文章目录
总结
本系列是机器学习课程的系列课程,主要介绍基于python实现神经网络。
参考
BP神经网络及python实现(详细)
本文来源原文链接:https://blog.csdn.net/weixin_66845445/article/details/133828686
用Python从0到1实现一个神经网络(附代码)!
python神经网络编程代码https://gitee.com/iamyoyo/makeyourownneuralnetwork.git
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
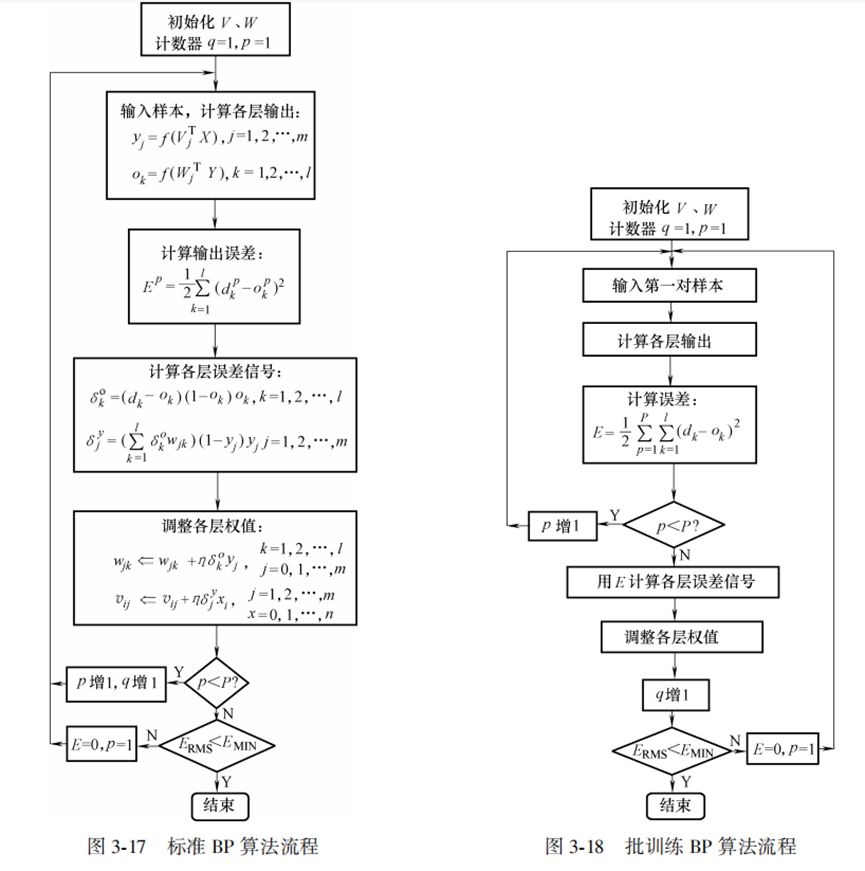
BP神经网络流程



BP算法实现流程图

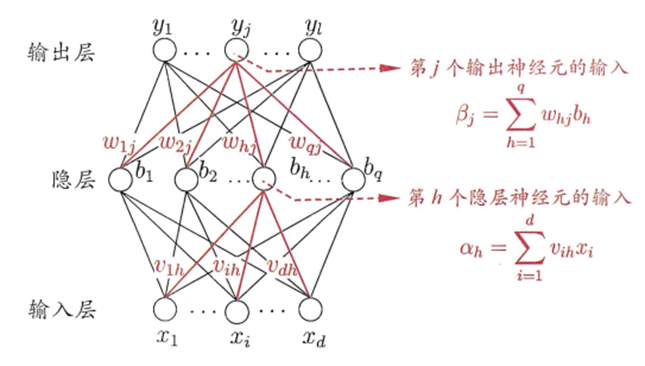
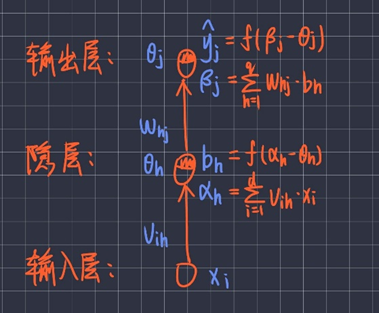
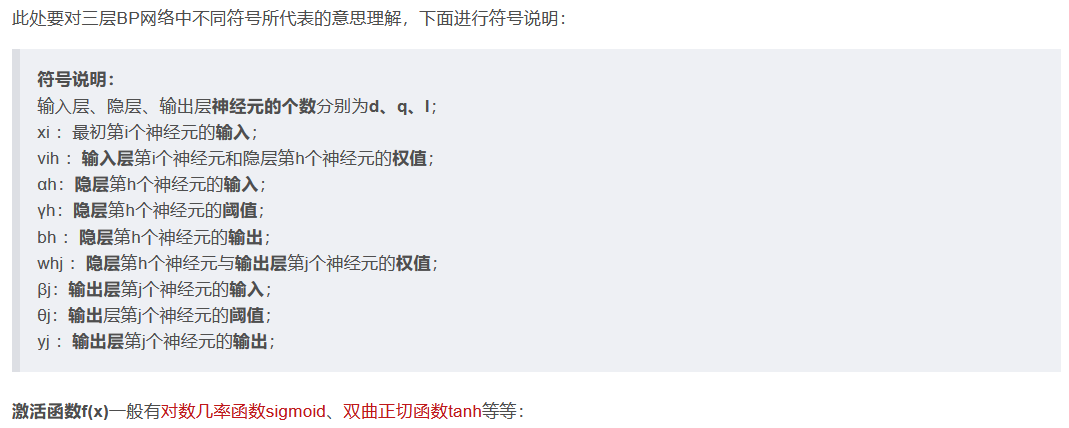
BP神经网络推导


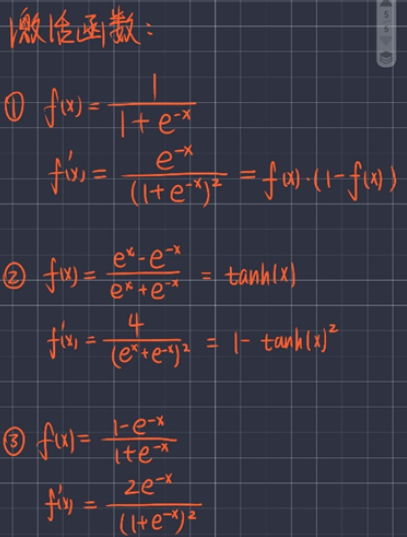


Python实现BP神经网络
4.1 激活函数sigmod
激活函数采用双曲正切函数tanh:
#? 激活函数sigmoid(x)、及其导数DS(x)
import numpy as np
# 双曲正切函数tanh
def sigmoid(x):
return np.tanh(x)
def DS(x):
return 1 - (np.tanh(x)) ** 2
# 第90次迭代 误差0.00005
4.2 构造三层BP神经网络
神经网络类架构
#? 构造3层BP神经网络架构
class BP:
#? 初始化函数:各层结点数、激活结点、权重矩阵、偏差、动量因子
def __init__(self,num_in,num_hidden,num_out):
pass
#? 信号正向传播
def update(self,inputs):
pass
#? 误差反向传播
def errorbackpropagate(self,targets,lr,m): # lr 学习效率
pass
#? 测试
def test(self,patterns):
pass
#? 权值
def weights(self):
pass
