文章目录
一、前言
- 我们在浏览一些网站时,有不少内容是通过 JavaScript动态渲染的,或是 AJAX 请求后端加载数据,这其中涉及到了不少加密参数如 token,sign,难以找规律,较为复杂。像前面的百度贴吧的一个评论的回复,百度翻译等,都是经过ajax动态 加载得到。
- 为了解决这些问题,我们可以直接模拟浏览器运行,然后爬取数据,这样就可以实现在浏览器中看到内容是怎么样了,不用去分析 JS 的算法,也不用去管 ajax 的接口参数了。
- python 提供了多种模拟器运行库,Selenium、Splash、Pyppetter、Playwright 等,可以方便帮我们爬取,很大程度上可以绕过JavaScript动态渲染,获取数据。
二、selenium的介绍
1、优点:
Selenium 是一个自动化测试工具,历史悠久,功能强大,技术成熟。其优点是能直接在浏览器上操作,利用它可以像人一样完成,输入文本框内容,点击,下拉等操作,它不但能做自动化测试,在爬虫领域也是一把利器,能解决大部分网页反爬问题,Selenium可以根据驱动的代码指令来获取网页内容,甚至是验证码的截屏,或判断网站上的某些动作是否发生。我们这边主要是围绕着爬虫展开。
2、缺点:
1、Selenium 运行比较慢,它需要等待浏览器的元素加载完毕,所以耗时。
2、驱动的适配,浏览器版本不同,浏览器类型不同,得使用不同的驱动器。
3、像一些安全性比较高,比较大型的网站是能检测出是否使用了Selenium来爬取网站
三、selenium环境搭建
1、安装python模块
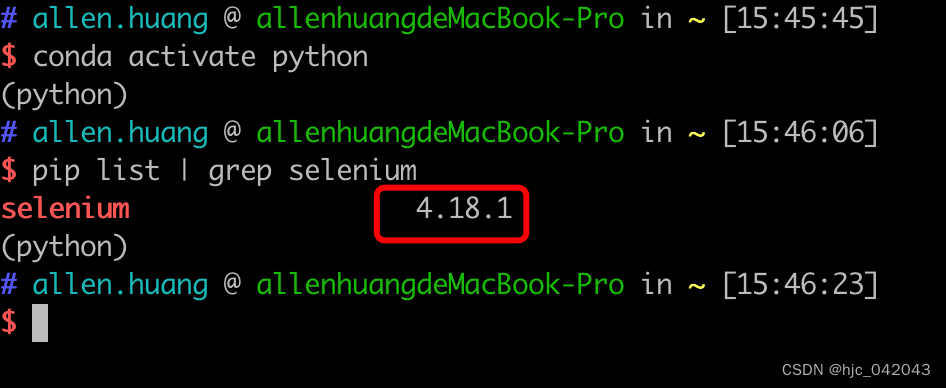
pip install selenium
这里是测试演示用,安装完成后是最新的版本, selenium4,如果是正式使用建议还是使用稳定版本
2、selenium4新特性
- executable_path已弃用,使用Service 对象来代替
- Selenium 4 可以自动回收浏览器资源,不需要手动quit()了,像4之前不停止服务会有残留进程,占用内存
- 定位语法方面,Selenium 4引入了新的定位方法,使用By类来替代之前的find_element_by系列方法;
- 放弃了无头浏览器PhantomJS,目前的 chrome,firefox 都是支持无头浏览器
我在这里测试的,也是以4为主,具体看这篇文章
3、安装驱动WebDriver
驱动选择
- Chrome浏览器驱动下载地址:
淘宝镜像:https://npmmirror.com/package/chromedriver/versions
google官网:https://googlechromelabs.github.io/chrome-for-testing/#stable
-
Firefox浏览器驱动下载地址:
https://github.com/mozilla/geckodriver/releases/ -
Edge浏览器驱动下载地址:
这是windows下的浏览器
https://developer.microsoft.com/en-us/microsoftedge/tools/webdriver/#downloads -
无头浏览器
PhantomJs安装教程(无界面浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效),它一般是用在像linux线上服务器,不过现在 chrome(v65以上) 也支持无头浏览器了。 -
注意: 下载安装步骤如下:需要下对应浏览器版本的驱动
查看 chrome的版本是最新版本123,所以下载对应的驱动

-
下载对应的版本:
macos 分为 intel 还是arm 的,我因电脑是 intel,所以选择时也要选mac64
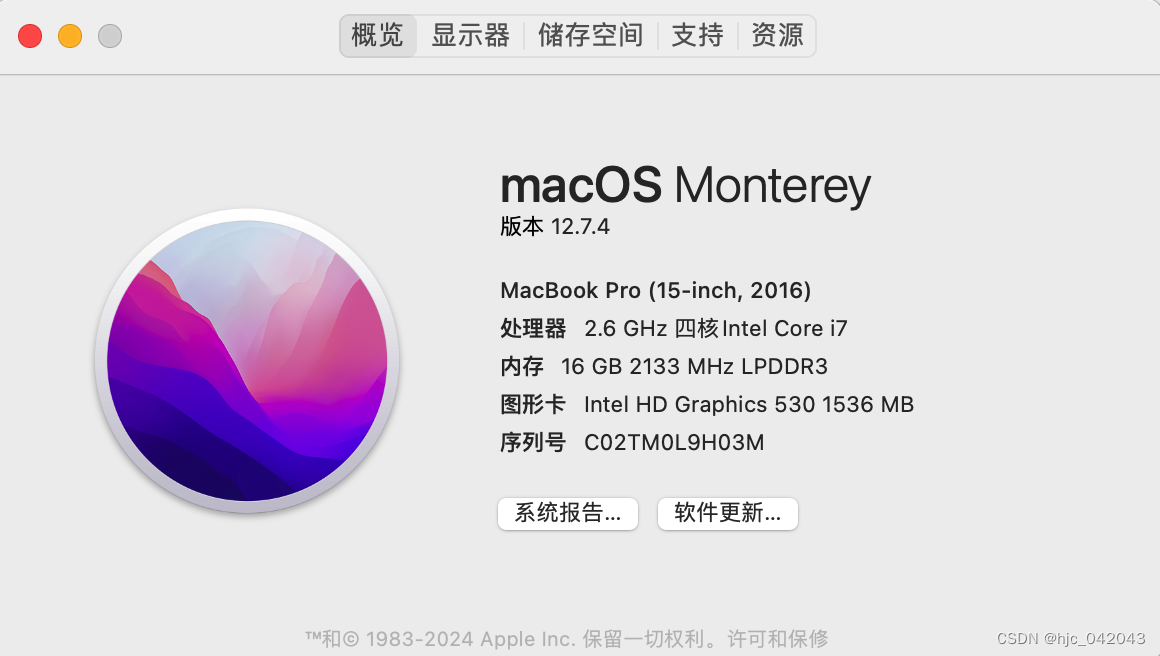
浏览器对应的驱动版本

驱动安装和测试
mv Downloads/chromedriver-mac-x64/chromedriver /usr/local/bin/
- 测试
def setUp(self) -> None:
"""
@todo: 设置驱动的路径,主要是为了加快selenium的启动速度,不用再去搜索驱动的路径
@return:
"""
self.service = ChromService(executable_path="/usr/local/bin/chromedriver")
pass
def test_chrome_driver(self):
"""
@todo: selenium测试chrome的浏览器
@return:
"""
