一、声音基础
1.1 音量
声音振幅的大小
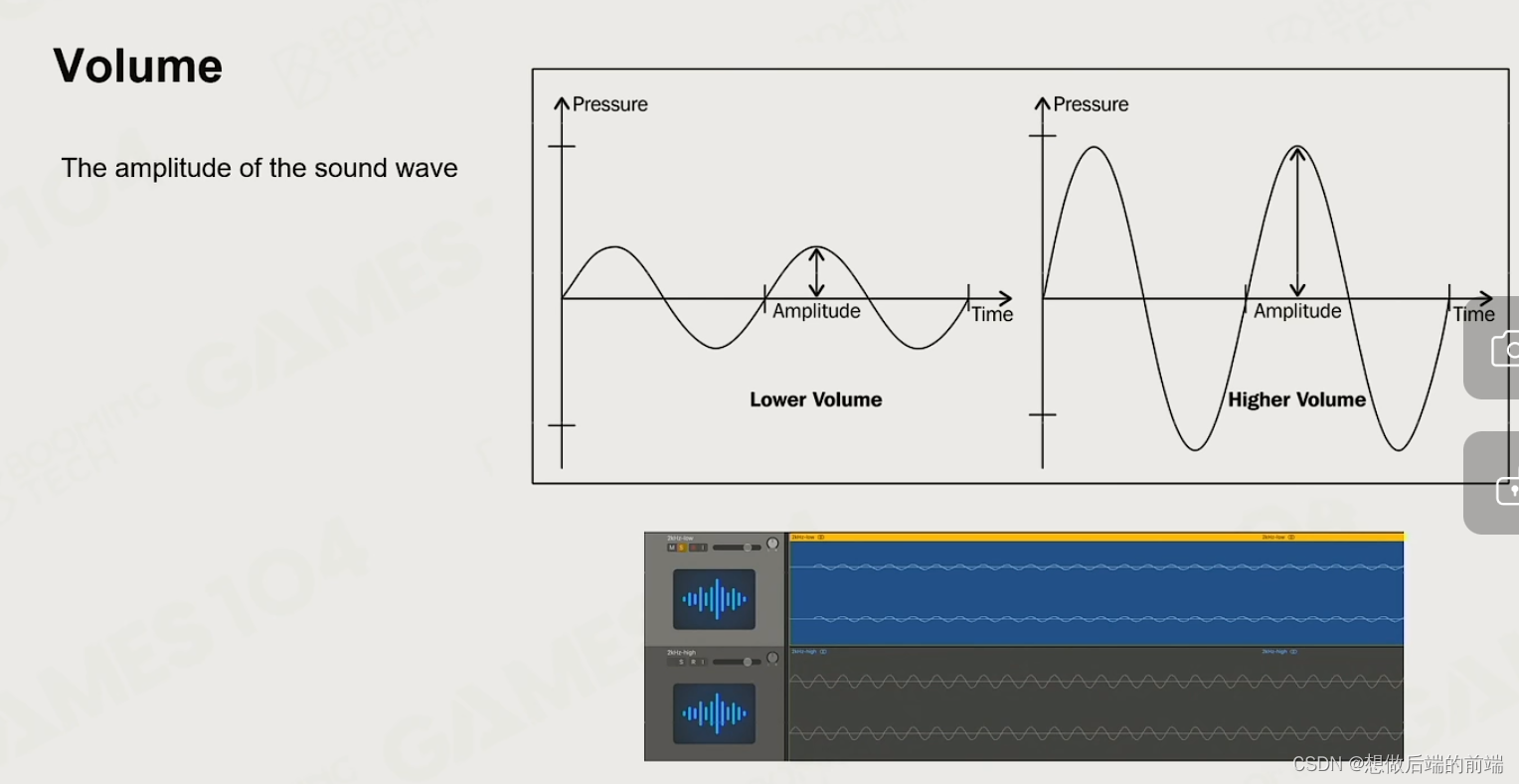
压强p:由声音引起的与环境大气压的局部偏差


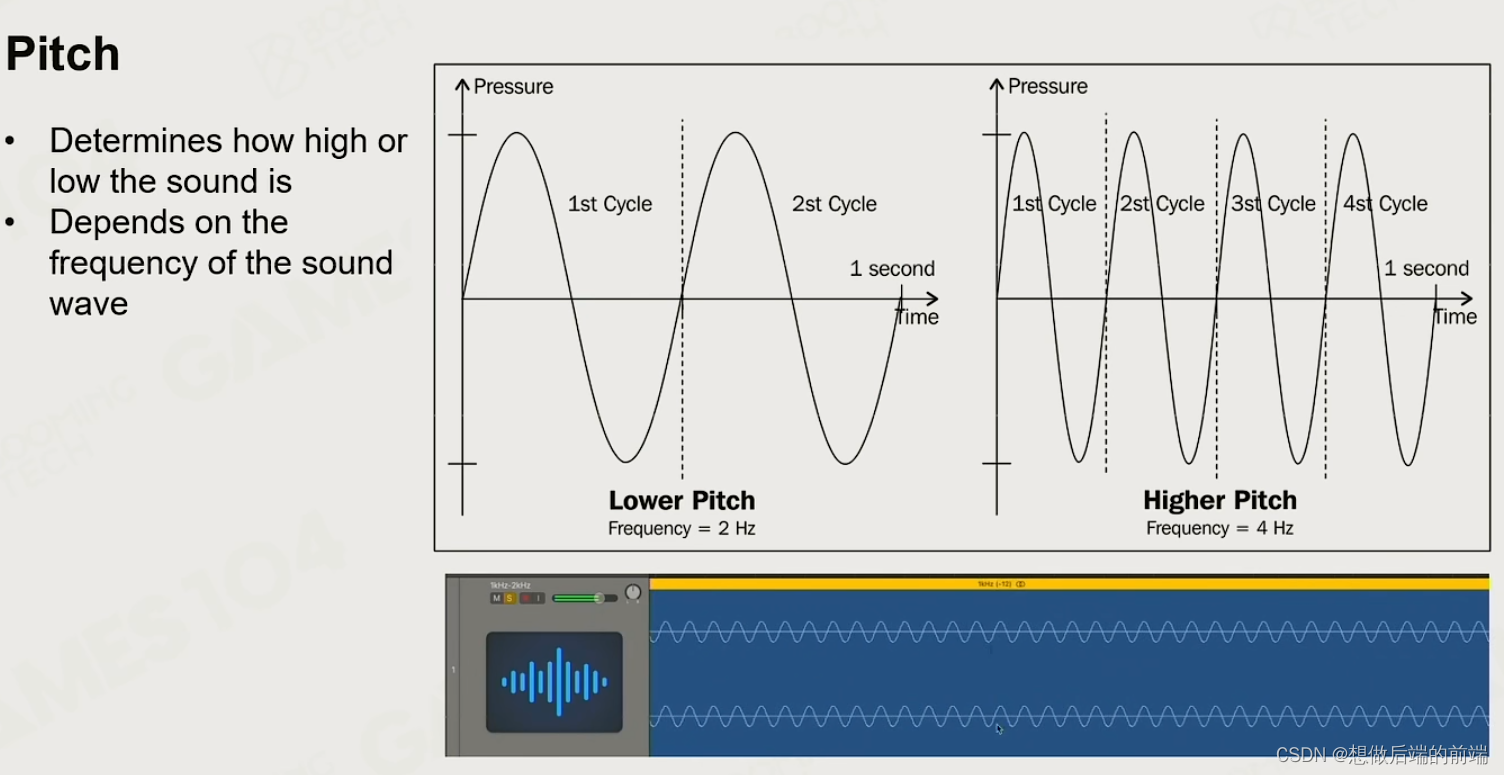
1.2 音调
1.3 音色

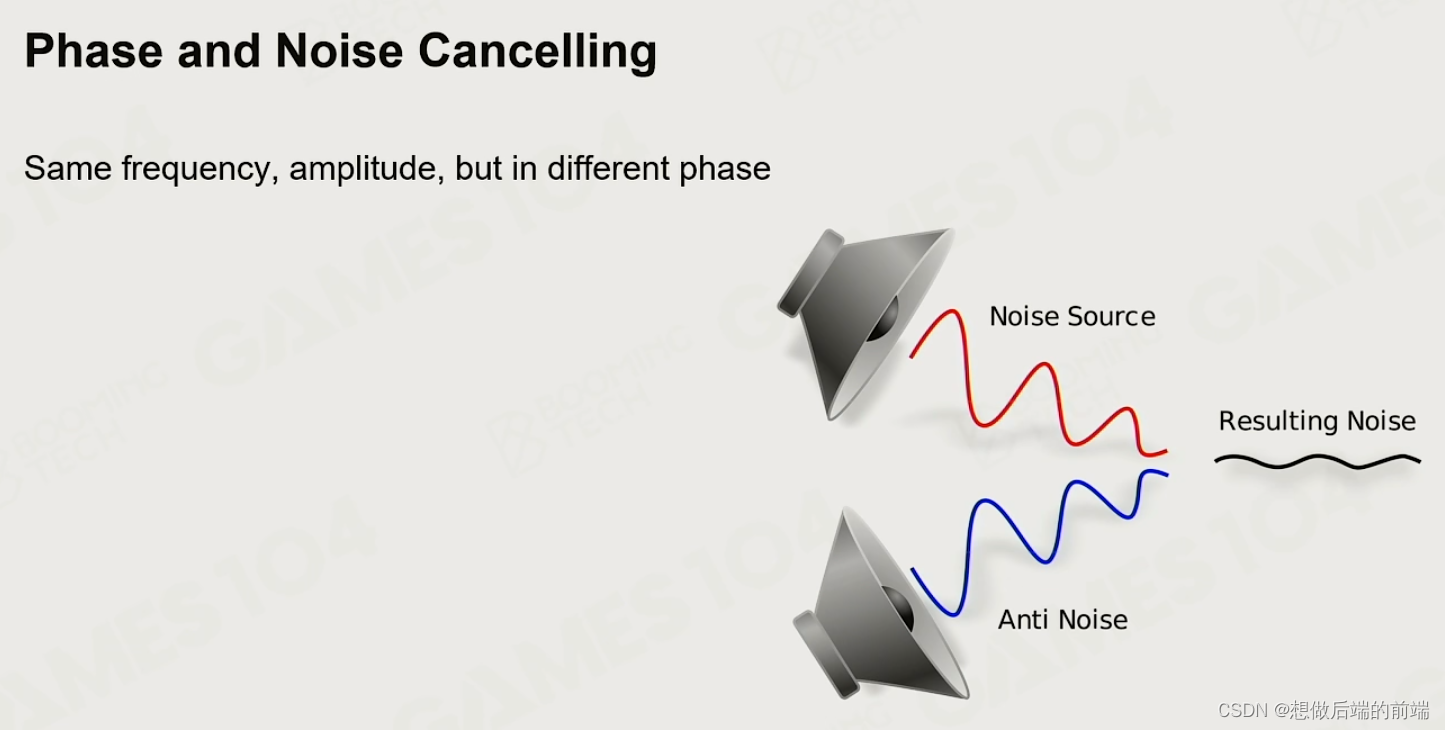