# 训练
def train(self,pattern,itera=100,lr=0.2,m=0.1):
pass
4.2.1 BP神经网络初始化
#? 构造3层BP神经网络架构
class BP:
#? 初始化函数:各层结点数、激活结点、权重矩阵、偏差、动量因子
def __init__(self,num_in,num_hidden,num_out):
# 输入层、隐藏层、输出层 的结点数
self.num_in=num_in+1 # 输入层结点数 并增加一个偏置结点(阈值)
self.num_hidden=num_hidden+1 # 隐藏层结点数 并增加一个偏置结点(阈值)
self.num_out=num_out # 输出层结点数
# 激活BP神经网络的所有结点(向量)
self.active_in=np.array([-1.0]*self.num_in)
self.active_hidden=np.array([-1.0]*self.num_hidden)
self.active_out=np.array([1.0]*self.num_out)
# 创建权重矩阵
self.weight_in=makematrix(self.num_in,self.num_hidden) # in*hidden 的0矩阵
self.weight_out=makematrix(self.num_hidden,self.num_out) # hidden*out的0矩阵
# 对权重矩阵weight赋初值
for i in range(self.num_in): # 对weight_in矩阵赋初值
for j in range(self.num_hidden):
self.weight_in[i][j]=random_number(0.1,0.1)
for i in range(self.num_hidden): # 对weight_out矩阵赋初值
for j in range(self.num_out):
self.weight_out[i][j]=random_number(0.1,0.1)
# 偏差
for j in range(self.num_hidden):
self.weight_in[0][j]=0.1
for j in range(self.num_out):
self.weight_out[0][j]=0.1
