1. Map and Reduce
- Map:处理键值对,生成一组中间键值对
- Reduce:合并与同一中间键相关的所有中间值
- process overview:分割输入数据,组织程序在一组机器上的执行,处理机器故障,以及管理所需的机器间的通信
2. Introduction
- 如何并行化计算、分发数据和处理故障等问题,使得原本简单的计算被大量复杂的代码所掩盖,无法处理这些问题。
- 通过设计MapReduce,我们可以清晰表达我们试图执行的简单计算,同时隐藏关于并行化、容错、数据分布、负载均衡的相关细节。
- 主要贡献:提供一个可以自动进行分布式并行化大规模计算的接口,及其实现。
3. Programming Model
- MapReduce执行的计算以一组键值对作为输入,然后产生另一组键值对作为输出。执行的计算由两个函数完成:Map函数和Reduce函数,均由用户来编写实现。
- Map:应用在每个键值对上,产生一组中间键值对作为输出,然后MapReduce库会汇总关联于同一中间键I的中间值并将它们传送给Reduce函数。
- Reduce:接受由Map函数传递过来的中间键I及其相应的一组中间值作为输入,然后合并这些中间值得到一个更小的值的集合作为输出。
- 类型
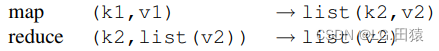
- 对于Map,输入的键值对和输出的键值对来自不同的值域,而对于Reduce则相同。
- 例子

- 给定大量的文档,计算出文档中每个word出现的次数。Map函数会输出每个单词以及相关的出现次数,Reduce函数会将某个单词的所有计数相加并输出。
4. Implementation
4.1 Execution Overview
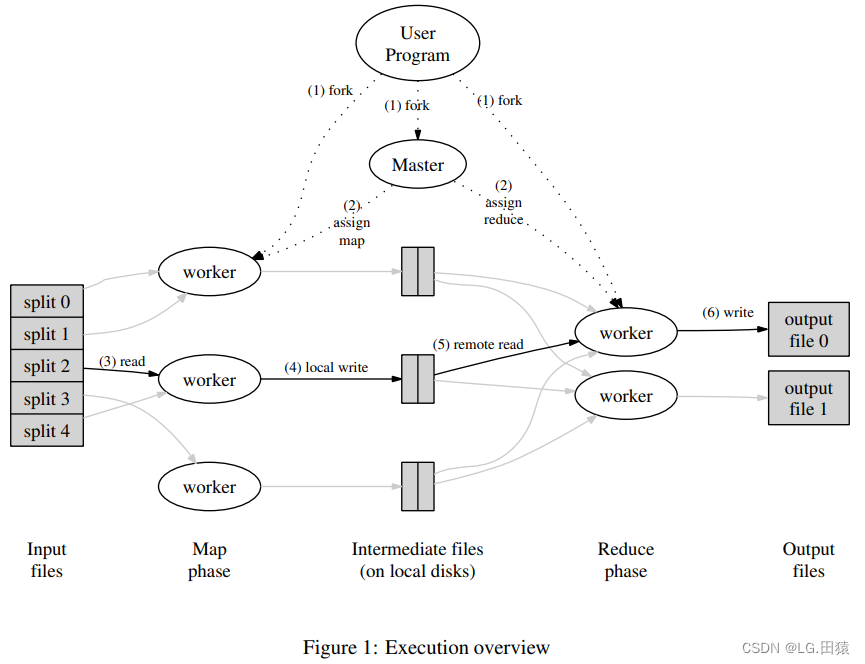
- MapReduce的执行流程:
- 将输入文件分割成若干个大小为16到64MB的pieces,然后在集群的机器中启动多个副本程序(fork);
- 在启动的程序中,由一个master和多个workers;假设计算过程总共包含M个Map任务和R个Reduce任务,master会将所有这些任务分配给workers,一个worker会被分配到一个Map任务或一个Reduce任务;(assign map/reduce)
- 被分配Map任务的worker首先读取相应split的内容,从输入数据中解析出所有的键值对,为每个键值对调用Map函数,由Map函数产生的中间键值对会被缓冲在内存中;(read)
- 缓冲在内存中的中间键值对会被阶段性地写到本地磁盘中,同时根据partition函数被分为R个部分,然后worker会将这些中间结果的位置信息报告给master;(local write)
- 当一个负责Reduce任务的worker接收到master传递过来的中间结果的位置信息后,通过远程调用从Map workers的本地磁盘中读取中间结果;当worker完成读取所有中间结果时,将数据以中间键排序使得对应相同键的值能够连续分布;(如果中间结果数据量太大,可能需要进行外部排序)(read remote)
- Reduce worker遍历所有已排序的中间键值对,然后对于每个中间键,将该键及其相应的值作为参数调用用户定义的Reduce函数,Reduce 函数的输出会被放入到对应的 Reduce Partition 输出文件;(write)
- 当所有的Map任务和Reduce任务都已经完成后,master会唤醒用户程序,MapReduce调用结束并返回到用户代码中。
4.2 Master Data Structures
