
目录
八、线程安全问题(重点)
我们在前面说过,线程之间是抢占式执行的,这样产生的随机性,使得程序的执行顺序变得不一致,就会使得程序产生不同的结果,有的时候这些不同的结果,我们是不可接受的,认为是一种bug
那么由多线程引起的bug,这样的问题就是线程安全问题,存在线程安全问题的代码,就认为线程是不安全的
1.一个典型的线程不安全的例子
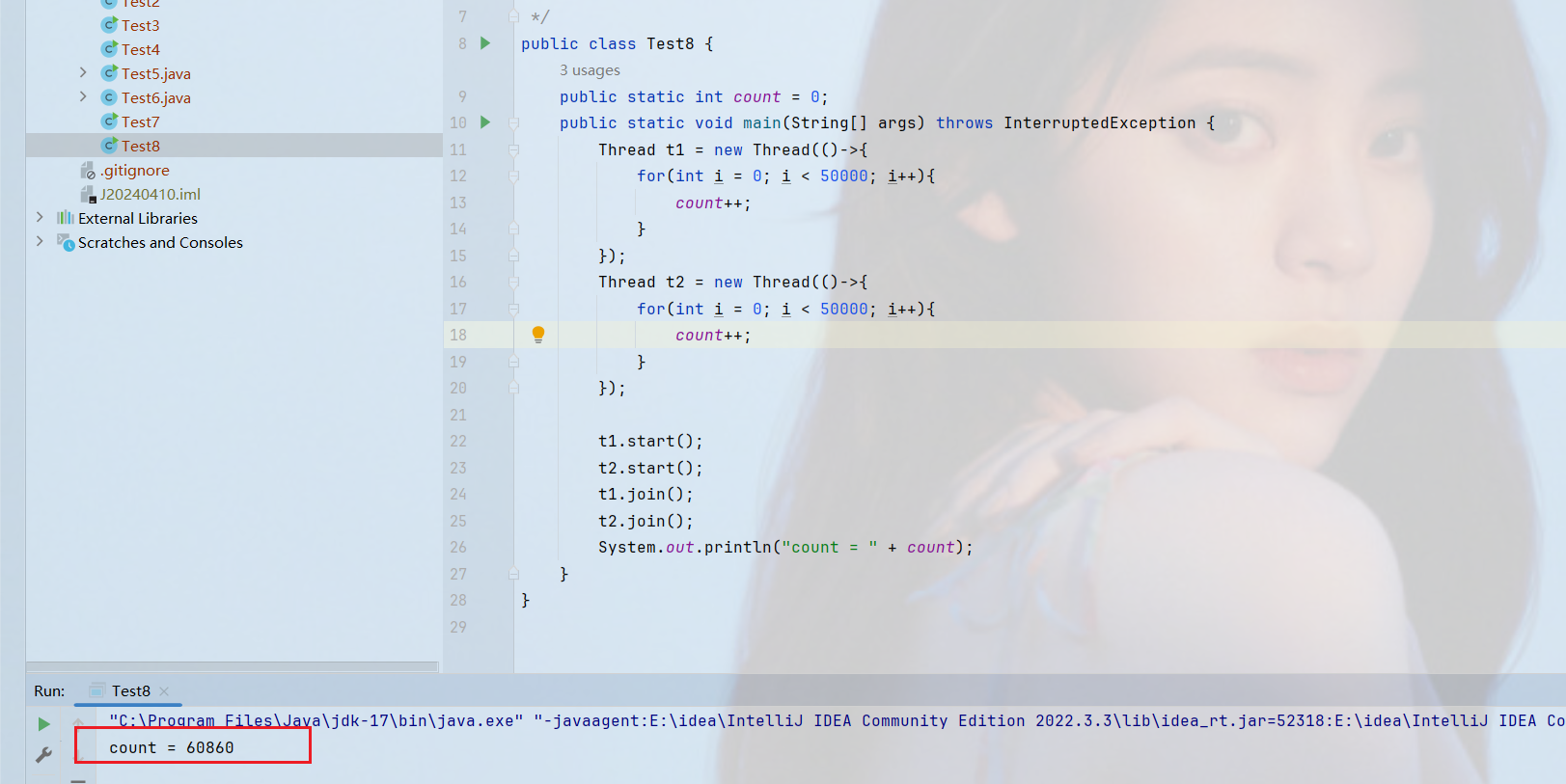
我们在编写程序的时候的预期值是10000,但是得到的结果确实不确定的,小于10000的
这就是一个典型的多线程并发导致的问题
实际上我们的count++这一步操作包含了3步
(1)load : 将内存中count 的值读取到寄存器里面
(2)add:把寄存器里的count 进行+1操作,后还是保存到寄存器里面
(3)save:将寄存器里的值写回到内存里面
那么由于抢占式执行,在两个线程执行的过程中就有可能出现下面这种情况:

在上面的执行过程中,我们发现,两个线程分别执行了一次count++,但是由于前一个写会到内存的count被后一个写回去的给覆盖了,最后内存的count还是1
由于当前线程里的执行顺序是不确定的,.有的时候顺序加两次,结果就是对的,有的时候加两次,结果只是加了一次,具体有多少次,结果是多少,都是随机的
因此看到的结果不是一个确定的数,是不可预测的
如果我们能够保证,一个线程的save是在另一个线程的load之前,那么结果就是我们所预期的
2.出现线程不安全的原因
(1)线程在系统中的执行是随机的,抢占式执行,这也是线程安全问题的罪魁祸首
(2)当前代码,存在多个线程同时修改一个变量
如果是一个/多个线程修改单独的变量,那就没事;如果是多个线程读取同一个变量,也没事
但是如果是多个线程同时修改同一个变量,那就有问题了
(3)线程针对变量的操作不是"原子"的
有的操作,例如对int 类型的变量进行赋值操作,在cpu就是一个move指令,但是有的修改操作不是一个原子的,像count++这种
(4)内存可见性问题引起的线程不安全
(5)指令重排序问题引起的不安全
3.解决线程不安全的问题
解决问题就要从产生问题的原因入手
3.1针对原因1(线程在系统中的执行是随机的)
这种我们就无能为力了,我们无法干预
3.1针对原因2(存在多个线程同时修改一个变量)
虽然是一个切入点,但是实际上这种做法不是很普适,只是针对一些特定的场景可以使用,例如String就是个不可变的变量
3.2针对原因3(线程针对变量的操作不是"原子"的)
针对原因三是我们解决线程安全问题最普适的方案,可以通过一些操作让原来不是原子的操作.打包成一个原子的操作,这个操作就是"加锁"
锁实际上也是操作系统提供的功能,也就是内核提供的功能,通过系统api给应用程序,而jvm中又对这样的api进行了封装.方便我们使用
关于锁,主要就是两方面的操作
(1)加锁:t1线程加锁后,t2如果尝试加锁,就会进入阻塞等待(都是操作系统内核在控制),此时就能看到t2线程处于blocked状态
(2)解锁,直到t1解锁后,t2才有机会拿到锁(加锁成功)
这种就是锁的"互斥特性",即锁竞争 / 锁冲突
那么怎么使用锁呢??
创建出一个对象,用这个对象作为锁
Object o = new Object();//在java中,随便拿一个对象都能作为加锁的对象(这个是java中特例的设定)
使用synchronized
public class test1 {
private static int count = 0;
public static void main(String[] args) {
Object locker = new Object();
Thread t = new Thread(()->{
for(int i = 0; i < 50000; i++){
synchronized (locker){
count++;
}
}
});
t.start();
}
}
(1)synchronized是java的关键字(不是方法)
(2)synchronized后面带上的(),()里面带的对象就是"锁对象"
(3)synchronized()后面带着的{ }
表示当进入这个代码块,就是给上述( )锁对象进行了加锁操作
当出了这个代码块,就是给上述的锁对象解锁
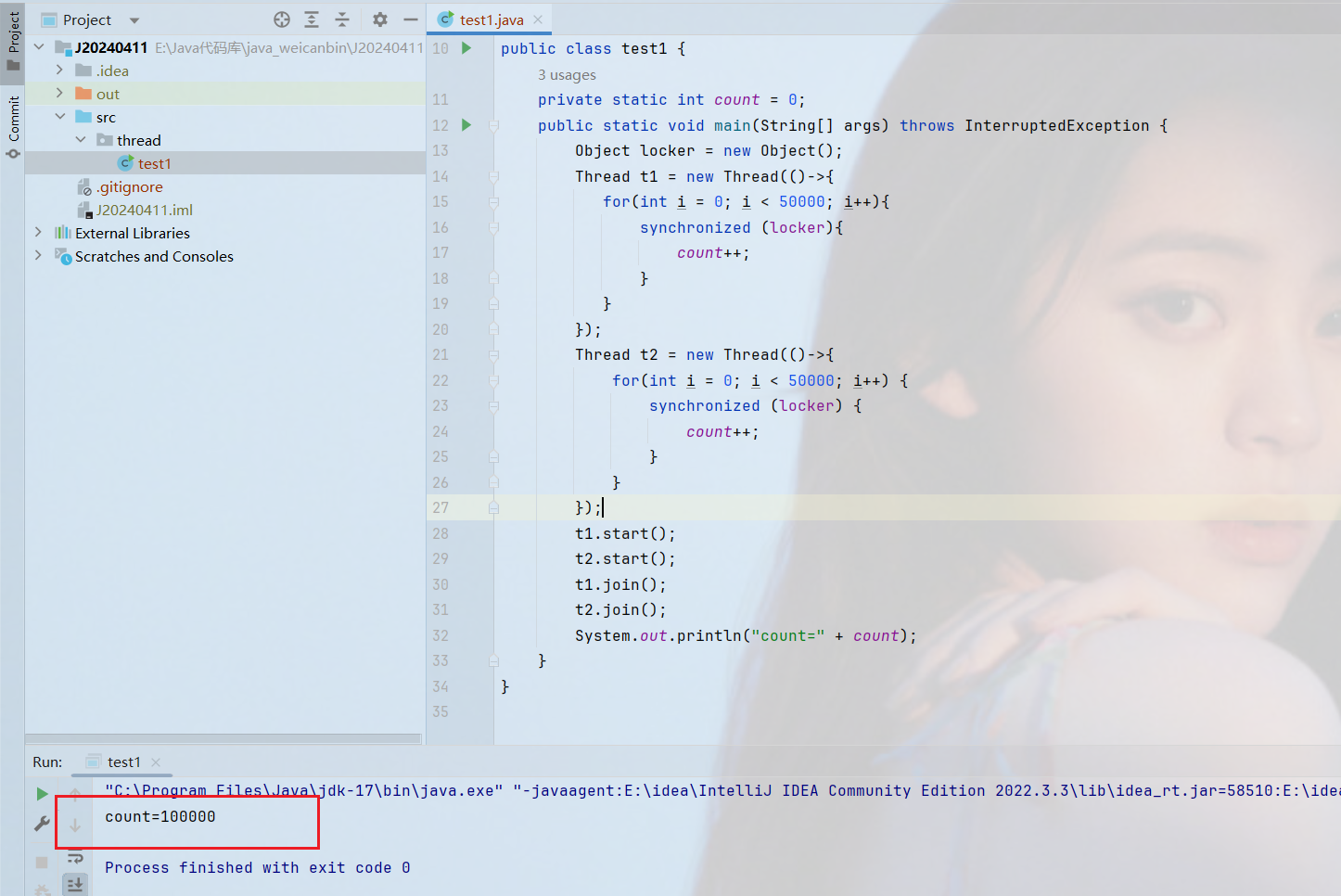
如图所示,此时这个代码就是两个线程针对同一个对象进行加锁,就会出现互斥现象,那么此时的结果就是我们所预期的了
执行过程
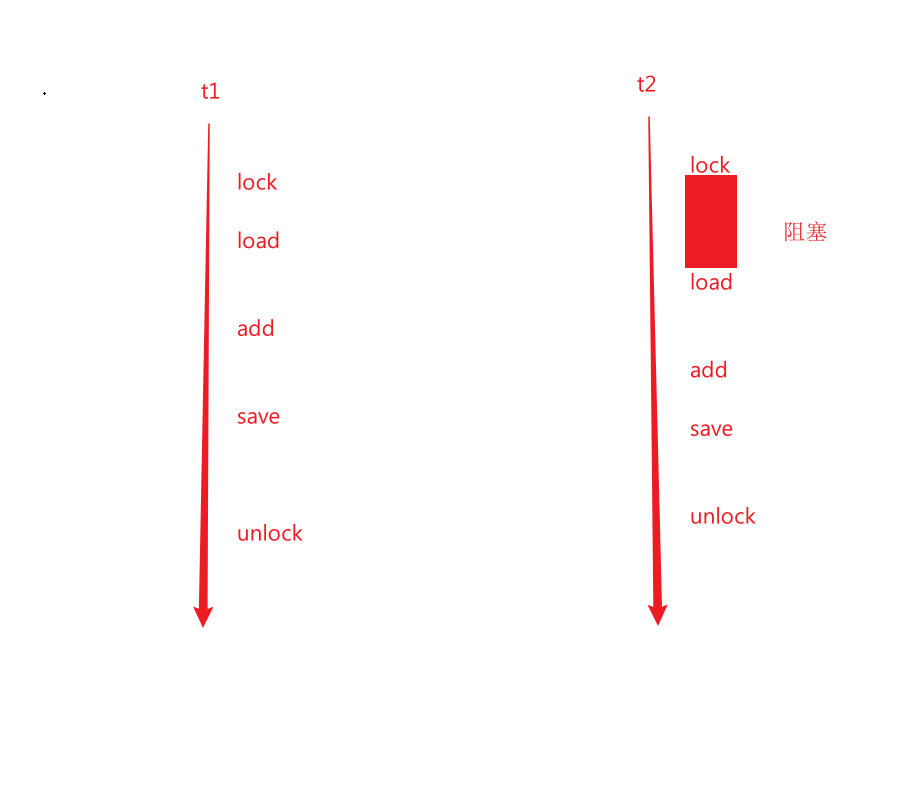
当t1先加锁后,t2尝试进行加锁,就会进入阻塞状态,当t1的save执行完后,才会释放锁,那么就能够保证一个线程的save在另一个线程的load之前了,即强行构造出"串行执行"的效果
另外几种操作
将锁加在for循环外面

此时for循环就不能并发了
在对象里面的方法里加锁

由于方法里面只是count++,此时锁的生命周期和方法的生命周期实际上是一致的
那么我们就可以直接将锁加在方法上

这种写法就相当于一进入方法就进行加锁操作
那如果是static方法呢??
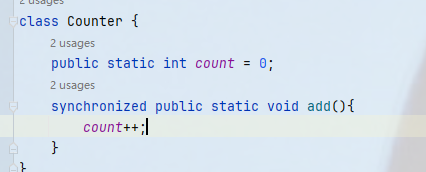
由于static方法是不依赖对象的,那么此时就相当于针对该类的类对象进行加锁
即等效于:
public void func(){
synchronized (Counter.class){
//...
}
}
这里的Coout.class就是所谓的类对象
死锁
class Counter {
private static int count = 0;
public void add(){
synchronized(this){
count++;
}
}
public static int getCount() {
return count;
}
}
public class Demo1 {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for(int i = 0; i < 50000; i++){
synchronized (counter){
counter.add();
}
}
});