# 设置驱动的路径,这是 selenium4之后的新写法
# 实例化浏览器对象
browser = webdriver.Chrome(service=self.service)
# 发送请求访问百度
browser.get('https://www.baidu.com')
# 获取页面标题
print("当前页面标题:", browser.title)
time.sleep(10)
# 退出浏览器
browser.quit()
pass
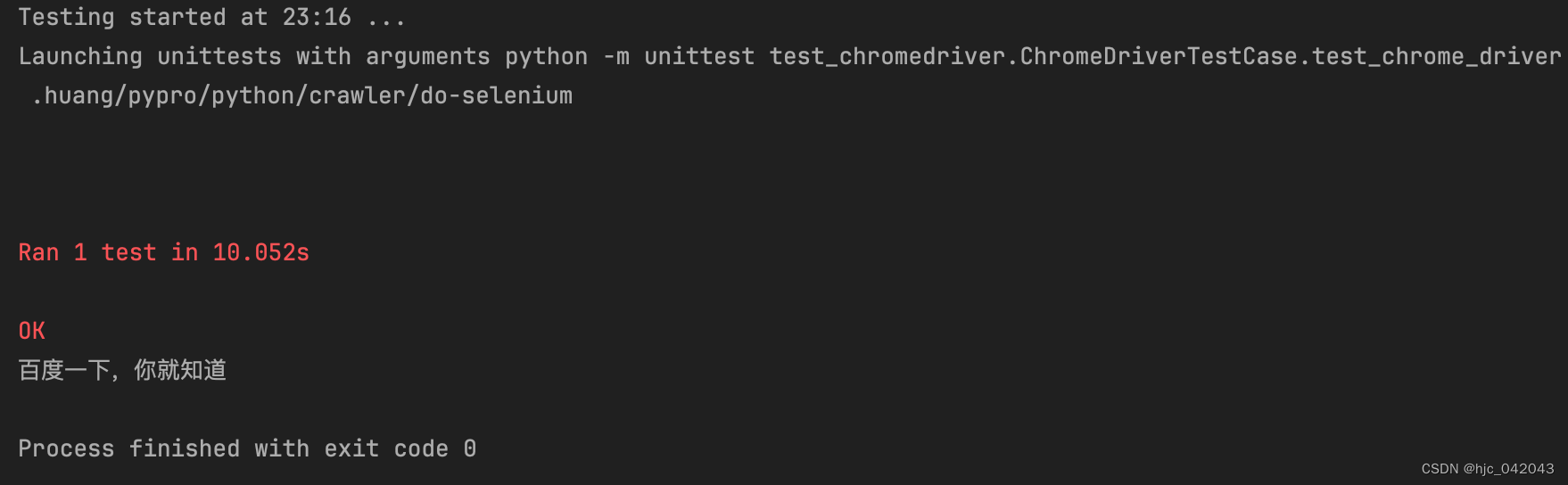
其流程是:
①、开启了一个 新的chrome 窗口,并打开 baidu 网站
②、输出 title 标题
③、关闭浏览器,注意,在 selenium4之前最后一定要手动退出,不然会有残留进程,之后是不用写,自动关闭
基础操作
1、属性和方法
- 常用属性说明:
- 方法说明:
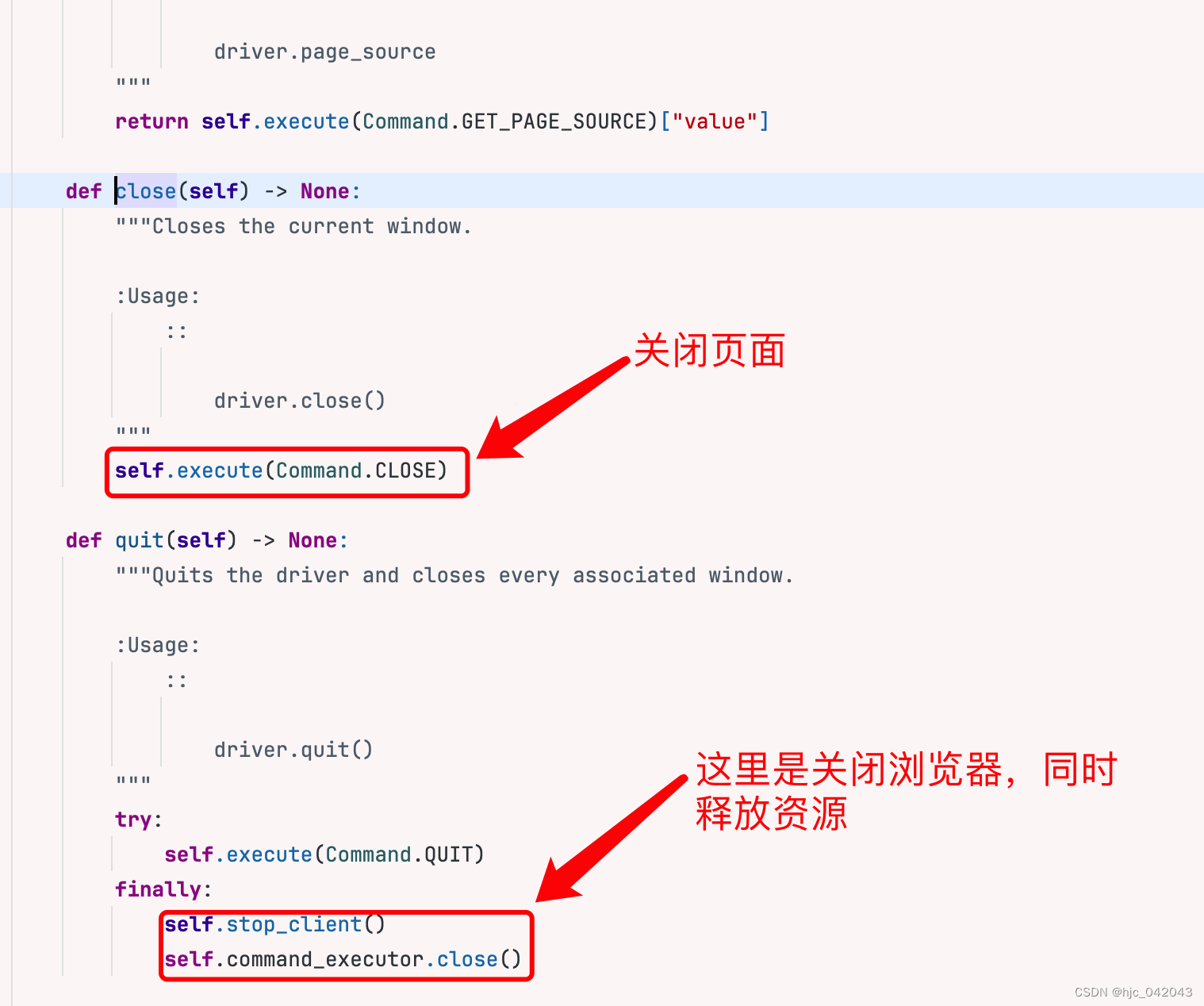
cloase()和quit()的区别:
从 selenium4的源码中比较可以看出来
代码展示:
def test_attr_method(self):
"""
@todo: 测试浏览器的属性和方法
@return:
"""
# 实例化浏览器对象
driver = webdriver.Chrome(service=self.service)
# 获取浏览器的名称
print(driver.name)
# 访问百度首页,这里先暂时不使用https
driver.get('http://www.baidu.com')
# 属性1:打印当前响应对应的URL,之前 http的转换成了 https
print(driver.current_url)
# 属性2:打印当前标签页的标题
print(driver.title)
# 属性3:打印当前网页的源码长度
print(len(driver.page_source))
# 休息2秒,跳转到豆瓣首页,这里的两秒是等当前页面加载完毕,也就是浏览器转完圈的两秒
time.sleep(2)
driver.get('https://www.douban.com')
# 休息2秒,再返回百度
time.sleep(2)
driver.back()
# 休息2秒,再前进到豆瓣
time.sleep(2)
driver.forward()
# 休息2秒,再刷新页面
time.sleep(2)
driver.refresh()
# 保存当前页面的截屏快照
driver.save_screenshot("./screenshot.png")
# 关闭当前标签页
driver.close()
# 关闭浏览器,释放进程
driver.quit()
pass
2、单个元素定位
通过id定位
-
语法格式:
find_element(by=By.ID, value='标签的id属性名) -
测试代码
def test_element_id(self):
"""
@todo: 通过id定位元素,测试输入框的输入和点击
@return:
"""
# 实例化浏览器对象
browser = webdriver.Chrome(service=self.service)
# 打开百度首页
browser.get('https://www.baidu.com')
# 输入关键字内容sora,并赋值给 标签的id属性名来定位;这是新的写法,
browser.find_element(by=By.ID, value='kw').send_keys('sora')
# 点击搜索按钮
browser.find_element(by=By.ID, value='su').click()
# 获取搜索结果
# 关闭浏览器
time.sleep(5)
browser.quit()
pass
通过class_name定位一个元素
-
语法格式:
find_element(by=By.CLASS_NAME, value='标签的class属性名来定位') -
测试代码:
def test_element_class_name(self):
"""
@todo: 通过class_name定位元素,测试输入框的输入和点击
@return:
"""
browser = webdriver.Chrome(service=self.service)
browser.get('https://www.baidu.com')
# 使用class_name定位输入框,并把输入框的内容设置为sora
browser.find_element(by=By.CLASS_NAME, value='s_ipt').send_keys('sora')