1.4 降噪
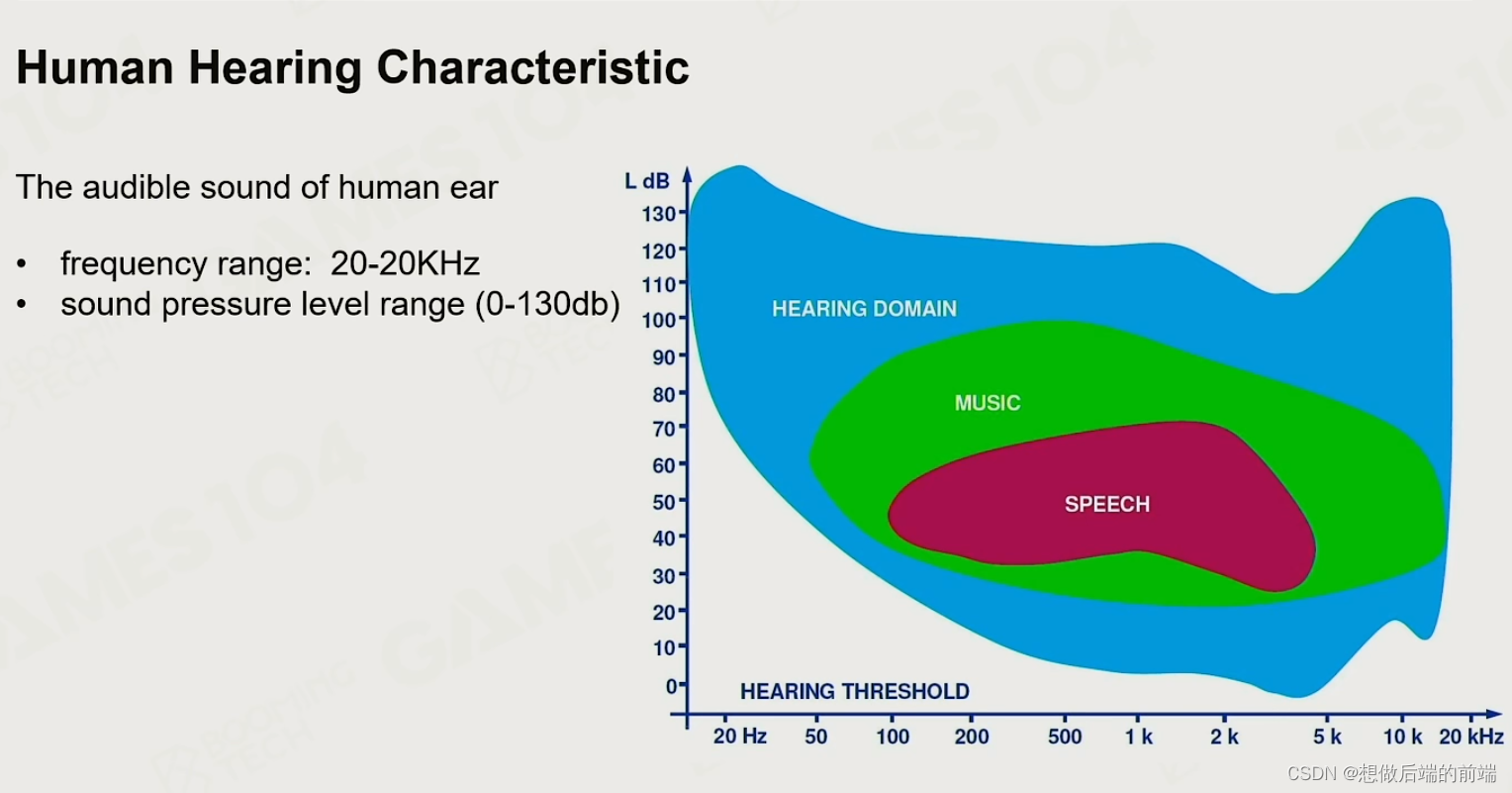
1.5 人的听觉范围
1.6 电子音乐
将自然界中连续的音乐转换成离散的信号记录到内存中
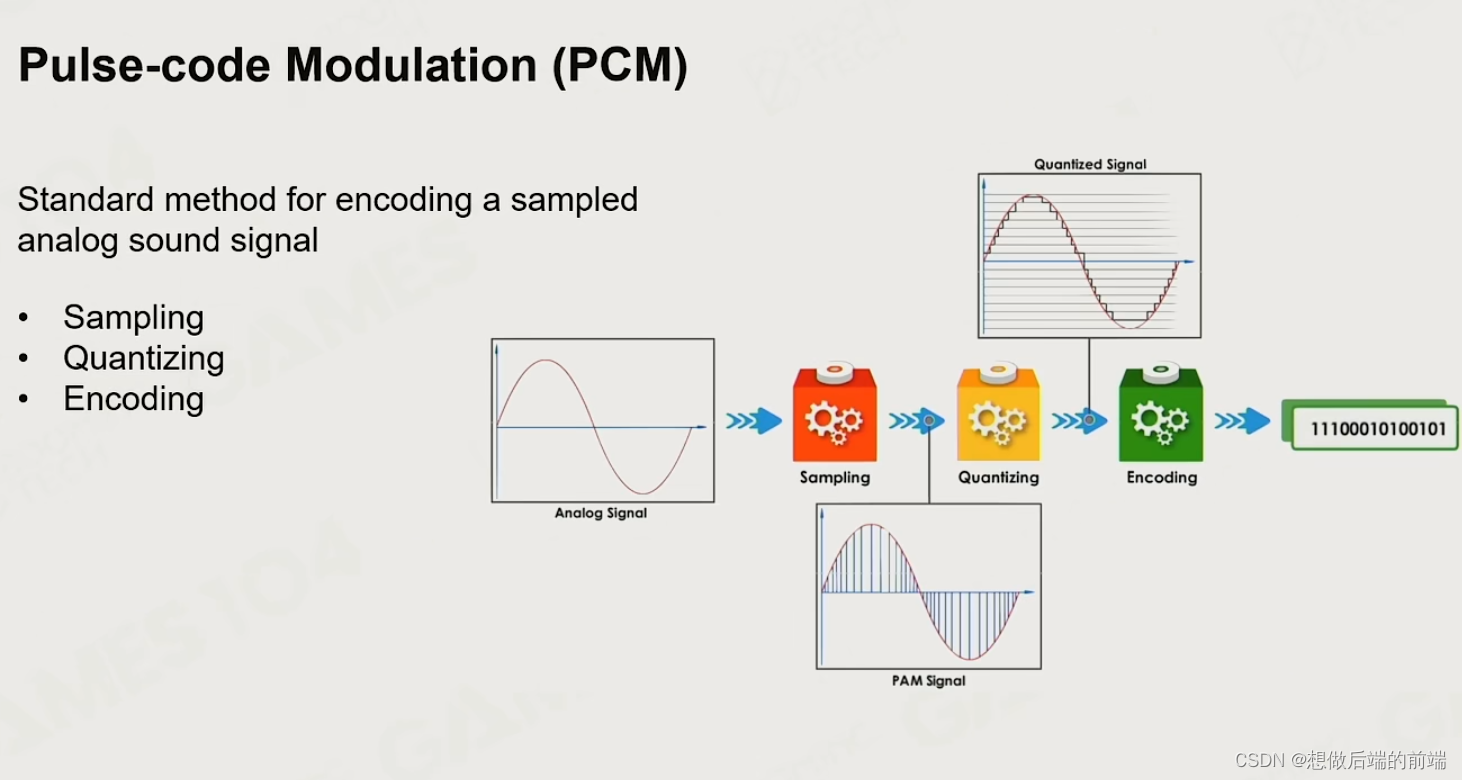
采样 - 量化 - 编码
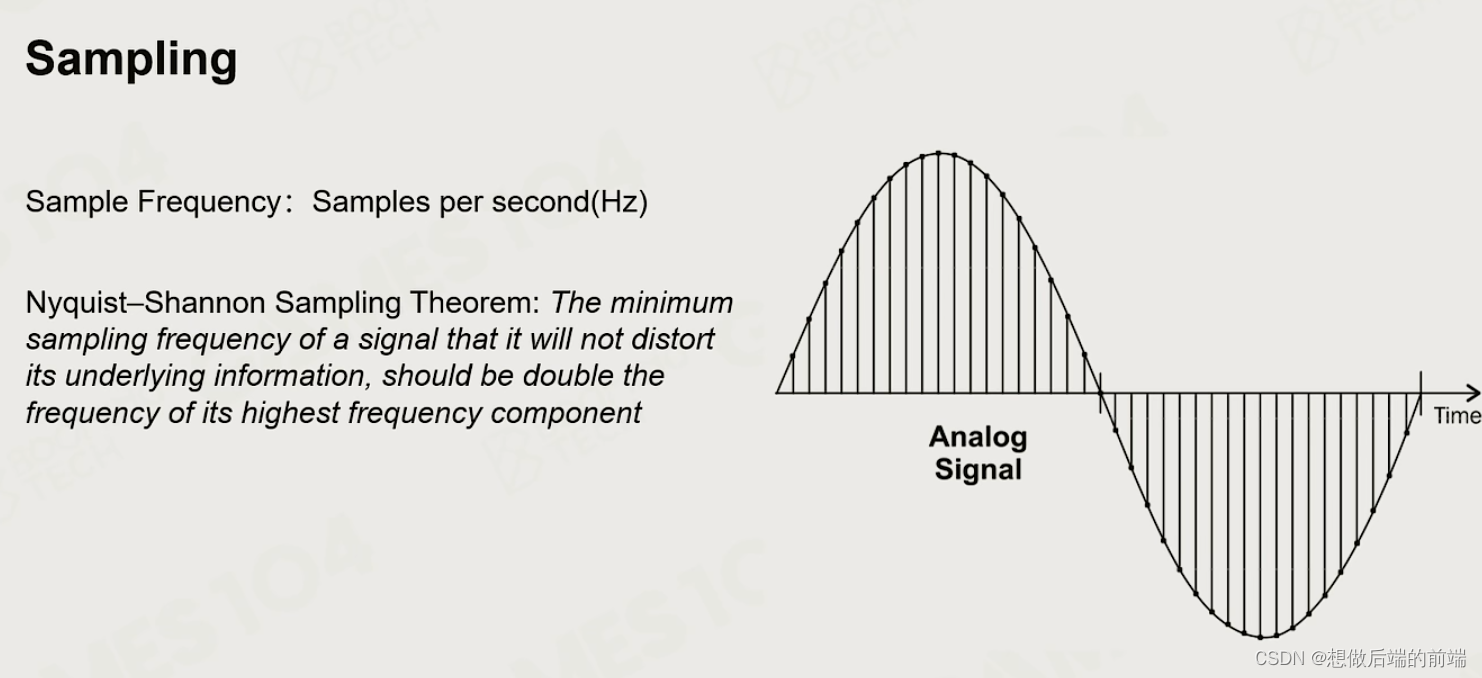