t1.start();
t1.join();
System.out.println(Counter.getCount());
}
}
就类似上面的代码,我们在进入for循环的时候,肯定就先获得了锁,接着进入add方法中又尝试针对同一个锁对象进行加锁,但是按照我们上面的说法来说,就会进入阻塞等待,直到第一把锁被释放,但第一把锁被释放,又要先等第二把锁获得,这样就进入了矛盾了
这种情况,就是"死锁"
那么按照我们上面的逻辑来说,就会卡死

但是居然可以运行通过???
实际上我们上述分析的过程针对java里面的synchronized是不适用的,在C++或者Python是适用的
是因为在synchronized内部做了特殊处理,在每一个锁对象里面都会记录当前是哪个线程持有了这个锁,当某个多线程里面要进行加锁时,就会进行判断,判断当前进行加锁的线程是否已经持有了该锁??
如果没有,那么就阻塞等待,如果有,那么就放行
那么此时实际上,内层的锁就没有什么用了,因为外层的锁就已经保证了线程安全了.而之所以要搞这一套,就是要防止程序员粗心大意搞出死锁
死锁实际上有三种比较典型的场景:
场景1:锁是不可重入锁,并且同一个线程针对同一个对象重复加锁两次就会造成死锁(java中synchronized不会出现这种问题)
场景2:两个线程两把锁
存在锁1和锁2,以及线程1和线程2,线程1拿到锁1后,在锁里面尝试去拿锁2;但是此时锁2已经被线程2拿走了,而恰恰线程2又尝试去拿锁1
public static void main(String[] args) {
Object locker1 = new Object();
Object locker2 = new Object();
Thread t1 = new Thread(()->{
synchronized (locker1){
//...
try {
Thread.sleep(1000);//让线程2拿到锁
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (locker2){
//...