browser.find_element(by=By.CLASS_NAME, value='s_btn').click()
time.sleep(2)
browser.quit()
pass
通过xpath定位
- 语法格式:
find_element(by=By.XPATH, value='xpath的表达式') - 测试代码
def test_element_xpath(self):
"""
@todo: 通过xpath定位元素,测试输入框的输入和点击
@return:
"""
# 实例化浏览器对象
browser = webdriver.Chrome(service=self.service)
browser.get('https://www.baidu.com')
# 使用xpath定位输入框,并把输入框的内容设置为sora
browser.find_element(by=By.XPATH, value='//*[@id="kw"]').send_keys('sora')
# 点击搜索按钮
browser.find_element(by=By.XPATH, value='//*[@id="su"]').click()
# 关闭浏览器
time.sleep(5)
browser.quit()
pass
通过CSS 选择器定位
- 语法格式:
browser.find_element(by=By.CSS_SELECTOR, value="选择器表达式") - 测试代码:
def test_element_css_selector(self):
"""
@todo: 通过css选择器定位元素,测试输入框的输入和点击
@return:
"""
# 实例化浏览器对象,打开百度首页
browser = webdriver.Chrome(service=self.service)
browser.get('https://www.baidu.com')
# 使用css选择器定位输入框,先进行清空文本框,并把输入框的内容设置为sora
browser.find_element(by=By.CSS_SELECTOR, value="#kw").clear()
browser.find_element(by=By.CSS_SELECTOR, value="#kw").send_keys('sora')
browser.find_element(by=By.CSS_SELECTOR, value="#su").click()
# 关闭浏览器
time.sleep(2)
browser.quit()
pass
3、多个元素定位
通过xpath定位排行榜的基金代码
-
语法格式:
格式上和单个获取的差不多,唯一有差别的是方法后面多了一个s,使用了find_elements -
测试代码:
def test_elements_xpath(self):
"""
@todo: 通过xpath定位元素列表,测试获取列表的数据
@return:
"""
browser = webdriver.Chrome(service=self.service)
browser.get('https://fund.eastmoney.com/data/fundranking.html#tall')
# 使用xpath定位列表
elements = browser.find_elements(by=By.XPATH, value='//table[@id="dbtable"]/tbody/tr/td[3]/a')
for elem in elements:
print(elem.text)
# 页面加载完后,再等待2秒,自动关闭浏览器,这里没有使用quit()方法,也能自动释放
time.sleep(2)
browser.quit()
pass
打印结果:
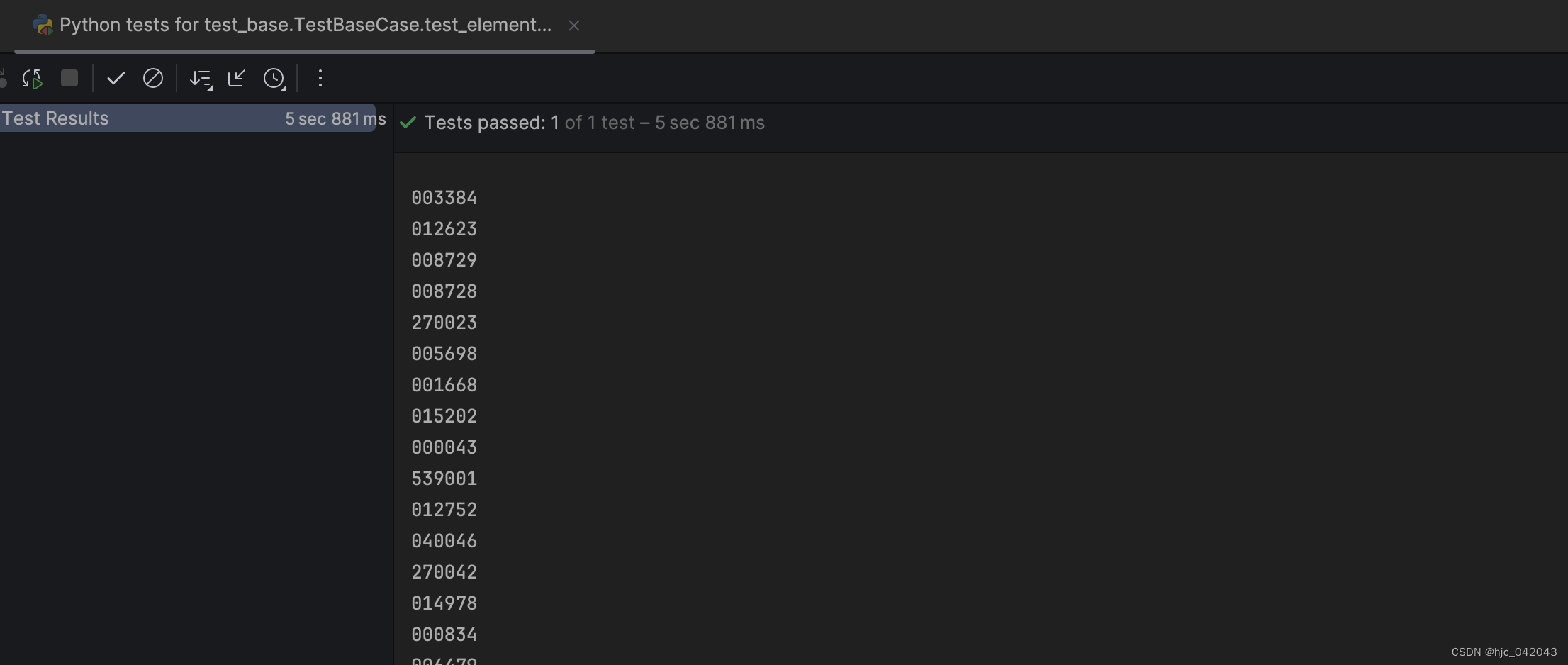
取数据单个和多个的区别
- find_element:
- find_elements:
4、元素操作
获取元素的文本内容和属性值
- 文本内容:
元素对象.text - 属性值:
元素对象.get_attribute(‘属性名’) - 测试用例:
def test_op_element(self):
"""
测试获取元素的文本内容
@return:
"""
# 实例化浏览器对象
browser = webdriver.Chrome(service=self.service)
# 天天基金网,查看所有基金,这只是测试,不作为正式的爬虫
browser.get('https://fund.eastmoney.com/data/fundranking.html#tall')