采样:
量化:

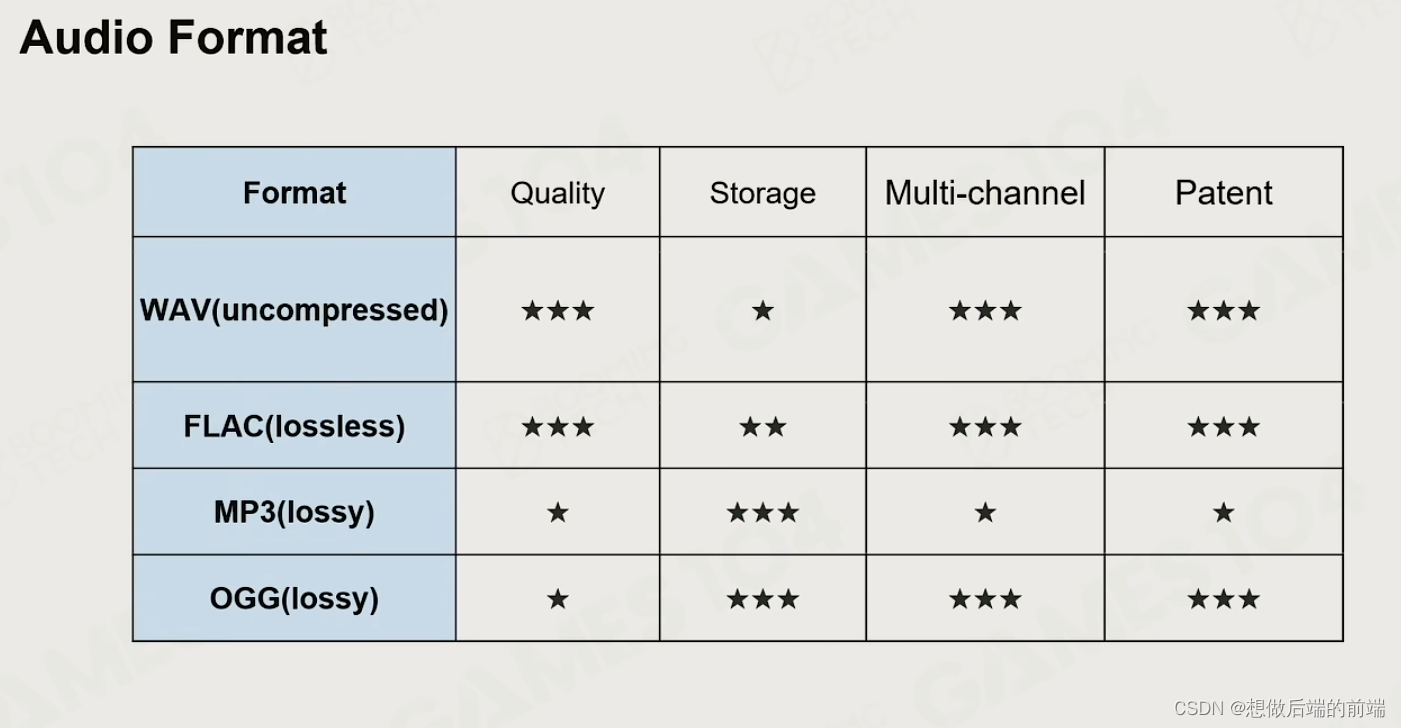
编码格式:
二、三维音频渲染
三维场景中有无数的声源,每个声源从不同的方向,不同的距离表现的效果都不一样。

2.1 Listener
位置:一般放在摄像机和人物中间。不放在摄像机身上是因为当人物离开时仍然能听到声音;不放到人物身上的原因是当视野离开后,仍然能听到声音。