目录
1.langchain agent使用chatgpt调用tools的源代码
背景:如果使用openai的chatgpt4进行语言问答,是需要从国内到国外的一个客户请求-->openai服务器response的一个过程,尽管openai的算力很强,计算速度很快,但这个国内外网络的信息传输存在一定的延迟和不稳定现象。
可能的解决办法:调用本地语言模型,这样就不需要去访问openai的服务器了,也就没了网络传输。
0.langchain agent 原理
本质:llm推理-->推理结果和tools的描述计算相似度-->top 1 tool-->行动
在 LangChain 中,Agent 是一个代理,接收用户的输入,采取相应的行动然后返回行动的结果。
官方也提供了对应的 Agent,包括 OpenAI Functions Agent、Plan-and-execute Agent、Self Ask With Search 类 AutoGPT 的 Agent 等。
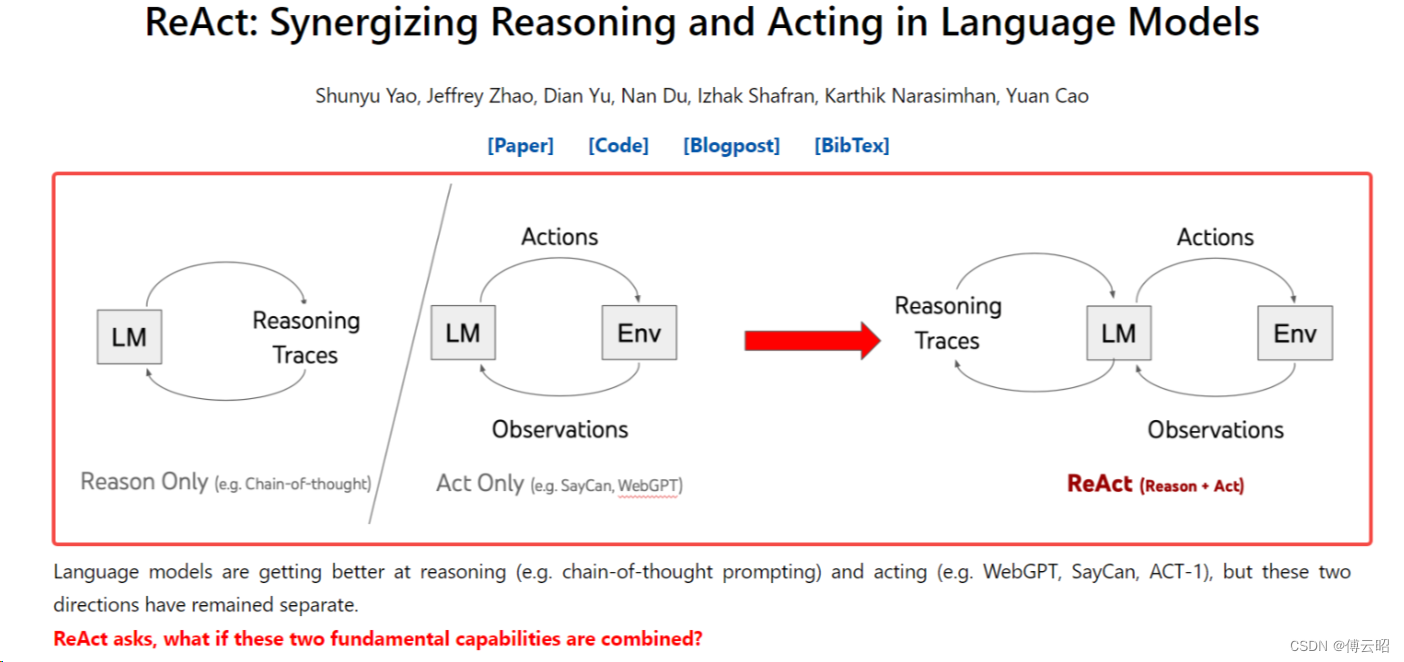
ReAct
其中一种是基于 ReAct 原理来实现的 Agent。
https://react-lm.github.io/
https://github.com/ysymyth/ReAct