- 对于每个Map任务和Reduce任务,存储状态信息(idle, in-progress, or completed),以及每个(非空闲的)worker机器的ID。
4.3 Fault Tolerance
- Background:MapReduce计算通常在成千上万的机器上面执行,难免遇到机器故障,所以必须容错。
- Worker Failure
- master会周期性地向每个worker发送ping信号,如果没有收到回复,则将该worker设置为不可用状态,然后将已经在该worker中完成的Map任务或正在该worker中执行的Map或Reduce任务设置为初始的idle状态,并重新分配给其他worker。
- 在不可用的worker中已经完成的Map任务需要重新执行,因为Map任务的输出是存储在已经不可用的worker的本地磁盘中(不可访问);而已经完成的Reduce任务不需要重新执行,因为Reduce任务输出的结果是存储在global file system中。
- Map任务重新分配的worker信息需要通知所有负责Reduce任务的workers。
- Master Failure
- 周期性地将集群的当前状态以及checkpoints写入磁盘中,如果master进程终止后,重新启动一个新的master进程并利用存储在磁盘中的数据恢复到最新一次的checkpoint的状态。
- Semantics in the Presence of Failures
- 通过Map任务和Reduce任务的原子性提交来保证输入输出的确定性(保持和整个程序无错顺序执行的输出结果一致)
- 当一个Map任务完成后,worker向master发送中间结果位置信息,master仅保存一次同一Map任务的结果信息。
- 当一个Reduce任务完成后,worker原子性地将暂存输出文件重命名为最终输出文件。
4.4 Locality
- 在分配任务时,master会考虑输入文件的位置信息,并尝试在包含相应输入数据副本的机器上分配Map任务。如果做不到,它会尝试给在该任务的输入数据副本附近的worker分配一个Map任务。
- 通过利用数据的本地性以减小网络带宽开销。
4.5 Task Granularity
- M和R的取值一般比worker机器的数量大得多,通过使每个worker承担多个不同的任务来实现动态的负载均衡同时加速一个不可用worker的恢复(当一个负责某些Map任务的worker变为不可用时,其他所有worker可以分担这些任务)。
- master需要进行O(M + R)次调度决策和使用O(M * R)的空间保存状态信息。
4.6 Backup Tasks
- straggler:某个worker机器花了很长时间去完成剩下的若干个Map或Reduce任务,从而使得整个MapReduce计算花费很长时间
- solution:当一个MapReduce计算接近完成时,将剩下的正在执行的任务进行备份然后分配给其他空闲的worker,只要其中一个完成某个任务即视该任务已完成。
5. Refinements
- Partitioning Function
- 根据用户指定的(Reduce)输出文件数R,设置partition函数,如“hash(key) mod R”
- Combiner Function
- 在某些情况下,Map任务会产生大量重复的中间键,通过引入combiner函数来执行Map函数输出结果的部分合并(对应相同键的值),从而减少 Map 和 Reduce之间需要传输的数据量,并且加速了整个MapReduce计算过程。










