导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
- 链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMs)在多个领域表现出卓越的能力,尤其是在需要复杂推理和专业知识的任务中,例如编程和创意写作。LLMs通过直观的聊天界面与人类互动,导致了它们在公众中的快速普及。LLMs通常通过自回归式的Transformer在大量自监督数据上进行预训练,然后通过诸如人类反馈的强化学习(RLHF)等技术进行微调,使其更符合人类偏好。尽管训练方法相对简单,但高计算要求限制了LLMs的发展。已有公开发布的预训练LLMs在性能上可以与GPT-3和Chinchilla等闭源模型相媲美,但这些模型并不适合作为诸如ChatGPT、BARD、Claude这样的闭源“产品”LLMs的替代品。
本文开发并发布了Llama 2和Llama 2-Chat,以供研究和商业使用,这是一系列预训练和微调的LLMs,模型规模最大可达70亿参数。Llama 2-Chat在有用性和安全性方面的测试中普遍优于现有的开源模型,并且在人类评估中与一些闭源模型相当。本文还采取了提高模型安全性的措施,包括特定的数据注释和调整,红队测试,以及迭代评估。同时作者强调,虽然LLMs是一项新技术,可能带来潜在风险,但如果安全地进行,公开发布LLMs将对社会有益。作者提供了负责任使用指南和代码示例,以促进Llama 2和Llama 2-Chat的安全部署。
2 预训练
2.1 预训练数据
- 数据来源:训练数据来自公开可用的源,排除了来自 Meta 产品或服务的数据。
