本篇介绍httprunner中hook函数的使用,以及通过编程能力实现建设自动化测试更全面的场景覆盖
前置:
互联网时代让我们更快的学习到什么是Httprunner
正文:
举个例子:假设我们的业务系统目前是通过Kafka来实现消息的交互,A系统生产的消息B系统需要去消费处理后在生产消息给到下游系统
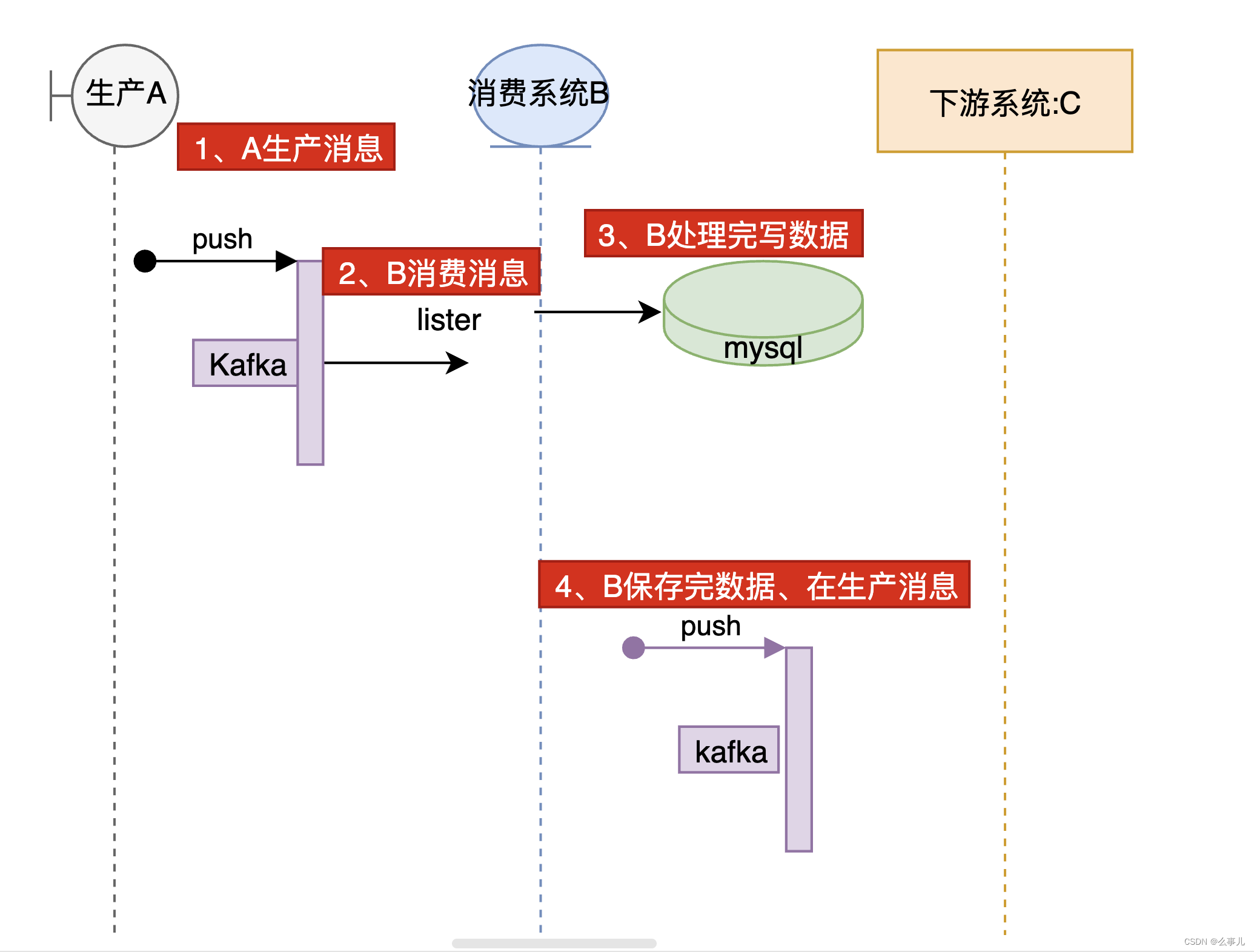
那么如果说我们需要为B系统编写这类流程的自动化,我们需要怎么实现呢?