# 使用xpath定位元素列表,基金代码
elems = browser.find_elements(by=By.XPATH, value='//table[@id="dbtable"]/tbody/tr/td[3]/a')
for elem in elems:
# 代码的内容
print(elem.text)
# 获取基金的链接
print(elem.get_attribute('href'))
time.sleep(2)
browser.quit()
pass
文本框输入内容和点击按钮
- 示例:
def test_element_css_selector(self):
"""
@todo: 通过css选择器定位元素,测试输入框的输入和点击
@return:
"""
# 实例化浏览器对象,打开百度首页
browser = webdriver.Chrome(service=self.service)
browser.get('https://www.baidu.com')
# 使用css选择器定位输入框,先进行清空文本框,并把输入框的内容设置为sora
browser.find_element(by=By.CSS_SELECTOR, value="#kw").clear()
browser.find_element(by=By.CSS_SELECTOR, value="#kw").send_keys('sora')
browser.find_element(by=By.CSS_SELECTOR, value="#su").click()
# 关闭浏览器
time.sleep(2)
browser.quit()
pass
5、无头浏览器模式
基于chrome 的无头浏览器
如下代码展示
def test_headless_driver(self):
"""
@todo: 测试chrome无头模式浏览器
@return:
"""
# 1.实例化配置对象
chrome_options = webdriver.ChromeOptions()
# 2.配置对象开启无头模式
chrome_options.add_argument('--headless')
# 3.配置对象添加无显卡模式,即无图形界面
chrome_options.add_argument('--disable-gpu')
# 4.实例化浏览器对象
browser = webdriver.Chrome(service=self.service, options=chrome_options)
browser.get('https://www.baidu.com')
# 查看当前页面url
print(browser.current_url)
# 获取页面标题
print("页面标题:", browser.title)
# 获取渲染后的页面源码
print("页面源码-长度:", len(browser.page_source))
# 获取页面cookie
print("cookie-data", browser.get_cookies())
# 关闭页面的标签页
browser.close()
time.sleep(5)
# 关闭浏览器
browser.quit()
pass
基于PhantomJS的无头模式(selenium2系列用的多)
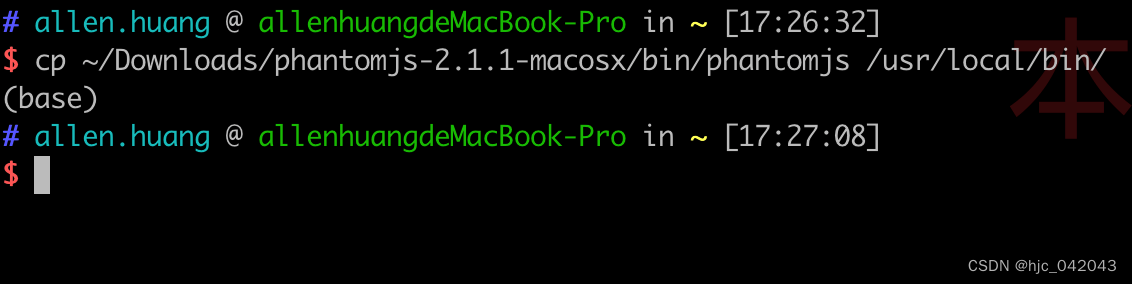
- 下载安装
下载地址:https://phantomjs.org/download.html
选择对应的操作系统即可,我这里是 mac os的

解压出来后,将 bin 目录的phantomjs拷贝到环境变量目录/usr/local/bin 目录下就行
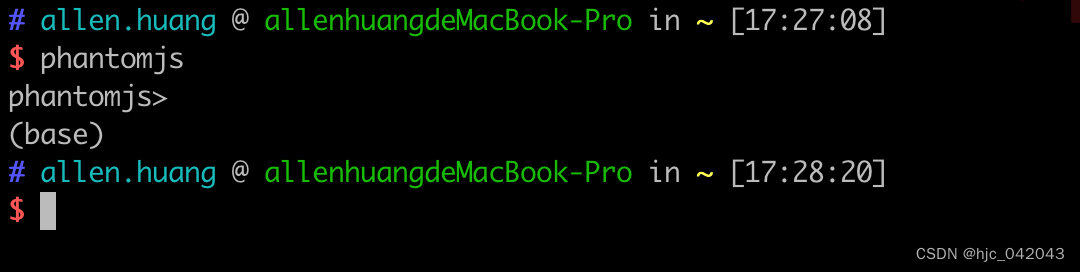
- 验证
出现这个表示安装成功了
代码写法都差不多的
def test_phantjs_driver(self):
driver = webdriver.PhantomJS()
driver.get('https://www.baidu.com')
print(driver.title)
driver.quit()
pass
进阶操作
1、切换标签页
句柄的数据结构:
这是一个列表结构,用来存放所有页面的句柄信息,每打开一个标签的网址,就会存一个,在切换到别的页面时,就去定位对应的索引
driver.window_handles
句柄使用:
就是去指定句柄列表中,具体的句柄值,来切换某个页面的资源,索引 index表示具体哪个页面
driver.switch_to.window(driver.window_handles[index])
在不切换句柄的效果
...