# 建立动量因子(矩阵)
self.ci=makematrix(self.num_in,self.num_hidden) # num_in*num_hidden 矩阵
self.co=makematrix(self.num_hidden,self.num_out) # num_hidden*num_out矩阵
图解:初始化后各个变量的存在形式:
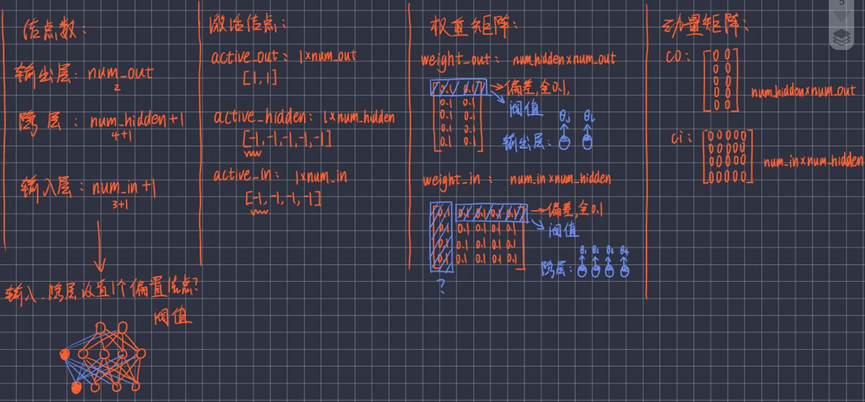
4.2.2 前向传播
#? 构造3层BP神经网络架构
class BP:
#? 信号正向传播
def update(self,inputs):
if len(inputs)!=(self.num_in-1):
raise ValueError("与输入层结点数不符")
# 数据输入 输入层
self.active_in[1:self.num_in]=inputs
# 数据在隐藏层处理
self.sum_hidden=np.dot(self.weight_in.T,self.active_in.reshape(-1,1)) # 叉乘
# .T操作是对于array操作后的数组进行转置操作
# .reshape(x,y)操作是对于array操作后的数组进行重新排列成一个x*y的矩阵,参数为负数表示无限制,如(-1,1)转换成一列的矩阵
self.active_hidden=sigmoid(self.sum_hidden) # active_hidden[]是处理完输入数据之后处理,作为输出层的输入数据
self.active_hidden[0]=-1
# 数据在输出层处理
self.sum_out=np.dot(self.weight_out.T,self.active_hidden)
self.active_out=sigmoid(self.sum_out)
# 返回输出层结果
return self.active_out
图解:正向传播的过程:计算出active_in、active_hidden、active_out:
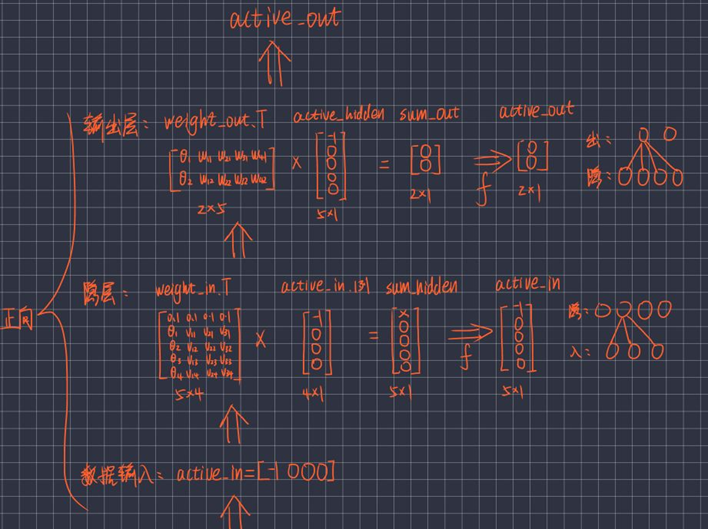
4.2.3 反向传播
#? 构造3层BP神经网络架构
class BP:
#? 误差反向传播
def errorbackpropagate(self,targets,lr,m): # lr 学习效率
if self.num_out==1:
targets=[targets]
