什么是文档?
在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}
通常情况下,我们使用的术语 对象 和 文档 是可以互相替换的。不过,有一个区别: 一个对象仅仅是类似于 hash 、 hashmap 、字典或者关联数组的 JSON 对象,对象中也可以嵌套其他的对象。 对象可能包含了另外一些对象。在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index——文档在哪存放
_doc——默认type
_id——文档唯一标识
_index
一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products 中,而存储所有销售的交易到索引 sales 中。 虽然也允许存储不相关的数据到一个索引中,但这通常看作是一个反模式的做法。
我们将在 索引管理 介绍如何自行创建和管理索引,但现在我们将让 Elasticsearch 帮我们创建索引。 所有需要我们做的就是选择一个索引名,这个名字必须小写,不能以下划线开头,不能包含逗号。我们用 website 作为索引名举例。
_id
ID 是一个字符串,当它和 _index 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
索引文档
通过使用 index API ,文档可以被 索引 —— 存储和使文档可被搜索。 但是首先,我们要确定文档的位置。正如我们刚刚讨论的,一个文档的 _index 和 _id 唯一标识一个文档。 我们可以提供自定义的 _id 值,或者让 index API 自动生成。
使用自定义的 ID
如果你的文档有一个自然的标识符 (例如,一个 user_account 字段或其他标识文档的值),你应该使用如下方式的 index API 并提供你自己 _id :
PUT /{index}/_doc/{id}
{
"field": "value",
...
}
举个例子,如果我们的索引称为 website ,类型称为 _doc,并且选择 123 作为 ID ,那么索引请求应该是下面这样:
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
Elasticsearch 响应体如下所示:
{
"_index": "website",
"_id": "123",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
- _index: 表示操作所涉及的索引名称,这里是 website。
- _id: 表示操作的文档ID,这里是 123。
- _version: 表示文档的版本号,每次文档更新都会增加版本号。
- result: 表示操作的结果,这里是 created,表示文档创建成功。
- _shards: 提供有关操作期间涉及的分片数量和状态的信息。
- total: 总分片数,这里是2个分片。
- successful: 成功执行操作的分片数,这里是1个分片成功。
- failed: 失败的分片数,这里是0个分片失败。
- _seq_no: 文档的序列号,用于处理并发操作。
- _primary_term: 文档所属的主要分片的代数,用于处理并发操作。
在 Elasticsearch 中每个文档都有一个版本号。当每次对文档进行修改时(包括删除), _version 的值会递增。 在 处理冲突 中,我们讨论了怎样使用 _version 号码确保你的应用程序中的一部分修改不会覆盖另一部分所做的修改。
Autogenerating IDs
如果你的数据没有自然的 ID, Elasticsearch 可以帮我们自动生成 ID 。 请求的结构调整为: 不再使用 PUT 谓词(“使用这个 URL 存储这个文档”), 而是使用 POST 谓词(“存储文档在这个 URL 命名空间下”)。
现在该 URL 只需包含 _index 和 _type :
POST website/_doc
{
"title": "My second blog entry",
"text": "Still trying this out...",
"date": "2014/01/01"
}
除了 _id 是 Elasticsearch 自动生成的,响应的其他部分和前面的类似:
{
"_index": "website",
"_id": "Rgr1o44B5LMk3sHDz2II",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
取回一个文档
为了从 Elasticsearch 中检索出文档,我们仍然使用相同的 _index , _type , 和 _id ,但是 HTTP 谓词更改为 GET :
GET /website/_doc/123?pretty
响应体包括目前已经熟悉了的元数据元素,再加上 _source 字段,这个字段包含我们索引数据时发送给 Elasticsearch 的原始 JSON 文档:
{
"_index": "website",
"_id": "123",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}
GET 请求的响应体包括 {"found": true} ,这证实了文档已经被找到。 如果我们请求一个不存在的文档,我们仍旧会得到一个 JSON 响应体,但是 found 将会是 false 。 此外, HTTP 响应码将会是 404 Not Found ,而不是 200 OK 。
返回文档的一部分
默认情况下, GET 请求会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定。
GET /website/_doc/123?_source=title,text
该 _source 字段现在包含的只是我们请求的那些字段,并且已经将 date 字段过滤掉了。
{
"_index": "website",
"_id": "123",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
或者,如果你只想得到 _source 字段,不需要任何元数据,你能使用 _source 端点:
GET /website/_source/123
那么返回的的内容如下所示:
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
或者,如果你不想想得到 _source 字段
GET /website/_doc/123?_source=false
检查文档是否存在
如果只想检查一个文档是否存在–根本不想关心内容—那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
HEAD /website/_doc/123
200 - OK
更新整个文档
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。相反,如果想要更新现有的文档,需要 重建索引 或者进行替换, 我们可以使用相同的 index API 进行实现,在 索引文档 中已经进行了讨论。
PUT /website/_doc/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值:
{
"_index": "website",
"_id": "123",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
result 标志设置成 updated ,是因为相同的索引、类型和 ID 的文档已经存在。
在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档。
在本章的后面部分,我们会介绍 update API, 这个 API 可以用于 partial updates to a document 。 虽然它似乎对文档直接进行了修改,但实际上 Elasticsearch 按前述完全相同方式执行以下过程:
- 从旧文档构建 JSON
- 更改该 JSON
- 删除旧文档
- 索引一个新文档
唯一的区别在于, update API 仅仅通过一个客户端请求来实现这些步骤,而不需要单独的 get 和 index 请求。
创建新文档
当我们索引一个文档,怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
请记住, _index 、 _type 和 _id 的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id :
POST /website/_doc/
{ ... }
然而,如果已经有自己的 _id ,那么我们必须告诉 Elasticsearch ,只有在相同的 _index 、 _type 和 _id 不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。使用哪种,取决于哪种使用起来更方便。
第一种方法使用 op_type 查询-字符串参数:
PUT /website/_doc/124?op_type=create
第二种方法是在 URL 末端使用 /_create :
PUT /website/_create/125
如果创建新文档的请求成功执行,Elasticsearch 会返回元数据和一个 201 Created 的 HTTP 响应码。
另一方面,如果具有相同的 _index 、 _type 和 _id 的文档已经存在,Elasticsearch 将会返回 409 Conflict 响应码,以及如下的错误信息:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[125]: version conflict, document already exists (current version [1])",
"index_uuid": "VU0CcQCbRoCPHzAyB0025w",
"shard": "0",
"index": "website"
}
],
"type": "version_conflict_engine_exception",
"reason": "[125]: version conflict, document already exists (current version [1])",
"index_uuid": "VU0CcQCbRoCPHzAyB0025w",
"shard": "0",
"index": "website"
},
"status": 409
}
删除文档
删除文档的语法和我们所知道的规则相同,只是使用 DELETE 方法:
DELETE /website/_doc/125
如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{
"_index": "website",
"_id": "125",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}
如果文档没有找到,我们将得到 404 Not Found 的响应码和类似这样的响应体:
{
"_index": "website",
"_id": "125",
"_version": 3,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1
}
即使文档不存在( result 是 not_found), _version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
处理冲突
当我们使用 index API 更新文档 ,可以一次性读取原始文档,做我们的修改,然后重新索引 整个文档 。 最近的索引请求将获胜:无论最后哪一个文档被索引,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到 Elasticsearch 中并使其可被搜索。 也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是 非常严重的 。试想我们使用 Elasticsearch 存储我们网上商城商品库存的数量, 每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。
有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。 假设有两个 web 程序并行运行,每一个都同时处理所有商品的销售,如图 Figure 7, “Consequence of no concurrency control” 所示。
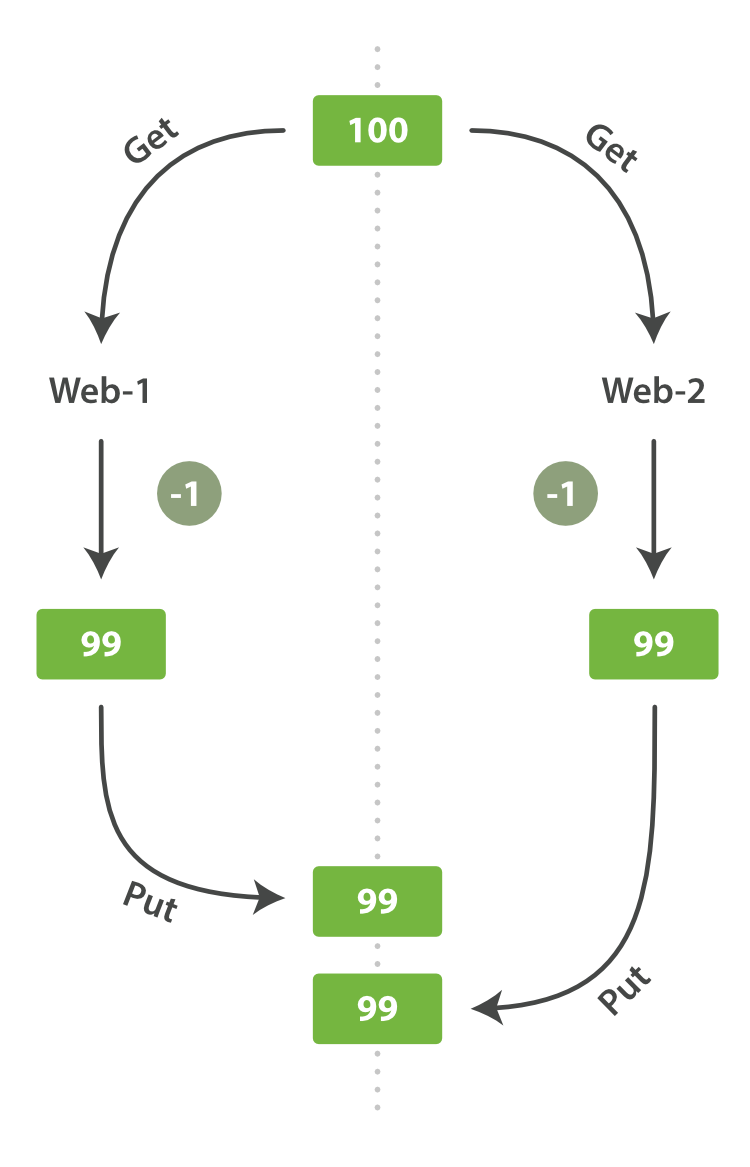
web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。 结果我们会认为有超过商品的实际数量的库存,因为卖给顾客的库存商品并不存在,我们将让他们非常失望。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
悲观并发控制
- 这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
- Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
乐观并发控制
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的 。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
让我们创建一个新的博客文章:
PUT /website/_create/1
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
响应体告诉我们,这个新创建的文档 _version 版本号是 1 。现在假设我们想编辑这个文档:我们加载其数据到 web 表单中, 做一些修改,然后保存新的版本。