driver.get("https://hz.58.com/")
# todo 获取当前所有的标签页的句柄构成的列表,这不能提前申明变量,因为句柄相当于是指针,这是动态变化的
# current_windows = driver.window_handles
# 获取当前页
print(driver.current_url)
print(driver.window_handles)
# 点击整租的链接,打开租房页面
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[2]/a").click()
# todo 根据标签页句柄,将句柄切换到最新新打开的标签页,这一定要有,不然句柄不会变化,那么下一页内容取不到
# driver.switch_to.window(driver.window_handles[-1])
print(driver.current_url)
print(driver.window_handles)
elem_list = driver.find_elements(by=By.XPATH, value="/html/body/div[6]/div[2]/ul/li/div[2]/h2/a")
# 统计租房列表的个数
print(len(elem_list))
...
这个时候发现,页面并没有跳转
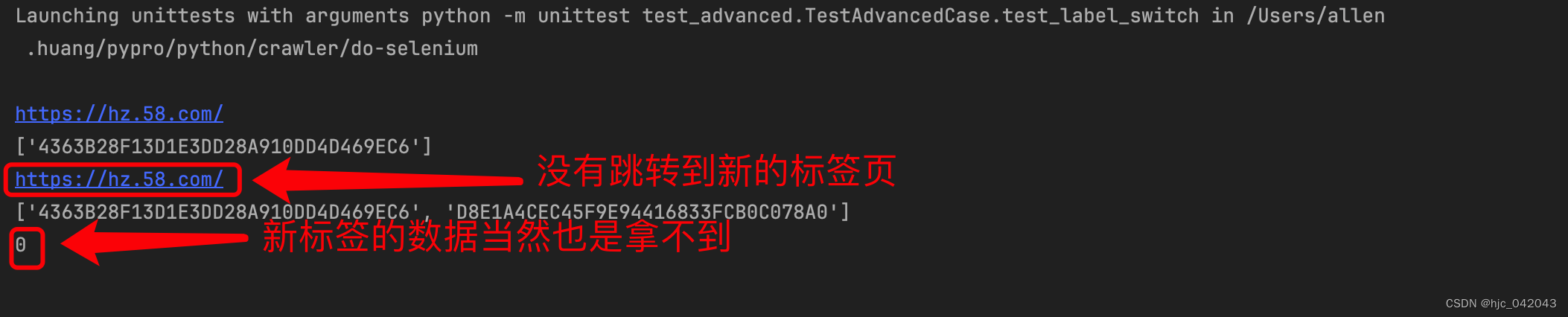
切换句柄后的效果:
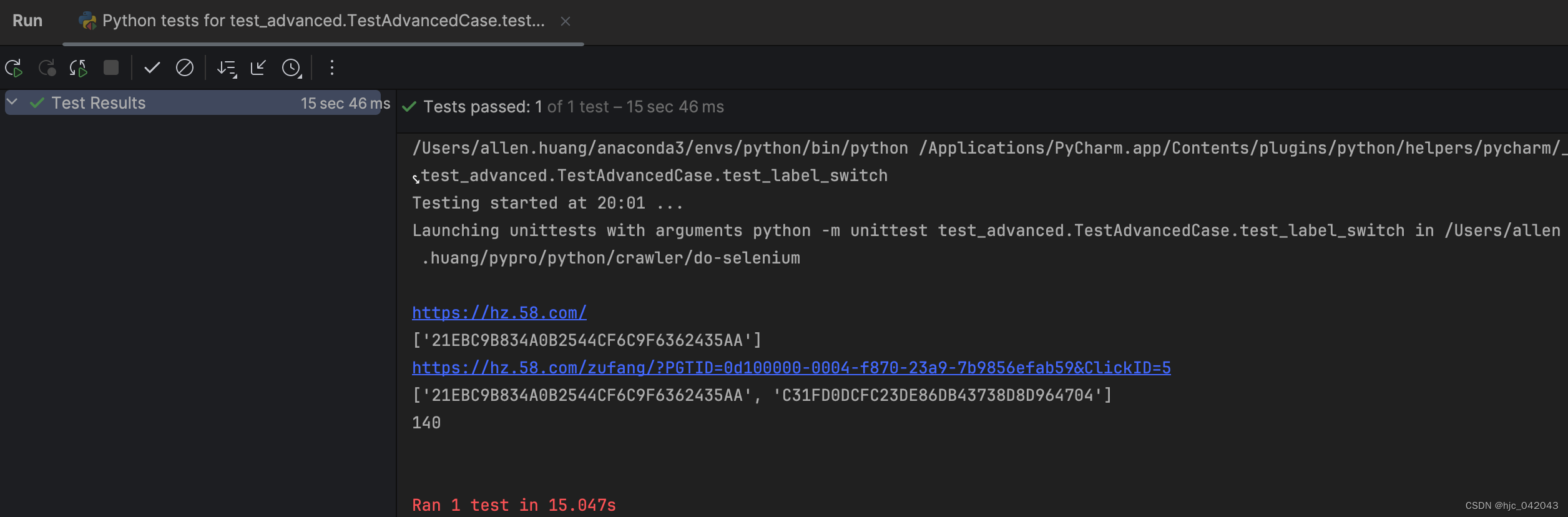
注意: 句柄列表,这不能提前申明为变量,因为句柄随着新便签页的打开,这是动态变化的current_windows = driver.window_handles不能这么赋值。
2. iframe窗口的切入

不使用switch_to.frame方法测试
- 测试代码
根据账号,密码的元素属性id 进行定位
def test_no_switchto_frame(self):
# 声明浏览器驱动实例
driver = webdriver.Chrome(service=self.service)
# 打开 qzone 登录页
driver.get("https://qzone.qq.com/")
# 默认进来是采用扫码,我们这里需要切换成账号密码登录
driver.find_element(by=By.ID, value="switcher_plogin").click()
# 填写账号
driver.find_element(by=By.ID, value="u").send_keys("531881823.qq.com")
# 并不是真实的密码
driver.find_element(by=By.ID, value="p").send_keys("123456")
# 点击登录按钮
driver.find_element(by=By.XPATH, value='//*[@id="login_button"]').click()
time.sleep(5)
driver.quit()
pass
- 执行结果
报错的意思是,未能定位id='u’的元素

学习 switch_to.frame的语法
- 语法格式:
switch_to.frame(frame_element)
frame_element表示可以传入的元素属性值,用来定位 frame ,可以传入i属性d、name、index 以及selenium 的 WebElement 对象,假设有来自某网站的 a.com/index.html,如下 HTML 代码:
<html lang="en">
<head>
<title>iframetest</title>
</head>
<body>
<iframe src="a.html" id="fid" name="fname">
...
<div id="test-a">
<a href="test.com" class="test-a">打开页面</a>
</div>
...
</iframe>
</body>
</html>
可以如下定位:
from selenium import webdriver
# 打开Chrome浏览器
driver = webdriver.Chrome()
# 浏览器访问地址
driver.get("https://a.com/index.html")
# 1.用id来定位
driver.switch_to.frame("fid")
# 2.用name来定位
driver.switch_to.frame("fname")
# 3.用frame的index来定位,第一个是0
driver.switch_to.frame(0)
# 4.用WebElement对象来定位
driver.switch_to.frame(driver.find_element(by=By.XPATH,value='//*[@id="fid"]')
通常采用 id 和 name 就能够解决绝大多数问题。但有时候iframe并无这两项属性,则可以用 index 和 WebElement 来定位:
- index 从 0 开始,传入整型参数即判定为用 index 定位,传入 str 参数则判定为用 id/name 定位
- WebElement 对象,即用 find_element 系列方法所取得的对象,我们可以用 css、xpath 等来定位 iframe 对象
最后使用switch_to.frame 方法测试
def test_switchto_frame(self):
driver = webdriver.Chrome(service=self.service)
driver.get("https://qzone.qq.com/")
# 切入iframe
driver.switch_to.frame("login_frame")
driver.find_element(by=By.ID, value="switcher_plogin").click()
driver.find_element(by=By.ID, value="u").send_keys("531881823.qq.com")
driver.find_element(by=By.ID, value="p").send_keys("123456")
driver.find_element(by=By.XPATH, value='//*[@id="login_button"]').click()
time.sleep(5)
driver.quit()
pass
从iframe中切出
从 iframe 中切出的方法:switch_to.default_content()
driver.switch_to.default_content()
3. 使用 cookie
看如下代码:就是来展示 cookie的测试
def test_cookie(self):
"""
获取cookie
@return:
"""
driver = webdriver.Chrome(service=self.service)
driver.get("https://baidu.com/")
# 获取cookie的值
cookie_info = {data["name"]: data["value"] for data in driver.get_cookies()}
pprint(cookie_info)
time.sleep(2)
driver.quit()
pass
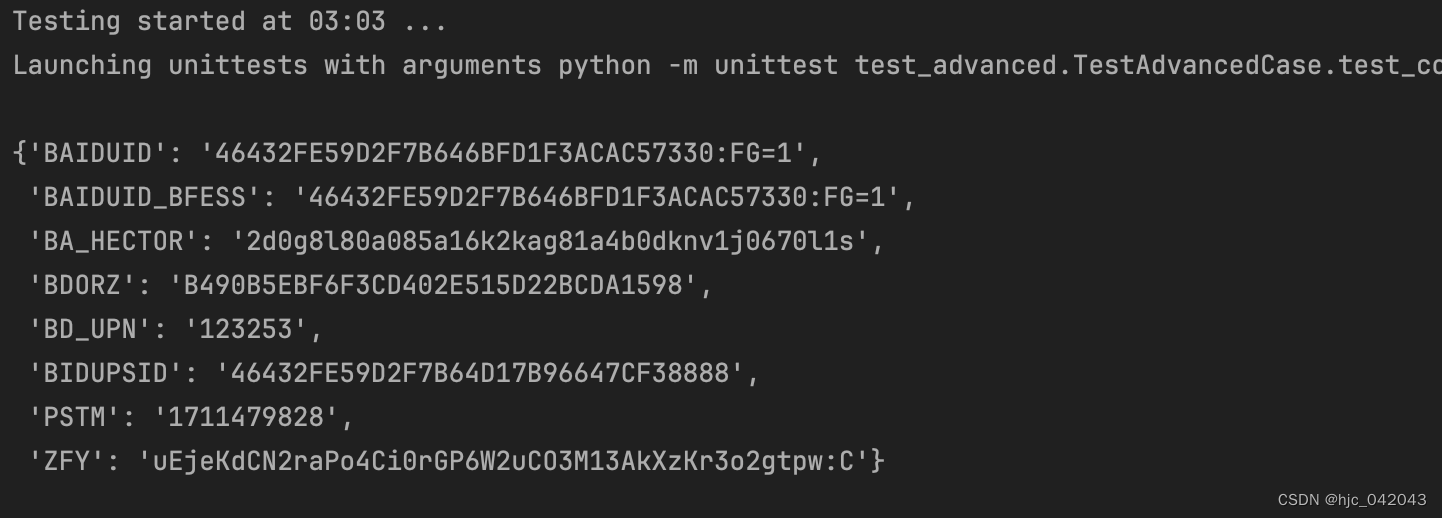
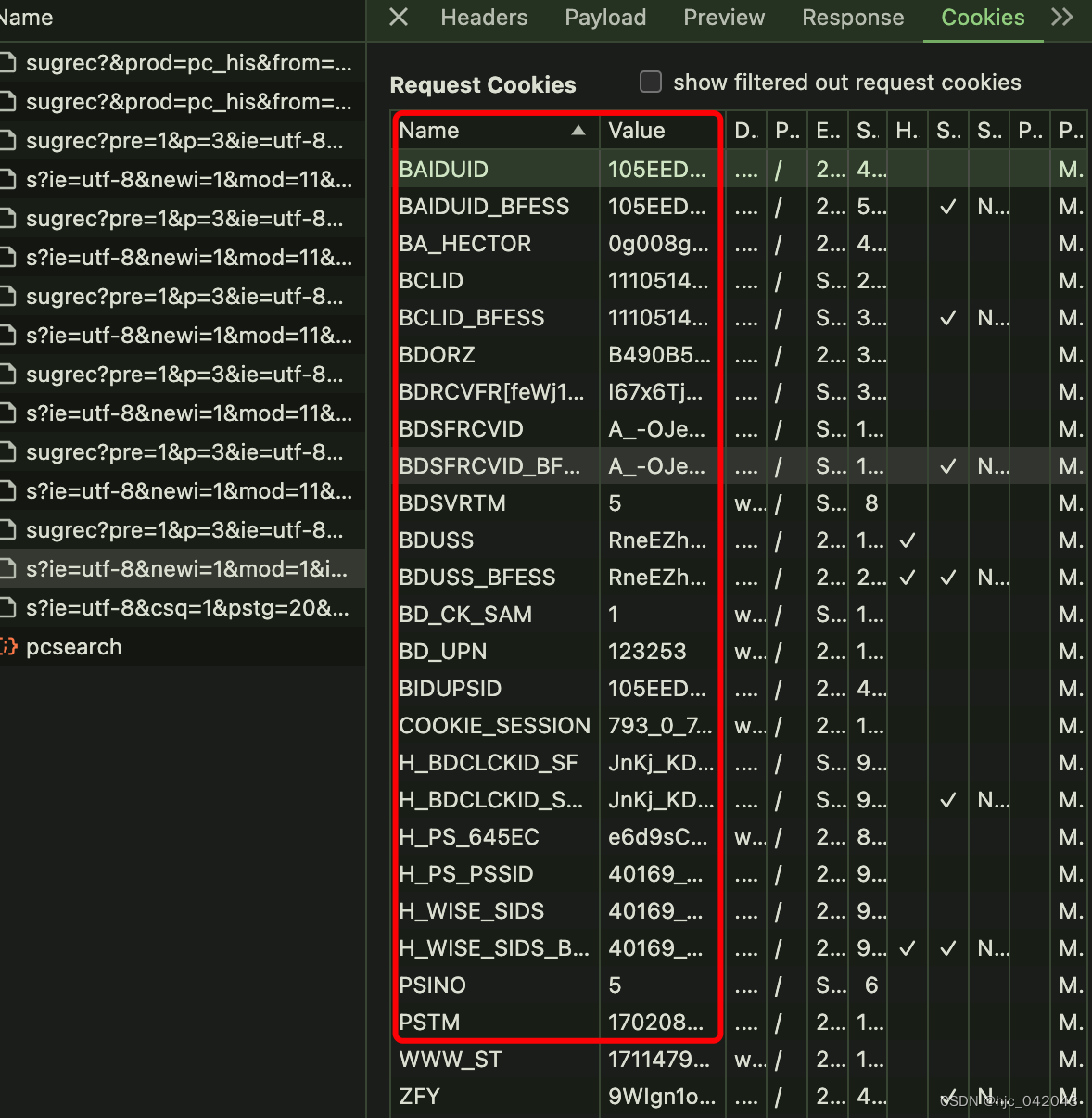
最后打印出的 key,value 对应的值就是在浏览器中的 cookie结构图,如下图所示:
4. 执行JS
- 语法格式:
driver.execute_script(js)
- 代码例子1:
打开一个新窗口
def test_js(self):
"""
执行js,打开一个新窗口,跳转到二手房页面
@return:
"""