一)设计
首先考虑一个问题:如果A系统是独立系统,如果我们写的自动化要依赖A系统的数据那就耦合度太高了。如果我们只考虑B系统的完整性,那么我们完全可以把A mock掉,将A生产的报文消息当作cases,通过python脚本来实现。
然后B系统消费后会操作数据库,那么我们断言是否可以也读数据库去判断是否预期
其次B会发消息来通知下游系统消费,那么我们是不是也可以写一个kafka监听消费消息,判断报文是否符合预期
二)实现
1、先写一个发送消息的函数,这个地方加一个参数是为了写多个cases
import json
from kafka import KafkaProducer
def sengMessage(tag):
producer = KafkaProducer(bootstrap_servers='这个地方写集群名称')
if('A' == tag):
msg_dict = {
"CMD": "这个地方是CMD",
"Data": "这个地方是消息体",
"Key": "这个是Key",
"LogID": "681533193628954414",
"Tag": "这个是标识",
"TimeStamp": "这是个时间",
"Topic": "这是个要发送的主题"
}
msg = json.dumps(msg_dict).encode()
#partition这个地方写的是0表示放0这个Partition上了,如果要随机就看你有几个Partition,random一下
producer.send("这个地方放主题topic", msg, partition=0)
producer.close()2、然后将这个函数放到debugtalk.py文件里面
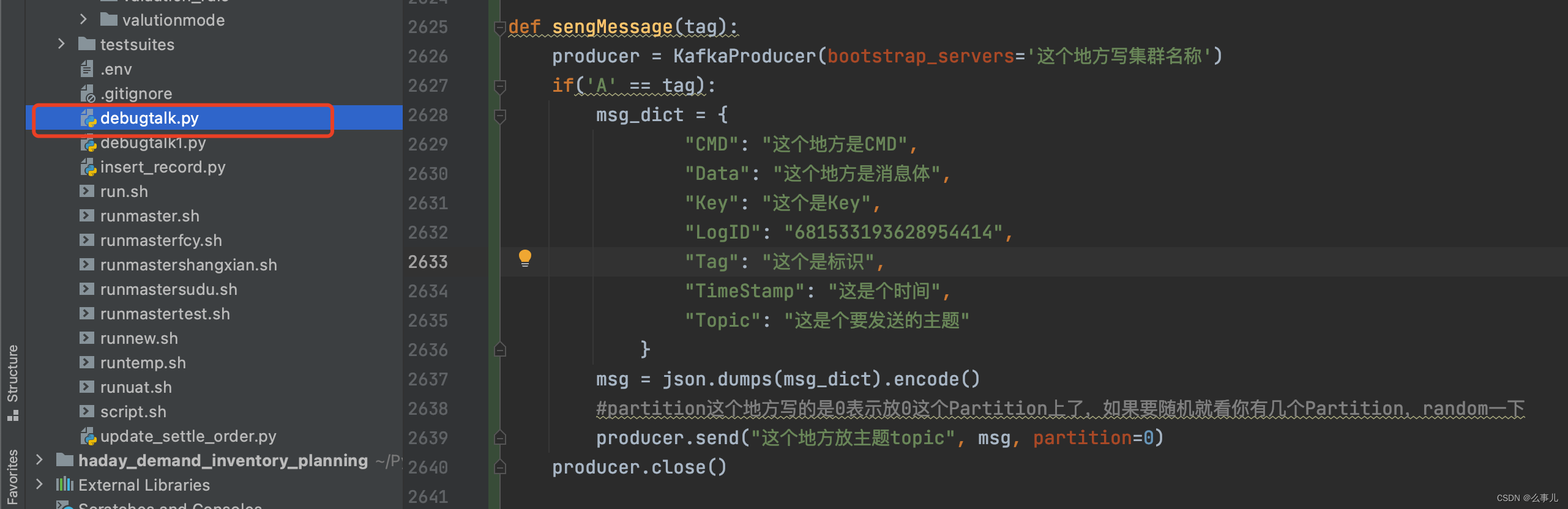
3、编写一个cases,将此函数引用到setup_hooks
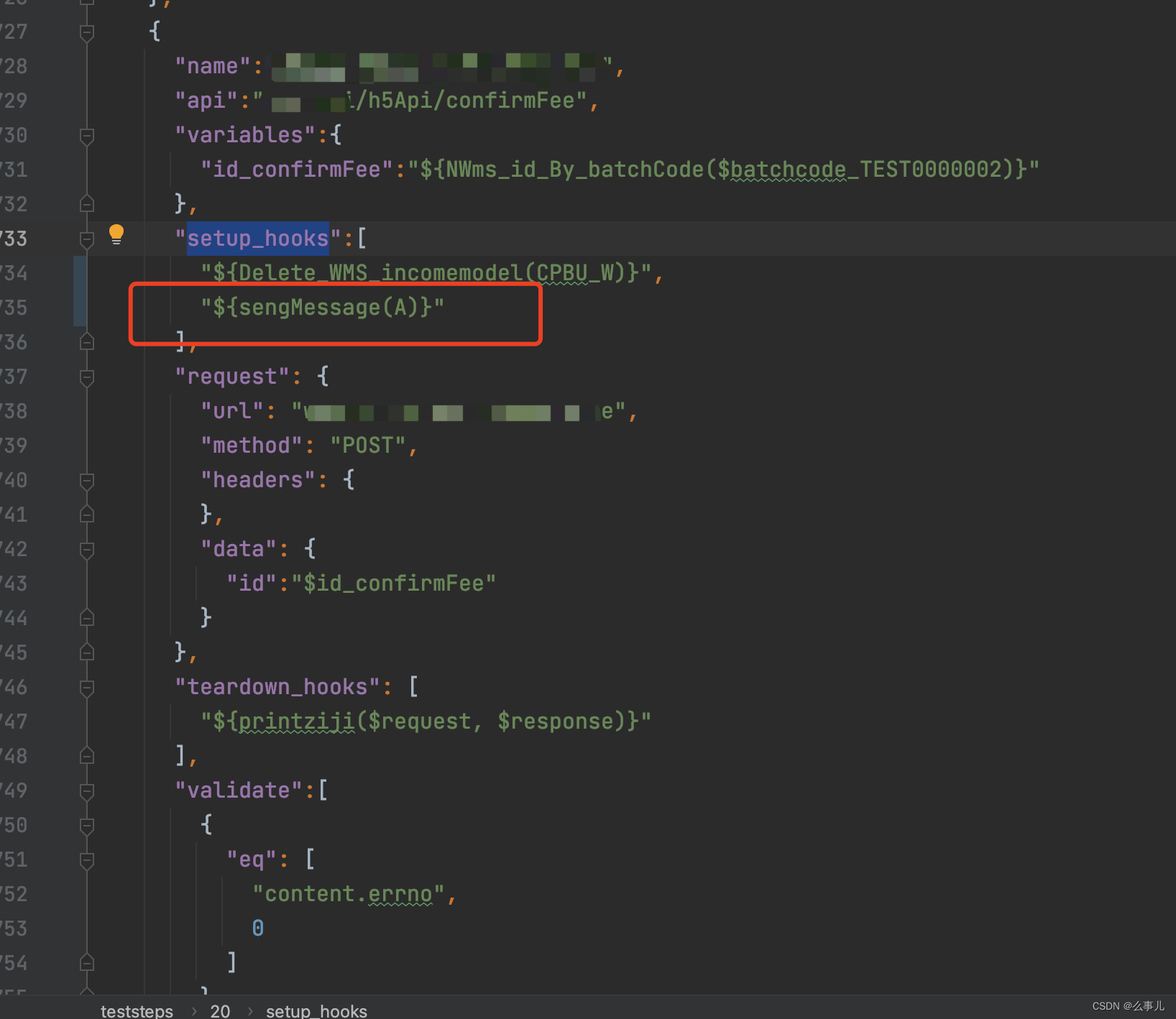
使用方式就是${函数名称(参数)},说明一下就是为啥要在setup_hooks里面使用,是因为需要在执行cases之前将消息发送之后系统消费到了才能走后面的流程(就是前置)
然后这个前置操作可以做:消息的发送、数据的处理(比如删除数据,更新数据等等)
4、编写一个操作数据库的函数
import pymysql
import yaml
from loguru import logger