if len(targets)!=self.num_out:
raise ValueError("与输出层结点数不符")
# 误差
error=(1/2)*np.dot((targets.reshape(-1,1)-self.active_out).T,
(targets.reshape(-1,1)-self.active_out))
# 输出层 误差信号
self.error_out=(targets.reshape(-1,1)-self.active_out)*DS(self.sum_out) # DS(self.active_out)
# 隐层 误差信号
self.error_hidden=np.dot(self.weight_out,self.error_out)*DS(self.sum_hidden) # DS(self.active_hidden)
# 更新权值
# 隐层
self.weight_out=self.weight_out+lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T+m*self.co
self.co=lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T
# 输入层
self.weight_in=self.weight_in+lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T+m*self.ci
self.ci=lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T
return error
图解:反向传播计算出error_hidden(即eh)、error_out(即gj):

反向传播更新权值,计算出weight_in、weight_out:
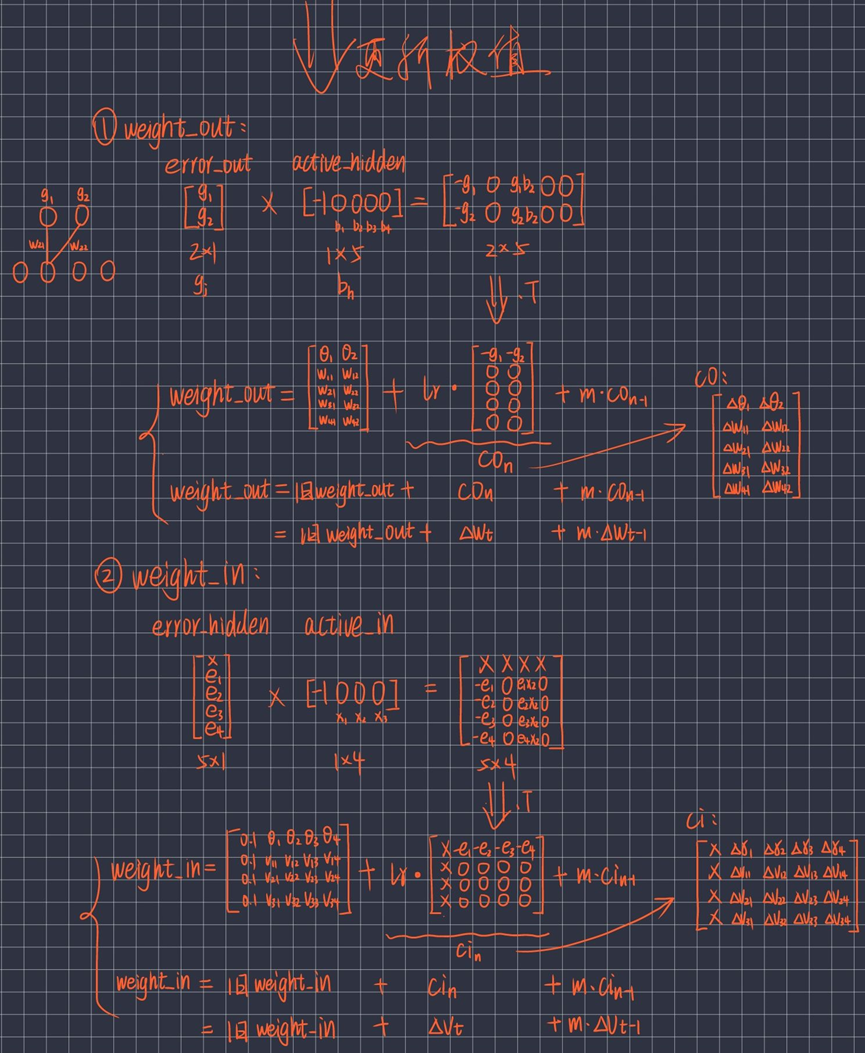
4.2.4 迭代训练
#? 构造3层BP神经网络架构
class BP:
def train(self,pattern,itera=100,lr=0.2,m=0.1):
for i in range(itera):
error=0.0 # 每一次迭代将error置0
for j in pattern: # j为传入数组的第一维数据 #! *2?(1次迭代里面重复两次?)
