一、什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析也成为如今主流的爬取策略。
1 爬虫可以做什么
你可以爬取网络上的的图片,爬取自己想看的视频等等,只要你能通过浏览器访问的数据都可以通过爬虫获取。
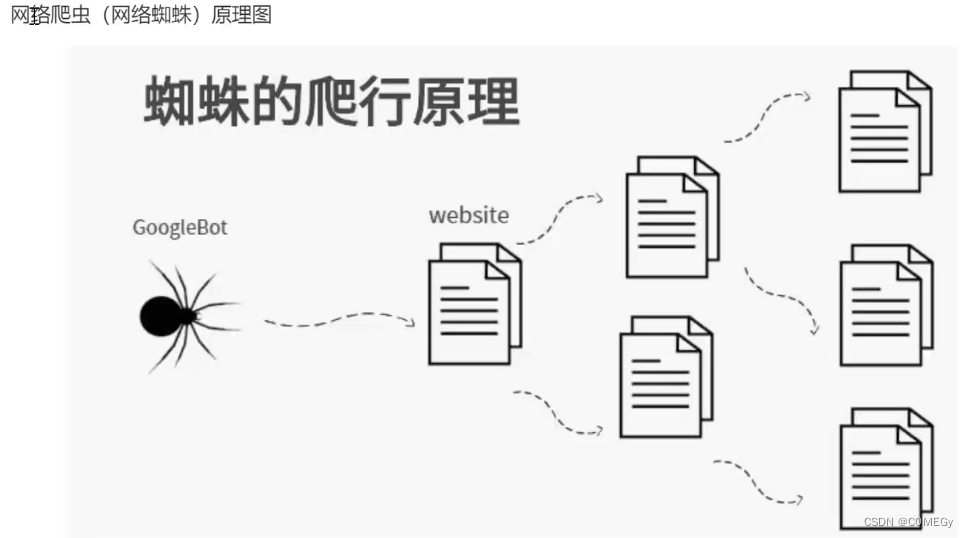
2 爬虫的本质是什么
模拟浏览器打开网页,获取网页中我们想要的那部分数据
学习案例:爬取豆瓣电影 Top 250的基本信息
引入第三方模块
# 引入第三方模块
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt #进行Excel操作
import sqlite3 #进行数据库操作正则表达式——制定获取数据规则
# 影片详情链接规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式对象,表示规则(字符串模式)
findImg=re.compile(r'<img.*src="(.*?)?"',re.S) #影片图片
findTitle=re.compile(r'<span class="title">(.*)</span>') #影片名字
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') #影片评分
findJudge=re.compile(r'<span>(\d*)人评价</span>') #影片评价人数
findIng=re.compile(r'<span class="ing">(.*)</span>') #找到概况
findBd=re.compile(r'<p class="">(.*?)</p>',re.S) #找到影片的相关内容完整代码
# 引入第三方模块
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt #进行Excel操作
import sqlite3 #进行数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
dataList=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls"
# 影片详情链接规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式对象,表示规则(字符串模式)
findImg=re.compile(r'<img.*src="(.*?)?"',re.S) #影片图片
findTitle=re.compile(r'<span class="title">(.*)</span>') #影片名字
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') #影片评分
findJudge=re.compile(r'<span>(\d*)人评价</span>') #影片评价人数
findIng=re.compile(r'<span class="ing">(.*)</span>') #找到概况
findBd=re.compile(r'<p class="">(.*?)</p>',re.S) #找到影片的相关内容
def getData(baseurl):
dataList=[]
for i in range(0,10):# 调用获取页面信息的函数 10次
url=baseurl+ str(i*25)
html=askURL(url) # 保存获取到的源码
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串
data=[] #保存电影信息
item =str(item)
#获取影片详情链接
link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串
data.append(link) #添加链接
imgSrc=re.findall(findImg,item)[0]
data.append(imgSrc) #添加图片
titles=re.findall(findTitle, item)[0]
if(len(titles)==2): #片名可能有两个名字,一个中文,一个外文
ctitle=titles[0]
data.append(ctitle) #添加中文名
otitle=titles[1].replace("/","")
data.append(otitle) #添加外文名
else:
data.append(titles[0]) # 添加图片
data.append(' ') #留空,保持Excel数据一致性
rating=re.findall(findRating, item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评分人数
ing = re.findall(findIng, item)
if len(ing)!=0:
ing=ing[0].replace("。","")
data.append(ing) # 添加概述
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?'," ",bd)
bd=re.sub('/'," ",bd)
data.append(bd.strip()) # 添加影片的相关内容
dataList.append(data) #把处理好的电影信息放入dataList
print(dataList)
return dataList
# 得到指定一个URL的网页内容
def askURL(url):
# head用户代理,本质上告诉浏览器我们接收什么水平的数据
head={
"User-Agent": "Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.87 Mobile Safari / 537.36"
}
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(savepath):
print("save.....")
if __name__ =="__main__":
# 调用函数
main()