from lib import utils
class MySQL(object):
"""Mysql数据库操作
"""
db = {}
def __init__(self, db):
"""初始化数据库对象
Args:
db (str): 数据库名字,代表了db配置的某个文件,数据库连接信息也在对应文件配置
"""
file = f"{utils.get_root_path()}/conf/{db}.yml"
with open(file, encoding="utf-8") as conf:
self.db = yaml.load(conf, Loader=yaml.FullLoader)
def execute(self, sql):
"""在mysql上执行一个sql语句,返回的结果为多条记录的元组,每条记录为dict,内容为字段-值字典
Returns:
[tuple]: 执行结果
"""
self.db['cursorclass'] = pymysql.cursors.DictCursor
try:
connection = pymysql.connect(**self.db)
logger.info(f"execute sql: [{sql}]")
with connection.cursor() as cursor:
cursor.execute(sql)
data = cursor.fetchall()
logger.debug(f"execute ret: [{data}]")
connection.commit()
finally:
connection.close()
return data
#怎么使用呢,就是直接用这个函数传配置文件名称,sql
if __name__ == '__main__':
MySQL("auto").execute("select * from A limit 1")设置放置存储数据库配置文件的目录
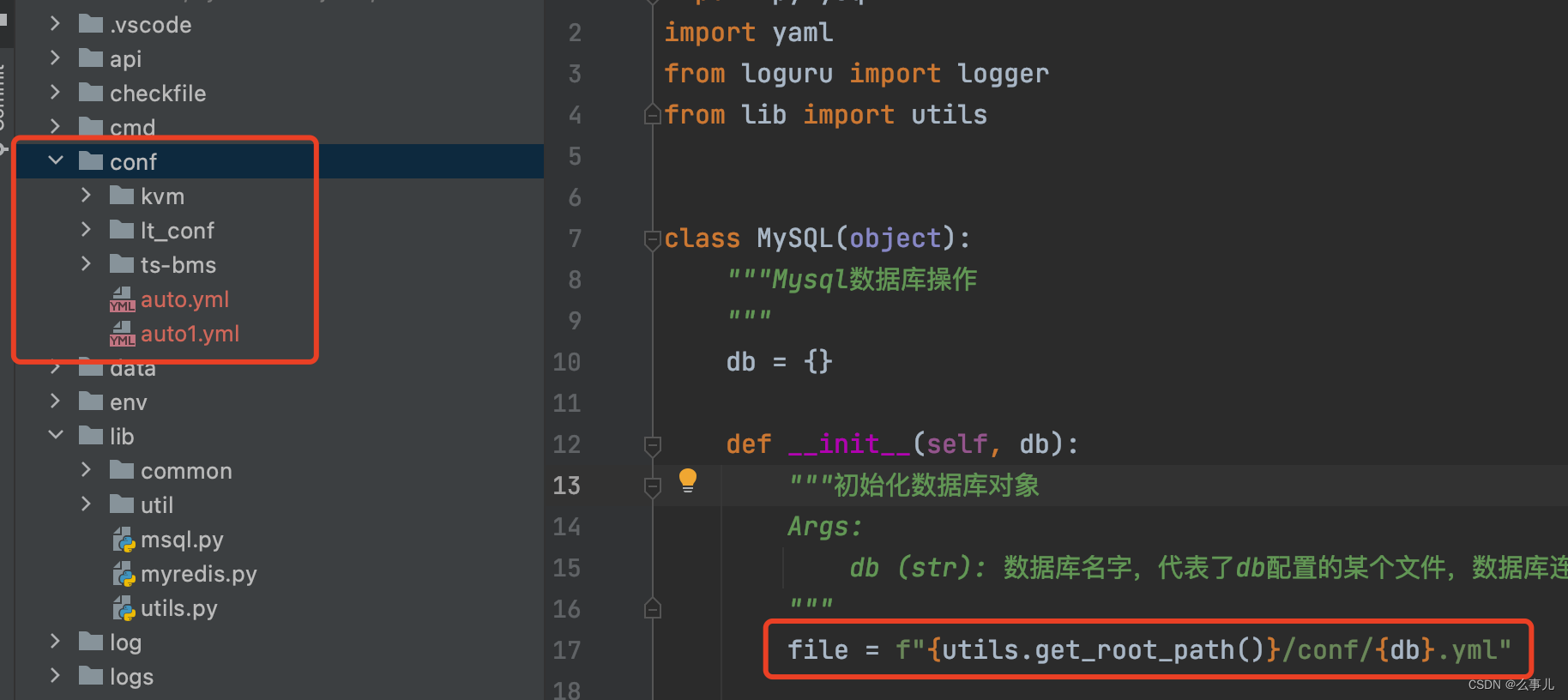 数据库配置
数据库配置
host: IP
port: 端口
user: 用户名
passwd: 密码
db: 数据库5、能操作数据库之后,那么我们是否可以将查询回来的全部重要字段(什么自增主键ID、时间啥的就不用断言了)进行判断了,写一个比较json的函数
class Check(object):