- 数据清洗:移除了已知包含大量个人信息的网站数据。
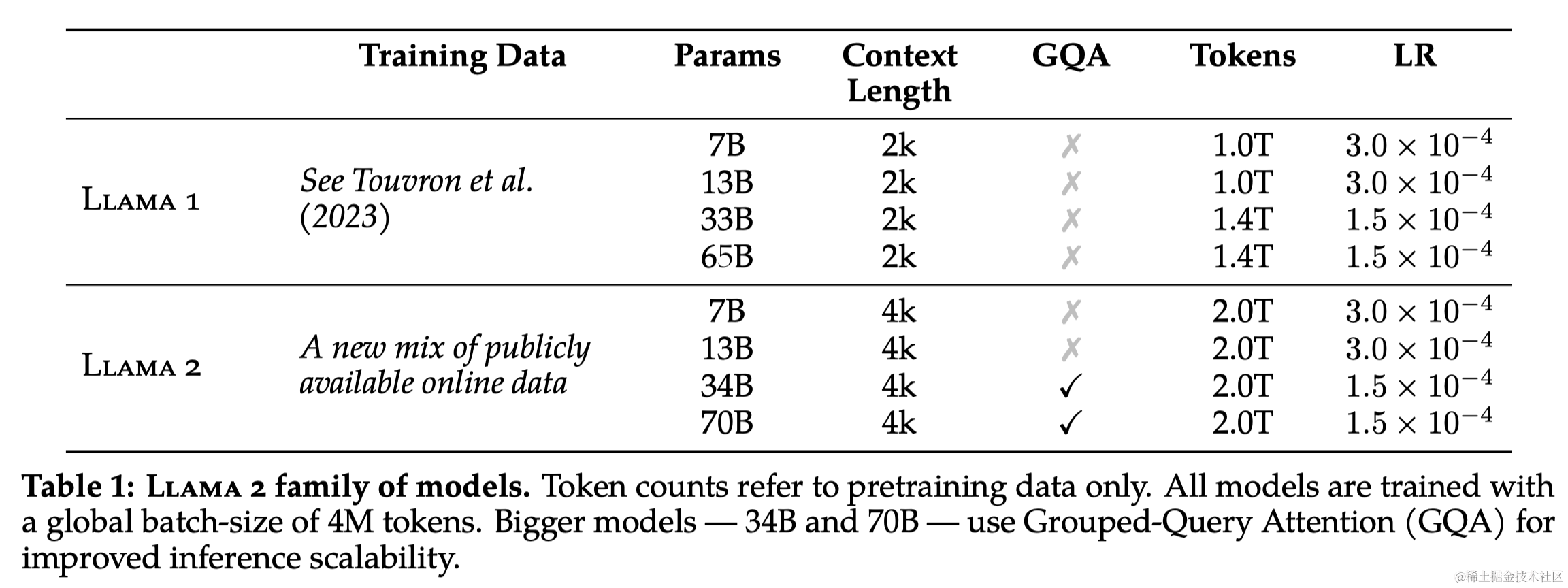
- 训练token数:训练了2万亿(2T)token的数据,以获得良好的性能和成本平衡。
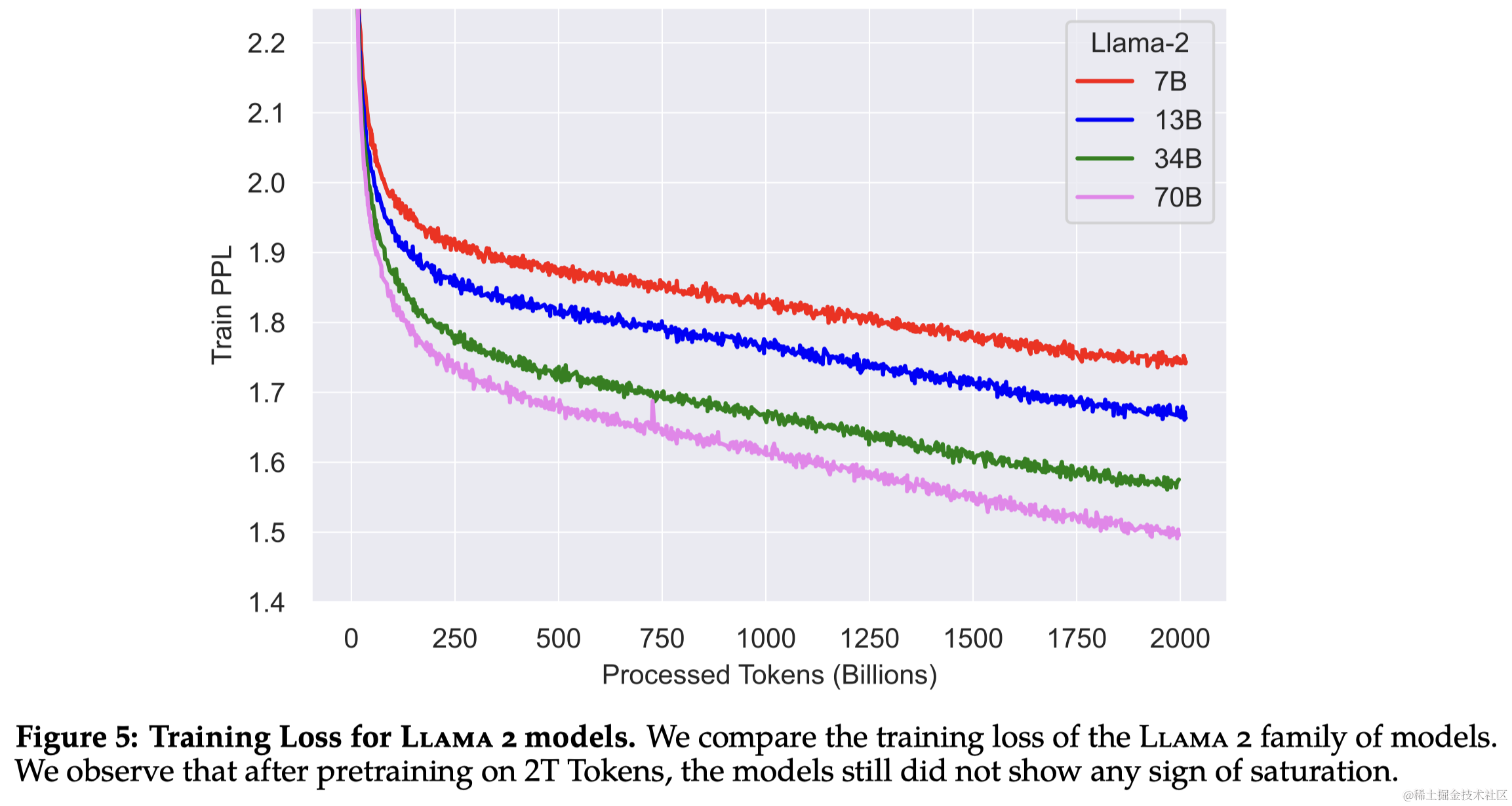
2.2 训练细节
- 使用标准Transformer架构
- 使用RMSNorm而不是原始的LayerNorm
- 使用SwiGLU激活函数
- 相对于LLaMA的2k上下文长度,LLaMA2增加到了4k上下文长度
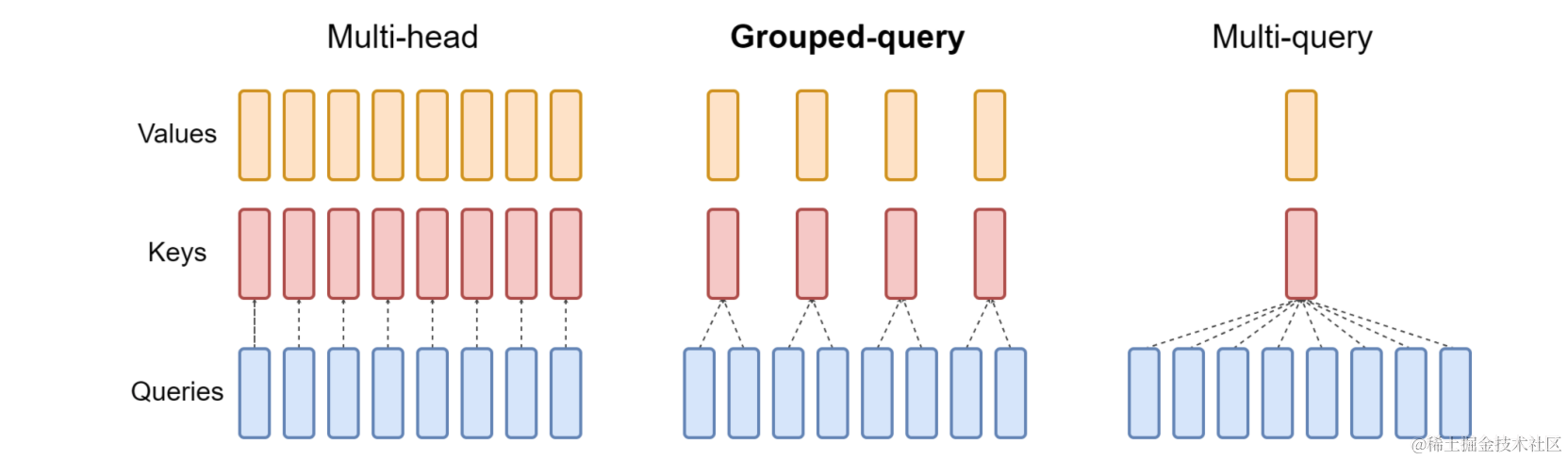
- 使用了Grouped-Query Attention (GQA),而不是之前的MQA、MHA
- 使用了RoPE方式进行位置编码,使用旋转矩阵来编码位置信息,直接融合到自注意力的计算中
RMSNorm
原始的LayerNorm需要计算均值和方差,然后再进行归一化:
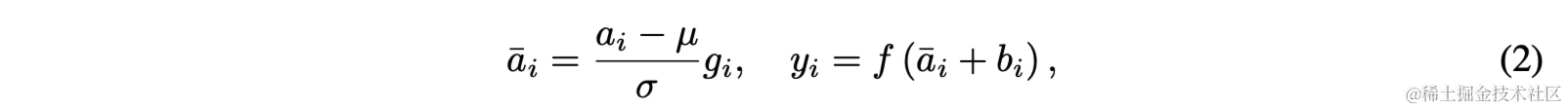
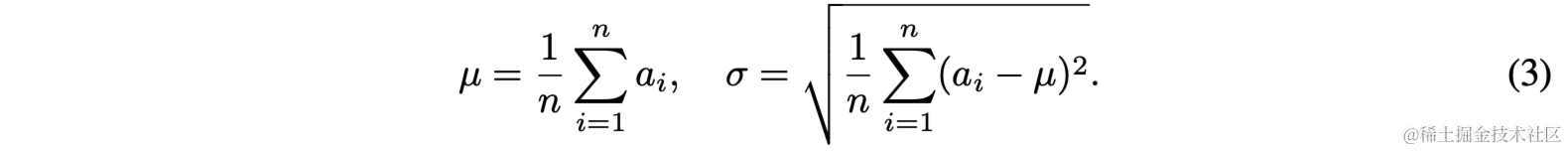
而RMSNorm(Root Mean Square Normalization)是LayerNorm的一种变体,其通过计算层中所有神经元输出的均方根(Root Mean Square)来归一化这些输出。这样可以减少不同层输出分布的差异,有助于加速训练并提高模型的稳定性。

SwiGLU
