笔摔坏了
在一个阳光明媚的早晨,我愉快的奋笔疾书,抄写默写着单词“abandon”,喝水的时候,水性笔顺着桌子掉落到地上,我心里一紧,颤颤巍巍的弯腰捡起来,在纸上写个字,发现果然笔尖果然摔坏了。没办法,只能掏出C++primeplus,复习一下什么是类,然后运用脑袋里为数不多的知识写了一个默写单词cpp。
- 编译环境:Visual Studio 2022
提供两个路径:
直接使用版😋
仔细学习版😋
===============
1.直接使用版😋(文件+使用规范)
(1)文件
头文件 word.h
#include<iostream>
#include<new>
#include<stdio.h>
#include<cstring>
#include <stdlib.h>
#include<time.h>
#pragma warning (disable:4996)
using namespace std;
typedef struct Word //存储单词的类型
{
char str_EN[20]; //英文的记录
char str_CH[10][20]; //一个英文可能有很多中文意思
int CHcount; //中文翻译的个数,比如tone的英文意思有色调也有声调
Word()
{
memset(str_EN, 0, sizeof str_EN);
memset(str_CH, 0, sizeof str_CH);
CHcount = 0;
}
}Word;
typedef struct mWord //记录默写错误的单词
{
int mistake[100];
int len; //默写错误单词的个数
mWord()
{
memset(mistake, 0, sizeof mistake);
len = 0;
}
}mWord;
class WordWork //主体类
{
private: //私有成员(单词指针,单词个数)
Word* pp;
mWord misword; //默写错误的单词
int length; //单词个数
public:
WordWork() //初始化成员,为什么misword不需要初始化?实际上执行“mWord misword”这句话的时候就初始化了,mWord有自己的构造函数
{
pp = NULL;
length = 0;
};
bool Muen(); //菜单
bool Dynamic_GetSpace(FILE* fp);
bool Get_inCPP(); //将单词从文件放入数组
bool test(); //测试单词
bool testMis(); //测试错误单词
bool Wordcmp(char* w, int p_c); //判断是否默写正确