def CheckSql(prama):
db = 'auto'
errmsgl_success = 'success'
sql = 'SELECT A,B,C,D,E,F,G,H,I,J,K from AAA where aa=' + '\'' + str(
prama) + '\''
sql_count = 'SELECT count(1) from AAA WHERE (aa = ' + "\'" + str(
prama) + "\'" + ')'
# 先查询条数,没有就重试,如果重试还没有就失败
count = MySQL(db).execute(sql_count)[0]['count(1)']
retry = 0
while count == 0 and retry < 15:
time.sleep(3)
retry = retry + 1
count = MySQL(db).execute(sql_count)[0]['count(1)']
aa = MySQL(db).execute(sql)[0]
response = json.dumps(aa)
print(response)
# 这个地方,假如A字段是一个JSON,这个地方是做了一个处理,让这个json排序,就不会出现每次查询这个json都是乱序得导致断言失败
# 假设A字段:[{fee:1},{fee:2},{fee:3}],那么我们就用fee来排序
A = eval(str(aa["A"]))
aa["A"] = sorted(A, key=lambda x: (x['fee']), reverse=True)
print(json.dumps(aa))
# 这个地方用的直接是传进来得参数作为文件名称
checkfile__detail = str(prama)
detail_ret = Check.checkfile_json(aa, checkfile__detail)
if detail_ret != errmsgl_success:
return '文件名称:' + checkfile__detail + ', 失败原因: ' + detail_ret
return errmsgl_success
# 读取对应的预期文件,这个函数可以抽出来,当一个公共方法
def checkfile_json(requestdata, checkfile):
# 文件地址当前项目/checkfile/checkfile.json
basic_url = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + '/checkfile'
if checkfile:
with open(basic_url + checkfile + '.json', 'r') as f:
setdatas = json.load(f)
return Check.cmp(requestdata, setdatas)
def cmp(src_data, dst_data):
msg = 'success'
if isinstance(dst_data, dict):
"""若为dict格式"""
for key in dst_data:
if key not in src_data:
return 'key: ' + str(key) + ' 在请求中不存在'
msg = Check.cmp(src_data[key], dst_data[key])
if msg != 'success':
return msg
elif isinstance(dst_data, list):
"""若为list格式"""
for src_list, dst_list in zip((src_data), (dst_data)):
"""递归"""
msg = Check.cmp(src_list, dst_list)
if msg != 'success':
return msg
else:
if str(src_data) != str(dst_data):
return 'src_data != dst_data, src_data: ' + str(src_data) + ', dst_data: ' + str(dst_data)
return msg6、断言函数既然已经写好了,那就直接引用,同上面那个流程,加载到debugtaik.py文件之后,我们需要在cases断言处加上此函数,还是用${函数名称(参数)}来引用
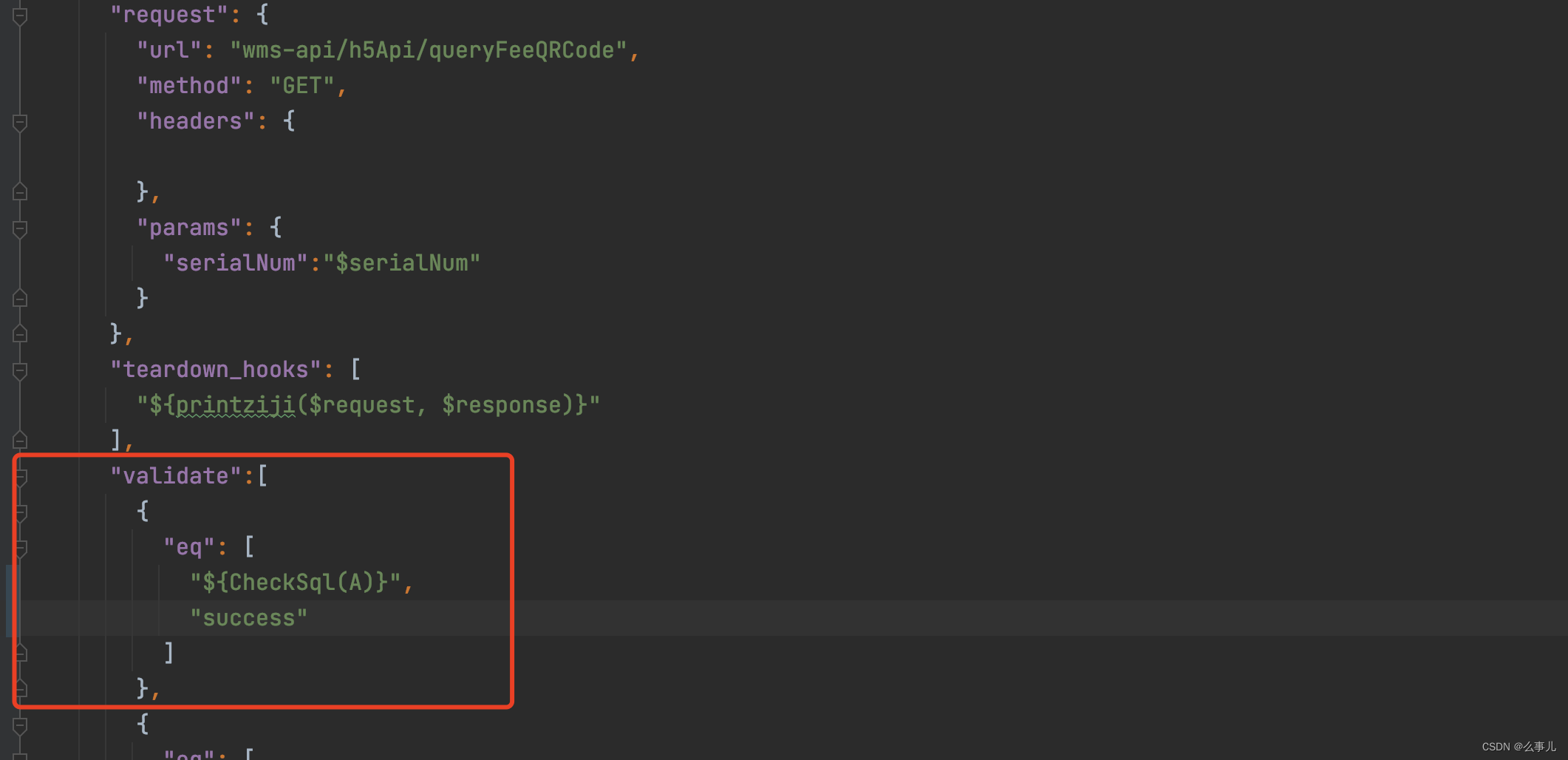
7、最后编写一下消费kafka消息进行断言的函数
def check_kafka_messgae(topic, bootstrap_servers, checkfile, enable_auto_commit=False, consumer_timeout_ms=300):
# 参数分别是主题,集群,断言文件地址,自动提交,超时时间
consumer = KafkaConsumer(bootstrap_servers=[bootstrap_servers], enable_auto_commit=enable_auto_commit,
consumer_timeout_ms=consumer_timeout_ms)
# 这个地方只监听一个partition == 0的
topic_partition = TopicPartition(topic=topic, partition=0)
lastoffset = consumer.end_offsets([topic_partition])[topic_partition]
consumer.assign([topic_partition])
consumer.seek(topic_partition, lastoffset - 1)
messagelist = ''
for message in consumer:
messagelist = message.value
messagelist = json.loads(json.loads(str(messagelist, 'utf-8'))['Data'])
print('topic数据' + str(messagelist))
# checkfile_json这个方法上面写得函数里面有,直接调用
return checkfile_json(messagelist, checkfile)8、同上,还是将这个函数加入到debugtaik.py,在validate里面进行断言判断
总结:
将上面的流程串起来之后发现,从kafak消息的发送、数据库的查询、文件读取/数据判断,到kafka消息监听断言整个流程能够完成上述的诉求。
通过一个例子来解读hook函数的作用。在真实的业务场景下,我们在编写自动化cases的时候完全可以用纯代码的方式来实现我的复杂的业务场景。通过这种方式能更有效的认可自动化去替代人工操作。
后话:
个人认为自动化的灵魂不是用什么工具,而是断言。不管是人工还是程序自动操作都需要有一个判断依据,如果这个判断依据十分有效,那么我们只需要完善场景cases就能实现自动化替换人工(百分之80吧)










