01 引言
在一个线上 Kafka 集群中,流量的波动、Topic 的创建和删除、Broker 的消亡和启动都随时可能发生,而这些变化可能导致流量在集群各个节点间分布不均,从而导致资源浪费、影响业务稳定。此时则需要主动将 Topic 的不同分区在各个节点间移动,以达到平衡流量和数据的目的。
当前,Apache Kafka 仅提供了分区迁移工具,但具体的迁移计划则需要运维人员自行决定,而对于动辄成百上千个节点规模的 Kafka 集群来说,人为监控集群状态并制定一个完善的分区迁移计划几乎是不可能完成的任务,为此,社区也有诸如 Cruise Control for Apache Kafka这类第三方外置插件用于辅助生成迁移计划。但由于 Apache Kafka 的重平衡过程中涉及到大量变量的决策(副本分布、Leader 流量分布、节点资源利用率等等),以及重平衡过程中由于数据同步带来的资源抢占和小时甚至天级的耗时,现有解决方案复杂度较高、决策时效性较低,在实际执行重平衡策略时,还需依赖运维人员的审查和持续监控,无法真正解决 Apache Kafka 数据重平衡带来的问题。
02 AutoMQ 的架构优势
得益于 AutoMQ 对云原生能力的深度应用,我们将 Apache Kafka 的底层存储完全基于云的对象存储进行了重新实现,由此带来的优势有:
- 完全的存算分离架构,Broker 仅需保留少量块存储空间用作 Delta WAL,其余数据均下沉至对象存储,在集群内部可见。
- 基于 EBS 和对象存储的高可用保证,分区仅需保留单副本。
基于上述优势,分区迁移计划的决策因素得到了极大的简化:
- 无需考虑节点的磁盘资源。
- 无需考虑分区的 Leader 分布和副本分布。
- 分区的迁移不涉及数据同步和拷贝。
故我们有机会在 AutoMQ 内部实现一个内置的、轻量化的数据自动平衡组件,持续监控集群状态,自动执行分区迁移。
03 AutoMQ 重平衡组件的实现
3.1 整体架构
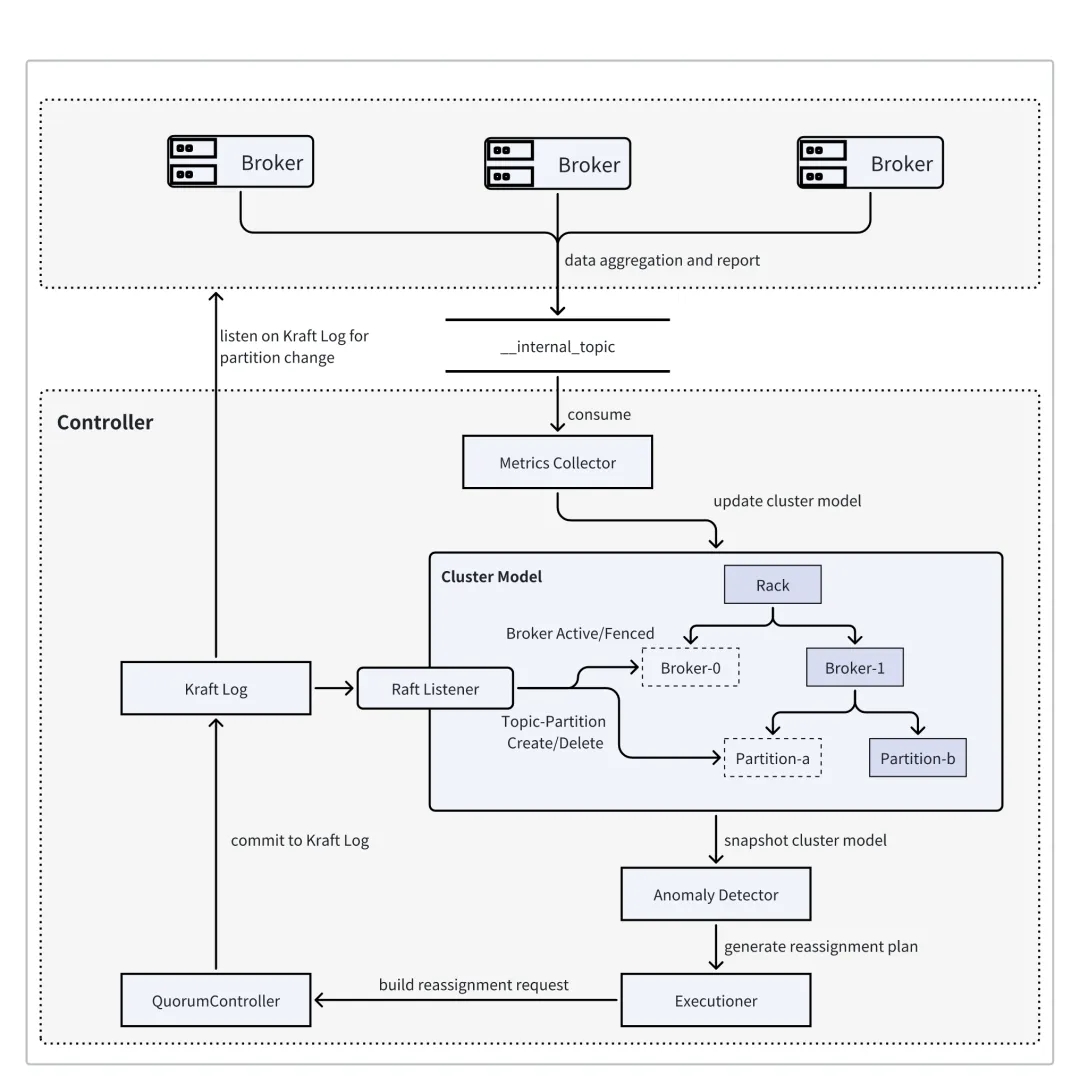
AutoMQ 持续重平衡组件(AutoBalancer)的实现,主要分为以下三个部分:
- 指标采集
- 状态维护
- 决策调度
除了 Broker 侧完成指标采集外,状态感知和决策调度由 Active Controller 处理,确保调度组件的可用性与 Controller KRaft Group 保持一致。