int CmpCH(const string s, int p_c); //判断中文意思对没对
int Get_point(); //打分
void Print(); //打印所有单词
void PrintMis(); //打印错误的单词
~WordWork() //析构函数
{
delete[]pp;
}
};
bool WordWork::Dynamic_GetSpace(FILE* fp) //动态开辟数组
{
char temp[50];
while (fgets(temp, 50, fp) != NULL) //先一行一行读取单词,目的不是将单词提取出来,目的是看有多少单词,然后开辟数组
{
length++;
}
pp = new Word[length];
for (int i = 0; i < length; i++) //初始化单词,此时单词还没有读入,单纯开辟空间,所有待会文件指针fp需要重新指向文件开头
{
memset(pp[i].str_CH, 0, sizeof pp[i].str_CH);
memset(pp[i].str_EN, 0, sizeof pp[i].str_EN);
}
return true;
}
int WordWork::CmpCH(const string s, int p_c) //s是中文串,p_c是pp的下标
{
int rightCount = 0;
int i, j;
for (i = 0; i < pp[p_c].CHcount; i++)//因为s只是一个中文串,即一个中文意思,那么就需要对pp对应下标的所有中文意思都进行一个判断,有一个正确就正确
{
for (j = 0; j < s.length(); j++)
{
if (s[j] != pp[p_c].str_CH[i][j])break;
}
if (j == s.length()) //说明s和pp[p_c].str_CH[i]完全匹配,此时注意,可能pp后面还有字符,即有可能s=="我",pp=="我是"
{
if (pp[p_c].str_CH[i][j] == '\0')rightCount++;
}
}
return rightCount;
}
int WordWork::Get_point() //计算得到的分数
{
return (100 - misword.len * 2);
}
bool WordWork::Wordcmp(char* w, int p_c) //k==1,英文 p_c表示pp的下标,w是默写的字符串
{
if (w[0] >= 'a' && w[0] <= 'z') //很明显默写的英文
{
int i = 0;
