PostgreSQL中内部数据一致性是基于多版本并发控制 (MVCC) 机制,该机制允许数据库引擎维护多个行版本,能提供更大的并发,同时尽量减少不同进程之间的阻塞。在这个过程中会保留旧版本的行,这些旧版本的不活跃的行记录除非清理,否则会一直存在,占用磁盘空间并膨胀表和索引,从而导致查询性能缓慢。
PostgreSQL通常是使用autovacuum的进程来自动清理死元组。autovacuum 不仅会自动进行 vacuum,也会自动进行 analyze,以分析统计信息用于执行计划,autovacuum是postgresql数据库是一个后台进程,会随数据库自启动。
一、vacuum的相关代价参数
vacuum_cost_page_hit:读取已在共享缓冲区中且不需要磁盘读取的页面的开销。 默认值设置为 1。
vacuum_cost_page_miss:提取不在共享缓冲区中的页面的开销。 默认值设置为 10。
vacuum_cost_page_dirty:在某个页面中发现不活动元组时写入该页面的开销。 默认值设置为 20。
二、影响autovacuum每次的工作量的参数
autovacuum_vacuum_cost_limit 是自动清理一次性完成的工作量。
autovacuum_vacuum_cost_delay 是自动清理在达到 autovacuum_vacuum_cost_limit 参数指定的开销限制后休眠的毫秒数。
在PostgreSQL数据库里,autovacuum_vacuum_cost_limit的默认值是-1,当为-1的时候,实际上它的值会参考vacuum_cost_limit 的值,而vacuum_cost_limit的值默认为200,所以一般情况下,我们可以把autovacuum_vacuum_cost_limit的值,当成默认为200。
至于 autovacuum_vacuum_cost_delay,在 PostgreSQL-11及以下版本中,它默认为20毫秒,而在PostgreSQL-12及更高版本中,它默认为2毫秒。
autovacuum_vacuum_cost_limit=-1
vacuum_cost_limit=200
autovacuum_vacuum_cost_delay=20ms
按照如上的默认值的话,自动清理每秒唤醒 50 次 (50*20 ms=1000 ms)。 每次唤醒时,自动清理的开销限制数值为200。
这意味着,自动清理在一秒内可以执行以下操作:
大约 80 MB/秒 [(200 /vacuum_cost_page_hit) * 50 * 8 KB] 如果在共享缓冲区中找到具有不活动元组的所有页面。(在shared_buffers读取速度)
大约 8 MB/秒 [(200 /vacuum_cost_page_miss) * 50 * 8 KB] 如果从磁盘读取中所有了具有不活动元组的页面。(在os上读取速度)
大约 4 MB/秒 [(200 /vacuum_cost_page_dirty) * 50 * 8 KB]自动清理的最高写入速度为 4 MB/秒。(vacuum写入速度)
可以根据硬件的配置,以及autovacuum主要是顺序读写的情况增加autovacuum_vacuum_cost_limit参数,比如增加到1000或2000,这会使吞吐量增加5倍或10倍。
三、autovacuum的触发条件
通常autovacuum由以下几种触发场景:
当死元组的数量超过取决于两个因素的特定数量时,将触发自动清理操作(ANALYZE 或 VACUUM):表中的总行数加上固定阈值。 默认情况下,当表的 10% 加上 50 行更改时,ANALYZE 触发,当 20% 的表和 50 行发生更改时,VACUUM 触发。 由于 VACUUM 阈值是 ANALYZE 阈值的两倍,因此 ANALYZE 的触发时间早于 VACUUM。