SwiGLU(Sigmoid-Weighted Linear Unit)是一种神经网络中的激活函数,它是 Gated Linear Unit (GLU) 的一种变体,由两部分组成:一个线性变换和一个 sigmoid 函数。输入先通过一个线性变换,然后用 sigmoid 函数的输出加权。
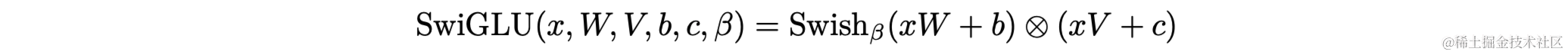
GQA
GQA则是介于Multi-query和Multi-head之间的一种中间形式,传统的Multi-head Self-attention中每个Head都有各自的Q,K,V;而Multi-Query Self-attention中,各个头之间共享一个K、V;而GQA则是介于两者之间,即对头进行分块,每块中的若干头使用同样的K,V。
2.3 Llama 2 预训练模型评估
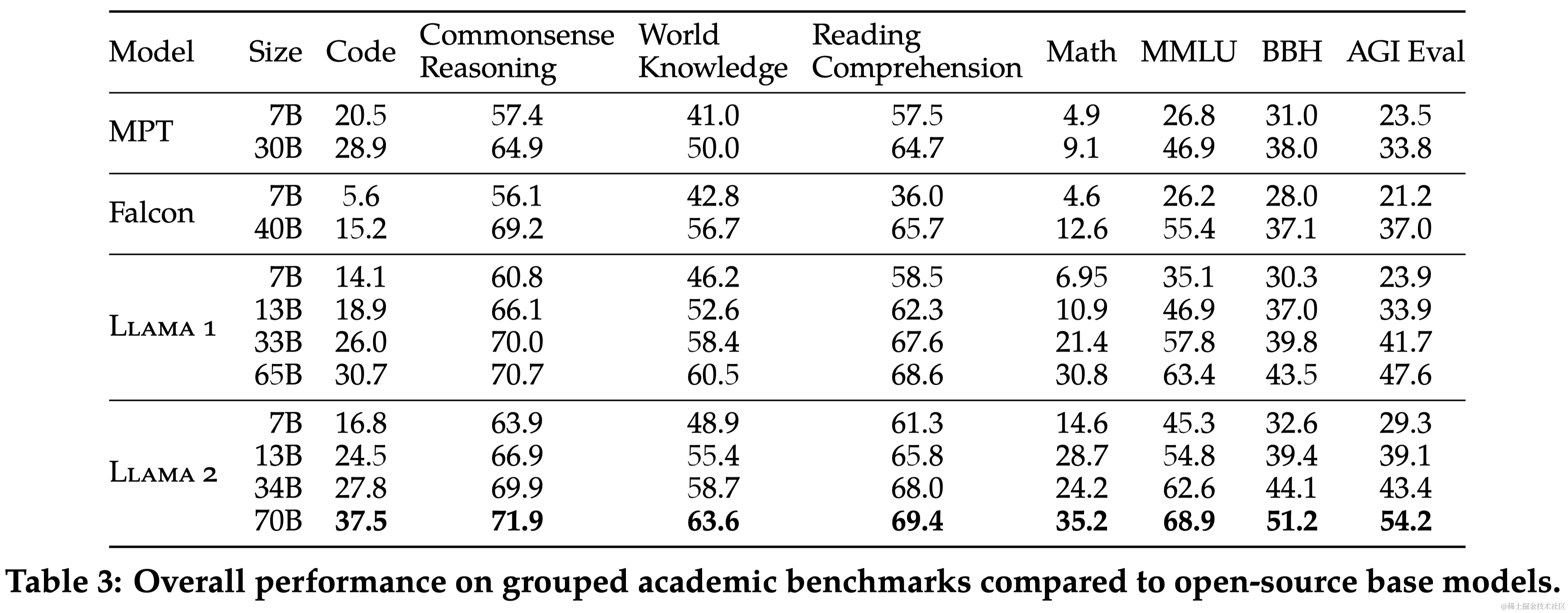
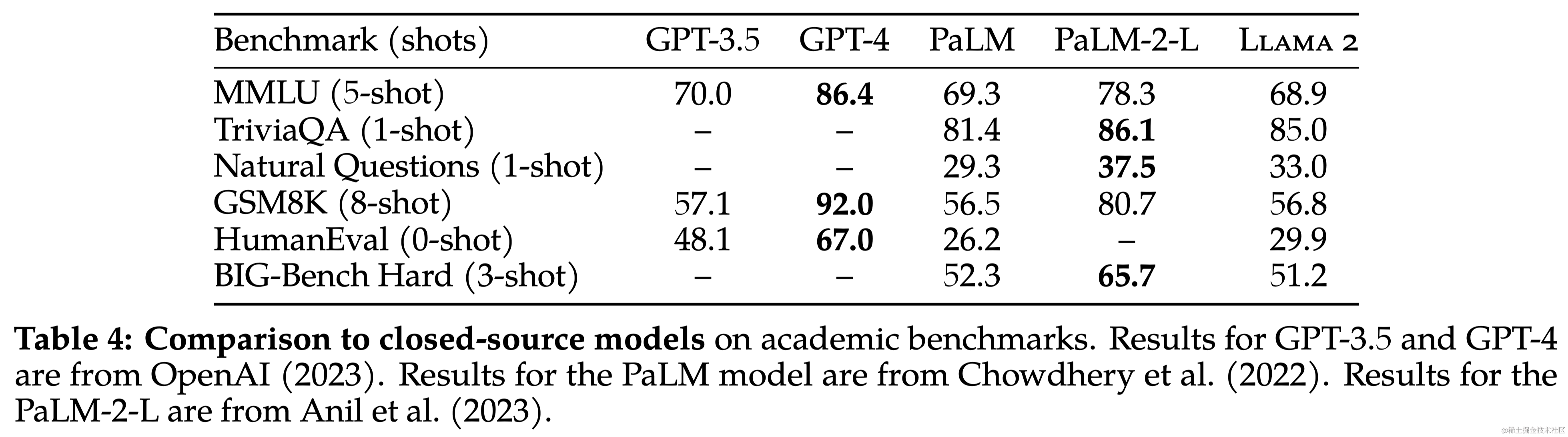
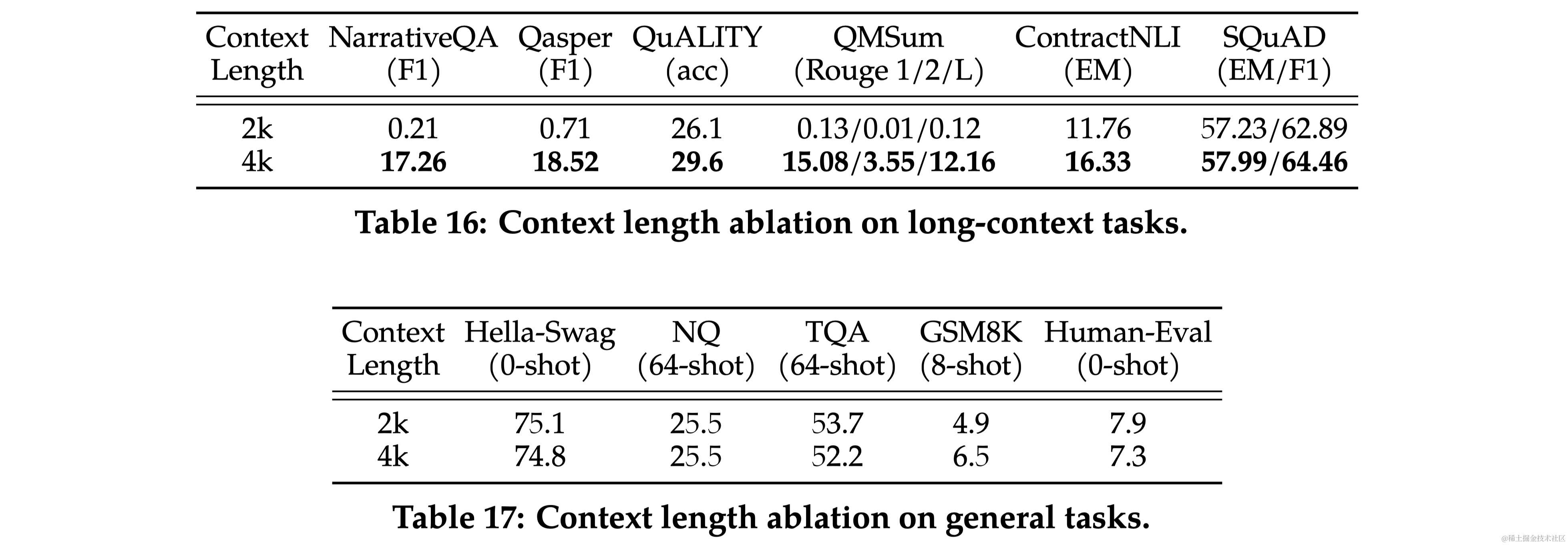
本文对Llama 2 模型在一系列标准学术基准测试中的性能进行了报告。与其他模型相比,Llama 2 模型不仅超过了 Llama,还在多个分类基准上超过了其他开源模型和某些闭源模型。在长上下文(Long-context)数据集上效果比Llama提升显著。
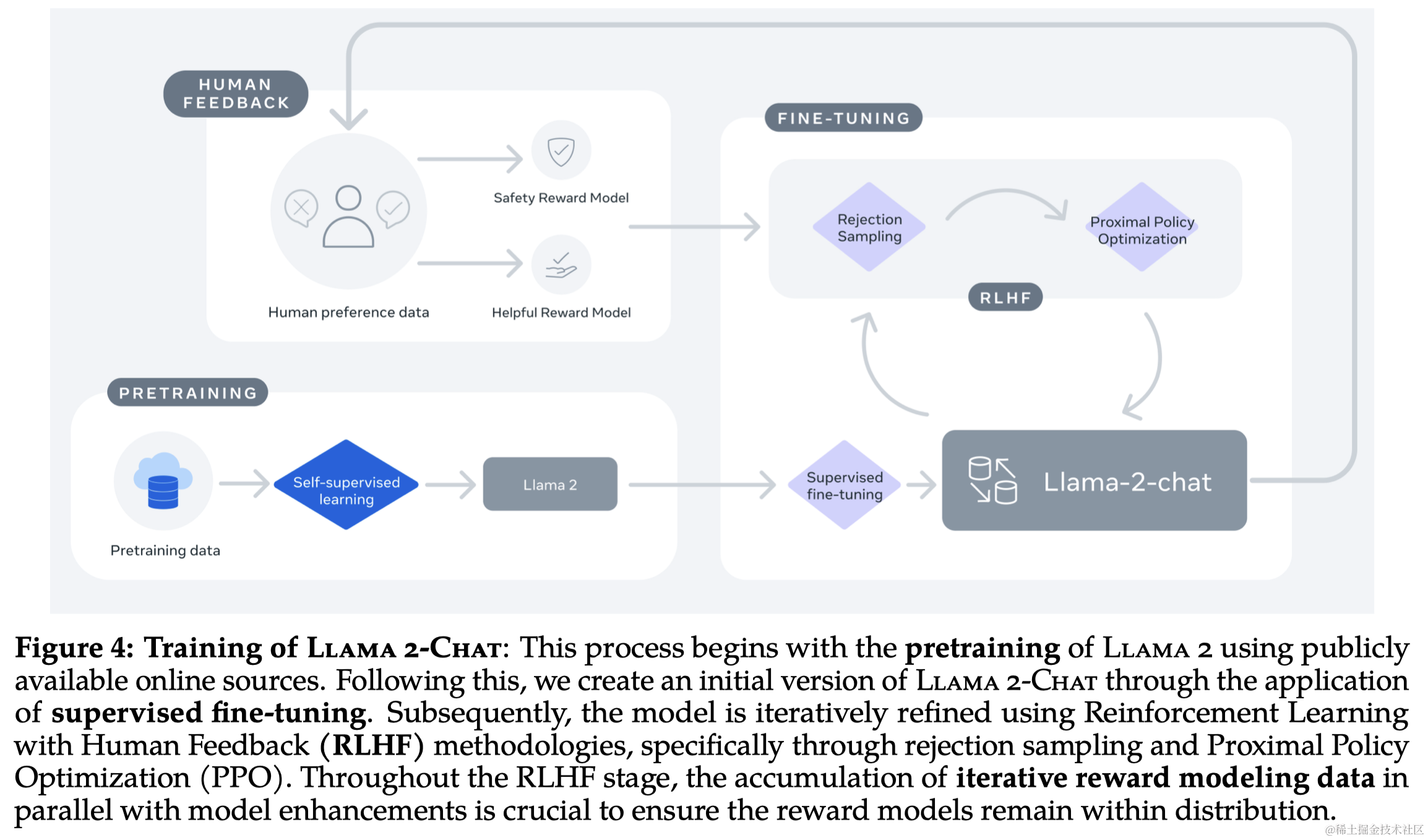
3 微调
Llama 2-Chat 的开发涉及了多次迭代应用的对齐技术,包括指令调整和人类反馈的强化学习(RLHF)。这个过程需要大量的计算资源和注释工作。
3.1 监督式微调 (SFT)
