MySQL 中 count(*) 和 count(1) 的异同
count() 函数的基本原理
语法:
COUNT(expr)
其中:
expr可以是字段名、常量、表达式或星号 (*)。
用法:
count() 函数用于统计满足特定条件的记录数量。它可以有以下几种用法:
1. 统计所有记录数量:
SELECT COUNT(*) FROM table_name;
2. 统计特定字段不为 NULL 的记录数量:
SELECT COUNT(field_name) FROM table_name;
3. 统计满足条件的记录数量:
SELECT COUNT(*) FROM table_name WHERE condition;
示例:
示例 1:统计表中所有记录数量
mysql> SELECT COUNT(*) FROM customers;
+----------+
| COUNT(*) |
+----------+
| 1000 |
+----------+
示例 2:统计特定字段不为 NULL 的记录数量
mysql> SELECT COUNT(name) FROM customers;
+----------+
| COUNT(name) |
+----------+
| 950 |
+----------+
示例 3:统计满足条件的记录数量
mysql> SELECT COUNT(*) FROM customers WHERE age > 30;
+----------+
| COUNT(*) |
+----------+
| 500 |
+----------+
COUNT(*) vs COUNT(1)
在使用COUNT函数时,我们可以选择使用SELECT COUNT(*)或SELECT COUNT(1)两种方式进行计数。这两种方式在实现上并没有明显的差别,都可以得到相同的结果。然而,它们在语义上略有不同。
- SELECT COUNT(*): 这种方式表示计算表中所有行的数量,包括非空记录和空记录。它会统计表中的所有行,不论其是否为空。
- SELECT COUNT(1): 这种方式表示计算表中每行的行号,也就是在内存中为每一行分配的唯一标识符。与COUNT(*)不同,它只计算非空记录,忽略了空记录。
因此,当表中存在大量空记录时,使用SELECT COUNT(*)会比SELECT COUNT(1)更加耗费资源,因为前者会统计空记录,而后者则会忽略它们。
尽管 count(*) 和 count(1) 在大多数情况下性能相似,但以下情况可能会导致细微的差异:
-
count(字段名): 当指定的字段不是索引的一部分时,其性能可能较差,因为需要检查每条记录中的该字段是否为 NULL。
-
多个二级索引: 如果表有多个二级索引,MySQL 优化器会选择具有最小
key_len的索引进行扫描。 -
主键索引 vs 二级索引: 只有当没有二级索引时,才会使用主键索引进行计数,这可能会略微降低效率。
如何优化 count()?
在面对大表的记录统计时,使用count()函数可能会导致性能问题,特别是当表中包含大量数据时。在这种情况下,我们可以考虑一些优化策略来提高查询效率。
1. 近似值统计
如果业务对于记录数的精确性要求不高,可以使用近似值来加速统计。例如,搜索引擎在显示搜索结果数量时通常使用的是近似值,而不是精确值。在MySQL中,可以使用show table status或explain命令来获取表的估算记录数,因为这些命令执行效率很高,不会真正执行查询操作。
采用select语句查询表中共有 1200+ 万条记录,我也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒!