3.2 指标采集
Apache Kafka 原生提供了基于 Yammer Metrics 和 KafkaMetrics 实现的指标采集体系,并且可以通过 MetricsRegistry 和 MetricsReporter 接口实现对这两类指标的监听,AutoMQ 基于上述接口实现了 AutoBalancerMetricsReporter,可周期性采集预置指标,如网络流量吞吐或其他自定义的指标或参数。
同时,与大多数业界 Kafka 内部监控实现方案类似,AutoMQ 使用了一个内部 Topic 用于在 Broker 和 Controller 侧传递指标,当 AutoBalancerMetricsReporter 完成一次指标采集后,会将所有指标拼装成多条消息发入内部 Topic 中,从而完成 Broker 端的指标上报。
3.3 状态维护
AutoMQ 的 Controller 侧维护了一个集群状态模型 ClusterModel,用于表示当前集群的 Broker 状态及各个 Broker 的分区分布和负载情况。
ClusterModel 的结构性变更,如 Broker 加入和移除、分区的迁移和删除等均通过监听 KRaft record 变更实现,从而保证了 ClusterModel 结构与元数据一致。
同时 Controller 会持续从内部 Topic 中进行消费,并将解析出的指标进行预处理后更新到 ClusterModel,由此我们获得了一个能够真实反应集群当前状态的模型。
3.4 决策调度
AutoMQ 的每个 Controller 都会维护一个相应的 ClusterModel,但仅有 Active Controller 才会真正进行决策调度,当 Active Controller 发生变更时,决策调度权也相应移动到当前的 Active Controller 节点上。决策开始前,AutoMQ 会先对 ClusterModel 进行一次快照,并使用快照的集群状态进行后续的调度,快照完成后,ClusterModel 即可继续更新。AutoMQ 的决策过程采用了类似 Cruise Control 的启发式调度算法,如下图:
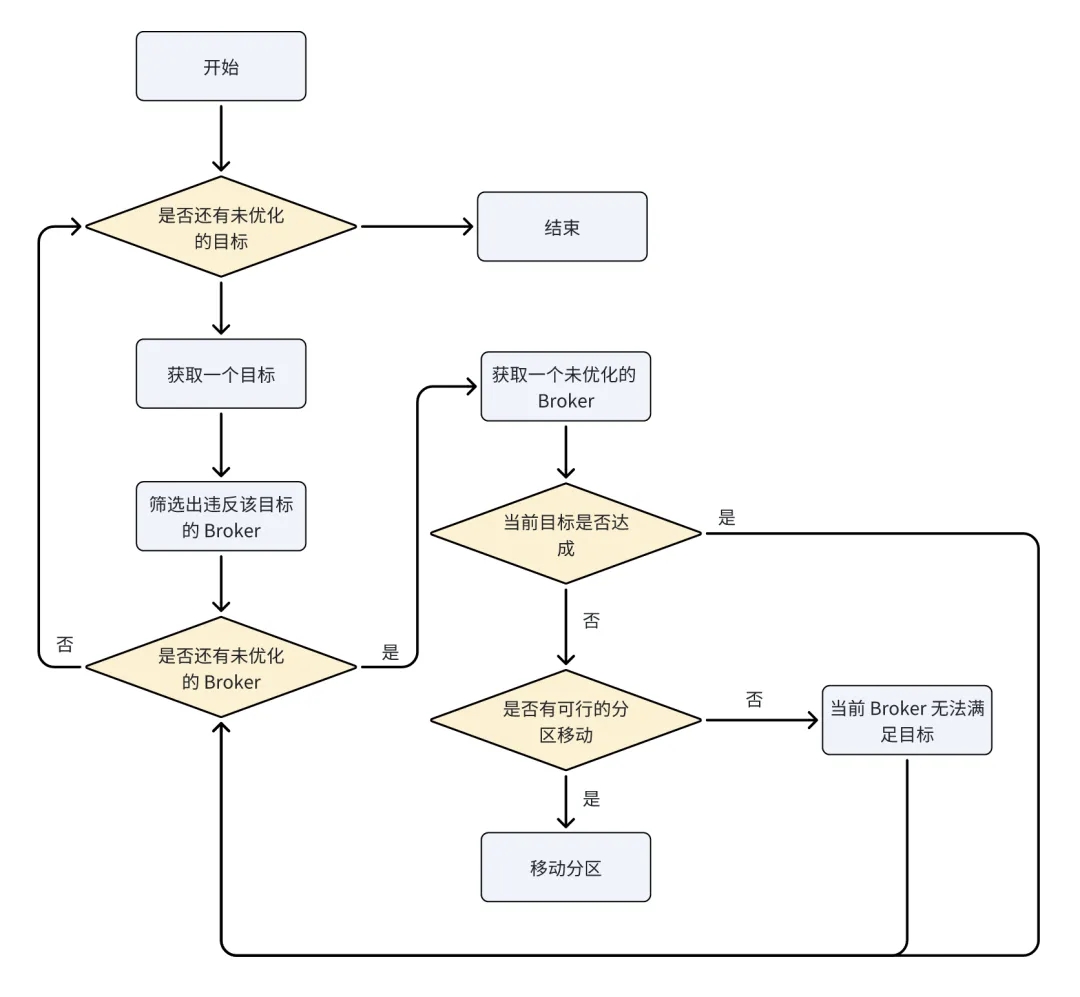
可以看到,决策的重点在于如何定义一个合理的目标。一个目标即为一个期望通过调度达到的目的,如实现流量均衡、限制单 Broker 的分区数量、限制单 Broker 的流量上限等,确定了目标后,还需要解决以下两个问题:
- 如何判断一个 Broker 是否满足当前目标
- 如何判断一次分区移动是否可行
3.4.1 判断 Broker 是否满足目标
我们可以用一个简单的数学模型来表示一个 Broker 当前的状态是否满足目标:
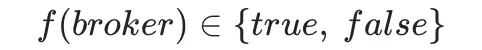
其中:输入为 Broker 状态模型(包含 Broker 上的分区和流量),输出为 true 或 false,表示是否满足当前目标。
以流量均衡目标为例,首先根据集群总体流量和 Broker 数量,计算出流量平均值 loadavg ,再根据预设的偏移系数 ratio(可接受的流量与均值的偏差范围),计算出期望的流量分布范围:
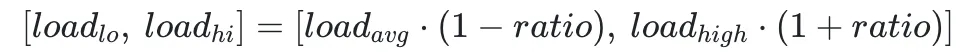
如果 Broker 当前的流量位于该范围内,则认为 Broker 满足目标。同时考虑到实际业务场景,当集群流量较小时,调度误差较大,且进行流量均衡调度意义不大,于是我们还需额外设置流量调度阈值,当 Broker 流量低于该阈值时,也认为目标被满足。综上,我们可以用如下模型表示流量均衡目标的满足性判断:

3.4.2 判断分区移动是否可行
一次分区移动(下称 Action)包含三个部分:需移动的分区、源 Broker、目标 Broker。如果使用我们之前已经定义好的的判断 Broker 是否满足目标的数学模型来表示 Action 前后 Broker 的状态变化,可表示如下:
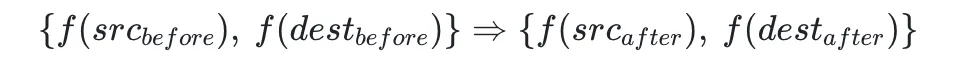
每个 f\(broker\) 函数有两种取值可能,总共可以得出 16 种可能的状态转移,其中仅部分状态转移可以得出明确的 Action 是否可行的结论,其余则无法做出判断,受限于本文篇幅,下面仅举例论证。
- {false,false}⇒{true,true}:移动后使得 Broker 均从不满足目标变成了满足目标,表示此次 Action 带来积极作用,可以被接受
- {true,true}⇒{false,false}:移动后使得 Broker 均从满足目标变成了不满足目标,表示此次 Action 带来负面作用,应被拒绝