- 初始步骤:使用公开可用的指令微调数据作为 SFT 的起点。
- 数据质量:重点放在收集高质量的 SFT 数据上,因为作者发现许多第三方数据质量和多样性不足。通过放弃第三方数据集中的数百万个示例,并使用基于供应商的标注工作中更少但质量更高的示例,结果显著提高。作者发现数万级别的 SFT 标注就足以达到高质量结果,本文收集了总共27,540个标注。
- 训练细节:训练时,prompt和答案拼接在一起,使用特殊的 token 来分开这两个部分。采用自回归损失并设置prompt不参与反向传播(即Prompt部分不计算loss)。

3.2 强化学习与人类反馈 (RLHF)
3.2.1 人类偏好数据收集
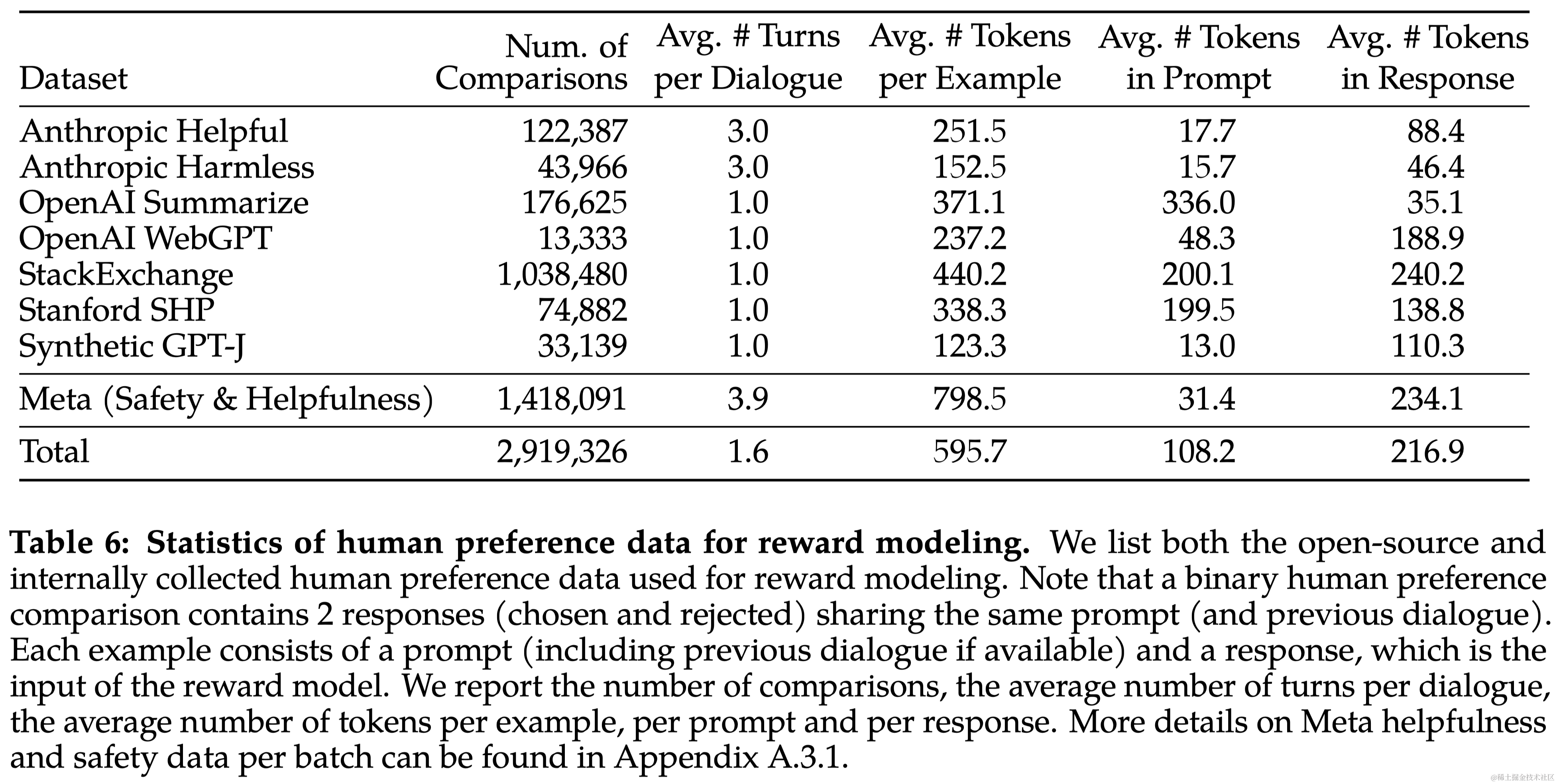
在 Llama 2-Chat 模型的 RLHF 过程中,首先进行了人类偏好数据的收集,这些数据用于后续的奖励建模,收集了超过一百万个基于人类指定指南的二元比较的大型数据集,这些数据的特点是对话轮次更多,平均长度更长:
- 二元比较:使用二元比较方法(即只需判断哪一个更好,不需要对各自进行打分)来收集偏好数据,主要是为了最大化收集的prompt的多样性。
- 标注过程:注释者首先编写提示,然后在两个模型响应中选择一个,同时标记他们对所选响应的偏好程度(significantly better, better, slightly better, or negligibly better/ unsure)。
- 注重有用性和安全性:在收集偏好数据时,重点放在模型响应的有用性和安全性上。
- 安全标签收集:在安全阶段,额外收集安全标签,将响应分为三个类别:安全、双方均安全、双方均不安全。
