- 查看数据引擎
show engines;
- 创建数据库,并选择库
CREATE DATABASE IF NOT EXISTS test_database;
USE test_database;
- 创建表
CREATE TABLE IF NOT EXISTS test_table (
id INT AUTO_INCREMENT PRIMARY KEY,
field1 VARCHAR(50),
field2 VARCHAR(50),
field3 VARCHAR(50),
field4 VARCHAR(50),
field5 VARCHAR(50),
field6 VARCHAR(50),
field7 VARCHAR(50),
field8 VARCHAR(50),
field9 VARCHAR(50),
field10 VARCHAR(50)
);
- 循环插入测试数据,并调用存储过程插入测试数据
-- 循环插入测试数据
DELIMITER $$
CREATE PROCEDURE insert_test_data()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 100 DO
INSERT INTO test_table (field1, field2, field3, field4, field5, field6, field7, field8, field9, field10)
VALUES
(CONCAT('data', i, '_1'),
CONCAT('data', i, '_2'),
CONCAT('data', i, '_3'),
CONCAT('data', i, '_4'),
CONCAT('data', i, '_5'),
CONCAT('data', i, '_6'),
CONCAT('data', i, '_7'),
CONCAT('data', i, '_8'),
CONCAT('data', i, '_9'),
CONCAT('data', i, '_10'));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 调用存储过程插入测试数据
CALL insert_test_data();
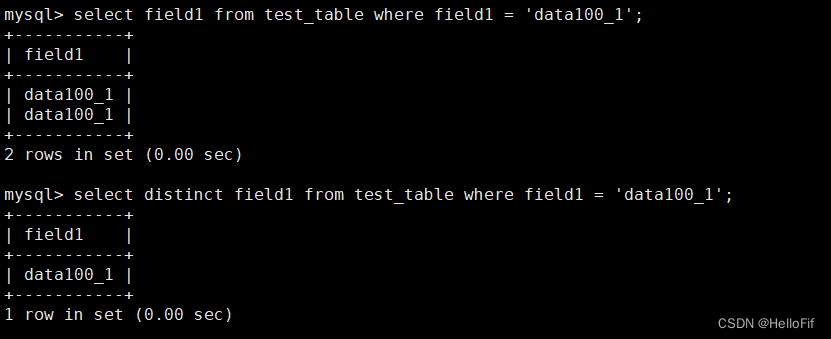
- 数据表去除某个表字段的重复值
select distinct field1 from test_table where field1 = 'data100_1'
6. 创建索引
-- 1.创建全文索引
CREATE FULLTEXT INDEX index_name ON table_name (column_name);
-- 示例
CREATE FULLTEXT INDEX content_index ON articles (content);
-- 2.创建组合索引
CREATE INDEX index_name ON table_name (column1, column2, ...);
-- 示例
CREATE INDEX name_index ON employees (first_name, last_name);
-- 3.创建局部索引
CREATE INDEX index_name ON table_name (column_name) WHERE condition;
-- 示例
CREATE INDEX recent_orders_index ON orders (order_date) WHERE order_date > '2023-01-01';
-- 4.唯一索引
CREATE UNIQUE INDEX index_name ON table_name (column_name);
-- 示例
CREATE UNIQUE INDEX email_unique_index ON users (email);
-- 5.外键索引的
ALTER TABLE child_table
ADD CONSTRAINT fk_constraint_name
FOREIGN KEY (referencing_column)
REFERENCES parent_table (referenced_column);
-- 示例
ALTER TABLE orders
ADD CONSTRAINT fk_customer_id
FOREIGN KEY (customer_id)
REFERENCES customers (customer_id);
-- 6. 创建表时增加索引
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
...
CONSTRAINT index_name UNIQUE (column_name)
);
-- 示例
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
CONSTRAINT unique_username UNIQUE (username)
);
- 查询一张表中有多少个索引
show index from test_table;
- delete、truncate、drop删除
-- 删除表中某几条记录
DELETE FROM employees WHERE age > 30;
-- 清空表中所有的记录
TRUNCATE TABLE employees;
-- 删除表
DROP TABLE employees;
- 关于group by
-- 场景1:计算每个分类的综合,假设有一个产品表products,包含category和price两个字段,你可以使用group by来计算每个分类中由多少产品;
select category ,count(*) from products group by category;
-- 场景2:计算每个组的平均值,如果你想要知道每个部门的平均工资,假设只有一个员工表employess包含department和salary两个字段
select department,AVG(salary) from employess group by department;
-- 场景3:求每个组的最大值或者最小值,在一个订单表orders中,包含customer_id和order_value字段,找出每个客户的最大订单值
select customer_id, max(order_value) from orders group by customer_id;
-- 场景4:分组后的筛选数据,使用group by 和having 一起,筛选出特定条件的组,路在上面的订单表中,找出订单总之超过某个阈值客户
select cunstomer_id from orders group by cunstomer_id having sum(order_value) > 10000;
-- 场景5:时间序列数据的聚合,如果有一个包含时间戳的表sales,你可能想按月汇总销售额
select year(sale_date) as sale_year, month(sale_date) as sale_month, sum(amount) from sales group by year(sale_date),month(sale_date)
-- 场景6: 结合聚合函数和普通列,在一个员工表employess表中,包含department,name,salary字段,你想找出每个部分薪水最高的员工
select department, name, max(salart) from employess group by department,name;