- {false,false}⇒{false,false}:难以判断,虽然移动前后 Broker 对于是否满足目标的判断都没有改变,但无法确定此次 Action 是否能带来积极作用。例如,broker-1 流量低于 loadlo,broker-2 流量高于 loadhi,此时将 broker-2 上的一个分区移动至 broker-1,虽然可能此次移动使得 broker-1 流量依旧低于低于loadlo,broker-2 流量依旧高于loadhi,但本次移动依然改善了两个 Broker 间的不均衡状态,依旧是可被接受的 Action;反之,如果将 broker-1 上的一个分区移动至 broker-2,则加剧了不均衡状态,此时 Action 是不可被接受的
综上可知,仅通过一个二元输出的目标函数来表示 Broker 状态,无法对所有场景产出明确的调度决策。为解决此问题,我们需要定义一套更加灵活的数学模型,当输入的集群状态一致时,能够产出确定且幂等的决策结果,实现稳定、可解释的多目标调度机制。我们定义函数:
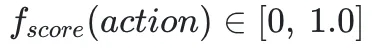
用于表示一个 Action 在单一目标下的得分。并对得分约定如下:
- score < 0.5:表示该 Action 会对当前目标产生负面影响,如果当前目标为强制性目标(Hard Goal)时,该 Action 直接被拒绝。典型的强制性目标如:限制 Broker 分区数量、限制 Broker 流量上限等,非强制性目标如:流量均衡、QPS 均衡等
- score = 0.5:表示该 Action 对当前目标不产生影响。如 Broker 分区数量、流量均在限制范围内,或 Broker 负载均衡度不被改变
- score > 0.5:表示该 Action 对当前目标产生正面影响。如使得 Broker 的流量从超出限制到回到限制范围内,或使的 Broker 流量分布更加均衡
Action 在单一目标的得分
为计算该函数,我们首先定义 Broker 在当前目标下的得分为:
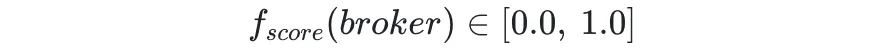
则可计算在进行一次分区迁移后,Broker 最小得分的差值如下:
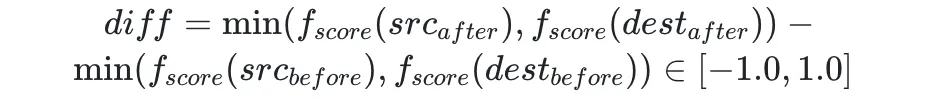
将得分差值归一化处理后,即可得:
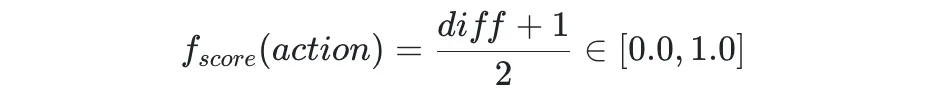
Action 在多目标的综合得分
通过前述计算,我们现在可以得出 Action 在各个不同目标的得分,从而计算出 Action 在多个目标的综合得分,而由于得分做了归一化处理,我们可以在同一尺度对不同目标的得分直接取加权和:
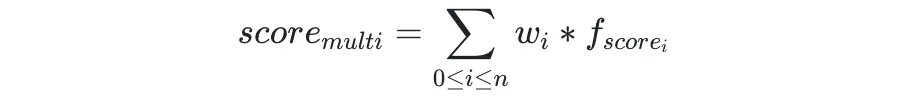
当需要在多个 Action 中择优选择时,仅需在所有得分大于 0.5 的 Action 中选取得分最高的即可。
Broker 在单一目标的得分
现在,我们只需确定 broker 在单一目标上的得分模型 fscore(broker) 即可计算出 Action 的综合得分,根据前述约定,该模型需满足如下条件:
- 得分范围需归一化至 [0.0,1.0],否则不同目标得分尺度不一致,最终的加权和不具备参考意义。
- 当一个 Action apply 至 broker 后,如果认为该 Action 对 broker 无影响,则 apply 前后得分应相同。
- 当一个 Action apply 至 broker 后,如果认为该 Action 对 broker 存在负面影响,则 apply 前得分应大于 apply 后 。
- 当一个 Action apply 至 broker 后,如果认为该 Action 对 broker 存在正面影响,则 apply 前得分应小于 apply 后 。
以 AutoMQ 当前内置的流量重平衡目标为例,定义的 Broker 得分模型为:

其中:
ua:表示当前流量与流量均值差值的绝对值
bound:ua 值在此范围内,认为当前流量在均值范围内
var:对数函数底数,此参数决定了阶梯函数何时从线性下降转变为对数下降
ua 值越大,表示与期望值偏离越大,得分也即越低,当偏离值在均值范围内时,得分不变,表示在此范围内的分区移动对此目标无影响。当偏离值大于均值范围,但小于 var 值时,得分随着偏移量线性下降,当偏离值大于 var 值时,随着偏移量趋于无穷大,得分趋于零。函数曲线如下(为易读性坐标轴做了相应伸缩):
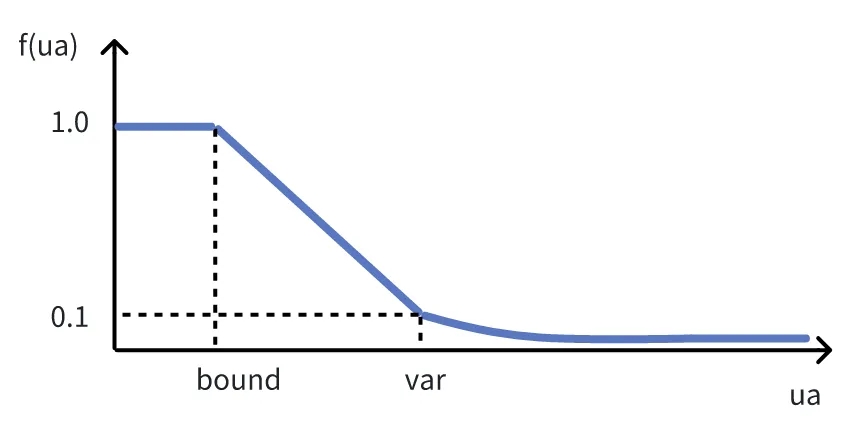
该函数模型的语意为:
- 当 Action 使得 Broker 的流量保持在均衡范围内时,认为该 Action 对集群无影响
- 当 Action 使得 Broker 的流量与期望值的偏离程度减小时,认为该 Action 产生积极影响