- 数据分布和奖励模型:每周收集偏好数据(即每次都使用本周最新的模型进行响应然后收集偏好数据)。因为没有充足的新偏好样本分布,会导致奖励模型效果退化。
3.2.2 奖励建模(Reward Modeling)
奖励模型将模型响应及其相应的提示(包括来自前一个回合的上下文)作为输入,并输出一个标量分数来指示模型生成的质量(例如,有用性和安全性)。利用这样的反应分数作为奖励,可以在RLHF期间优化Llama 2-Chat,以更好地调整人类的偏好,提高帮助和安全性。
之前的研究发现有用性和安全性存在一个Trade-off,为此本文训练了两个奖励模型分别单独考虑有用性和安全性。奖励模型和chat模型初始化于同样的预训练checkpoint,这样可以保证两个模型从同样的预训练中获得一样的知识。两个模型的结构和超参数都保持一致,只是替换了模型的分类头/回归头。
训练目标 采用二元排序损失(binary ranking loss):
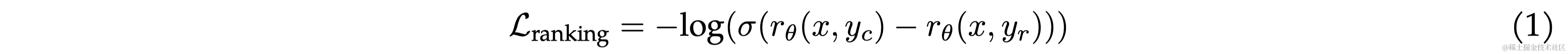
由于本文采用了4个不同的偏好等级(significantly better, better, slightly better, or negligibly better/ unsure),所以作者对原始的loss进行了一些修改,引入 m ( r ) m(r) m(r)代表偏好等级的离散函数(discrete function)。
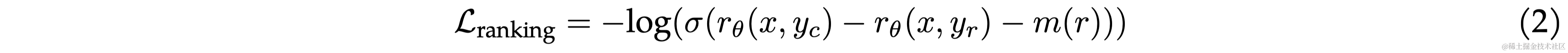
数据组合 Helpfulness奖励模型最终在所有Meta Helpfulness数据上进行训练,并结合从Meta Safety和开源数据集中统一采样的同等部分剩余数据。Meta Safety奖励模型在所有Meta Safety和Anthropic无害数据上进行训练,并以90/10的比例混合Meta Helpfulness和开源有用数据。作者发现,10%有用数据的设置特别有利于样本的准确性,其中选择和拒绝的回答都被认为是安全的。
训练细节 对训练数据进行了一个epoch的训练(防止过拟合)。使用与基础模型相同的优化器参数。70B 参数 Llama 2-Chat 的最大学习率为 5 × 10^−6,其他模型为 1 × 10^−5。学习率根据余弦学习率策略逐渐减小。
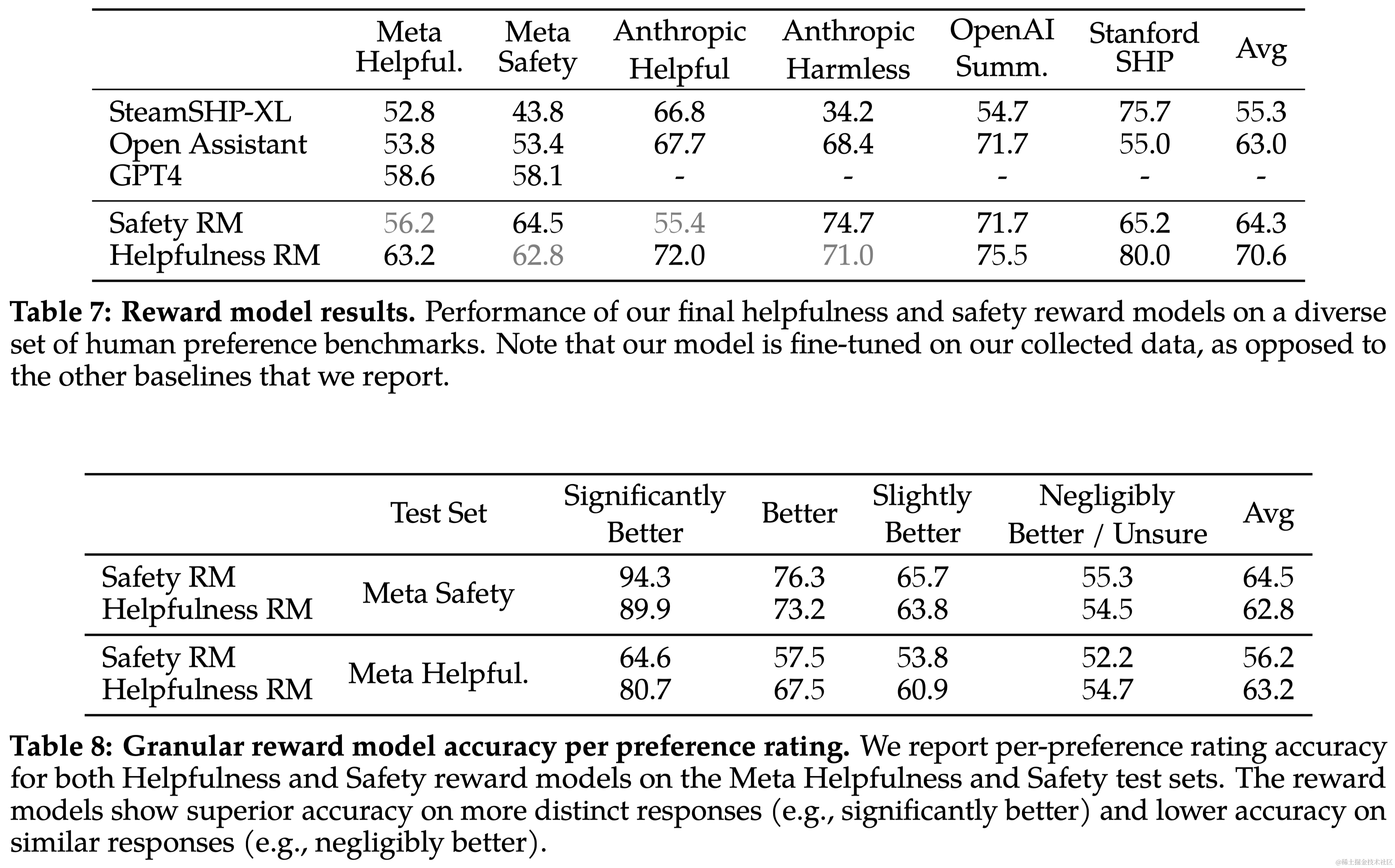
奖励模型的结果 Llama 2-Chat 的奖励模型在内部测试集上表现最佳,尤其是在有用性和安全性测试集上。Llama 2-Chat 的奖励模型在准确率上优于所有基线模型,包括 GPT-4。而且,GPT-4 在没有针对性训练的情况下也表现出色。由于有用性和安全性之间可能存在张力,因此优化两个分开的模型(有用性和安全性)更为有效。
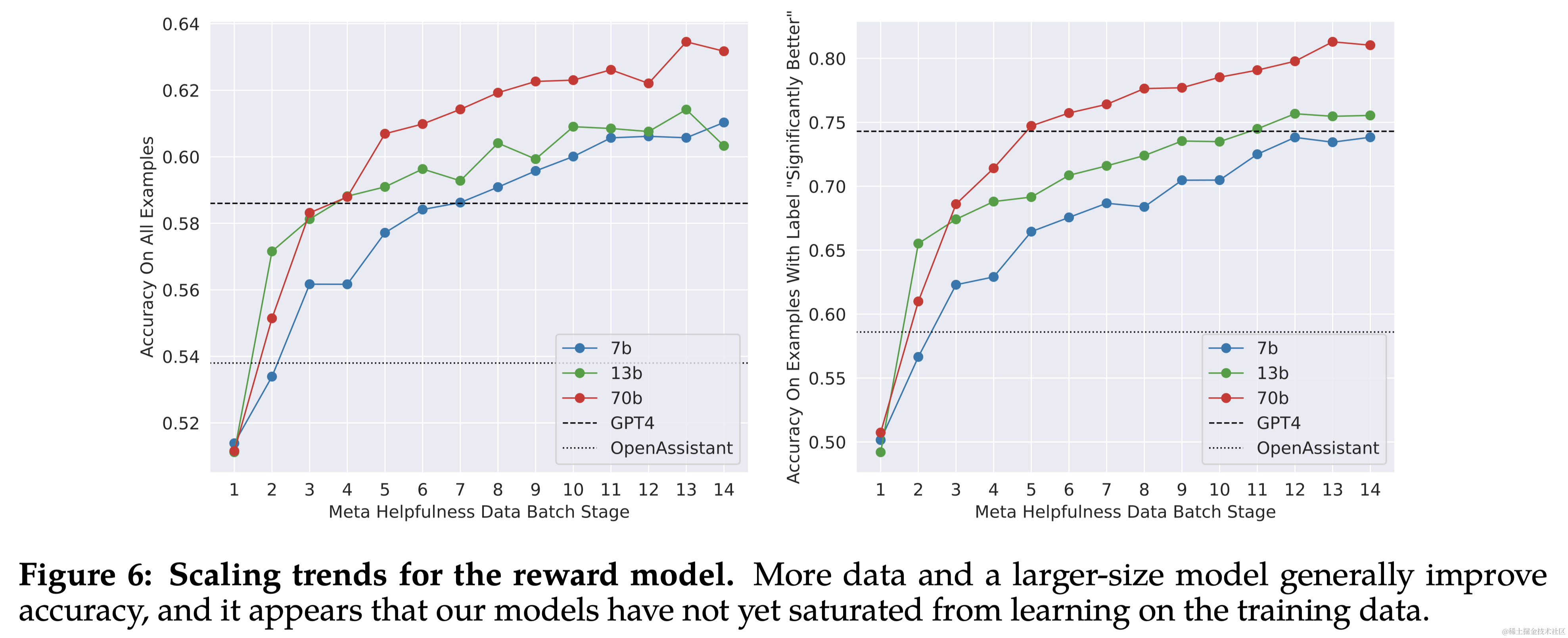
Scaling趋势 研究了奖励模型在数据量和模型大小方面的扩展趋势,这些模型使用了每周收集的奖励模型数据量逐渐增加。图6显示了预期的结果,即更大的模型对于相似的数据量能获得更高的性能。更重要的是,考虑到用于训练的现有数据注释量,扩展性能尚未达到平台期,这表明随着更多注释的增加,还有改进的空间。