目录
1.介绍
本文将介绍如何编写Python爬虫,爬取心食谱网站的一些与药膳相关的食谱信息,当然,通过修改对应食谱的URL,可以爬取其他食谱信息。爬取到的数据可用于数据分析和可视化,适用于学年设计或者毕设的数据来源。
2.分析
(1)数据来源
(2)页面结构
我们主要爬取食谱分类板块下的食谱数据:
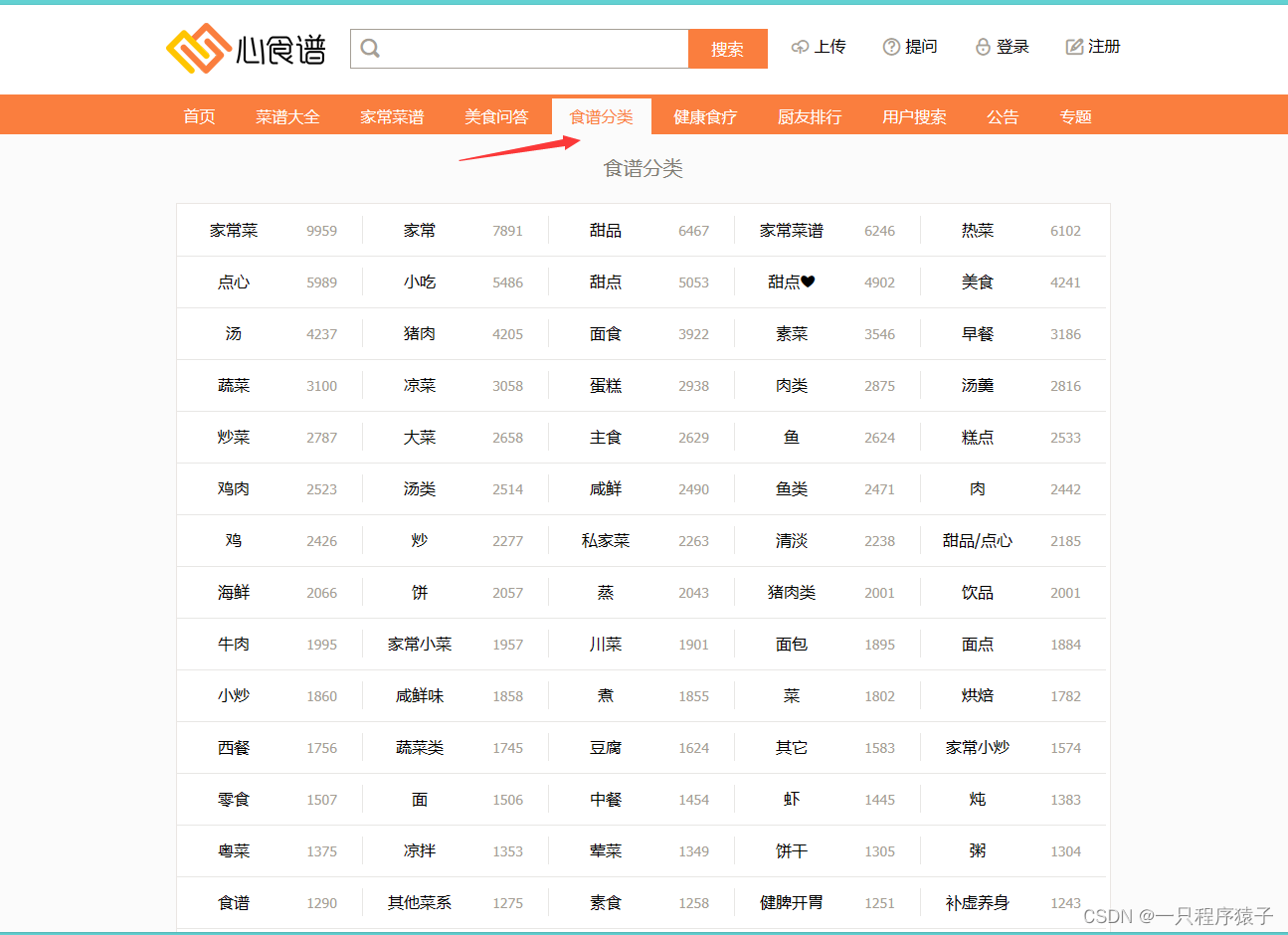
随便点开一个食谱,比如点开第一个家常菜:
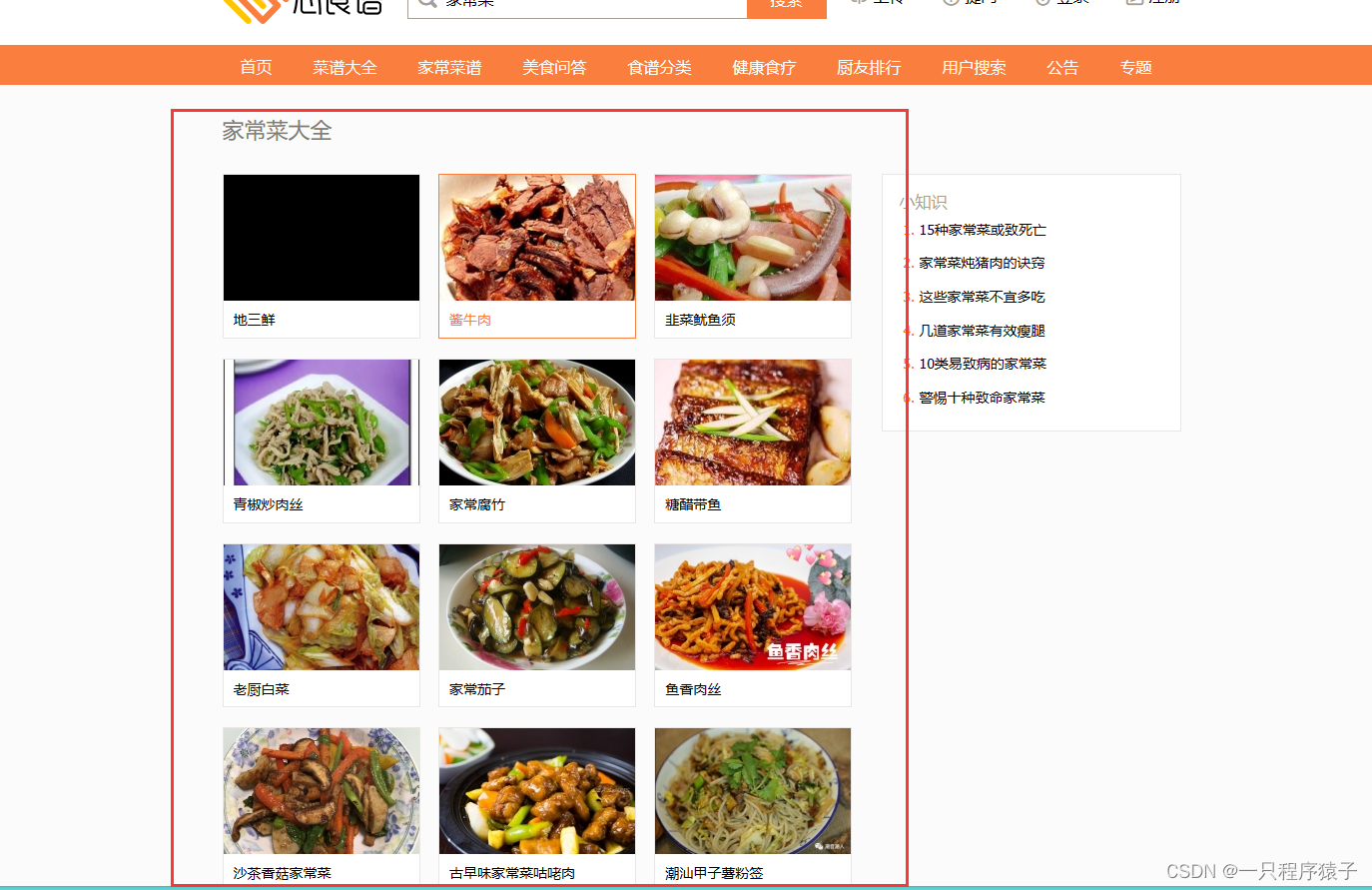
页面底部是换页按钮,需要注意的是:当查看本食谱中的尾页时,页面底部换页按钮并不会出现下一页的按钮了
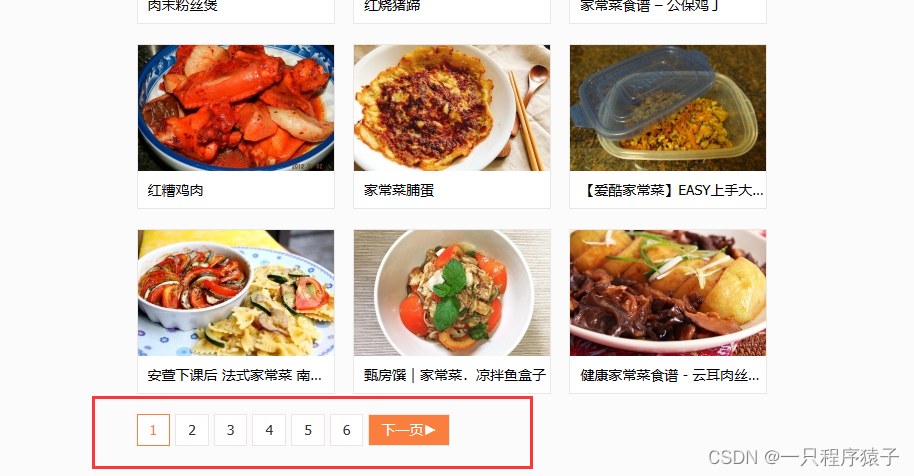

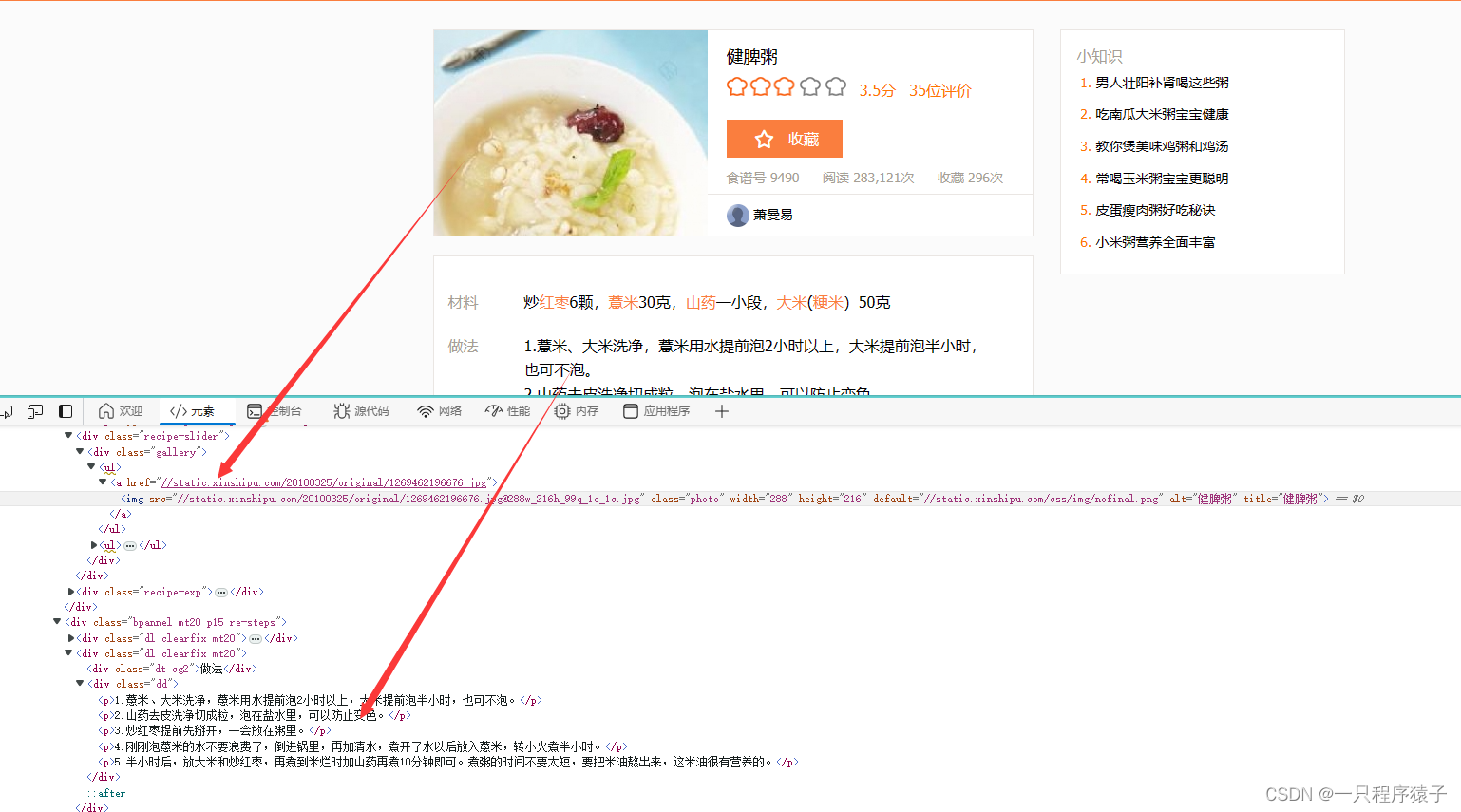
点开其中的一个菜品,可以看到菜品详细信息:

需要注意的是:有些菜品可能会有更多项或更少项介绍:
查看菜谱菜品的URL:

菜谱翻页:
 菜品详细信息:
菜品详细信息:
3.爬取流程
菜谱的URL-->获取菜谱页中所有菜品的URL-->根据菜品的URL获取菜品的详细信息
因为菜谱有多个页面,一页中有多个菜品,所以我们将使用循环遍历菜谱中的所有界面,获取所有菜品url,最后根据菜品url获取菜品的详细信息.
4.源码
import requests
from settings import COOKIES, HEADERS
from lxml import etree
from utils.utils import *
from db_helper import DBHelper
# 获取食谱类型
def get_type(url):
response = requests.get(url, cookies=COOKIES, headers=HEADERS)
html = etree.HTML(response.text)
type = html.xpath('/html/body/div[2]/div/h1/text()')[0]
type = type.strip()
DBHelper().findType(type)
return type
# 获取本菜谱下一页菜单页url
def get_next_page(url):
response = requests.get(url, cookies=COOKIES, headers=HEADERS)
html = etree.HTML(response.text)
next_page_url = html.xpath('//div[@class="page-turn fl"]/a/@href')[-1]
return next_page_url
# 获取本页菜谱内的所有菜品基础信息
def get_menu(url):
response = requests.get(url, cookies=COOKIES, headers=HEADERS)
html = etree.HTML(response.text)
ys_name_list = html.xpath('//div[@class="new-menu mt20"]/div[@class="bpannel cb"]/a/@title') # 药膳名称列表
ys_url_list = html.xpath('//div[@class="new-menu mt20"]/div[@class="bpannel cb"]/a/@href')
ys_img_list = html.xpath('//div[@class="new-menu mt20"]//div[@class="v-pw"]/img/@src')
memu = zip(ys_name_list, ys_url_list, ys_img_list)
return memu
# 获取菜品详细信息
def get_details(url):
response = requests.get(url, cookies=COOKIES, headers=HEADERS)
html = etree.HTML(response.text)
infos = html.xpath('/html/body/div[2]/div/div[1]/div[2]/div')
details = ''
for info in infos[:-1]:
title = ''
content = ''
for i in info.xpath('./div[1]/text()'):
title += i
for i in info.xpath('./div[2]//text()'):
content += i
title = title.replace('\t', '').replace('\n', '')
content = content.replace('\t', '').replace(' ', '').replace('\n\n', '').strip()
# print(title, content)
details += (title + '\n' + content + '\n')
return details
# 获取菜品的封面图片
def get_img(url):
response = requests.get(url, cookies=COOKIES, headers=HEADERS)
img_data = response.content
return img_data
# 主程序
if __name__ == '__main__':
# 每次运行前留一个url不被注释就行
# url = 'https://www.xinshipu.com/caipu/112026/'
# url = 'https://www.xinshipu.com/caipu/114076/' # 健脾开胃
# url = 'https://www.xinshipu.com/caipu/114485/' # 虚补养身
# url = 'https://www.xinshipu.com/caipu/115230/' # 防癌抗癌
# url = 'https://www.xinshipu.com/caipu/114194/' # 清热解毒
# url = 'https://www.xinshipu.com/caipu/115250/' # 壮腰健肾
# url = 'https://www.xinshipu.com/caipu/115222/' # 益智补脑
# url = 'https://www.xinshipu.com/caipu/114677/' # 营养滋补
# url = 'https://www.xinshipu.com/caipu/115222/' # 美容养颜
# url = 'https://www.xinshipu.com/caipu/114185/' # 润肺止咳
# url = 'https://www.xinshipu.com/caipu/115222/' # 美容养颜
url = 'https://www.xinshipu.com/caipu/114686/' # 补气补血
type = get_type(url)
type = get_type(url)
print(type)
all_page_list = [url]
while 1:
# 定义详细信息
# 1.获取本页菜单所有菜品基础信息
menu = get_menu(url)
for item in menu:
# print(item)
cname = item[0] # 菜品名称
detail_url = 'https://www.xinshipu.com' + item[1] #菜品详情URL
# 获取菜品详细信息
details = get_details(detail_url)
# print(details)
img_url = 'https:' + item[2] # 菜品的封面图片URL
# 获取菜品的封面图片
img_content = get_img(img_url)
# 保存封面图片到本地
img_name = getTimeStamp() + '.jpg'
# saveImge(img_content, img_name)
create_time = getCurrentTime()
shipu = dict()
shipu['type'] = type
shipu['cname'] = cname
shipu['img_name'] = img_name
shipu['details'] = details
shipu['create_time'] = create_time
print(shipu)
DBHelper().saveItem(img_content, img_name, shipu)
time.sleep(1)
# 获取下一页菜单url
next_page_url = 'https://www.xinshipu.com' + get_next_page(url)
if next_page_url not in all_page_list:
url = next_page_url
all_page_list.append(url)
else:
print('该菜谱所有页面的url已获取完毕')
break篇幅有限,这里仅展示了最核心的源码,涉及到的基础变量配置,数据库操作,工具类的源码这里不做展示 ,如果需要完整源码的话可以通过文章底部个人名片联系我.
5.效果展示

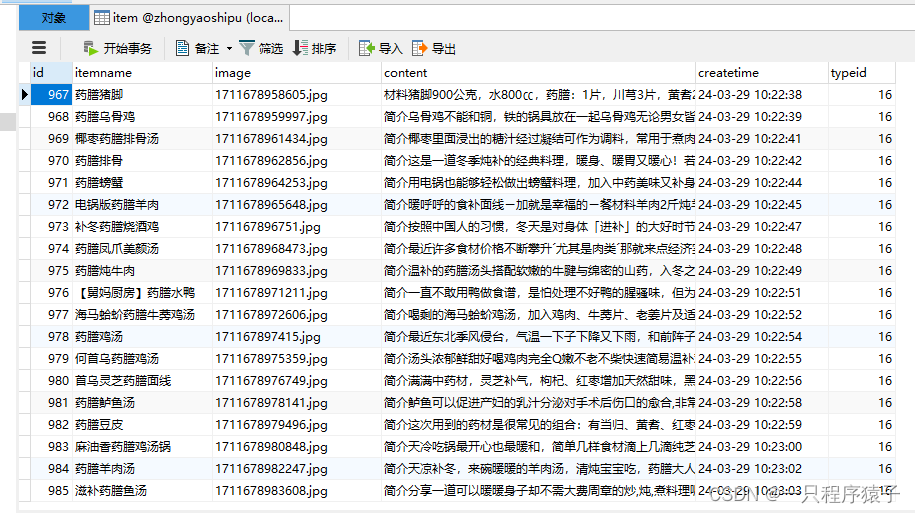
6.拓展
当我们获取了这些数据之后,可以做一个推荐系统之类的项目用作毕设或者参加比赛啥的,如下是我做的一个基于Django的药膳食谱推荐系统,使用的是基于用户的协同过滤推荐算法。

 如果有需要可以联系我哦!
如果有需要可以联系我哦!










