VideoSum: A Python Library for Surgical Video Summarization
Authors: Luis C. Garcia-Peraza-Herrera, Sebastien Ourselin, and Tom Vercauteren
Source: https://arxiv.org/pdf/2303.10173.pdf

这篇文章主要关注的是如何通过视频摘要来简化和可视化手术视频,以便于数据标注和处理。在这篇文章中,作者提出了一个名为videosum的Python库,可以用来生成手术视频的摘要图片(storyboard)。摘要图片是通过将视频分为一系列表示视频帧的代表图片来创建的。
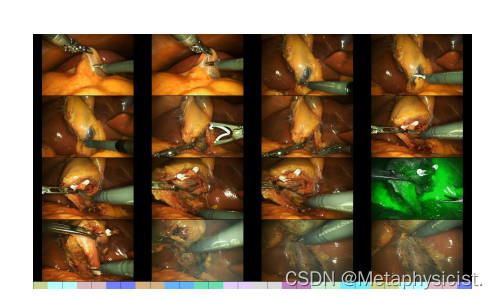
图1:视频总和时间法制作的手术视频的基线故事板。拼贴下方的条形图代表视频的长度。颜色表示视频帧的簇标签,黑色竖条是关键帧。通过时间方法将视频分割成均匀的时间段。

背景:深度学习算法的表现受到数据的质量和量的影响,但在手术数据科学领域,有限的标注数据使得这一点成为挑战。因此,大量的研究努力在这一领域提出了方法来缓解这一问题。同时,越来越多的计算助手手术数据集正在被发布,尽管该领域的数据规模仍然有限。数据挖掘因此成为许多手术数据科学研究的关键部分。手术视频数据集的处理和可视化是非常挑战性的,因为手术视频的平均时长为130.45分钟。
贡献:这篇文章的贡献包括:
1. 提出了一种易于使用且开源的Python库videosum,可以生成手术视频的摘要图片。
2. 介绍了videosum中四种不同的方法来生成摘要图片:时间、inception、uid三、scda。
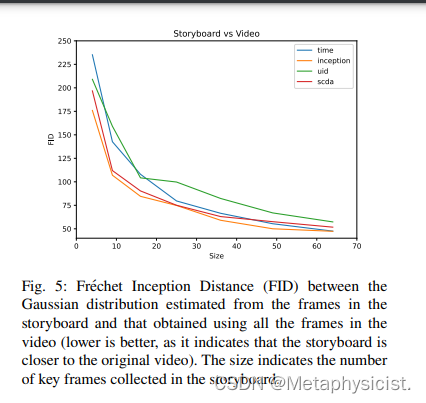
3. 提供了如何评估不同方法的方法,即使用Frechet Inception Distance(FID)来比较摘要图片与原始视频之间的分布接近程度。
内容:文章详细描述了每个方法的工作原理,以及它们在不同手术视频上的表现。例如,在inception方法中,每个帧的表示通过使用InceptionV3预训练的深度神经网络得到,并使用该网络的2048元稳定向量作为距离度量。在uid方法中,InceptionV3的稳定向量仍然用于帧的表示,但是采用2-Wasserstein距离作为聚类的度量。在scda方法中,表示帧的方法和距离度量与[5]中提出的方法相同,但是采用INCEPTION的低分辨率稳定向量作为表示图像的描述,并使用2-norm作为聚类的度量。
Reference
[1] Garcia-Peraza, L. C., Ourselin, S., & Vercauteren, T. (2023, July). VideoSum: A Python Library for Surgical Video Summarization. In Conference on New Technologies for Computer and Robot Assisted Surgery 2023.