while (w[i] != '\0' && pp[p_c].str_EN[i] != '\0' && w[i] == pp[p_c].str_EN[i])
{
i++;
}
if (w[i] != '\0' || pp[p_c].str_EN[i] != '\0')
{
return false;
}
}
else //默写的中文,那么可能一个单词有好几个中文意思,就需要更加复杂的判断了,这里规定有一个意思默写正确就算正确
{
int rightCount = 0; //正确的中文意思个数
string t = ""; //将字符串w复制道t,因为t是已经配置好的字符串类模板,更加好使用
for (int i = 0; w[i] != '\0'; i++)
t += w[i];
//考虑到可能默写的中文有好几个意思,每个意思中间用','分隔。
string s = ""; //s用来记录t中的某一段字符串来判断是否正确
for (int i = 0; i < t.length(); i++) //这里仔细看有一个小巧妙,我自己定义的遇到','表示收集完一个中文意思,但是如果没有','呢?所以for循环外面还要判断一次
{
if (t[i] == -93 && t[i + 1] == -84) //遇到,表示收集完一个中文意思
{
rightCount += CmpCH(s, p_c); //然后看看这个收集到的中文意思是否存在
s = "";
i++; //需要多一次i++,跳到t[i+1]后面,即跳过逗号
}
else
s += t[i];
}
if (s.length() != 0) //收集最后一个中文意思(包含两种情况,本来就只有一个意思,那么很显然自然也是最后一个。有多个意思,而这个是最后一个)
{
rightCount += CmpCH(s, p_c);
}
return rightCount == 0 ? false : true;
}
return true;
}
bool WordWork::Muen()
{
int choice = 1;
while (choice != 4)
{
cout << "*********1.默写单词 2.存入单词 3.打印单词 4.退出*********\n";
cin >> choice;
switch (choice)
{
case 1:
{ //先将文件数据存入数组,然后使用哈希表和随机种子函数打乱单词,最后默写
test();
break;
}
case 2: //读文件,按行读取文件
{
Get_inCPP(); //从文件获得单词到cpp程序
break;
}
case 3: //打印单词
{
Print();
break;
}
case 4:
break;
default:
{
choice = 1;
break;
}
}
}
return true;
}
void WordWork::Print() //打印单词
{
for (int i = 0; i < length; i++)
{
printf("(%d) %s: ", i + 1, pp[i].str_EN);
//cout << "(" << i + 1 << ") " << pp[i].str_EN;
for (int j = 0; j < pp[i].CHcount; j++)
{
if (j == pp[i].CHcount - 1)cout << pp[i].str_CH[j];
else
printf("%s,", pp[i].str_CH[j]);
//cout << pp[i].str_CH[j];
}
cout << endl;
}
cout << endl;
}
void WordWork::PrintMis() //打印错误的单词
{
cout << "你默写错误的单词是:\n";
for (int i = 0; i < misword.len; i++)
{
printf("(%d)%s:", i + 1, pp[misword.mistake[i]].str_EN); //默写英文
for (int j = 0; j < pp[misword.mistake[i]].CHcount - 1; j++) //默写中文
{
printf("%s,", pp[misword.mistake[i]].str_CH[j]);
}
printf("%s\n", pp[misword.mistake[i]].str_CH[pp[misword.mistake[i]].CHcount - 1]);
}
cout << endl << endl;
}
bool WordWork::Get_inCPP() //从文件中读取单词,按照行读入
{
//(1)打开文件夹(存入单词的文件夹)
char str[20];
memset(str, 0, sizeof str);
cout << "输入文件名:";
getchar();
cin.getline(str, 20);
FILE* fp = fopen(str, "r+");
rewind(fp);
if (!fp)
{
cout << "文件打开失败!\n";
return false;
}
if (feof(fp))
{
cout << "文件是空的!\n";
return false;
}
//(2)开辟数组空间,用于存储文件夹内单词信息(中文意思,英文意思)
Dynamic_GetSpace(fp); //动态开辟空间
rewind(fp); //将fp重新指向文件夹起始位置
char temp[50];
memset(temp, 0, sizeof temp);
int p_i = -1; //当前行,为什么是-1,因为下面while内第一句就是p_i++,由于数组下标从0开始,所以先设置-1
//(3)
//每一行的规则: 英文 空格若干 中文,中文,中文 换行符"\n"
while (fgets(temp, 50, fp) != NULL) //按照行读入 (乱七八糟一堆,目的就是把单词存入数组以便操作)
{
p_i++;
int t_i = 0; //从文件读入单词字符
int E_i = 0; //英文的下标
//区分一下,一个英文只有一个英文,但是一个英文有多个中文意思
int C_j = 0; //第j个中文
int C_j_i = 0;//第j个中文下标
//按照每一行的书写规则,一一读取字符
while (temp[t_i] != ' ') //空格的asciil码是32
{
pp[p_i].str_EN[E_i] = temp[t_i];
E_i++;
t_i++;
}
while (temp[t_i] == ' ')
t_i++;
while (temp[t_i] != '\0')
{
//说明一下:中文里面逗号的ascill码是"-93和-84"(每个中文都由两个char决定)
while ((temp[t_i] != -93 || temp[t_i + 1] != -84) && temp[t_i] != '\n') //只要不是遇到逗号或者换行符,就读入
{
pp[p_i].str_CH[C_j][C_j_i] = temp[t_i];
C_j_i++;
t_i++;
}
while (temp[t_i] == -93 && temp[t_i + 1] == -84)
{
t_i += 2;
C_j++;
C_j_i = 0;
}
if (temp[t_i] == '\n')
{
t_i++;
C_j++;
};
}
pp[p_i].CHcount = C_j;
memset(temp, 0, sizeof temp);
}
if (feof(fp) != 0) //关闭文件,用完就关
{
fclose(fp);
return true;
}
else //提示文件没有读完,感觉这句话不需要
{
fclose(fp);
cout << "文件没有走到末尾!\n";
return false;
}
}
bool WordWork::test() //用时间种子函数随机生成下标,按顺序存入哈希表,然后按照哈希表下表默写单词
{
//时间种子
time_t t;
t = time(0);
srand(t);
//哈希表1
int* Hash = new int[length];