- 当 Action 使得 Broker 的利用率与期望值的偏离程度增加时,认为该 Action 产生负面影响,由于均衡类目标为非强制性目标(Soft goal),即使该 Action 对当前目标产生负面影响,最终是否采纳还需要看该 Action 在所有目标的综合得分,只要综合得分大于 0.5,则依然认为该 Action 可被执行
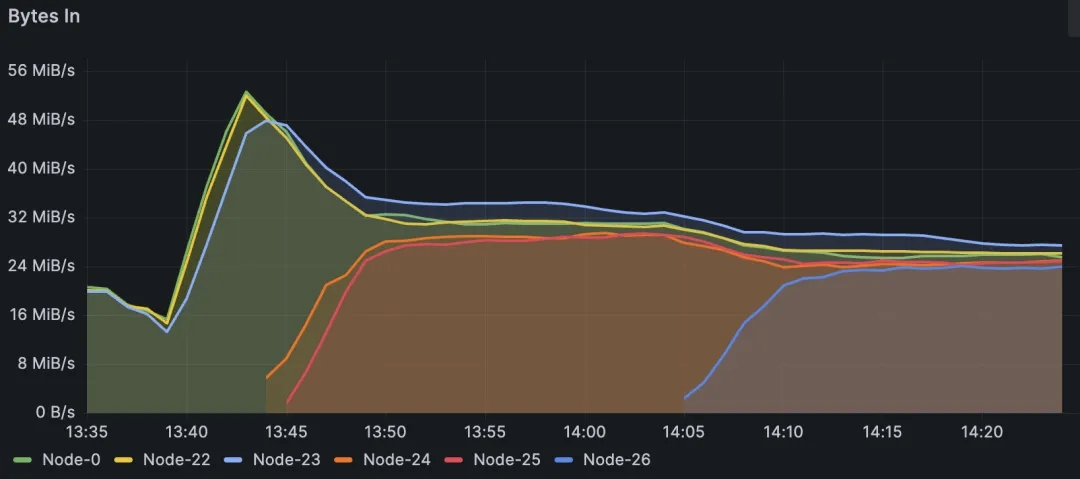
下图展示了使用上述数学模型进行的流量均衡调度效果(图源自 AutoMQ 内部 LongRunning 监控大盘):
04 结语
在本文中,我们详细探讨了 AutoMQ 如何通过其内置的自动平衡组件 AutoBalancer 实现分区的持续重平衡,以及如何通过定义数学模型来输出可解释、可观测的调度决策。未来我们还将持续完善调度模型以适配更加复杂的生产环境,并持续向社区贡献如冷读识别、流量预测等高阶调度能力,同时我们也欢迎社区开发者和我们一同共建,打造更加高效且多样化的自平衡能力。
参考资料
[1] Cruise Control for Apache Kafka: https://github.com/linkedin/cruise-control
[2] 与“众”不同的 AutoMQ 云原生架构:https://docs.automq.com/zh/docs/automq-s3kafka/X1DBwDdzWiCMmYkglGHcKdjqn9f
[3] 原理剖析:AutoMQ 如何基于裸设备实现高性能的 WAL:
[4] Yammer metrics maven dependency: https://mvnrepository.com/artifact/com.yammer.metrics/metrics-core/2.2.0
[5] KafkaMetrics.java: https://github.com/AutoMQ/automq/blob/main/clients/src/main/java/org/apache/kafka/common/metrics/KafkaMetric.java
[6] Introduction to Kafka Cruise Control \(Slides 37/47\):https://www.slideshare.net/slideshow/introduction-to-kafka-cruise-control-68180931/68180931
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:










