我们在正常使用缓存的时候的流程大概就是这样的:
请求访问缓存,缓存有数据就返回,缓存无数据就去数据库里面查数据写入到缓存中。
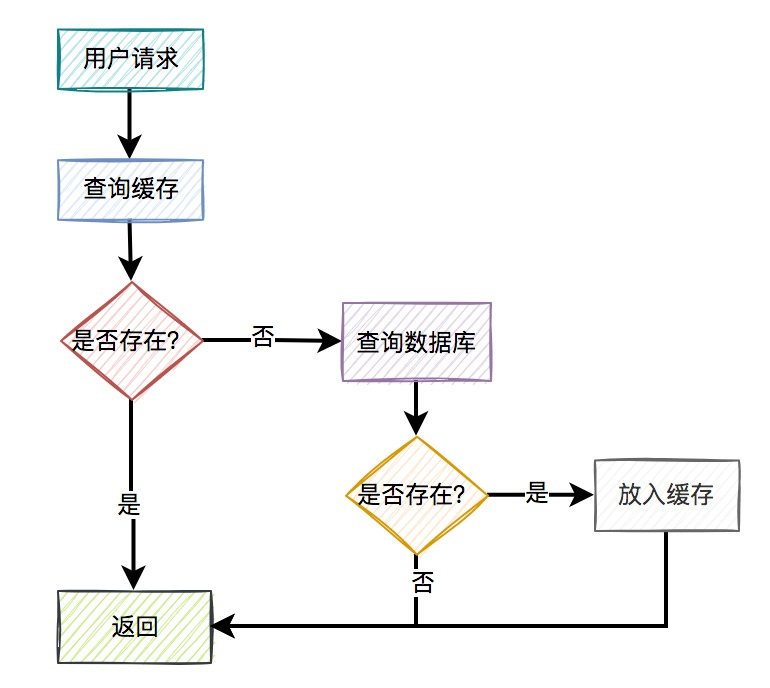
1、缓存穿透问题
但是如果由恶意请求,短时间内大量的访问不存在的数据,这时每个请求都会打到数据库上,数据库就会扛不住压力崩掉。
图例:

2、解决方案
1、缓存空对象
我们可以将此时这个恶意请求查询的内容添加到缓存,添加为一个空值缓存,也就是缓存空对象。
缓存空对象之后,此时这个恶意请求的请求都会击中缓存了,一定程度上就解决了缓存穿透的问题。
弊端: 如果此时恶意请求是大量访问多个空对象,就会导致短时间内,内存中被大量的空对象占用,造成系统资源浪费。
2、加锁
如果Redis中不存在该数据,在请求访问数据库的时候,加一把互斥锁。此时就可以让只有一个请求访问数据库了,就不会导致数据库压力过大。
但是这种方法不可取:
- 首先任何需要应对高并发的系统都应该尽量避免使用互斥锁,会阻塞其他用户的操作,导致其他用户体验不佳。
- 可能会误杀到正常请求,如果此时是正常请求只是缓存过期了,此时就会阻塞其他的请求。
所以这种方法并不可取。
3、布隆过滤器

布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
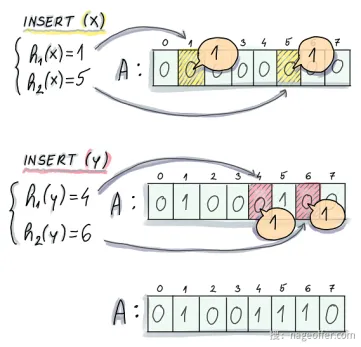
在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
1、 优缺点
优点:
- 高效地判断一个元素是否属于一个大规模集合。(哈希函数)
- 节省内存。(位数组)
缺点: - 可能存在一定的误判。
2、 布隆过滤器误判理解(为什么会误判)
- 布隆过滤器要设置初始容量。容量设置越大,冲突几率越低。
- 布隆过滤器会设置预期的误判值。
3、弊端:
- 做的业务需要支持一定的误判率
- 如果恶意请求是针对这小概率的误判进行攻击,那么数据库还是会遭到很大的压力。
4、组合方案
针对上述的缺点,我们可以将缓存空对象和布隆过滤器结合起来。
布隆过滤器的缺点是有小概率的误判,而且如果恶意请求拿着这个误判的值进行大量的请求,还是会对数据库造成很大的压力。但是此时如果我们针对于误判的这部分加上缓存空值,大部分的恶意请求都被布隆过滤器拦截下来了,不用担心内存大量占用的问题。此时就完美的解决了缓存穿透的问题。