1.langchain agent使用chatgpt调用tools的源代码
主要关注agent是如何调用tools的
主要的执行类:agentExecutor
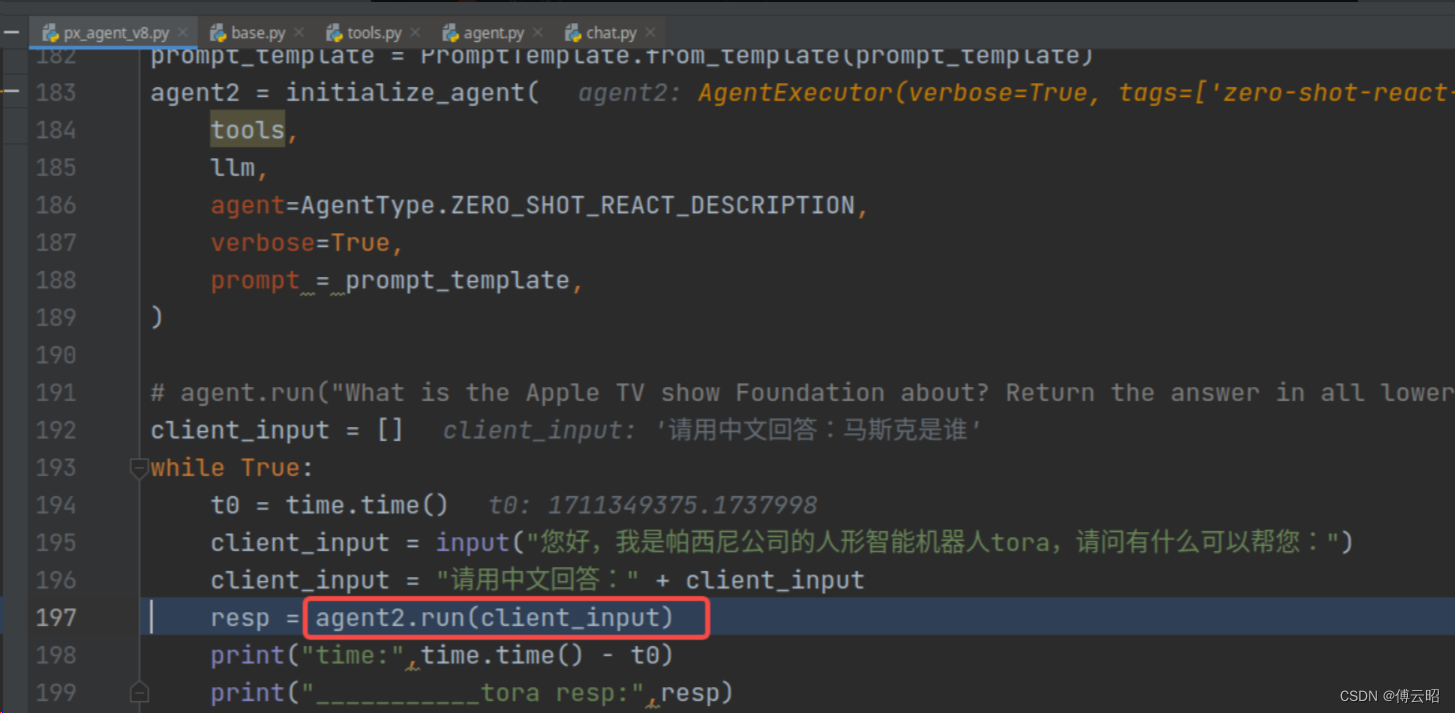

本质是agent就是一个特殊的chain
执行chain


在agentexcutor这个类里面,因为agent执行的是思考(llm)-->行为(tools)-->再根据结果再思考-->再行为这样的一个循环过程。即llm大脑思考用户的问题,然后计划方案,然后执行行为,根据行为结果思考是否解决问题,如果没有则继续思考然后继续执行行为,这样的逻辑过程。