# 打开浏览器,进到链家首页
driver = webdriver.Chrome(service=self.service)
driver.get("https://hz.lianjia.com/")
# 我想重开一个窗口查看所有的二手房页面
js = "window.open('https://hz.lianjia.com/ershoufang/');"
# 执行js代码
driver.execute_script(js)
time.sleep(5)
driver.quit()
pass
- 代码例子2
滚动到下面去,打开新的页面
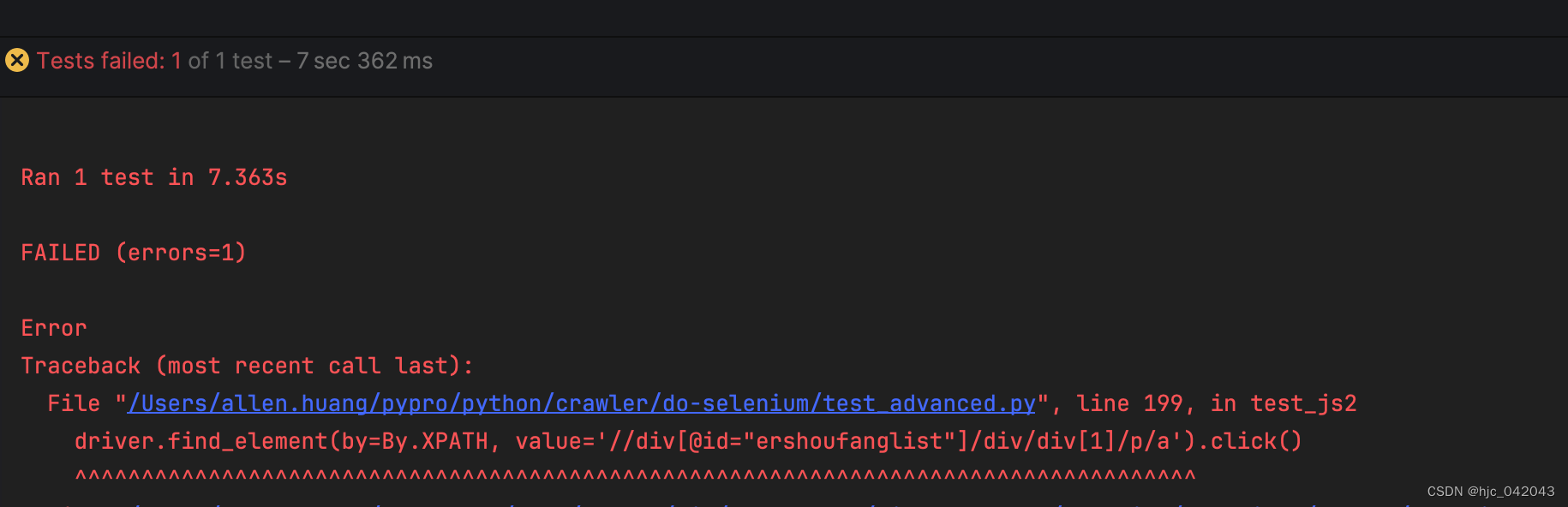
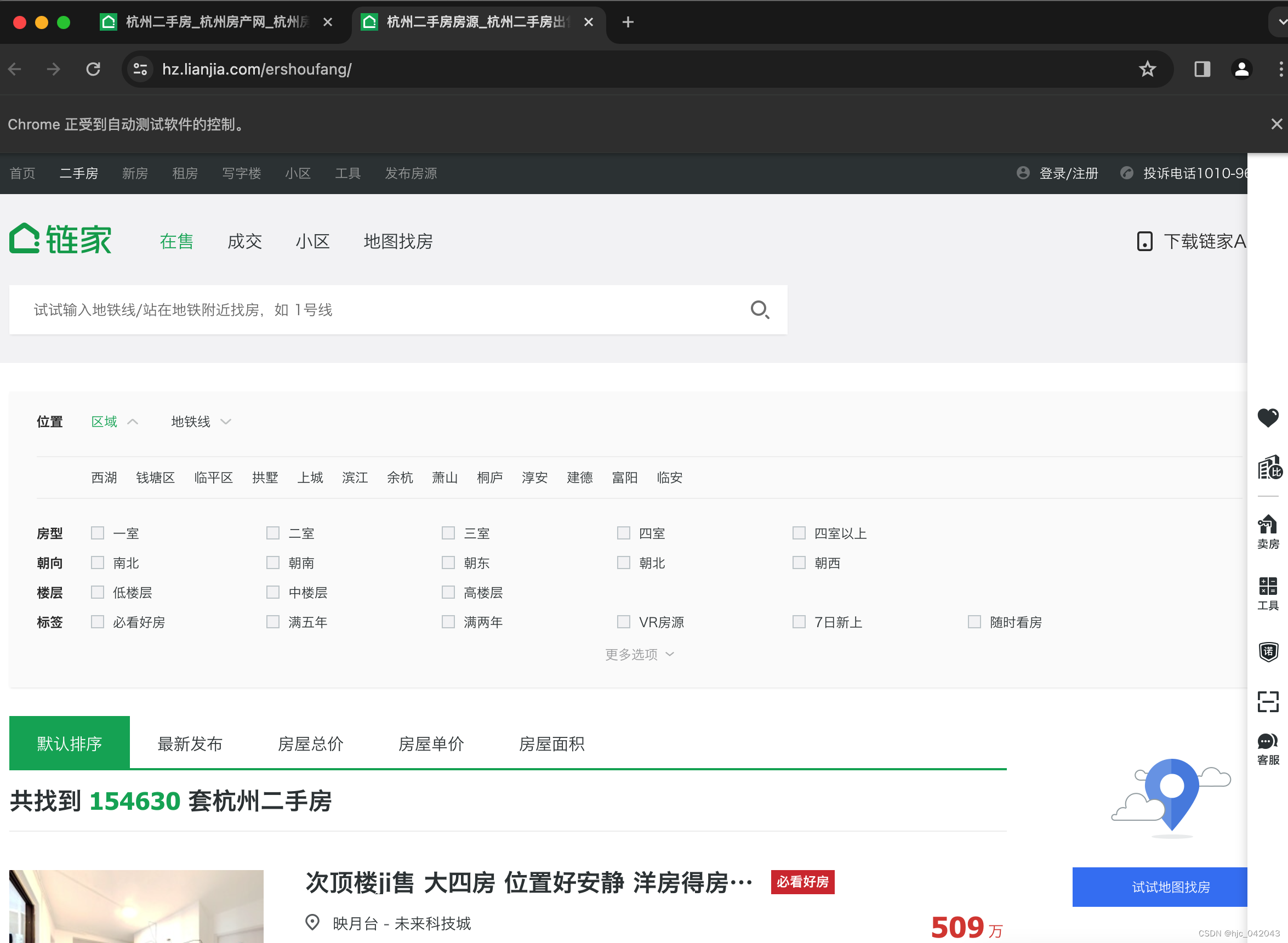
def test_js2(self):
"""
执行js代码,滚动条往下拉
@return:
"""
driver = webdriver.Chrome(service=self.service)
driver.get("https://hz.lianjia.com/")
# 执行js代码,滚动条往下拉500像素
js = "window.scrollTo(0,1000);"
driver.execute_script(js)
time.sleep(2)
# 然后点击查看更多二手房的按钮
driver.find_element(by=By.XPATH, value='//div[@id="ershoufanglist"]/div/div[1]/p/a').click()
# 强制等待5秒
time.sleep(5)
driver.quit()
pass
一开始定位不到时,就报错提示找不到元素
滚动正确的位置后,没再报错,能打开新的标签页
5. 页面等待
- 使用场景:
-
强制等待:
就是 time.sleep(x 秒),即整个页面等待 x秒 -
隐式等待(
较为常用):
针对是元素定位,隐式等待设置了一个时间,在每隔一段时间检查所有元素是否定位成功,如果定位了,就会进行下一步,如果没有定位成功,超时了,就会报超时错误。
假如设置了10秒,在10秒内会定期进行元素定位,但在第5秒钟的时候都加载成功了,那么就会往下执行,它不会一直等到10秒。如果超过了10秒就会报超时错误
driver.implicitly_wait(最大等待时间)
代码:
def test_page_wait(self):
"""
隐式等待
@return:
"""
# 打开浏览器,进到百度首页
driver = webdriver.Chrome(service=self.service)
driver.get("https://www.baidu.com/")
# 隐式等待,最大等待10秒
driver.implicitly_wait(10)
# 点击百度的logo图标的src 属性
elem = driver.find_element(by=By.XPATH, value='//img[@id="s_lg_img_new"]')
print(elem.get_attribute("src"))
# 强制等待2秒
time.sleep(2)
driver.quit()
pass

- 显示等待(
了解):
确定等待指定某个元素,然后设置最长等待时间。如果在这个时间还没定位到元素就报错。
在软件测试中使用的比较多,这在爬虫中用的不多,这里就不做过多的介绍
注意: 我们在隐式等待不好使的时候,才使用强制等待。
6. 配置代理
- 使用格式
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 需要在配置对象中添代理服务器
opt.add_argument("--proxy-server=http://ip地址:端口号")
- 代码实例
def test_proxy(self):
"""
使用代理测试121.234.119.235
@return:
"""
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
opt.add_argument("--proxy-server=http://121.234.119.235:64256")
# 打开浏览器,进到百度首页
driver = webdriver.Chrome(service=self.service, options=opt)
driver.get("https://www.baidu.com/")
driver.save_screenshot('baidu.png')
time.sleep(5)
driver.quit()
pass
7. 修改请求头
- 使用格式
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 设置user-agent修改请求头
opt.add_argument("--user-agent=xxxxxxxx")
- 代码示例:
def test_user_agent(self):
"""
selenium 可以修改请求头,user-agent,模拟成不同的浏览器
@return:
"""
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15"
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 设置user-agent修改请求头
opt.add_argument(f"--user-agent={user_agent}")
# 打开浏览器,进到百度首页
driver = webdriver.Chrome(service=self.service, options=opt)
driver.get("https://www.baidu.com/")
time.sleep(5)
driver.quit()
pass
8. 如何从selenium获取请求和响应头
- 安装模块
pip install selenium-wire
- 代码示例
def test_selenium_headers(self):
"""
selenium获取请求头和响应头
@return:
"""
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15"
# 导入seleniumwire库
from seleniumwire import webdriver
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 设置user-agent修改请求头
opt.add_argument(f"--user-agent={user_agent}")
# 打开浏览器,进到百度首页
driver = webdriver.Chrome(service=self.service, options=opt)
driver.get("https://www.baidu.com/")
print("请求头:")
for request in driver.requests:
pprint(request.headers)
break
print("响应头:")
for request in driver.requests:
pprint(request.response.headers)
break
time.sleep(5)
driver.quit()
pass

注意
- find_element 底层返回的是WebElement类型,它可以来进行时间操作比如点击 click(),清空clear()等事件
- 对于 send_keys 方法是只有文本框类型才能操作
- selenium在使用 time.sleep()时,是从浏览器转圈结束开始计时算起。
- selenium下元素的属性使用 get_attribute(“src”)等同于 xpath的@href
- selenium为了加快打开chrome驱动,可以显示的把驱动路径设置进去,这样子 selenium就不用再去搜索驱动路径了,这是selenium4之后的新写法:
service = ChromService(executable_path="/usr/local/bin/chromedriver")
driver = webdriver.Chrome(service=service)