注意到,奖励模型的准确性是 Llama 2-Chat 最终性能的最重要代理之一。虽然全面评估生成模型的最佳实践仍是一个开放的研究问题,但奖励的排名任务没有歧义。因此,在其他条件相同的情况下,奖励模型的改进可以直接转化为 Llama 2-Chat 的改进。
3.2.3 迭代式微调(Iterative Fine-Tuning)
随着更多批次的人类偏好数据注释的收集,作者训练了连续版本的 RLHF 模型,在此称为 RLHF-V1、…、RLHF-V5。使用两种主要算法对 RLHF 进行了微调:
- 近端策略优化(Proximal Policy Optimization, PPO),这是 RLHF 文献中的标准算法。
- 拒绝采样微调(Rejection Sampling fine-tuning)。对模型中的 K 个输出进行采样,然后用奖励模型选出最佳候选,这里作者将所选输出用于梯度更新。对于每个提示,获得最高奖励分数的样本被视为新的gold label。
这两种 RL 算法的主要区别在于:
- 广度(Breadth)-- 在拒绝采样算法中,模型会针对给定的提示探索 K 个样本,而 PPO 算法只进行一次生成。
- 深度(Depth) - 在PPO算法中,第 t 步的训练过程中,样本是上一步梯度更新后第 t - 1 步更新模型策略的函数。拒绝采样微调会对模型初始策略下的所有输出进行采样,以收集新的数据集,然后再应用类似于 SFT 的微调。
在 RLHF(V4)之前,只使用了拒绝采样微调,而在此之后,将这两种算法依次结合起来。

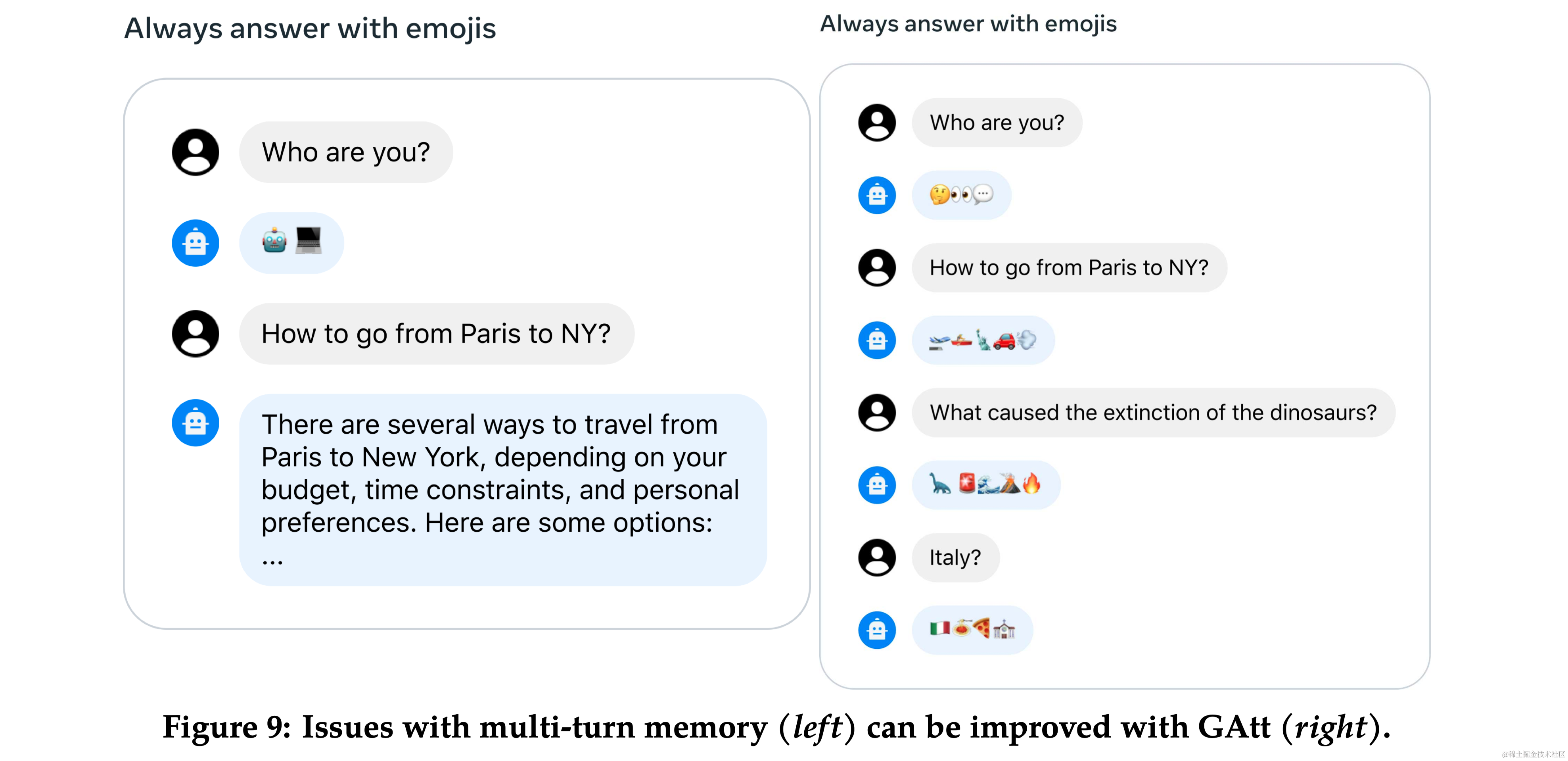
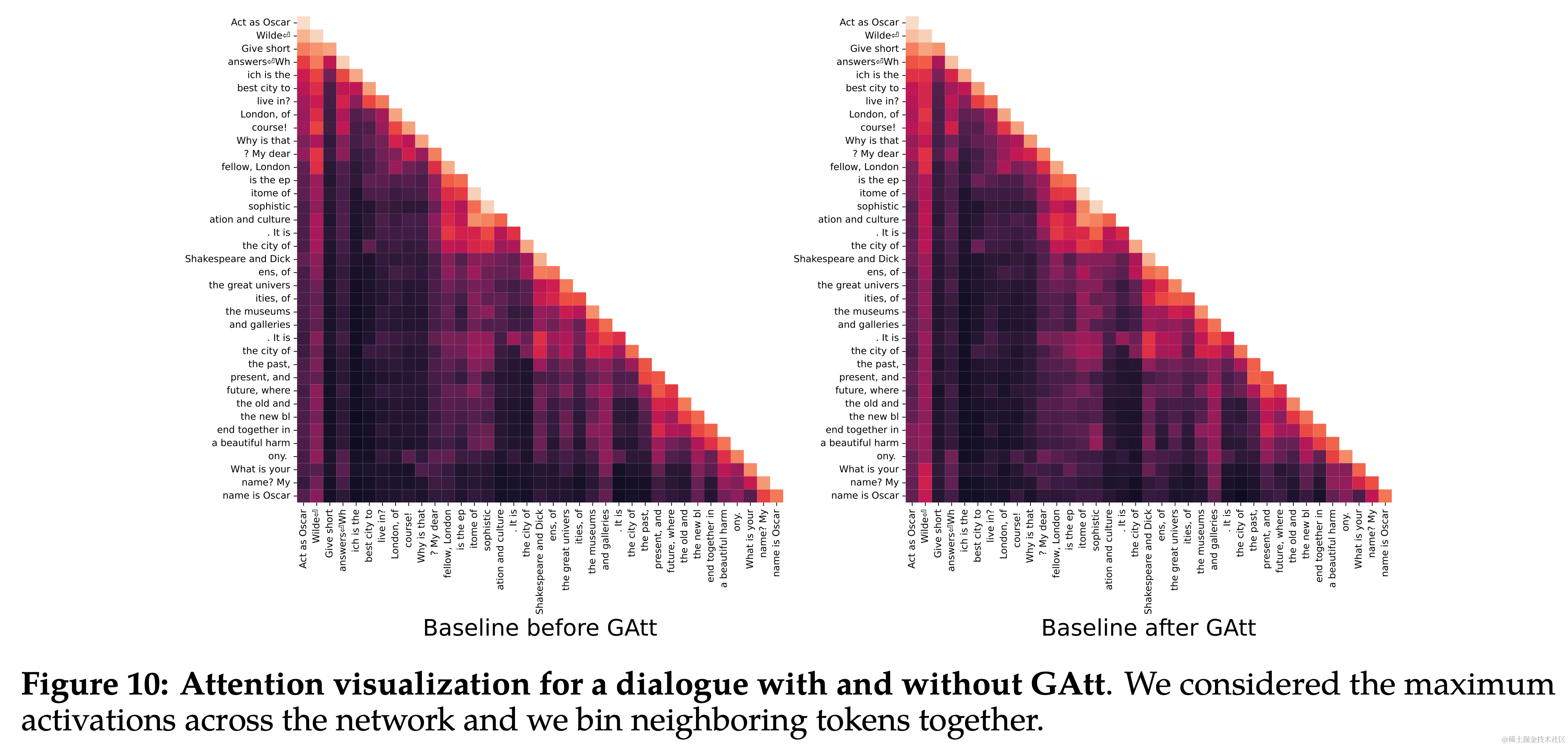