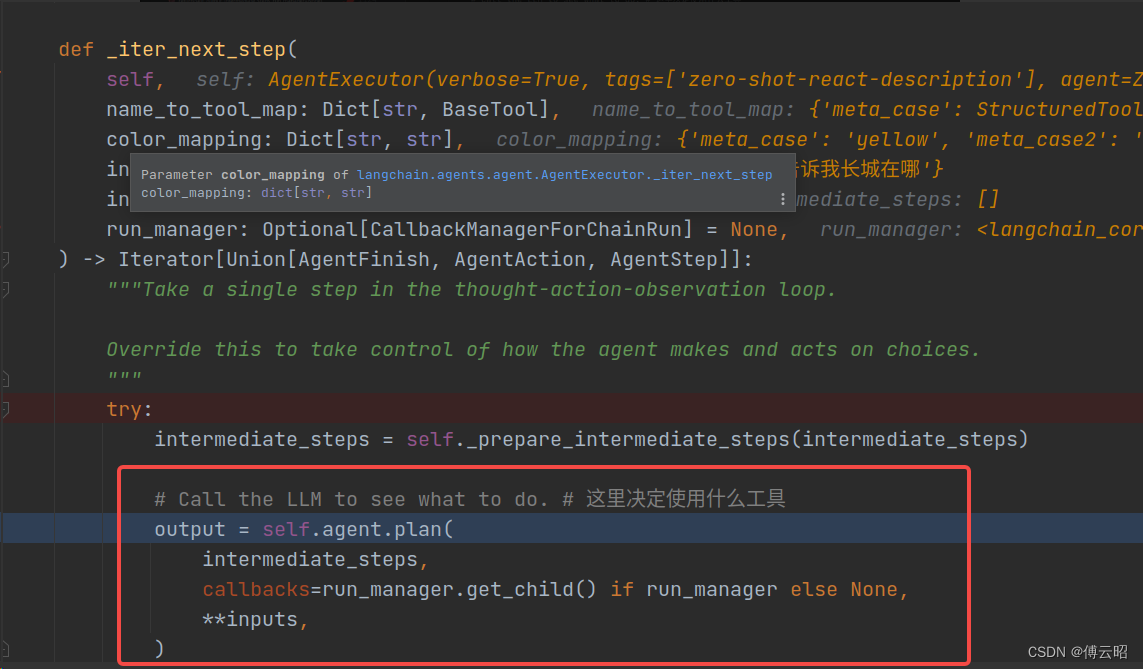

使用llm来思考决定使用什么工具

又到了这里,因为llm也是chain,langchain