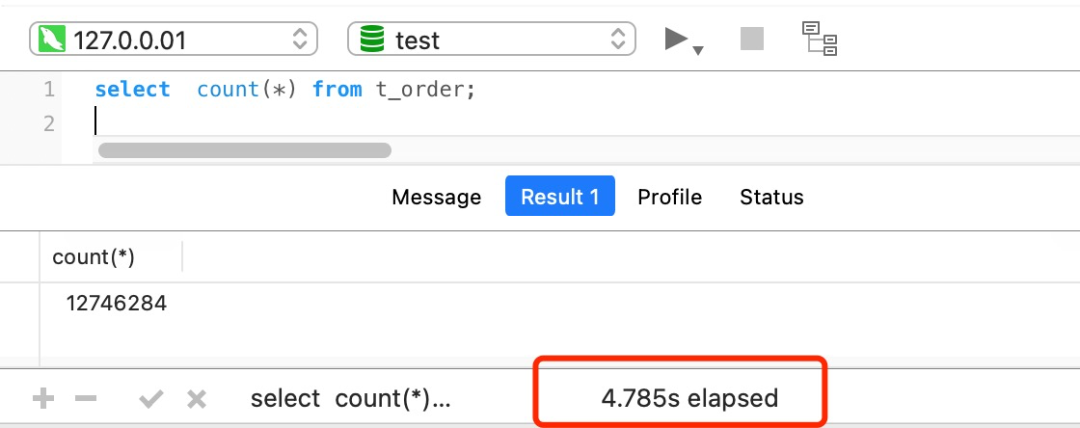
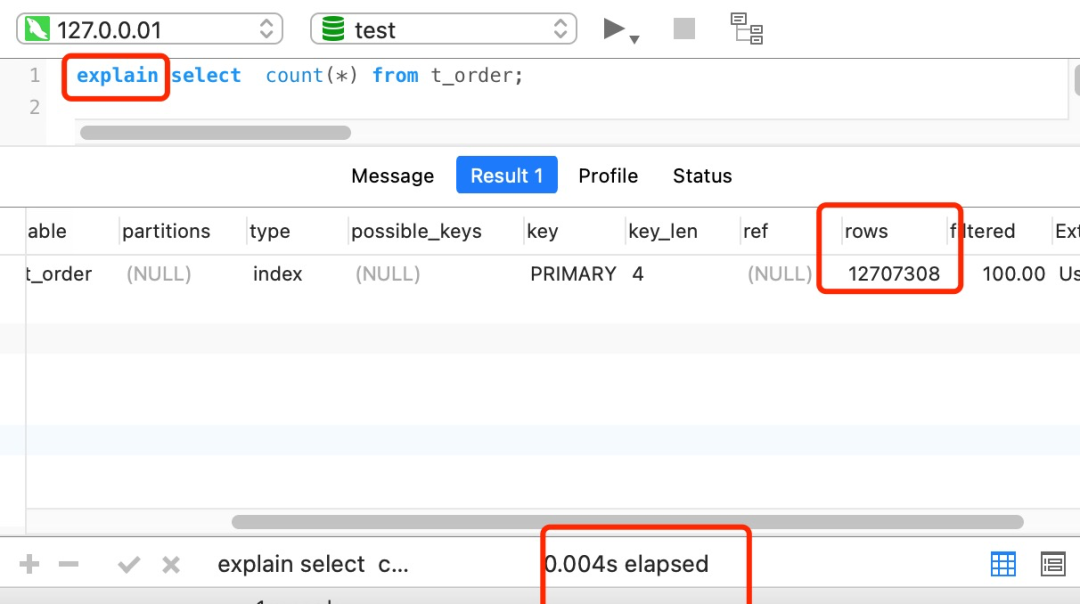
而执行 explain 命令效率是很高的,因为它并不会真正的去查询,大概0.0004s就完成了
2. 额外表保存计数值
对于需要精确获取记录总数的情况,可以考虑将计数值保存到单独的计数表中。每当在数据表中插入或删除记录时,同时更新计数表中的计数字段。这样,在查询记录总数时就不需要执行count()函数,而是直接查询计数表中的值,从而避免了对大表进行全表扫描的开销。
虽然这种方法提高了查询效率,但需要注意额外维护计数表的成本,特别是在新增和删除操作频繁的情况下,需要确保计数表的数据与实际数据表中的数据保持一致。
哪种 count 性能最好?
关于它们的执行效率的说法比较多,结合我自己的实践得出的比较认同的结论是:
在实践中,关于MySQL和Oracle数据库中的count函数,人们对其执行效率有许多不同的说法。通过我的实践和观察,我得出了以下比较认同的结论:
对于 count(*) 和 count(1),在MySQL的官方文档中已明确说明,InnoDB存储引擎对它们的处理方式是一样的,因此它们之间没有区别。
对于Oracle数据库,虽然我没有找到官方的解释,但通过观察它们的执行计划,我认为 count(*) 和 count(1) 的执行计划是一样的。尽管有些人提到它们的效率可能有细微的差异,但在实际应用中很少会出现不带where条件统计全表的情况,因此我认为这个性能差异并不值得过多关注。
最后是 count(列名)。由于 count(列名) 需要多一个判断列是否为空的步骤,所以理所当然地比前两种要慢一些。然而,我发现如果列上有非空约束,那么在Oracle数据库中,count(列名) 和 count(*) 一样,都会使用索引优化。但在MySQL中,如果该列上没有索引,count(列名) 就不会使用索引。