自动analyze和自动vacuum的公式如下:
Autoanalyze = autovacuum_analyze_scale_factor * tuples + autovacuum_analyze_threshold
Autovacuum = autovacuum_vacuum_scale_factor * tuples + autovacuum_vacuum_threshold
可以使用如下的语句查看表大概死元组在多少行的时候会触发autovacuum,其中av_threshold是表做autovacuum的死元组的数量,当表的死元组达到这个阈值的时候会触发清理。av_needed是是否需要触发autovacuum,pct_dead是死元组的比例。
SELECT *
,n_dead_tup > av_threshold AS av_needed
,CASE
WHEN reltuples > 0
THEN round(100.0 * n_dead_tup / (reltuples))
ELSE 0
END AS pct_dead
FROM (
SELECT N.nspname
,C.relname
,pg_stat_get_tuples_inserted(C.oid) AS n_tup_ins
,pg_stat_get_tuples_updated(C.oid) AS n_tup_upd
,pg_stat_get_tuples_deleted(C.oid) AS n_tup_del
,pg_stat_get_live_tuples(C.oid) AS n_live_tup
,pg_stat_get_dead_tuples(C.oid) AS n_dead_tup
,C.reltuples AS reltuples
,round(current_setting('autovacuum_vacuum_threshold')::INTEGER + current_setting('autovacuum_vacuum_scale_factor')::NUMERIC * C.reltuples) AS av_threshold
,date_trunc('minute', greatest(pg_stat_get_last_vacuum_time(C.oid), pg_stat_get_last_autovacuum_time(C.oid))) AS last_vacuum
,date_trunc('minute', greatest(pg_stat_get_last_analyze_time(C.oid), pg_stat_get_last_analyze_time(C.oid))) AS last_analyze
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE C.relkind IN (
'r'
,'t'
)
AND N.nspname NOT IN (
'pg_catalog'
,'information_schema'
)
AND N.nspname !~ '^pg_toast'
) AS av
ORDER BY av_needed DESC ,n_dead_tup DESC;
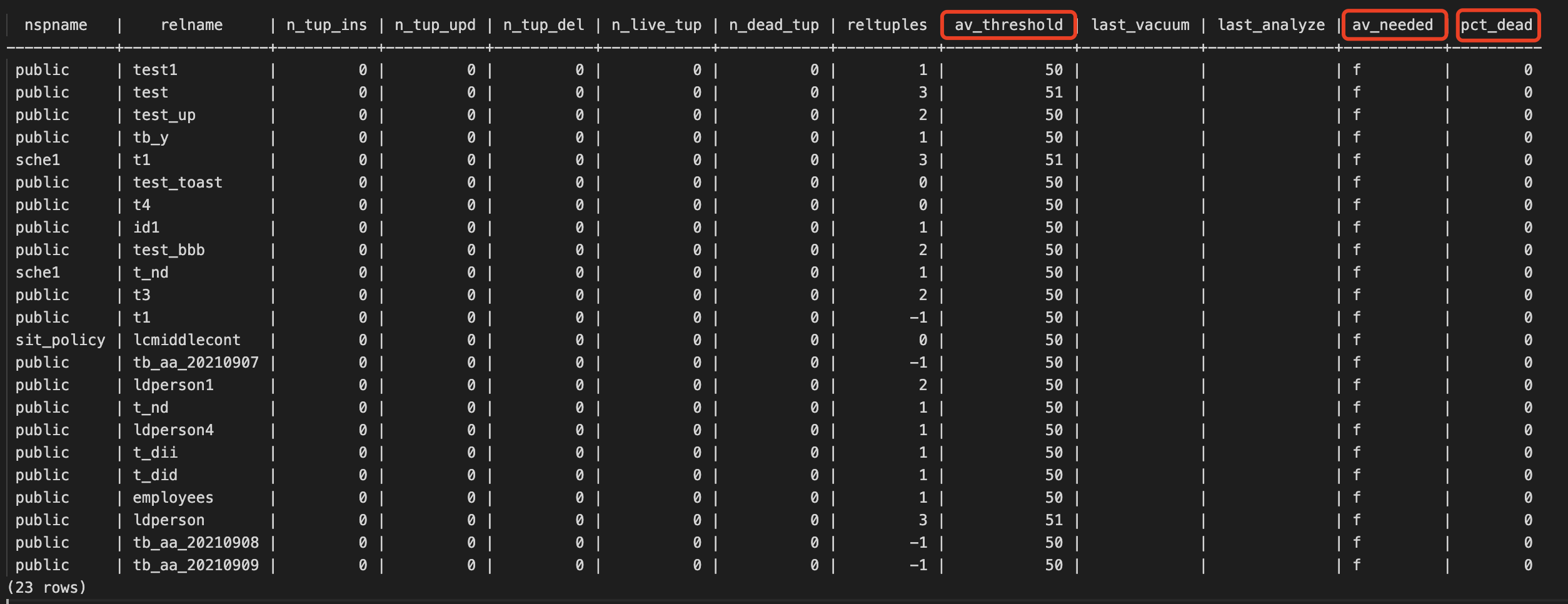
默认的autovacuum_vacuum_scale_factor和autovacuum_analyze_threshold其实比较适合于中小表,对于大表来说,默认的参数可能不太友好,一般来说解决方案有两种:一是调小大表的比例因子autovacuum_vacuum_scale_factor;二是放弃比例因子,调大autovacuum_analyze_threshold阈值。但是如果全局调大阈值或调小比例因子会影响小表的清理,不过综合全局来看,可以忽略一些小表的清理问题。