的核心就是所有的都是chain,然后组合起来




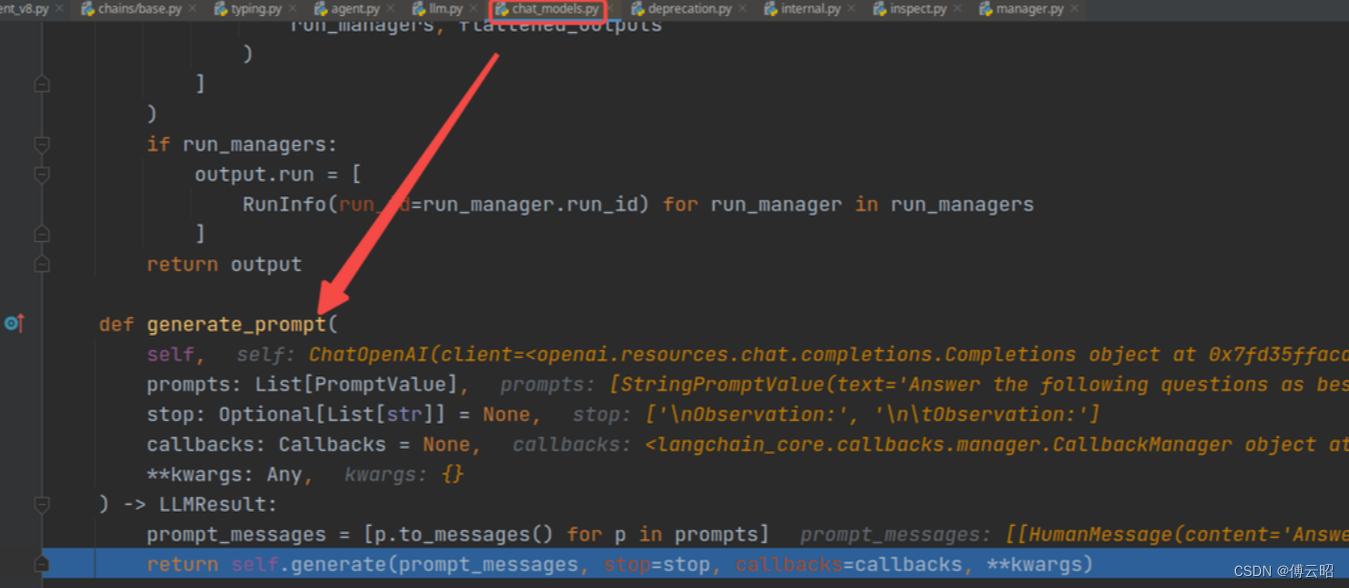




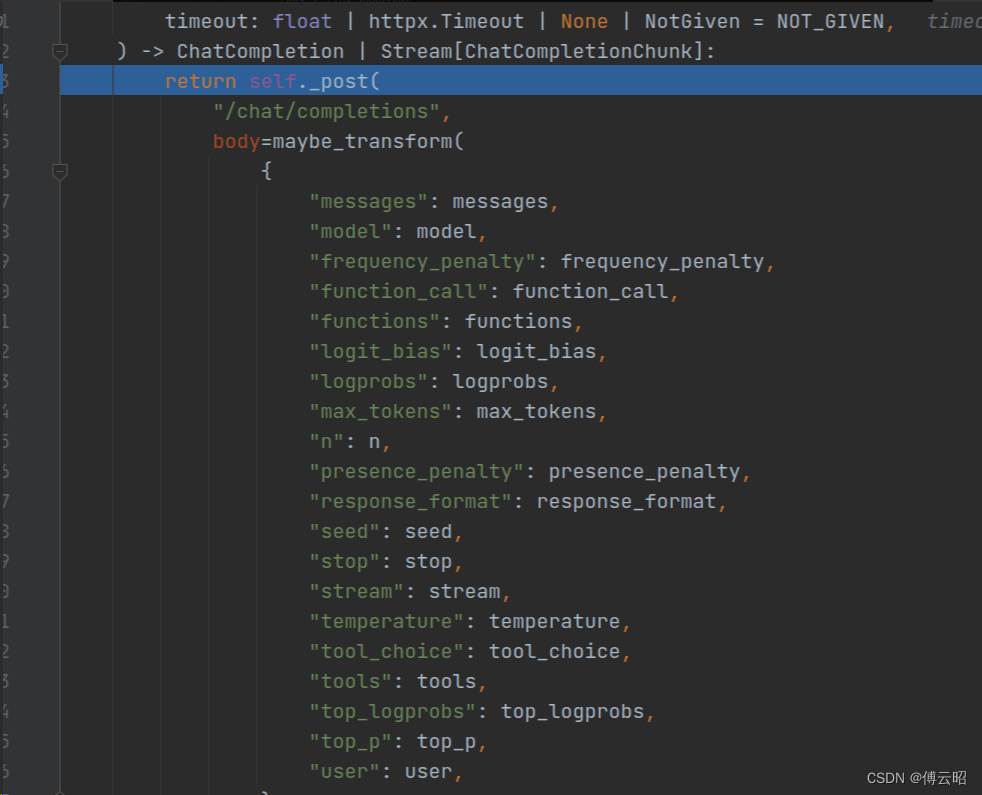

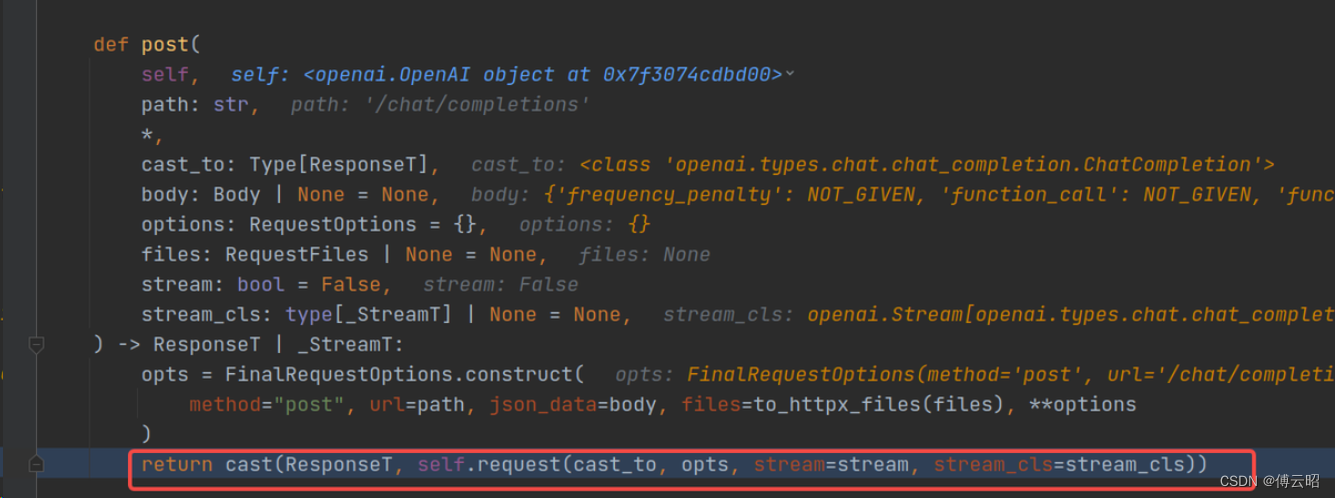

终于看到了client的request了,这就是我们发送请求给openai


send:发送请求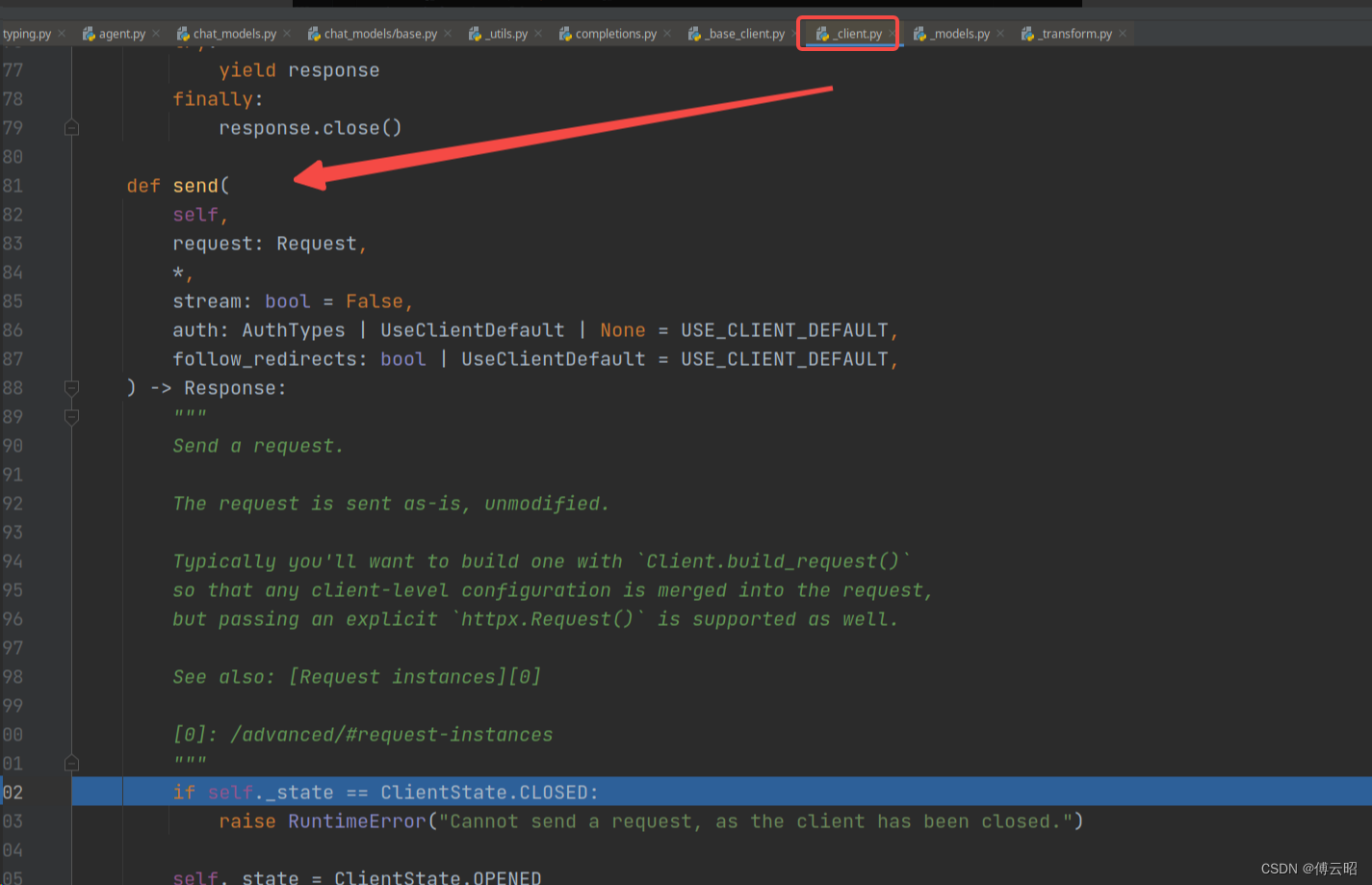 最后结果如下:
最后结果如下:

agent调用工具
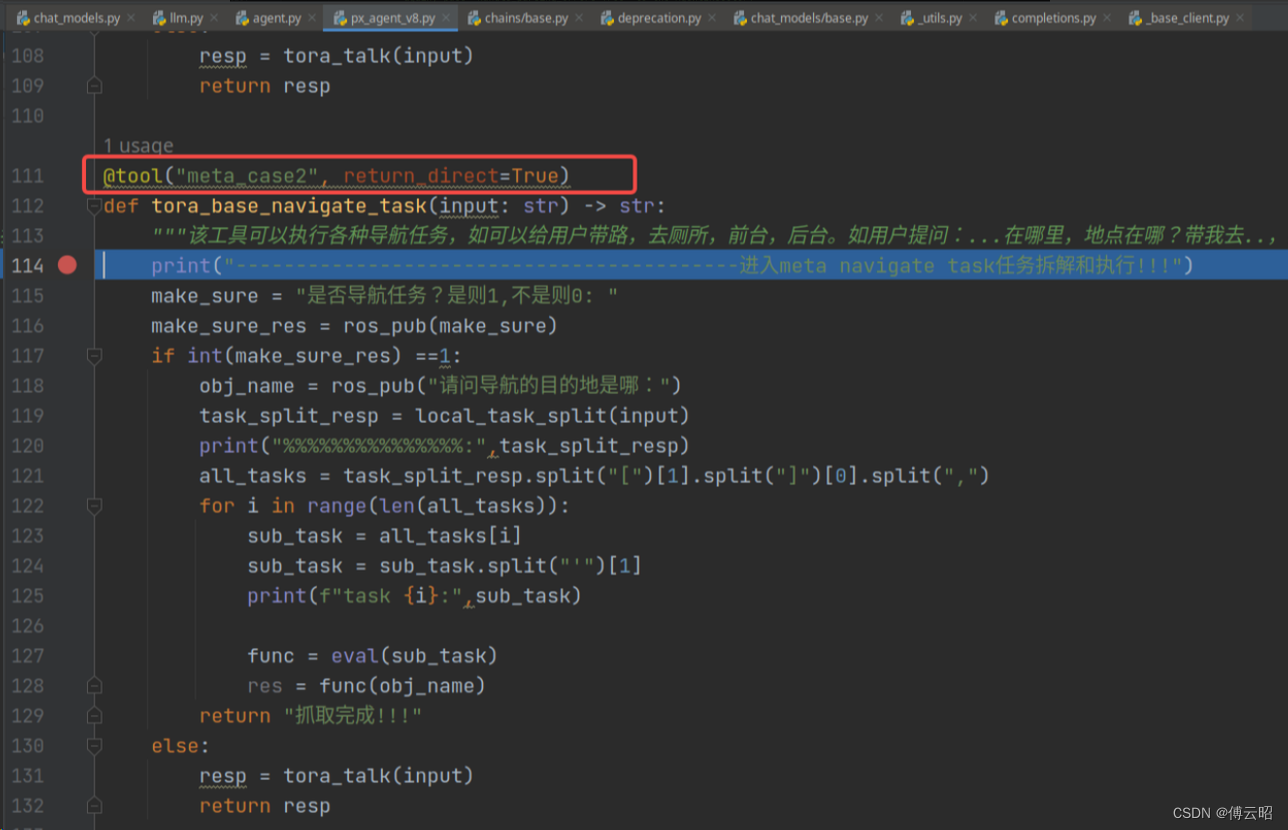
本质是llm会根据用户的输入和tools的函数的功能描述来选择工具。逻辑是先把描述的语句和用户输入做embedding为token,然后llm根据用户输入进行逻辑推理生成结果,然后把结果和工具描述做attention(余弦相似度计算),然后把相似度分数排序,选择相似度最高的。我们这里的用户输入是:告诉我长城在哪,和meta_case2的描述最接近(因为里面有"地点在哪"这个词),所以选择了这个工具。但并不符合我们的意图,所以llm并不能理解意图,只能做相似度计算,所以tools的函数功能描述非常重要。
关于我们函数功能描述的模板:
函数功能:什么功能作用
函数案例:比如可以抓取物品如零食
用户需求:可以解决什么用户需求
用户案例:可以解决用户的。。。需求
用户提问方式:是什么,为什么,怎么办。。。
一般性抽象性概括性词汇,水果>香蕉
2.自定义本地语言模型的代码chatglm6B
参考了一些官方和他人帖子:
https://zhuanlan.zhihu.com/p/630147161
https://python.langchain.com/docs/modules/model_io/chat/custom_chat_model
https://python.langchain.com/docs/modules/model_io/llms/custom_llm
主要就是LLM类的继承和重写
# 函数继承和重写
class GLM(LLM):
max_token: int = 2048
temperature: float = 0.8
top_p = 0.9
tokenizer: object = None
model: object = None
history_len: int = 1024
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "GLM"
def load_model(self):
self.tokenizer = AutoTokenizer.from_pretrained("PiaoYang/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, device_map='auto')
self.model = PeftModel.from_pretrained(model, "shibing624/chatglm-6b-belle-zh-lora")
self.model = self.model.half().cuda()
def _call(self, prompt:str,history:List[str] = [],stop: Optional[List[str]] = None):
response = self.model.chat(self.tokenizer, prompt, max_length=128, eos_token_id=self.tokenizer.eos_token_id)
return response我们这里的本地模型是chatglm6B,结果:
显存:

速度:
10个字需要0.12s
3.调用国内大语言模型
因为agent的结果严重依赖llm的性能,chatglm6B虽然确实可以加快速度,但效果很差,基本没法正常调用tools,因此尝试调用清华做的质谱AI大模型chatglm4.
ZHIPU AI | 🦜️🔗 Langchain
质谱的key:智谱AI开放平台 (bigmodel.cn) 可免费申请。

效果依旧不好,速度也不快
4.其他加速方法
再说吧。
https://blog.csdn.net/inteldevzone/article/details/134645500zhizhi