这两种情况都不合理。
速度:多普勒效应
朝向:不同的朝向效果也不一样

2.2 空间化
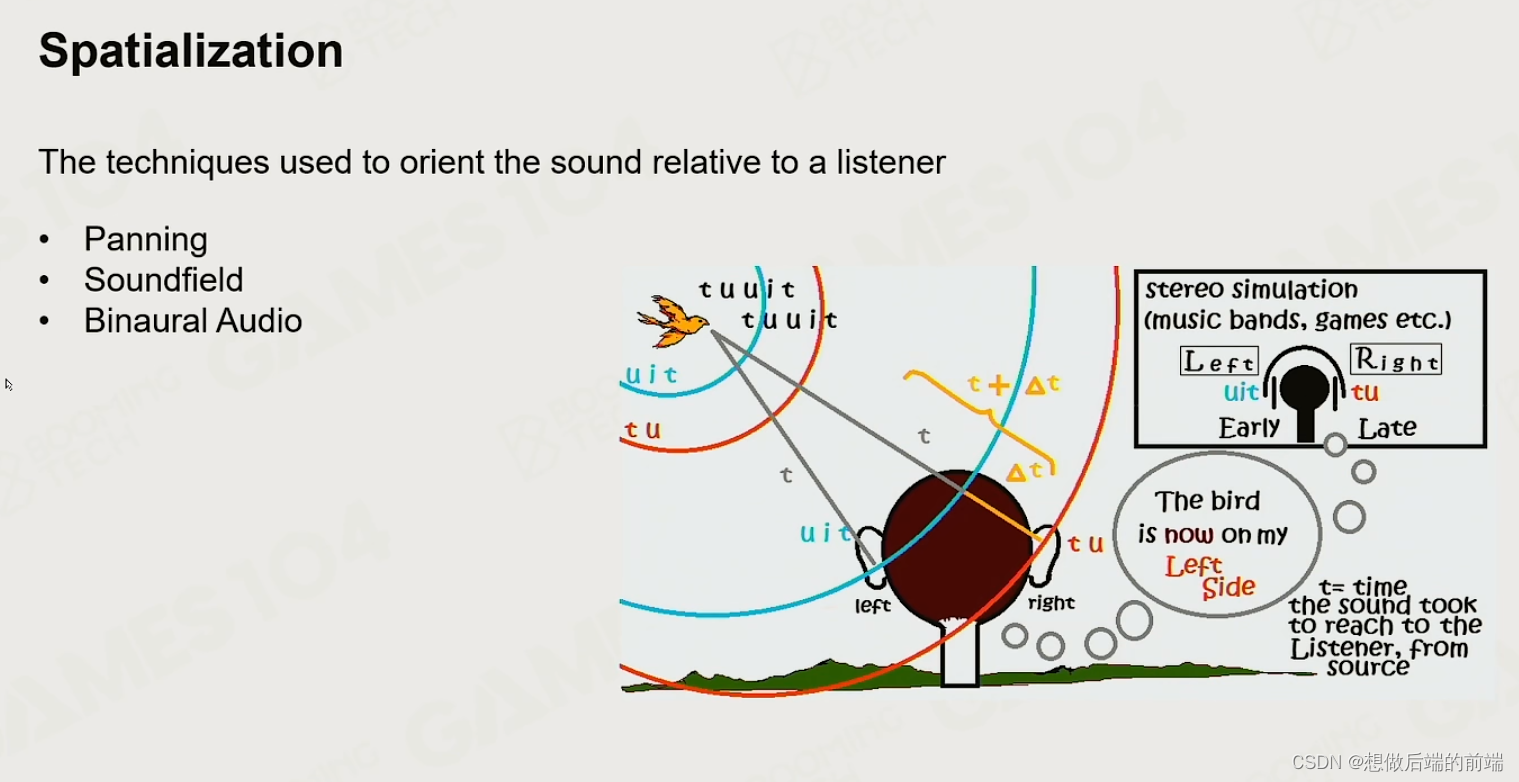
到达左右耳的时间,方向都会影响音效的空间感。(听声辨位)
2.3 Panning
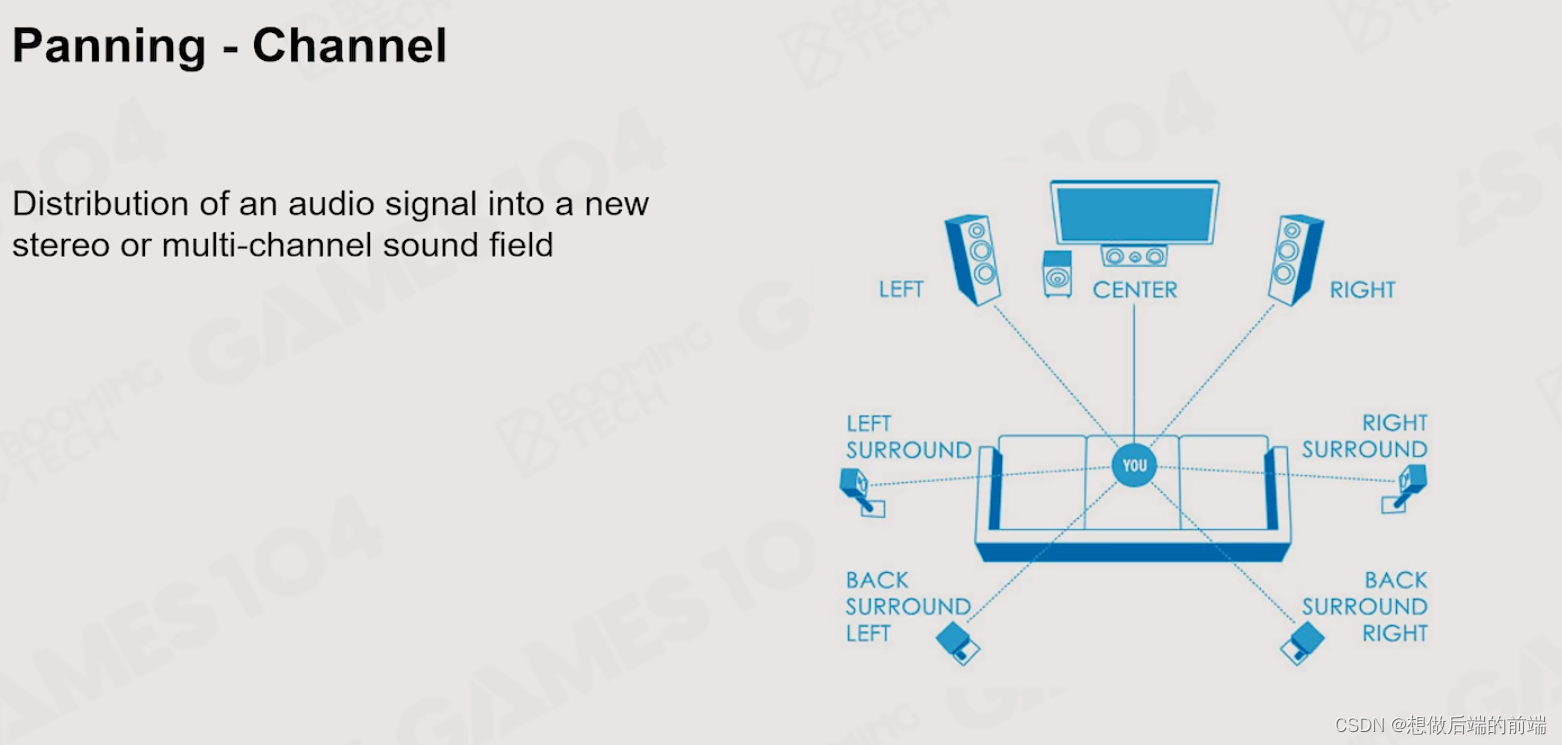
通过移动声源位置,模拟声音的变化。


但是当声音移动到两耳中间的时候,听到声音会变小
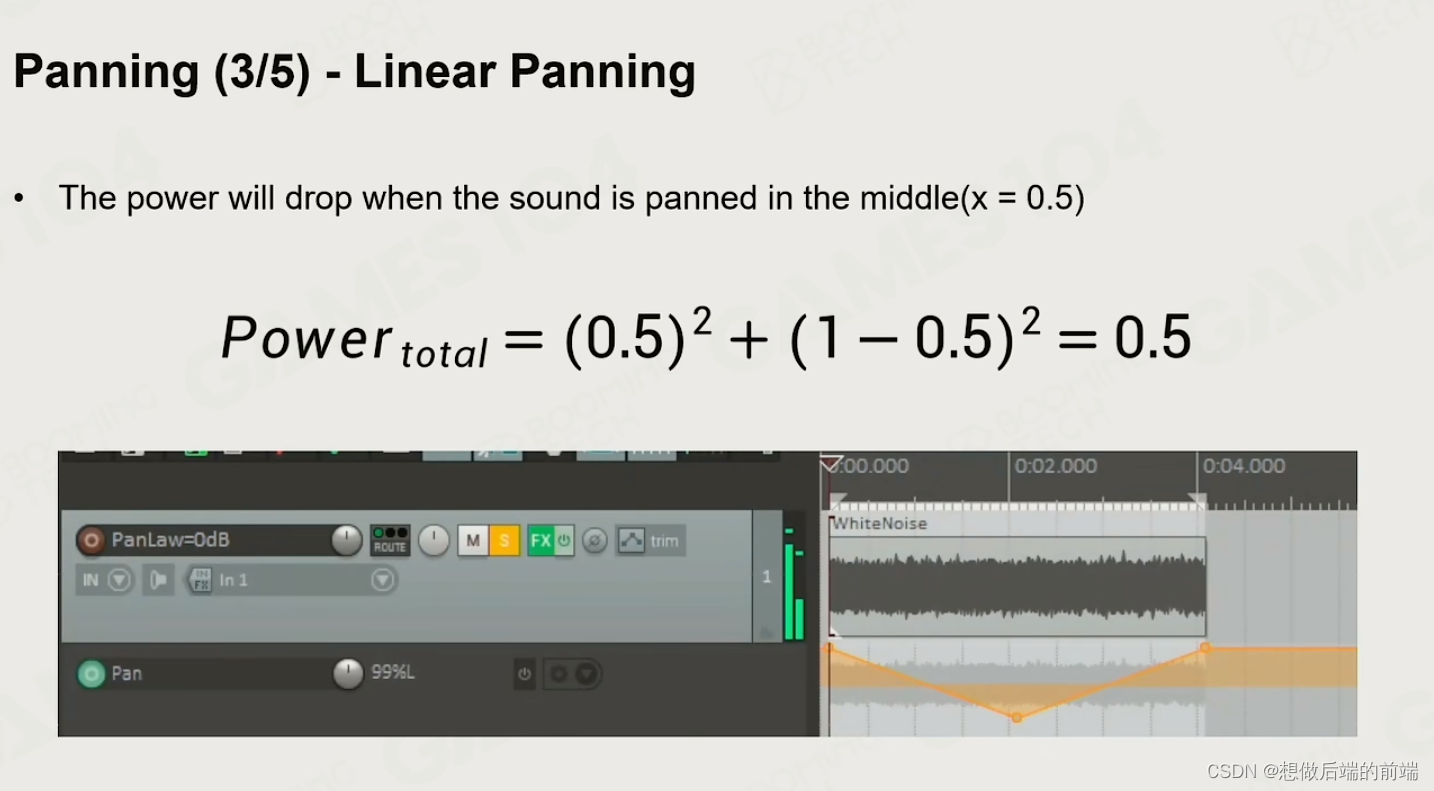
添加sin,cos解决这个问题

这样的话在声音移动的时候就可以保证听到的音量大小保持不变。
2.4 声音的衰弱
高频的声音衰减的快,低频的声音衰减的慢
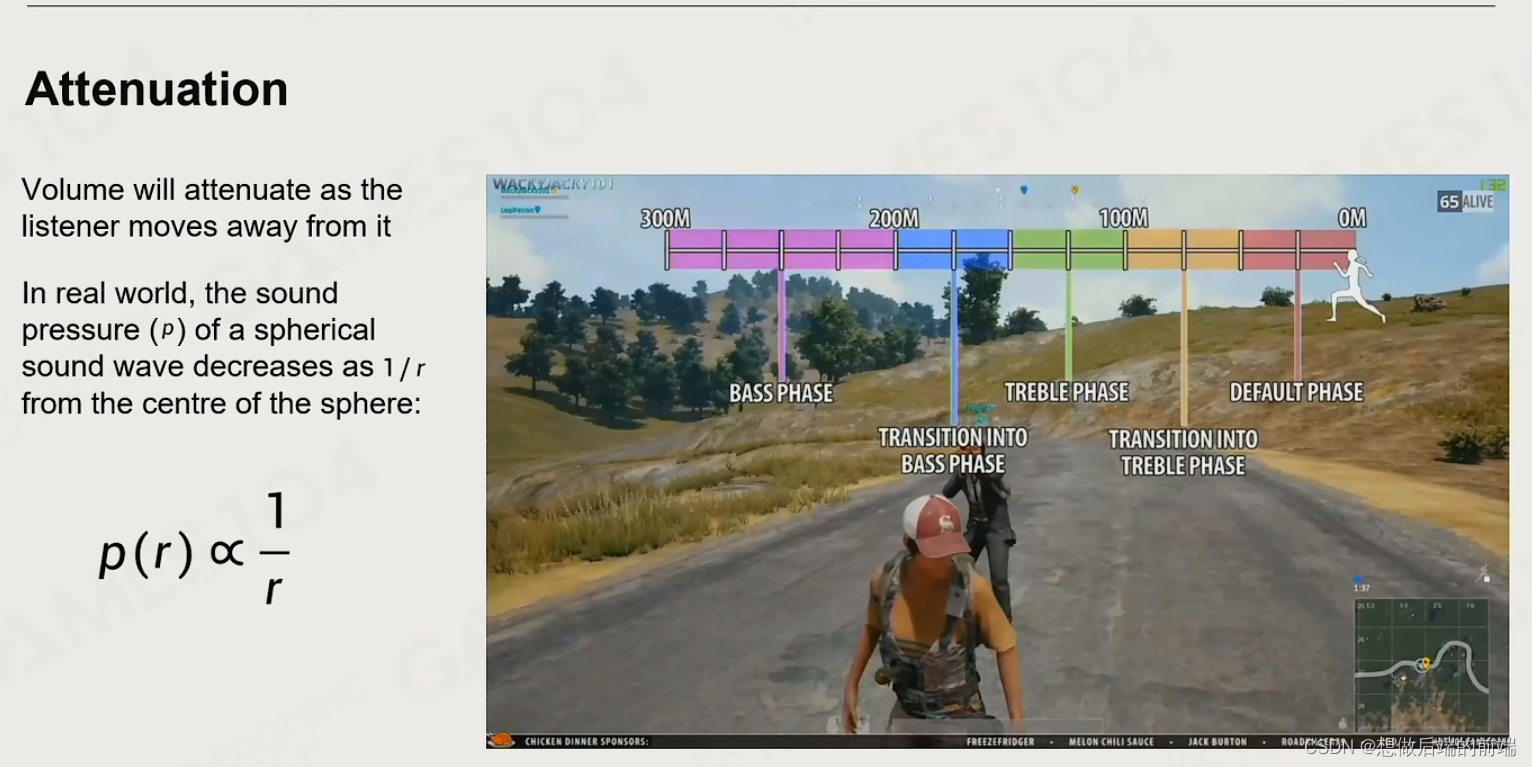
通过在不同的频率之间插值计算,就可以体现出你距离声源的远近。

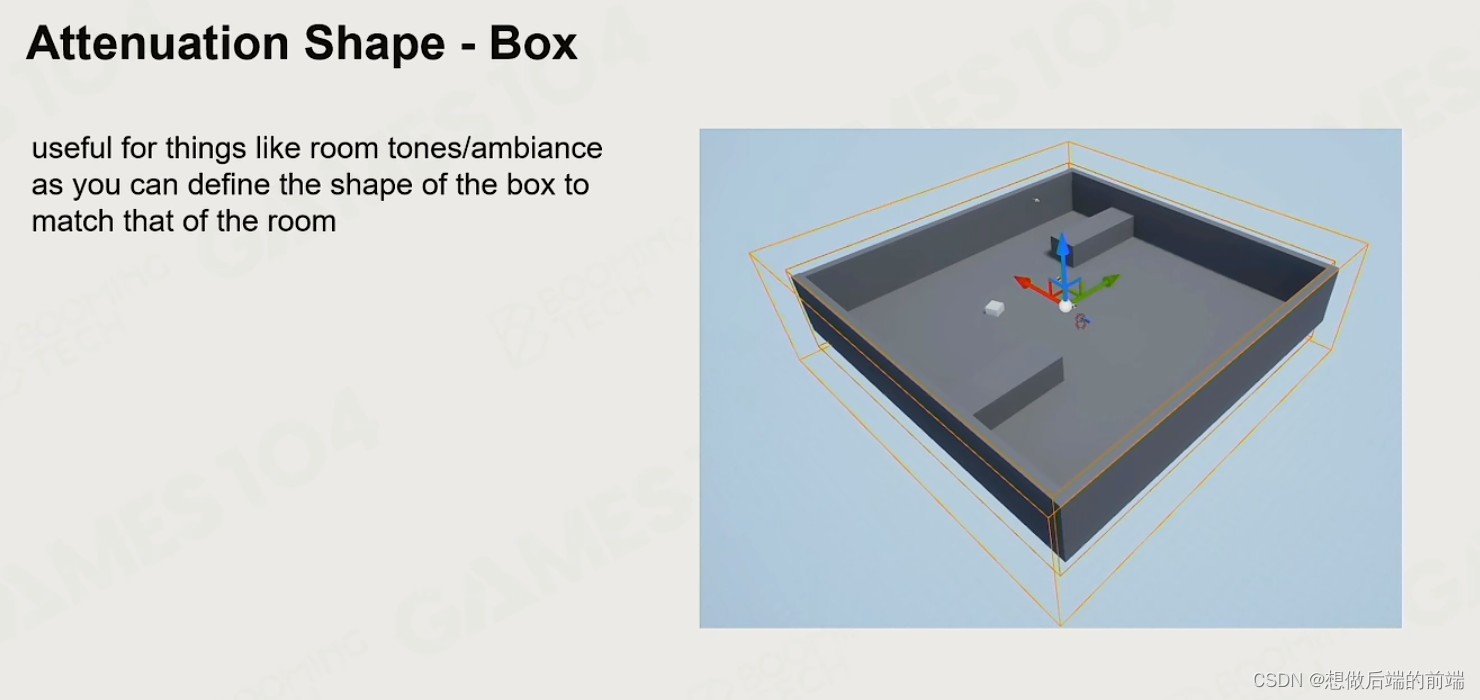
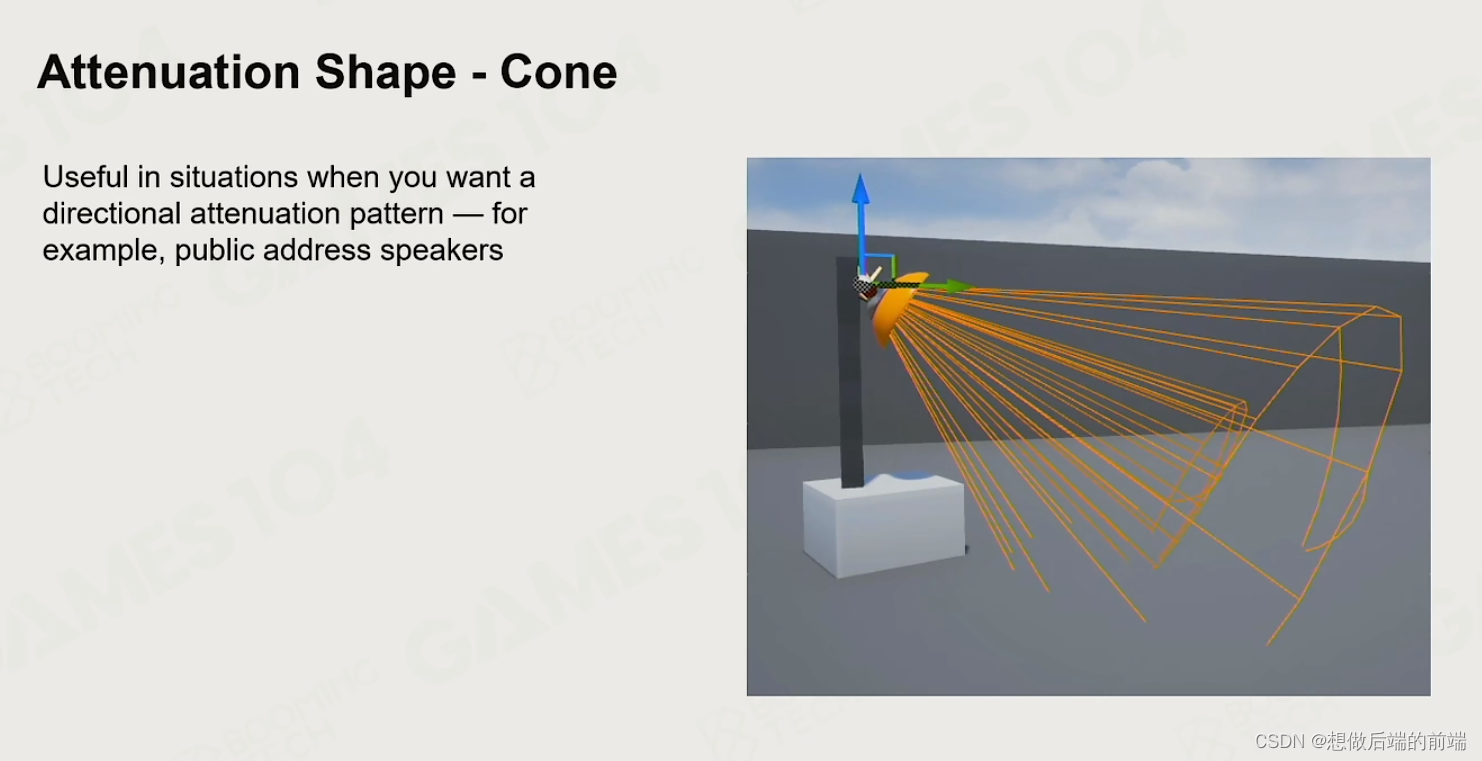
2.5声音的阻挡
声音是通过波的形式传播的
