1 Abstract
- 许多聚类方法基于输入数据的相似性矩阵对数据组进行划分。因此,聚类结果高度依赖于数据相似性学习。由于相似性度量和数据聚类通常是分两步进行的,学习到的数据相似性可能不是数据聚类的最佳选择,从而导致次优结果。在本文中,我们提出了一种新颖的聚类模型,用于同时学习数据相似性矩阵和聚类结构。我们的新模型通过为每个数据点分配基于局部距离的自适应和最优邻居来学习数据相似性矩阵。同时,我们对数据相似性矩阵的拉普拉斯矩阵施加了新的秩约束,使得结果相似性矩阵中的连通分量恰好等于聚类数量。我们推导出一种有效的算法来优化所提出的具有挑战性的问题,并展示了我们的方法与K-均值聚类和谱聚类之间的理论分析联系。我们还进一步扩展了新的聚类模型,用于处理高维数据的投影聚类。在合成数据和真实世界基准数据集上的广泛实验结果表明,我们的新聚类方法一致性地优于相关聚类方法。
2 Object funciton

3 Solving Stratege

4 Performance
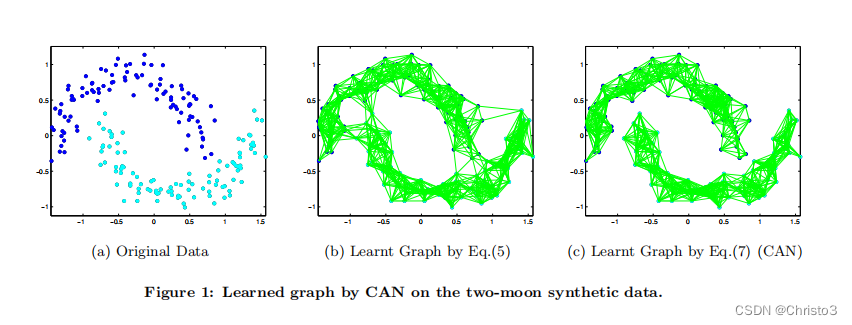
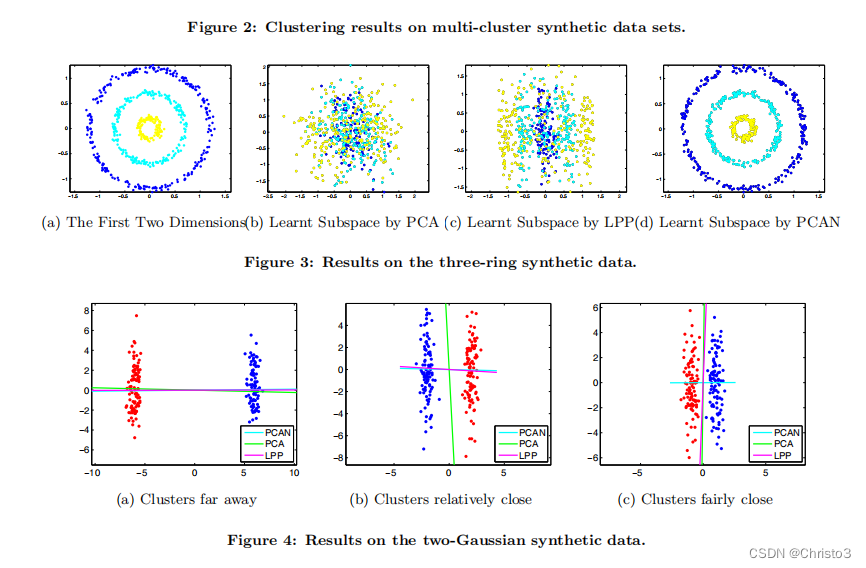
5 Advantages
-
优点:
-
自适应邻居分配:算法通过基于局部距离的自适应邻居分配机制,为每个数据点学习最优的邻居,这有助于更好地捕捉数据的局部结构。
-
同时学习相似性和聚类结构:CAN和PCAN算法不仅学习数据的相似性矩阵,还同时确定聚类结构,这有助于获得更准确的聚类结果。