}
}
});
Thread t2 = new Thread(() -> {
synchronized (locker2) {
//...
synchronized (locker1) {
//...
}
}
});
t1.start();
t2.start();
}
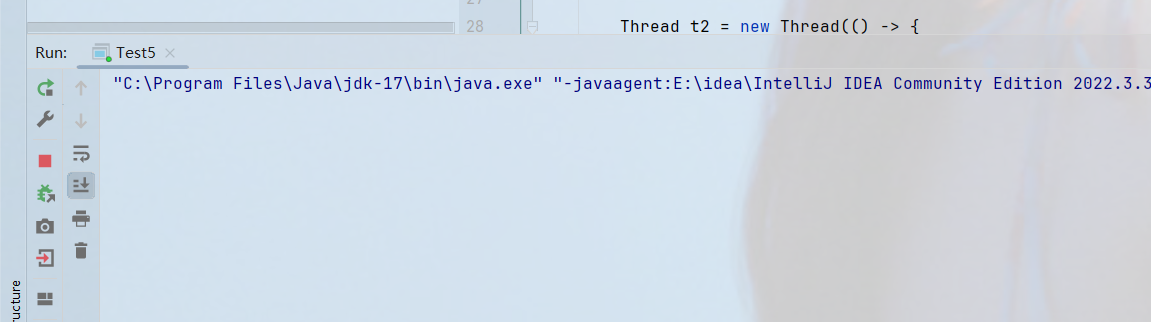
此时进程就会僵住,卡死了
因为此时t1等待t2释放锁2,才能释放锁1,但是t2释放锁2之前要等待t1释放锁1
场景3:N个线程 N 把锁
一个典型的例子就是哲学家就餐问题
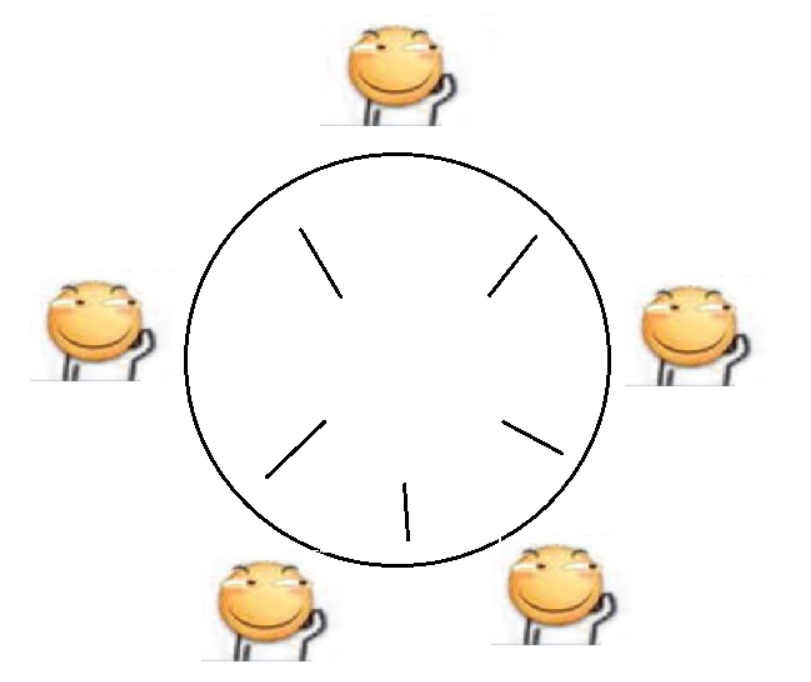
每个哲学家都坐在两个筷子之间,每个哲学家啥时候吃面条,啥时候思考人生都是不确定的(抢占式执行)
这么模型在大部分情况下是没问题的,可以最后正常工作的
但是如果出现极端情况,就会出现问题
即在同一时刻,所有的哲学家都拿起左边的筷子,此时就会出现所有的哲学家都无法拿起右边的筷子的情况,但是哲学家又是比较固执,不吃到面条就永远不会放下筷子
这就是典型的死锁状态
避免死锁问题
避免死锁问题,我们就要先理解产生死锁的必要条件
(1)锁具有互斥性:这是synchronized的基本特性
(2)锁不可被抢占(不可被剥夺):即一个线程拿到锁后,除非他自己释放,否则别的线程是拿不到锁的(也是锁的基本特性)
(3)请求和保持 : 一个线程拿到一个锁后,不释放这个锁的前提下,又尝试去获取别的锁(代码层面的特性)
(4)循环等待 多个线程获取多个锁的过程中,出现了A等待B,B又等待A的情况(代码层面的特性)
"必要条件"说明缺一不可
那么我们要避免死锁就只要避免其中一个就好了
对于前两点.由于是锁的基本特性,除非你自己实现锁.实现可以打破互斥,打破不可剥夺这样的条件,对于synchronized这样的锁是不行的
那么我们就可以从(3)(4)代码结构入手
第一点就是不要让锁嵌套获取
但是有的时候,针对某些场景,就必须嵌套获取了

上述代码,就变成了t1执行完所有逻辑后释放locker1之后,才轮到t2执行,自然就不会死锁了
有时候在代码中确实需要用到多个线程获取同一把锁,约定好加锁的顺序,就可以有效避免死锁了
这是一个最简单有效的方法
3.3针对原因4(内存可见性引起的线程安全问题)
public class Test6 {
public static int count = 0;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while (count == 0){
//
}
System.out.println("t1结束");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
System.out.println("输入一个整数");
count = scanner.nextInt();
});
t1.start();
t2.start();
}
}
此时按照我们的需求,输入任意一个数后,由于count改变了,那么t1里面循环就会结束,t1线程就会退出
但是实际上:
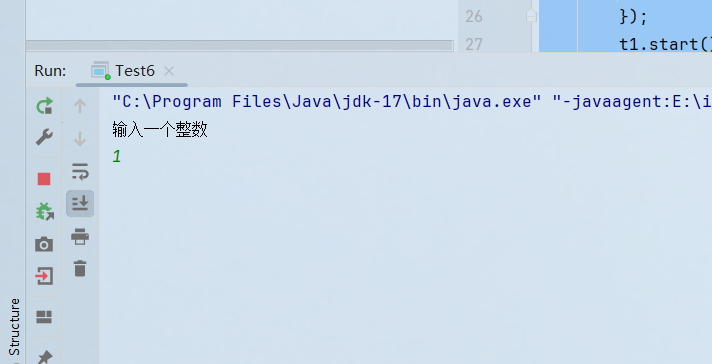
t1线程并没有结束
而当我们在循环里面尝试进行一些输出操作:

此时就没问题了
我们来分析一下出现这种问题的原因:
实际上while(count == 0)这个操作的执行流程
(1)load 从内存里面读count到cpu寄存器
(2)cmp 条件成立的话就执行流程,不成立就跳转到别的地方执行
实际上,由于while循环执行得太快,短时间内出现大量的load和cmp操作,而执行load操作消耗的时间,比cmp操作要多上几千倍上万倍
此时jvm发现,在t2修改count之前,每次执行load操作的结果实际上都是一样的,这时候jvm干脆就把load操作给优化掉了(把速度慢的优化掉,使程序运行速度更快了),这样的话,只是第一次真正的load,后续的load都是只是读取之前保留在寄存器里面的值
而出现优化后,t2线程修改count,t1就感知不到了
而当我们上述代码循环体中存在IO操作或者阻塞操作(sleep),这时候就会使循环的旋转速度大幅度降低了,此时的IO操作才是应该被优化的那一个,但是IO操作是不能被优化掉的,load被优化的前提是反复load的结果是相同的.而IO操作注定是反复执行结果是不相同的
致命的是,编译器到底啥时候优化是个"玄学问题"
但是就"内存可见性"问题来说,可以通过特殊的手段来控制,不让他触发优化的 ,那就是使用volatile关键字
volatile关键字
给变量修饰加上这个关键字后,此时编译器就知道,这个变量是"反复无常的",就不能按照上述优化策略进行优化了
(具体在java中,是让javac生成字节码的时候产生了"内存屏障"相关的指令)
但是这个操作和之前的synchronized保证的原子性是没有任何关系的
volatile是专门针对内存可见性的场景来解决问题的,并不能解决循环count++的问题