int Ha_c = 0;
for (int i = 0; i < length; i++)Hash[i] = -1;
//哈希表2
int* vis = new int[length]; //vis记录哪些下标被用过
for (int i = 0; i < length; i++)vis[i] = -1;
for (int i = 0; i < length; i++)
{
int k = rand() % length;
while (vis[k] != -1)k = (k + 1) % length;
vis[k] = 1;
Hash[Ha_c++] = k;
}
cout << "\n\n\n\n\n\n\n\n*********************!!开始默写!!*************************\n"
<< "****************************************\n******************************************\n\n\n";
t = time(0); //使用随机函数来交替默写英文中文
srand(t);
for (int i = 0; i < length; i++)
{
char w[50];
memset(w, 0, sizeof w);
int k = rand() % 2;
if (k == 1) //默写英文
{
cout << "(" << i + 1 << "):";
for (int j = 0; j < pp[Hash[i]].CHcount; j++)
{
if (j == pp[Hash[i]].CHcount - 1)cout << pp[Hash[i]].str_CH[j] << " ";
else
printf("%s,", pp[Hash[i]].str_CH[j]);
//cout << pp[i].str_CH[j];
}
cin >> w;
}
else //默写中文
{
cout << "(" << i + 1 << "):" << pp[Hash[i]].str_EN << " ";
cin >> w;
}
cout << endl;
//记录下错误的单词
if (!Wordcmp(w, Hash[i])) //如果单词默写错误,那么将错误的单词的下标存入misword
{
misword.mistake[misword.len] = Hash[i];
misword.len++;
}
if (w[0] == '0')break; //中途退出,不写了
}
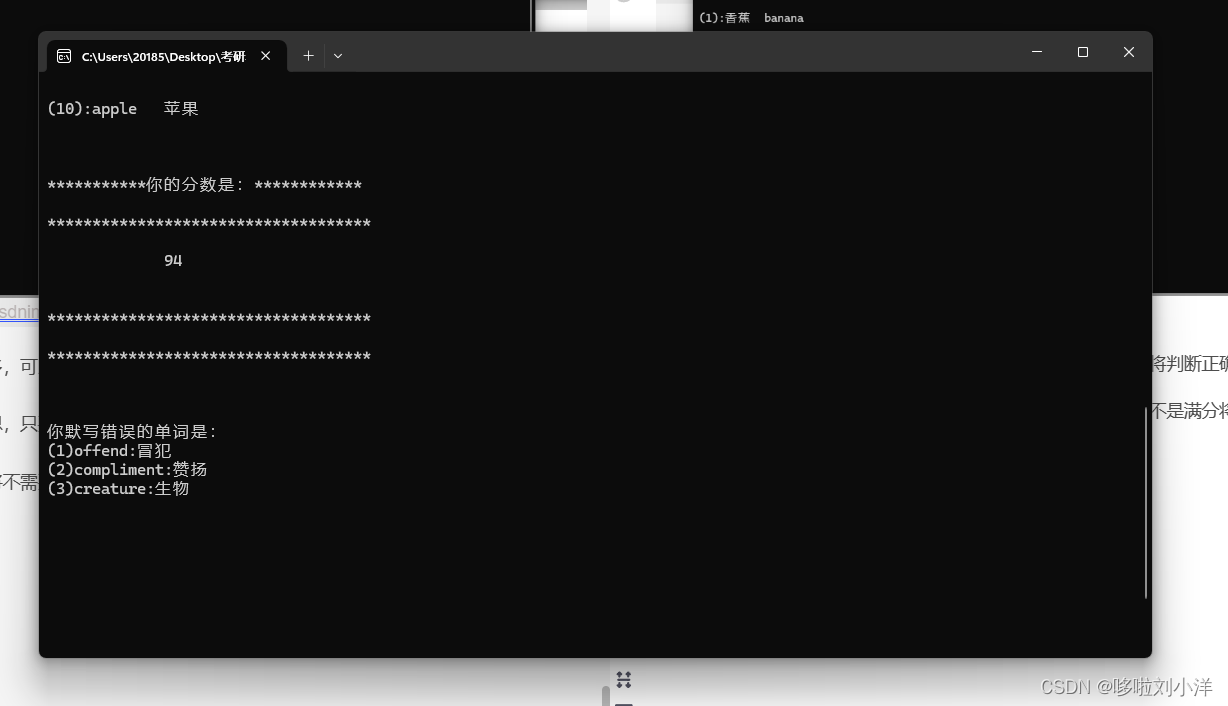