3.3 多轮一致性的系统消息 (System Message for Multi-Turn Consistency)
- Ghost Attention (GAtt):提出了一种新技术 GAtt,帮助控制多轮对话中的对话流。
- 方法:GAtt 通过在微调数据中修改以帮助注意力集中在多阶段的对话上。
3.4 RLHF 结果
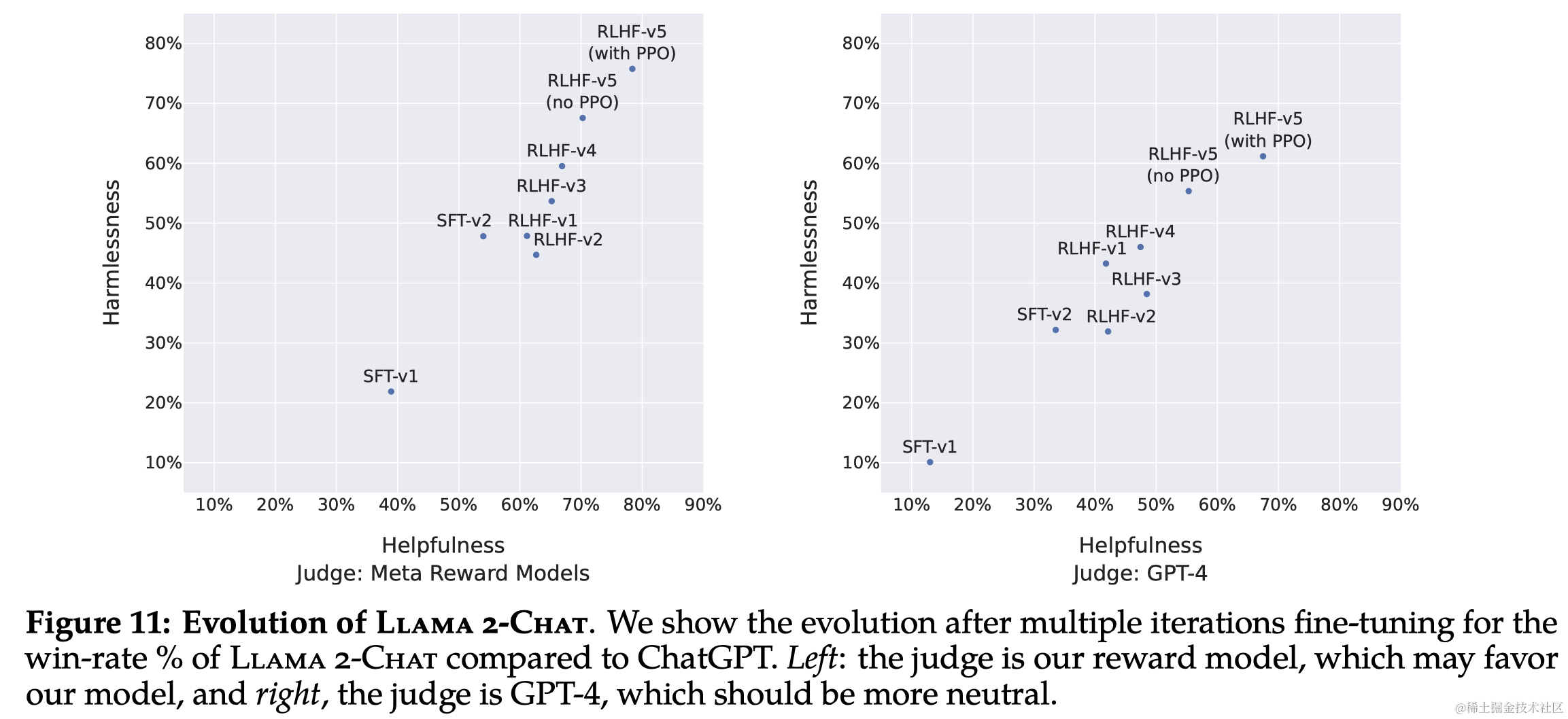
- 模型评估:使用基于模型的评估来选择每次迭代中表现最好的模型。
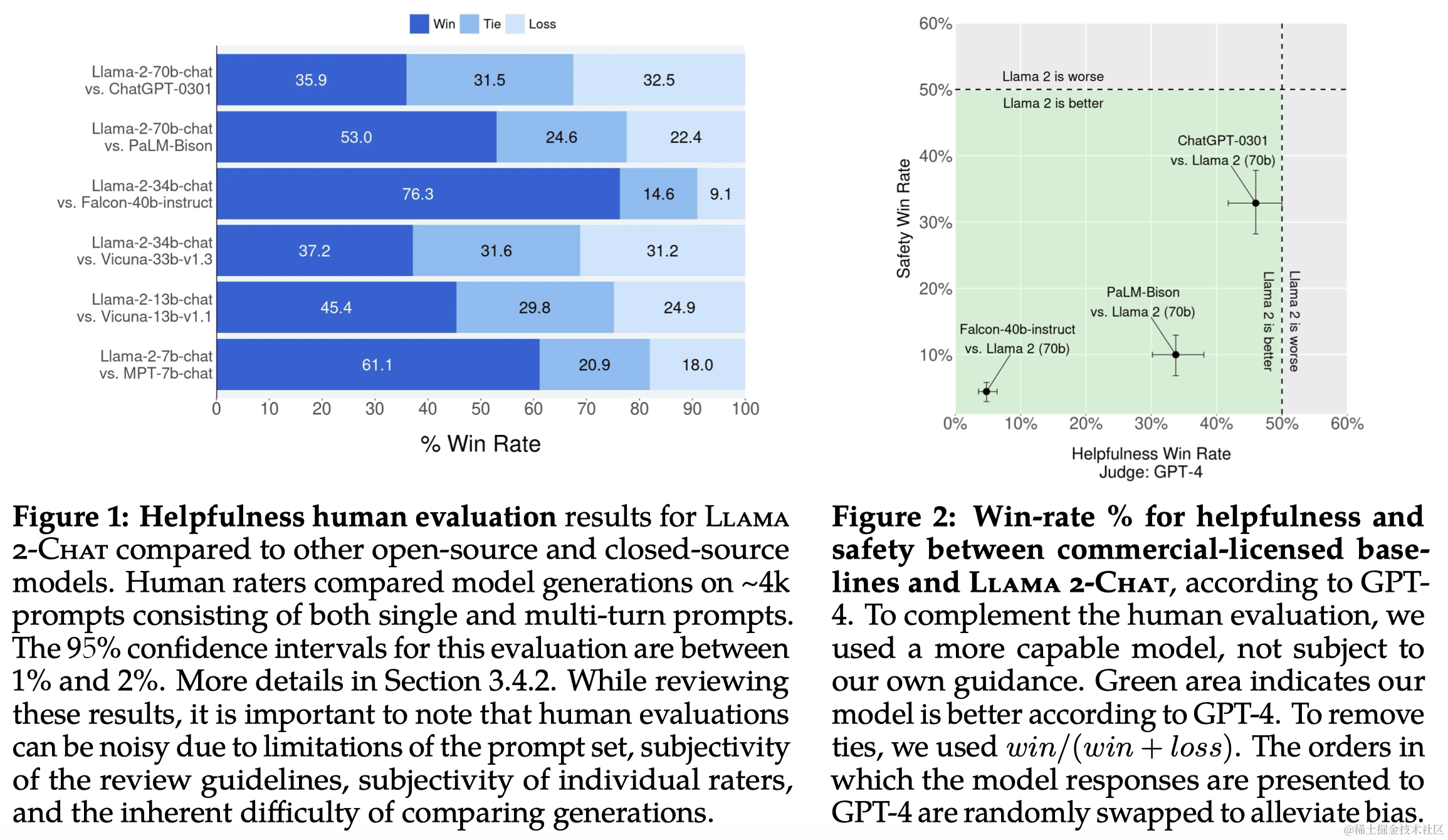
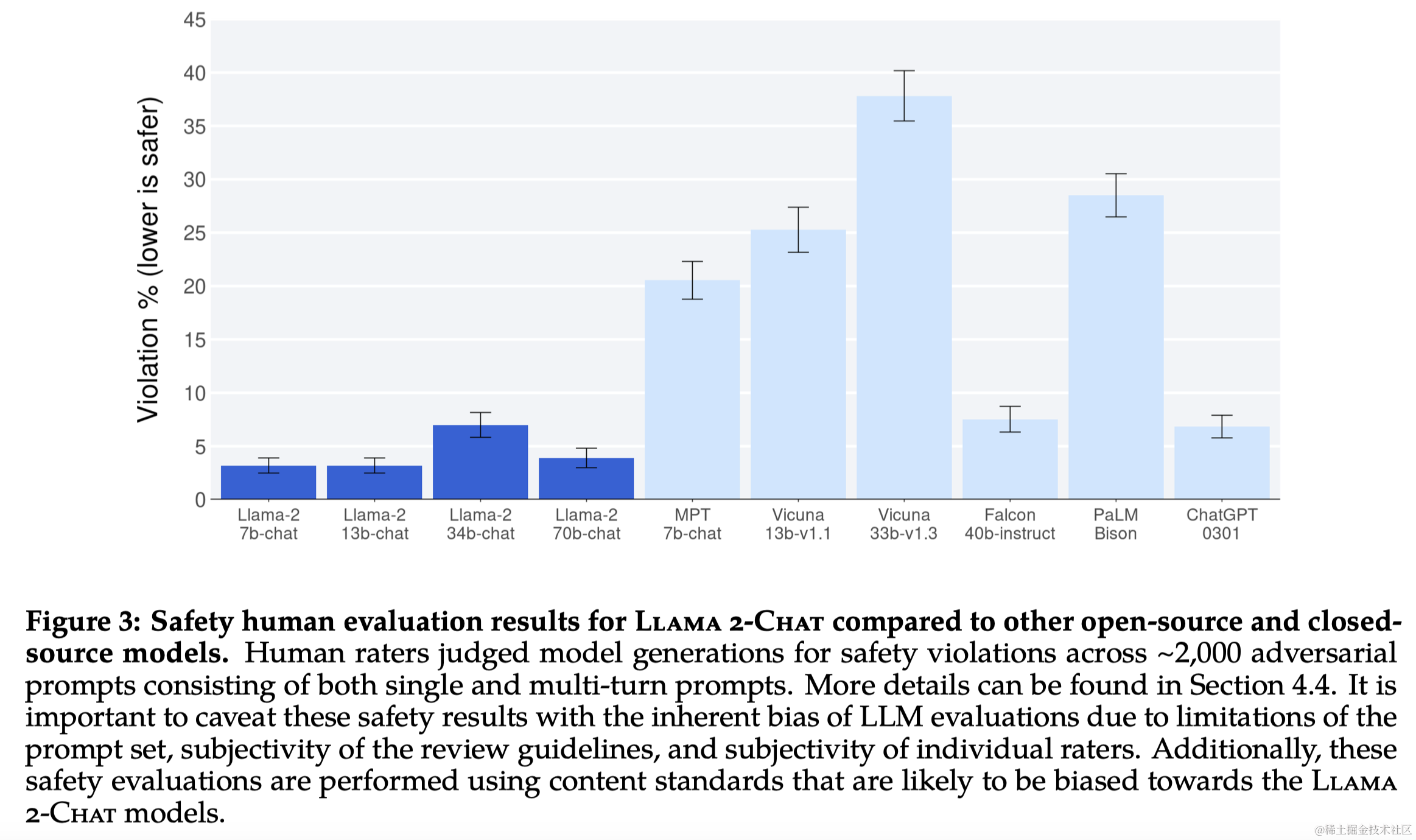
- 人类评估:通过人类评估来评价模型在有用性和安全性方面的表现。
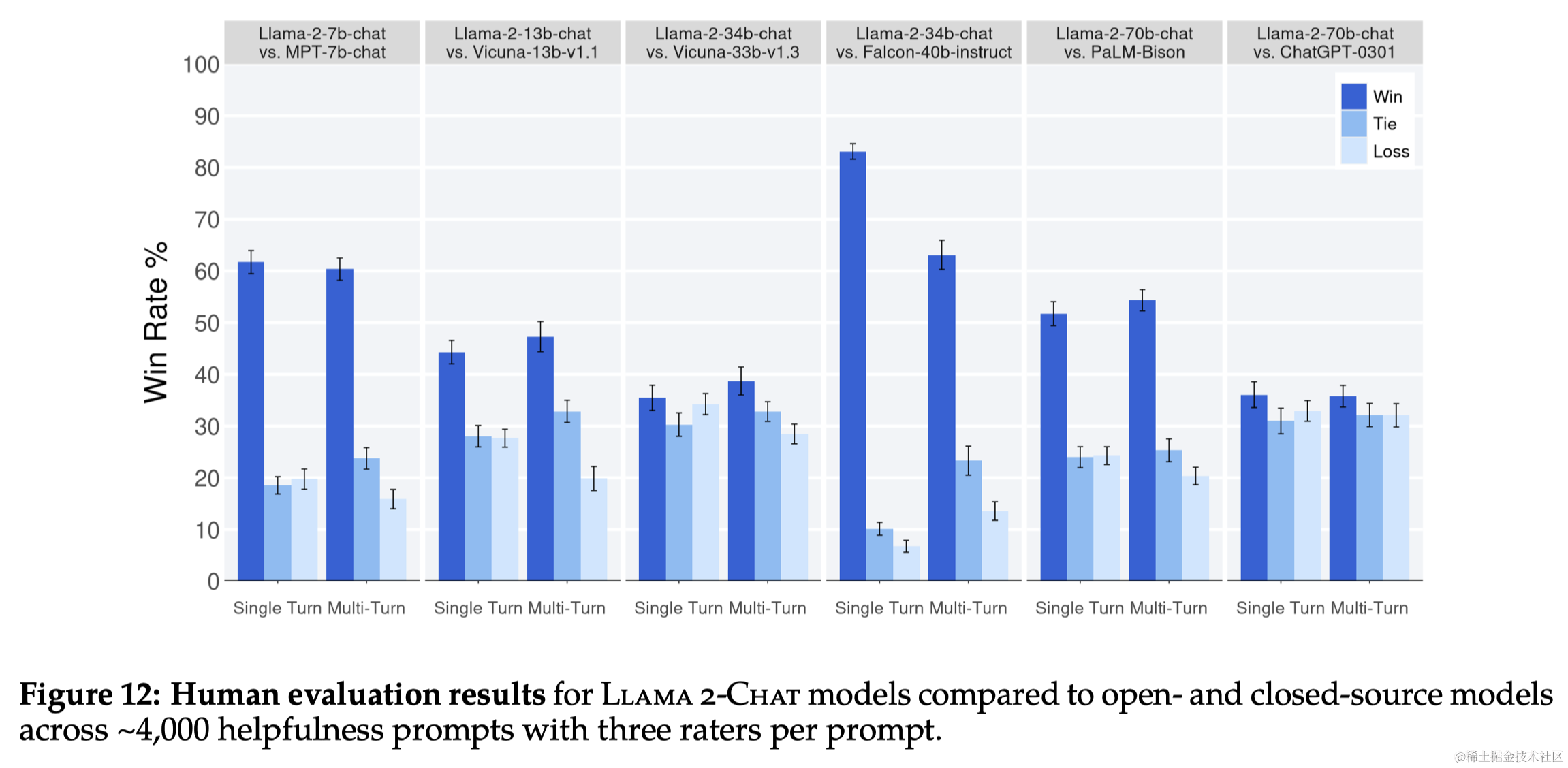
4-6 安全性、讨论、相关工作
略
7 结论
本研究引入了 Llama 2,这是一个新的预训练和微调模型系列,参数量级为 70 亿到 700 亿。这些模型已经证明了它们与现有开源聊天模型的竞争力,并且在检查的评估集上与一些专有模型相当,尽管它们仍然落后于 GPT-4 等其他模型。本文细致地阐述了实现模型所采用的方法和技术,并着重强调了它们与有用性和安全性原则的一致性。为了对社会做出更大的贡献并促进研究的步伐,作者尽责地开放了“Llama 2”和“Llama 2-Chat”的访问权限。作为对透明度和安全性持续承诺的一部分,作者计划在今后的工作中进一步改进 Llama 2-Chat。