比较理想的方案是分别在表级别根据各个表的delete和update频繁程度以及表的数据量单独为每个表设置阈值。
ALTER TABLE <table name> SET (autovacuum_vacuum_scale_factor = xx);
ALTER TABLE <table name> SET (autovacuum_vacuum_threshold = xx);
四、autovacuum的相关场景
1.长时间执行的vacuum查看所处的进度
当发现长时间执行的vacuum进程的时候,可以先查看vacuum的进度,然后
从PostgreSQL-9.6版本开始,增加了一个系统视图pg_stat_progress_vacuum,可以查看vacuum的进度,无论是手动触发的还是autovacuum进程自动触发的都会显示。
| 字段名 | 描述 |
|---|---|
| pid | VACUUM 进程的进程 ID |
| datid | 正在执行 VACUUM 的数据库 ID |
| relid | 正在处理的表的 OID |
| phase | VACUUM 的阶段(扫描、清理等) |
| heap_blks_total | 表中需要扫描的块总数 |
| heap_blks_scanned | 已扫描的表块数 |
| heap_blks_vacuumed | 已清理的表块数 |
| index_vacuum_count | 已经清理的索引数 |
| max_dead_tuples | 目前已找到的任何一页中的最大死元组数量 |
| num_dead_tuples | 已处理的死元组总数 |
| last_vacuum_time | 最后一次 VACUUM 进程更新的时间 |
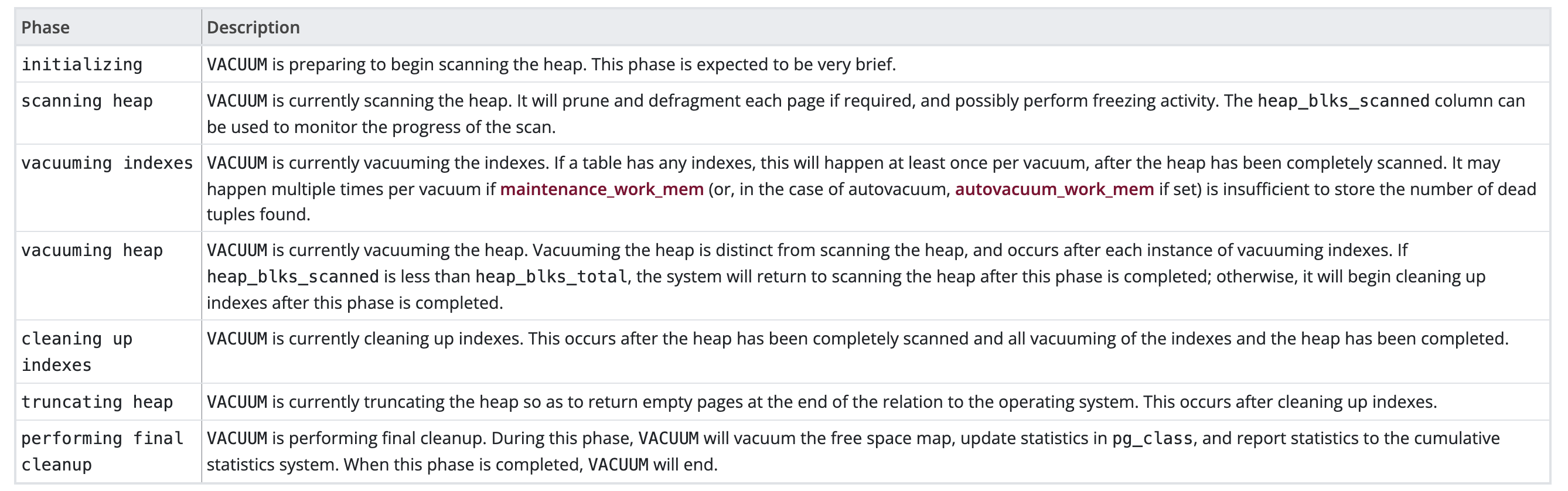
视图的phase列会显示vacuum的进度,主要有以下7个状态值:
- initializing :VACUUM正准备开始扫描堆。这一阶段预计会非常短暂。
- scanning heap :VACUUM当前正在扫描堆表。如果需要,它将对每个页面进行修剪和碎片整理,并可能执行冻结活动。heap_blks_scanned列可用于监控扫描进度。可以配合vm文件跳过一些没有包含死元组的页面。
- vacuuming indexes:VACUUM目前正在清理索引。如果表有任何索引,则在完全扫描堆表后,每次清理至少会发生一次。如果maintenance_work_mem(或在autovacuum的情况下,如果设置了autovacuum_work_mem)不足以存储找到的死元组的数量,则每次vacuum可能会发生多次。
- vacuuming heap :VACUUM当前正在清理堆表。清理堆表与扫描堆表不同,清理堆表发生在每次清理索引之后。如果heap_blks_scanned小于heap_blks_total,系统将在该阶段完成后返回扫描堆表;否则,它将在该阶段完成后开始清理索引。
- cleaning up indexes:VACUUM目前正在清理索引。这发生在堆表被完全扫描并且索引和堆表的所有清理完成之后。
- truncating heap:VACUUM当前正在截断堆表,以便在与操作系统的关系末尾返回空页。清理索引后会发触发。
- performing final cleanup:VACUUM正在执行最后的清理。在此阶段,VACUUM将清理可用空间映射(fsm),更新pg_class中的统计信息,并将统计信息报告给累积统计系统。当这个阶段完成后,VACUUM就会结束。
数据库里有log_autovacuum_min_duration参数,它会告诉我们autovacuum进程正在做什么工作,这对我们做故障诊断很有用,可以表级别设置log_autovacuum_min_duration。