cout << "\n\n***********你的分数是:************\n\n************************************\n\n " << Get_point() << endl << "\n\n************************************\n\n************************************\n\n";
cout << endl << endl;
testMis();
delete[]Hash;
delete[]vis;
return true;
}
bool WordWork::testMis() //默写错误的单词
{
while (misword.len != 0) //没有全部默写对不让走!!
{
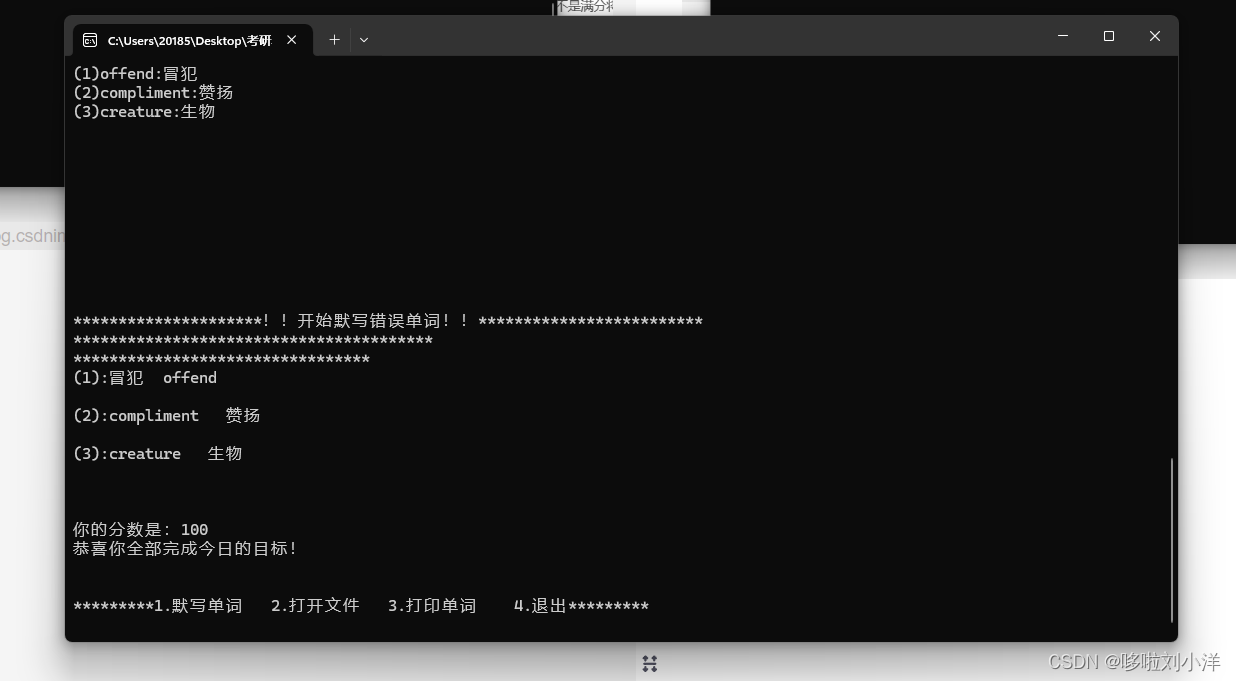
PrintMis(); //先输出默写错误的单词小看一下
time_t t;
t = time(0);
srand(t);
int hash[100];
int ha_c = 0;
memset(hash, 0, sizeof hash);
cout << "\n\n\n\n\n\n\n\n*********************!!开始默写错误单词!!*************************\n"
<< "****************************************\n*********************************\n";
for (int i = 0; i < misword.len; i++)
{
char w[20];
memset(w, 0, sizeof w);
int k = rand() % 2;
if (k == 1) //默写英文
{
cout << "(" << i + 1 << "):";
for (int j = 0; j < pp[misword.mistake[i]].CHcount; j++)
{
if (j == pp[misword.mistake[i]].CHcount - 1)cout << pp[misword.mistake[i]].str_CH[j] << " ";
else
printf("%s,", pp[misword.mistake[i]].str_CH[j]);
//cout << pp[i].str_CH[j];
}
cin >> w;
}
else //默写中文
{
cout << "(" << i + 1 << "):" << pp[misword.mistake[i]].str_EN << " ";
cin >> w;
}
cout << endl;
//记录下错误的单词
if (!Wordcmp(w, misword.mistake[i])) //如果单词默写错误,那么将错误的单词的下标存入misword
{
hash[ha_c] = misword.mistake[i];
ha_c++;
}
}
for (int i = 0; i < ha_c; i++)
misword.mistake[i] = hash[i];
misword.len = ha_c;
cout << "\n\n你的分数是:" << Get_point() << endl;
}
cout << "恭喜你全部完成今日的目标!\n\n\n";
return true;
}
主文件 wordmain.cpp
#include"word.h"
#include<iostream>
#include<cstring>
#include <stdlib.h>
#pragma warning (disable:4996)
using namespace std;
int main()
{
WordWork op;
op.Muen();
return 0;
}
(2)使用规范
首先抱歉,代码写的很乱,很难看。
1:打开项目的文件夹,在名字为项目文件名字的文件夹里面创建txt文档

2: 创建txt文档,命名day1,2,3,4,,以此类推,这是我的习惯。
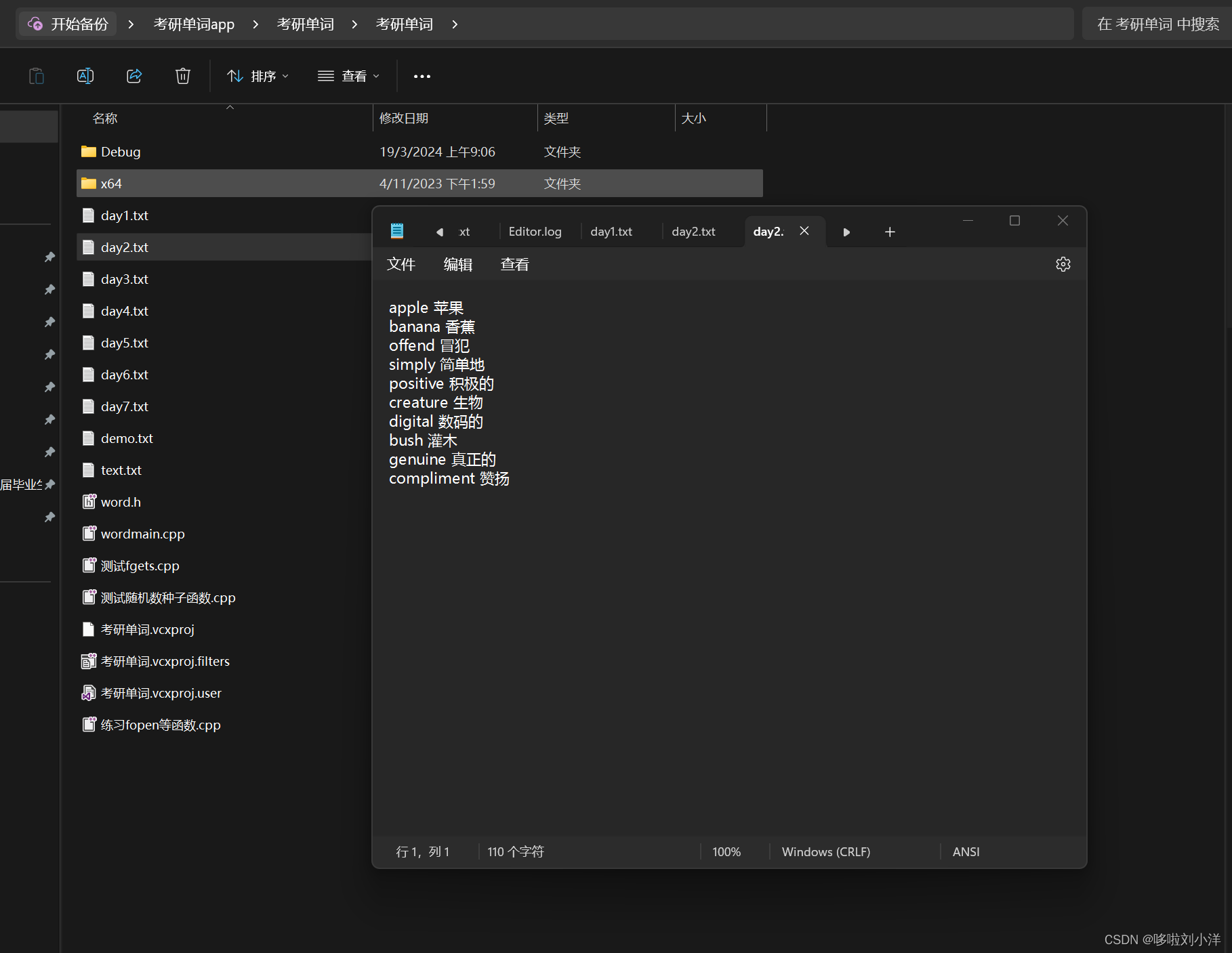
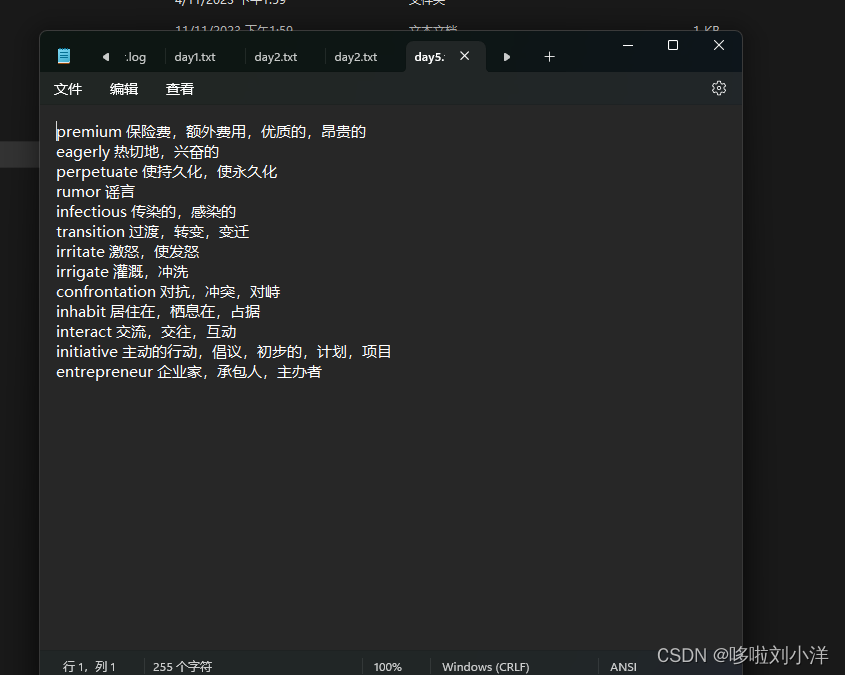
3:将要默写的单词按照图中格式写进txt文档,格式是:英文+空格+中文+“,”+中文+“,”+…+换行符(回车)
4:注意逗号是中文下的逗号
5:不要添加多的符合,比如句号感叹号
6:点击保存
7:打开项目,点击运行。将会弹出这个页面:
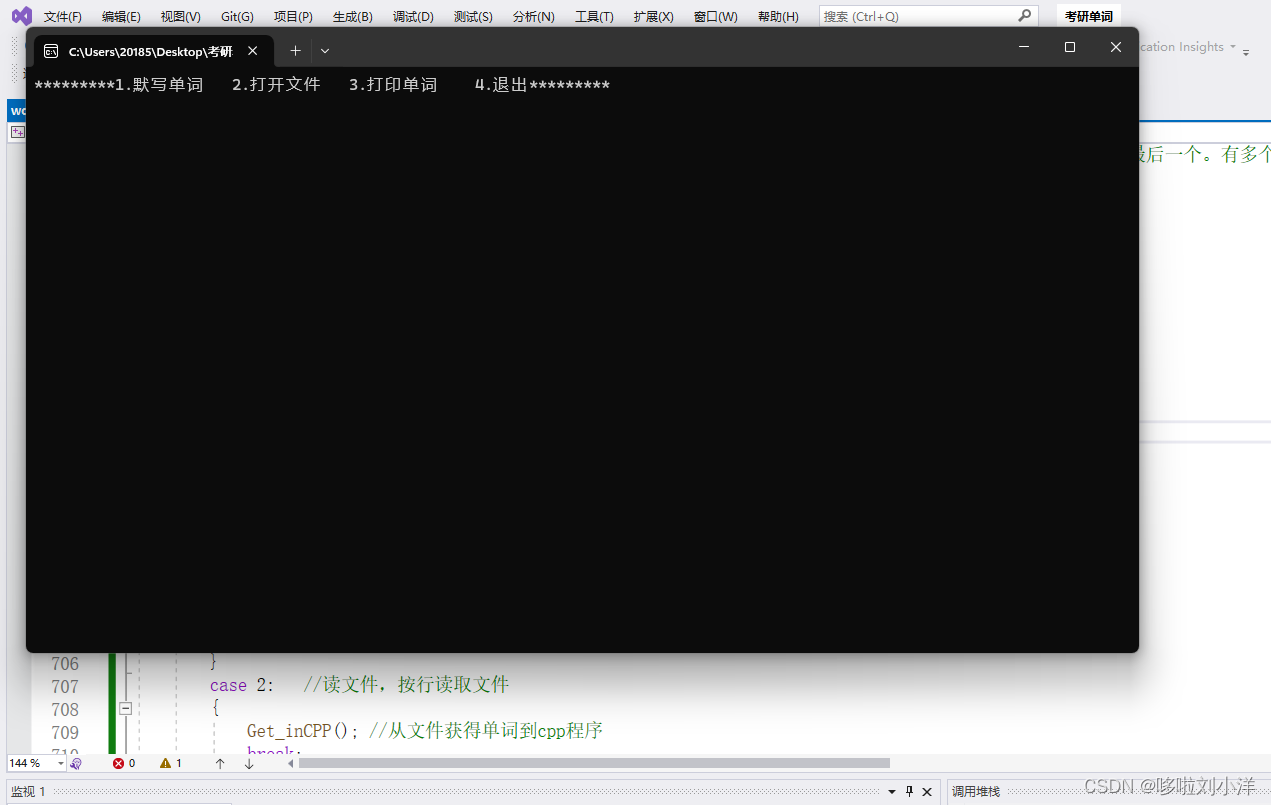
8:输入数字2,输入文件名,由于之前是将txt文件放入项目文件内,所以不需要添加多余路径,这是“相对路径”。不懂什么是“相对路径”和“绝对路径”的可以取了解一下。
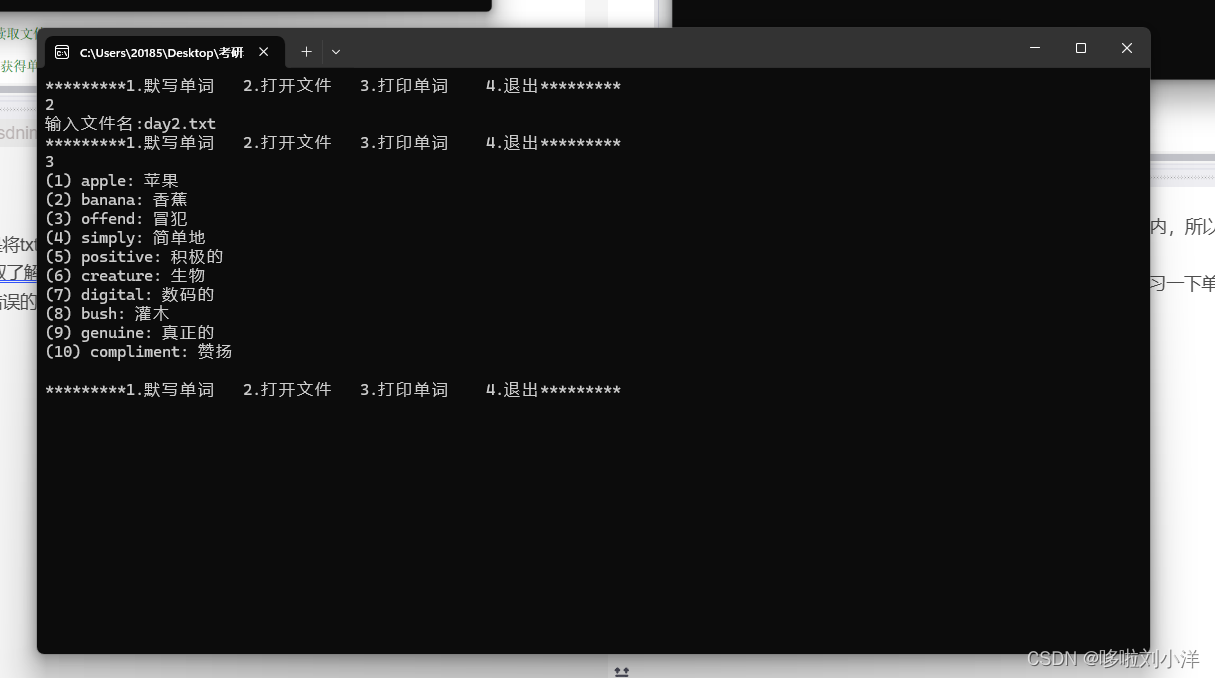
9:输入数字3,打印单词,看看是否有错误的填写或者可以取复习一下单词
10.输入数字1,默写单词
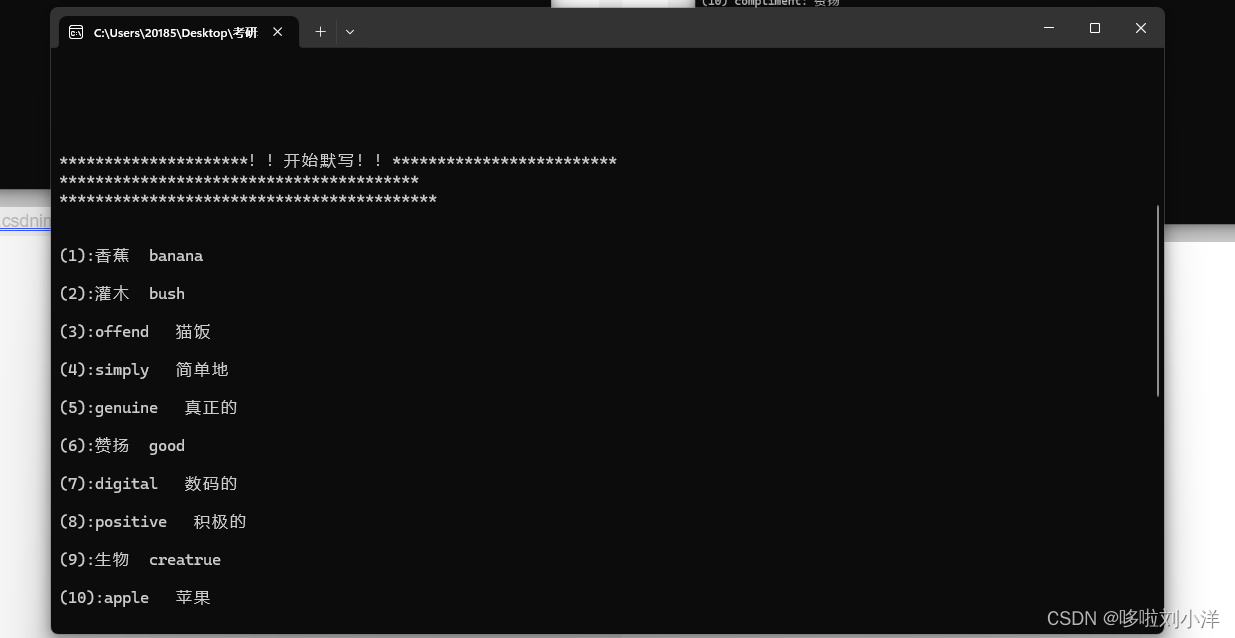
这里提一嘴!!!如果说不想默写那么多,可以按“0”退出默写。
再有一点,如果一个英文有多个中文意思,只要有一个是正确的将判断正确?
随后会给默写的单词打分。如果是满分将不需要重复默写,如果不是满分将会将错误的打印出来并让你重新默写直到你全对为止!