型对上下文的使用的模式,但并不一定是性能趋势形成的唯一原因。
-
长上下文的权衡(Trade-off of Long Contexts):
- 提供更多的上下文信息并不总是有益的,因为模型可能难以处理和推理过多的内容。
- 在实际应用中,需要在提供的信息量和模型能够有效利用的信息量之间找到平衡点。
综上所述,语言模型使用上下文的方式是复杂且多维度的,受到位置、上下文长度、模型架构、查询感知性、指令微调和长上下文权衡等因素的影响。未来的研究和模型设计需要进一步探索如何优化这些因素,以便模型能够更有效地使用上下文信息。
三、对编写提示词的启示
这些结论对于编写大型语言模型的提示词(prompts)提供了以下几点启示:
-
关注信息位置:当设计提示词时,应考虑将关键信息放置在输入上下文的开始或结束部分,因为模型在这些位置的性能更高。这可以通过将最重要的信息或查询相关的关键点放在文本的前面或后面来实现。
-
简化上下文:如果可能的话,尽量减少输入上下文的长度,特别是当信息不是特别关键时。因为随着上下文长度的增加,模型的性能可能会下降,尤其是在需要处理大量非关键信息时。
-
优化信息结构:在构建提示词时,应该优化信息的结构,使得相关信息更加突出和易于模型识别。例如,可以通过格式化或使用特定的标记来强调关键信息。
-
利用查询感知上下文化:在设计提示词时,可以尝试将查询或问题放置在文档或关键值对的前后,以提高模型对相关信息的敏感性和检索能力。
-
考虑模型架构:根据所使用的语言模型的架构(如解码器模型或编码器-解码器模型),调整提示词的策略。例如,对于编码器-解码器模型,可以考虑利用其双向处理能力来优化提示词。
-
指令微调的重要性:在编写提示词时,考虑到模型可能已经通过指令微调进行了优化,因此应确保提示词与模型的训练数据保持一致,以便模型能够更好地理解和执行任务。
-
避免信息过载:避免在提示词中包含过多的信息,这可能会导致模型难以区分和检索最重要的内容。相反,应该专注于提供最相关和必要的信息。
通过遵循这些启示,我们可以更有效地编写提示词,以提高大型语言模型在处理长文本和复杂任务时的性能和准确性。