inputs=j[0:self.num_in-1] # 根据输入层结点的个数确定传入结点值的个数
targets=j[self.num_in-1:] # 剩下的结点值作为输出层的值
self.update(inputs) # 正向传播 更新了active_out
error=error+self.errorbackpropagate(targets,lr,m) # 误差反向传播 计算总误差
if i%10==0:
print("########################误差 %-.5f ######################第%d次迭代" %(error, i))
默认迭代训练100次。
4.3 算法检验——预测数据
#? 算法检验——预测数据D
# X 输入数据;D 目标数据
X = list(np.arange(-1, 1.1, 0.1)) # -1~1.1 步长0.1增加
D = [-0.96, -0.577, -0.0729, 0.017, -0.641, -0.66, -0.11, 0.1336, -0.201, -0.434, -0.5,
-0.393, -0.1647, 0.0988, 0.3072,0.396, 0.3449, 0.1816, -0.0312, -0.2183, -0.3201]
A = X + D # 数据合并 方便处理
patt = np.array([A] * 2) # 2*42矩阵
# 创建神经网络,21个输入节点,13个隐藏层节点,21个输出层节点
bp = BP(21, 13, 21)
# 训练神经网络
bp.train(patt)
# 测试神经网络
d = bp.test(patt)
# 查阅权重值
bp.weights()
import matplotlib.pyplot as plt
fig,ax=plt.subplots(1,3)
ax[0].plot(X, D, label="source data",color='red') # D为真实值
# plt.subplots(212)
ax[1].plot(X, d, label="predict data",color='green') # d为预测值
ax[2].plot(X, D, label="source data",color='red') # D为真实值
# plt.subplots(212)
ax[2].plot(X, d, label="predict data",color='green') # d为预测值
plt.legend()
plt.show()
输入数据为X数据集、预测目标数据为D数据集,经过BP网络后输出的预测数据为d数据集。
最后结果输出形式为终端数据呈现、与可视化图像呈现。
4.4 图解总结
综上图解,各个变量的存在形式如下:
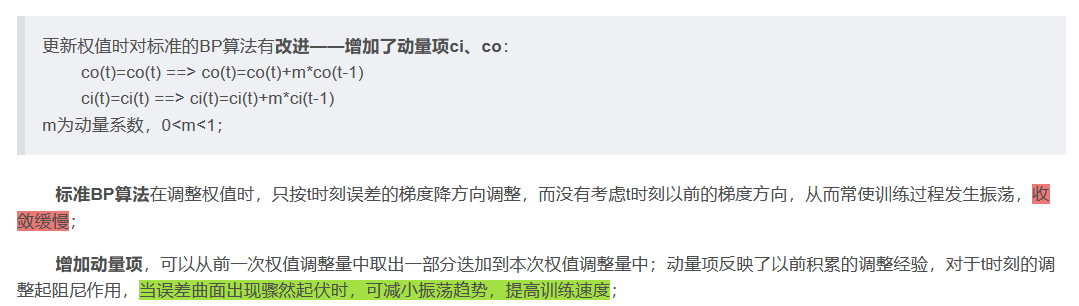
1、权值矩阵:

2、激活矩阵:

3、动量矩阵:
运行结果
1、运行后在终端输出的一部分结果:

“->”左侧为输入的数据xi,“->”右侧为这些数据经过三层感知机后的输出结果yj;

集合D为标准值,可以看到“->”右侧的预测结果和真实值相差很小,说明预测效果较好;
2、下面看一下一些迭代后的误差数据:
我们一共迭代训练了100次,可以看到当训练到90次后,误差已经减小到0.00005,误差极小,也说明预测效果较好;比较这些误差数据发现误差减小的速度很快,说明我们使用改进后的BP算法比较不错;
3、输入层的权值
4、输出层的权值
5、可视化预测值和真实值的差距:
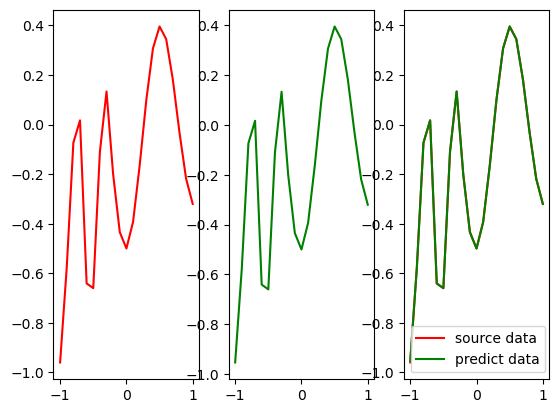
图中其实有两根线,分别为黄线和蓝线,因为预测效果较好导致蓝线不太明显;黄线代表经过三层感知机预测出的数据,蓝线代表真实值,两条曲线拟合度很高说明三层感知机训练效果较好;
整体总结
1、上述为三层的BP神经网络,即三层感知机;
2、此BP网络对标准BP网络进行改进:
总代码
#! BP神经网络(误差逆传播算法)
#! 三层BP神经网络/三层感知机
#? 激活函数sigmoid(x)、及其导数DS(x)
import numpy as np
# 双曲正切函数tanh
def sigmoid(x):
return np.tanh(x)
def DS(x):
return 1 - (np.tanh(x)) ** 2
# 第90次迭代 误差0.00005
#? 生成区间[a,b]内的随机数
import random
def random_number(a,b):
return (b-a)*random.random()+a # random.random()随机生成[0,1)内浮点数
#? 生成一个m*n矩阵,并且设置默认零矩阵
def makematrix(m,n,fill=0.0):
a = []
for i in range(m):
a.append([fill]*n) # 列表1*n会得到一个新列表,新列表元素为列表1元素重复n次。[fill]*3==[fill fill fill]
return np.array(a)
#? 构造3层BP神经网络架构
class BP:
#? 初始化函数:各层结点数、激活结点、权重矩阵、偏差、动量因子
def __init__(self,num_in,num_hidden,num_out):
# 输入层、隐藏层、输出层 的结点数
self.num_in=num_in+1 # 输入层结点数 并增加一个偏置结点(阈值)
self.num_hidden=num_hidden+1 # 隐藏层结点数 并增加一个偏置结点(阈值)
self.num_out=num_out # 输出层结点数
# 激活BP神经网络的所有结点(向量)
self.active_in=np.array([-1.0]*self.num_in)
self.active_hidden=np.array([-1.0]*self.num_hidden)
self.active_out=np.array([1.0]*self.num_out)
# 创建权重矩阵
self.weight_in=makematrix(self.num_in,self.num_hidden) # in*hidden 的0矩阵
self.weight_out=makematrix(self.num_hidden,self.num_out) # hidden*out的0矩阵
# 对权重矩阵weight赋初值
for i in range(self.num_in): # 对weight_in矩阵赋初值
for j in range(self.num_hidden):
self.weight_in[i][j]=random_number(0.1,0.1)
for i in range(self.num_hidden): # 对weight_out矩阵赋初值
for j in range(self.num_out):
self.weight_out[i][j]=random_number(0.1,0.1)
# 偏差
for j in range(self.num_hidden):
self.weight_in[0][j]=0.1
for j in range(self.num_out):
self.weight_out[0][j]=0.1
# 建立动量因子(矩阵)
self.ci=makematrix(self.num_in,self.num_hidden) # num_in*num_hidden 矩阵
self.co=makematrix(self.num_hidden,self.num_out) # num_hidden*num_out矩阵
#? 信号正向传播
def update(self,inputs):
if len(inputs)!=(self.num_in-1):
raise ValueError("与输入层结点数不符")
# 数据输入 输入层
self.active_in[1:self.num_in]=inputs
# 数据在隐藏层处理
self.sum_hidden=np.dot(self.weight_in.T,self.active_in.reshape(-1,1)) # 叉乘
# .T操作是对于array操作后的数组进行转置操作
# .reshape(x,y)操作是对于array操作后的数组进行重新排列成一个x*y的矩阵,参数为负数表示无限制,如(-1,1)转换成一列的矩阵
self.active_hidden=sigmoid(self.sum_hidden) # active_hidden[]是处理完输入数据之后处理,作为输出层的输入数据
self.active_hidden[0]=-1
# 数据在输出层处理
self.sum_out=np.dot(self.weight_out.T,self.active_hidden)
self.active_out=sigmoid(self.sum_out)
# 返回输出层结果
return self.active_out
#? 误差反向传播
def errorbackpropagate(self,targets,lr,m): # lr 学习效率
if self.num_out==1:
targets=[targets]
if len(targets)!=self.num_out:
raise ValueError("与输出层结点数不符")
# 误差
error=(1/2)*np.dot((targets.reshape(-1,1)-self.active_out).T,
(targets.reshape(-1,1)-self.active_out))
# 输出层 误差信号
self.error_out=(targets.reshape(-1,1)-self.active_out)*DS(self.sum_out) # DS(self.active_out)
# 隐层 误差信号
self.error_hidden=np.dot(self.weight_out,self.error_out)*DS(self.sum_hidden) # DS(self.active_hidden)
# 更新权值
# 隐层
self.weight_out=self.weight_out+lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T+m*self.co
self.co=lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T
# 输入层
self.weight_in=self.weight_in+lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T+m*self.ci
self.ci=lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T
return error
#? 测试
def test(self,patterns):
for i in patterns: # i为传入数组的第一维数据
print(i[0:self.num_in-1],"->",self.update(i[0:self.num_in-1]))
return self.update(i[0:self.num_in-1]) # 返回测试结果,用于作图
#? 权值
def weights(self):
print("输入层的权值:")
print(self.weight_in)
print("输出层的权值:")
print(self.weight_out)
def train(self,pattern,itera=100,lr=0.2,m=0.1):
for i in range(itera):
error=0.0 # 每一次迭代将error置0
for j in pattern: # j为传入数组的第一维数据
inputs=j[0:self.num_in-1] # 根据输入层结点的个数确定传入结点值的个数
targets=j[self.num_in-1:] # 剩下的结点值作为输出层的值
self.update(inputs) # 正向传播 更新了active_out
error=error+self.errorbackpropagate(targets,lr,m) # 误差反向传播 计算总误差
if i%10==0:
print("########################误差 %-.5f ######################第%d次迭代" %(error, i))
#? 算法检验——预测数据D
# X 输入数据;D 目标数据
X = list(np.arange(-1, 1.1, 0.1)) # -1~1.1 步长0.1增加
D = [-0.96, -0.577, -0.0729, 0.017, -0.641, -0.66, -0.11, 0.1336, -0.201, -0.434, -0.5,
-0.393, -0.1647, 0.0988, 0.3072,0.396, 0.3449, 0.1816, -0.0312, -0.2183, -0.3201]
A = X + D # 数据合并 方便处理
patt = np.array([A] * 2) # 2*42矩阵
# 创建神经网络,21个输入节点,13个隐藏层节点,21个输出层节点
bp = BP(21, 13, 21)
# 训练神经网络
bp.train(patt)
# 测试神经网络
d = bp.test(patt)
# 查阅权重值
bp.weights()
import matplotlib.pyplot as plt
fig,ax=plt.subplots(1,3)
ax[0].plot(X, D, label="source data",color='red') # D为真实值
# plt.subplots(212)
ax[1].plot(X, d, label="predict data",color='green') # d为预测值
ax[2].plot(X, D, label="source data",color='red') # D为真实值
# plt.subplots(212)
ax[2].plot(X, d, label="predict data",color='green') # d为预测值
plt.legend()
plt.show()