设置了符合要求的log_autovacuum_min_duration值后,打印的日志大致如下,日志中,如果看到“index scans: 2”或更大的值,则表示maintenance_work_mem内存快用完了,应该考虑增加该配置值。:
[2023-12-14 08:13:26 UTC] LOG: 00000: automatic vacuum of table "postgres.public.foo": index scans: 0
pages: 0 removed, 1 remain, 0 skipped due to pins, 0 skipped frozen
tuples: 0 removed, 10 remain, 0 are dead but not yet removable, oldest xmin: 740
index scan not needed: 0 pages from table (0.00% of total) had 0 dead item identifiers removed
avg read rate: 27.174 MB/s, avg write rate: 27.174 MB/s
buffer usage: 55 hits, 4 misses, 4 dirtied
WAL usage: 5 records, 4 full page images, 33264 bytes
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
2.autovacuum扫描/回收索引过程太慢
v11-v13引入的一个GUC参数vacuum_cleanup_index_scale_factor,但是在v14取消了,对于大量insert,没有update、delete操作的表的vacuum,或者常规静态表的vacuum会快很多,因为不需要scan index了。
索引假如被认为是过时的,也会在vacuum清理阶段触发对索引的扫描,也就是如果新插入的元组数量超过了之前统计信息所收集到的元组总数所对应的vacuum_cleanup_index_scale_factor参数指定的比例,则索引统计信息被认为是过时的。
当满足公式(insert_tuples - previous_total_tuples) / previous_total_tuples > vacuum_cleanup_index_scale_factor时,vacuum cleanup阶段才需要去扫描索引,更新index stats信息(包括meta page计数器信息)
而v12版本也在表级别增加了vacuum_index_cleanup参数,可以在创建表的时候设置,也可以alter table设置。参数可以控制VACUUM在是否禁用索引清理的情况下运行,默认值为true。v12版本的VACUUM引入了一个新的选项INDEX_CLEANUP,可以跳过索引的垃圾回收。
v13里引入了并行索引扫描(不过vacuum full是不能并行的)
v13引入autovacuum_vacuum_insert_threshold和autovacuum_vacuum_insert_scale_factor。
当死元组的数量达到 autovacuum_vacuum_insert_scale_factor * tuples + autovacuum_vacuum_insert_threshold的时候,就会触发autovacuum。
3.autovacuum_max_workers过多导致性能下降
autovacuum_max_workers可以增加autovacuum工作进程的最大数量,根据字面意思提升autovacuum_max_workers意味着有更多的worker执行清理工作,自然可以提高性能。但实际上,提高autovacuum_max_workers不一定会有用。
如果只有一个活跃业务db,那么不管设定的autovacuum_max_workers多大,永远只会启动一个worker来对该db进行清理,要想提升性能只能通过多线程的方式同时对多个表进行处理。但目前来看autovacuum worker进程并没有启动多线程并行处理。
如果有多个活跃业务db,单纯提高autovacuum_max_workers而不提高autovacuum_vacuum_cost_limit(默认值为vacuum_cost_limit,即200)的值也没有用处。因为autovacuum_vacuum_cost_limit对成本的限制是全局的。一旦达到成本上限,worker就会进入休眠,sleep时间为参数vacuum_cost_delay所设定的值(v12该参数默认为2ms,v11该参数默认为20ms),然后再继续处理。
简而言之,每个自动清理工作进程只获得总数 autovacuum_cost_limit 的 (1/autovacuum_max_workers),因此拥有大量工作器会导致每个工作进程变慢。
如果工作器的数量增加,那么也应该增大 autovacuum_vacuum_cost_limit 且/或减小 autovacuum_vacuum_cost_delay 以加快清理过程。
但是,如果我们更改了表级别autovacuum_vacuum_cost_delay 或 autovacuum_vacuum_cost_limit参数,那么平衡算法 [autovacuum_cost_limit/autovacuum_max_workers] 中将不会考虑在这些表上运行的worker。
4. maintenance_work_mem不合适可能引起性能问题
过大的maintenance_work_mem值可能会周期性地导致系统中的内存不足错误。如果maintenance_work_mem设置太低,甚至需要多次索引扫描。非常考验性能,并且非常浪费资源。
一般的经验法则是,为每 1 GB 的 RAM 为 maintenance_work_mem分配 50 MB。
5.长事务阻塞回收死元组
长事务会阻塞autovacuum进程回收死元组,所以需要留意数据库里的长事务,在autovacuum的时候,杀掉部分长事务,来释放这部分死元组以供删除。
//查询长事务的SQL如下
SELECT pid, age(backend_xid) AS age_in_xids,
now () - xact_start AS xact_age,
now () - query_start AS query_age,
state,
query
FROM pg_stat_activity
WHERE state != 'idle'
ORDER BY 2 DESC
LIMIT 10;
6.未提交的预定义语句阻塞回收死元组
如果有未提交的预定义语句,它们会阻止移除死元组。
需要使用 COMMIT PREPARED或ROLLBACK PREPARED提交或回滚这些语句。
//查询未提交的预定义语句的SQL如下
SELECT slot_name, slot_type, database, xmin
FROM pg_replication_slots
ORDER BY age(xmin) DESC;
7.业务繁忙,autovacuum清理速率慢
当业务繁忙,autovacuum清理速率慢的时候,可以考虑增大autovacuum_vacuum_cost_limit 参数,以提高成本限制。
也可以适当减小autovacuum_vacuum_cost_delay的值,让更多时间处于唤醒的状态,有更多时间做清理。
或者查看maintenance_work_mem/autovacuum_work_mem是否符合预期等。
但是上述调整应在更改之前和之后监视数据库的 CPU 和 I/O 利用率,以防物理资源瓶颈。