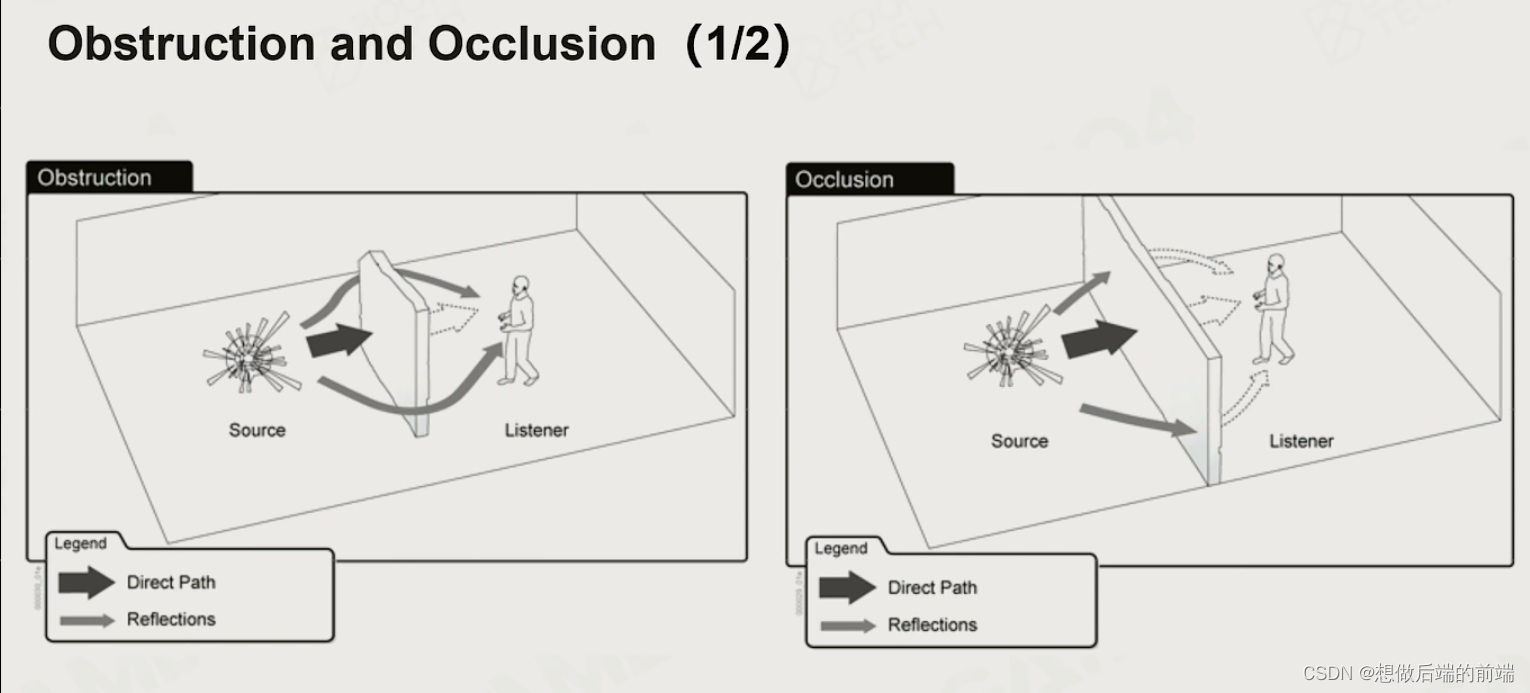
利用射线来计算声音的遮挡。

2.6 混响
回响-声音的反弹
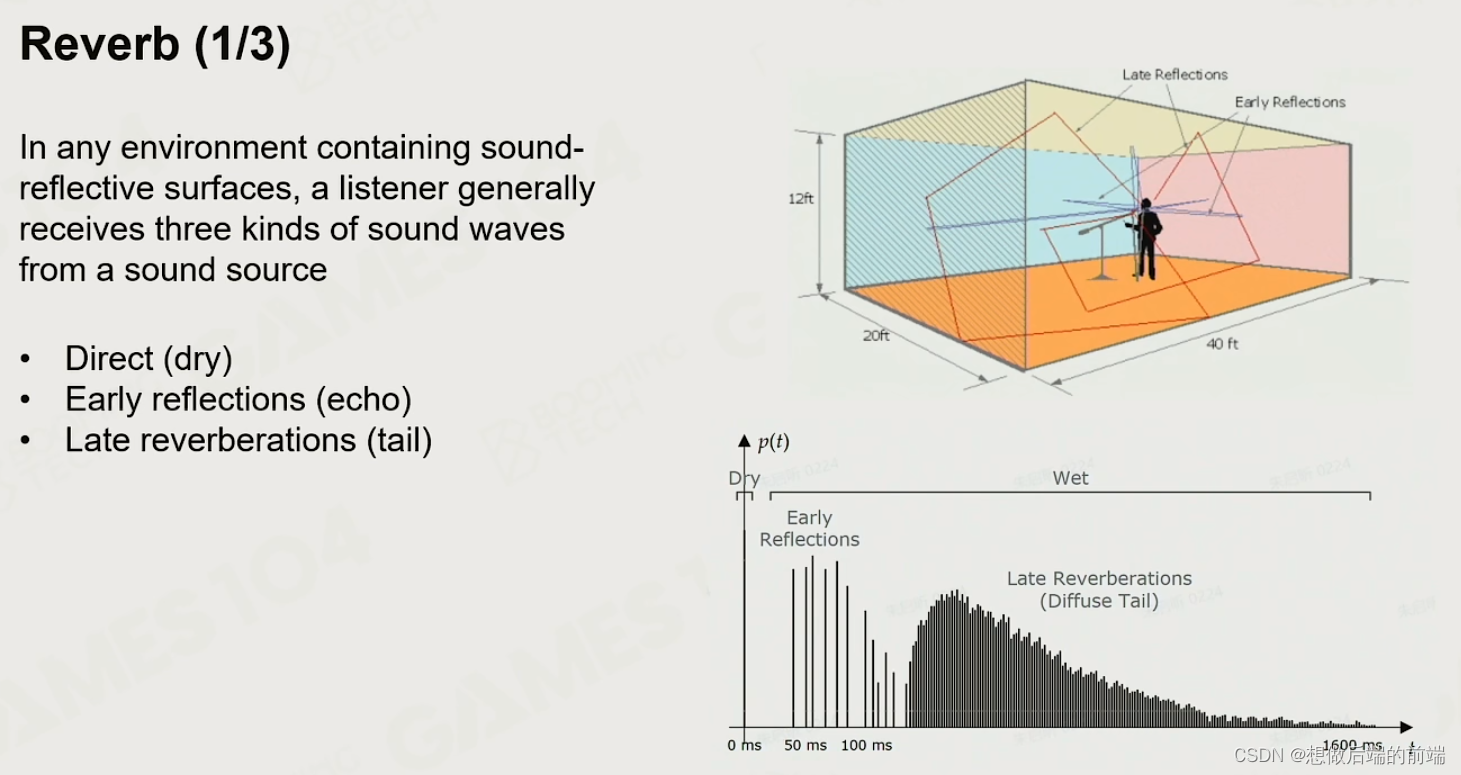
不同的材质对声音的吸收也不同
在浴室中唱歌好听的原因:浴室空间小混响效果好

2.7 多普勒效应
多普勒效应(Doppler effect)是波源与观察者有相对运动时,观察者接受到波的频率与波源发出的频率并不相同的现象。生活中比较常见的例子是远方急驶过来的火车鸣笛声变得尖细(即频率变高,波长变短),而离我们而去的火车鸣笛声变得低沉(即频率变低,波长变长),这就是多普勒效应现象,同样的现象也发生在私家车鸣响与火车的敲钟声,音频参见[声的多普勒效应]。而关于频率和波长的直观感受如下图所示(来自wiki)。