首先我们检索文档:
GET website/_doc/1
响应体包含相同的 _version 版本号 1 :
{
"_index": "website",
"_id": "1",
"_version": 1,
"_seq_no": 9,
"_primary_term": 1,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
现在,当我们尝试通过重建文档的索引来保存修改,我们指定 version 为我们的修改会被应用的版本,新版本只能用if_seq_no=10&if_primary_term=1:
PUT website/_doc/1?if_seq_no=10&if_primary_term=1
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
此请求成功,并且响应体告诉我们 _version 已经递增到 3 ,_seq_no 已经递增到 11:
{
"_index": "website",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}
然而,如果我们重新运行相同的索引请求,仍然指定 if_seq_no=10&if_primary_term=1 , Elasticsearch 返回 409 Conflict HTTP 响应码,和一个如下所示的响应体:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "VU0CcQCbRoCPHzAyB0025w",
"shard": "0",
"index": "website"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "VU0CcQCbRoCPHzAyB0025w",
"shard": "0",
"index": "website"
},
"status": 409
}
这告诉我们在 Elasticsearch 中这个文档的当前 seqNo 号是 11 ,但我们指定的 seqNo 为 10 。
我们现在怎么做取决于我们的应用需求。我们可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或者,在之前的商品 stock_count 场景,我们可以获取到最新的文档并尝试重新应用这些修改。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制,这是一种明智的做法。
通过外部系统使用版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号 — 或一个能作为版本号的字段值比如 timestamp — 那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数, 且小于 9.2E+18 — 一个 Java 中 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同, 而是检查当前 _version 是否 小于 指定的版本号。 如果请求成功,外部的版本号作为文档的新 _version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在 创建 新文档时也可以指定。
例如,要创建一个新的具有外部版本号 6 的博客文章,我们可以按以下方法进行:
PUT website/_doc/1?version=6&version_type=external
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
在响应中,我们能看到当前的 _version 版本号是 6 :
{
"_index": "website",
"_id": "1",
"_version": 6,
"result": "updated",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 13,
"_primary_term": 1
}
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误, 因为指定的外部版本号不大于 Elasticsearch 的当前版本号。
文档的部分更新
在 更新整个文档 , 我们已经介绍过 更新一个文档的方法是检索并修改它,然后重新索引整个文档,这的确如此。然而,使用 update API 我们还可以部分更新文档,例如在某个请求时对计数器进行累加。
我们也介绍过文档是不可变的:他们不能被修改,只能被替换。 update API 必须遵循同样的规则。 从外部来看,我们在一个文档的某个位置进行部分更新。然而在内部, update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,我们也减少了其他进程的变更带来冲突的可能性。
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。 例如,我们增加字段 tags 和 views 到我们的博客文章,如下所示:
POST /website/_update/1
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
如果请求成功,我们看到类似于 index 请求的响应:
{
"_index": "website",
"_id": "1",
"_version": 7,
"result": "updated",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 14,
"_primary_term": 1
}
检索文档显示了更新后的 _source 字段:
{
"title": "My first blog entry",
"text": "Just trying this out...",
"views": 0,
"tags": [
"testing"
]
}
新的字段已被添加到 _source 中。
使用脚本部分更新文档
脚本可以在 update API中用来改变 _source 的字段内容, 它在更新脚本中称为 ctx._source 。 例如,我们可以使用脚本来增加博客文章中 views 的数量:
POST /website/_update/1
{
"script" : "ctx._source.views+=1"
}
我们也可以通过使用脚本给 tags 数组添加一个新的标签。在这个例子中,我们指定新的标签作为参数,而不是硬编码到脚本内部。 这使得 Elasticsearch 可以重用这个脚本,而不是每次我们想添加标签时都要对新脚本重新编译:
POST /website/_update/1
{
"script" : {
"source": "ctx._source.tags.add(params.new_tag)",
"params" : {
"new_tag" : "search"
}
}
}
# 或者
# 这个更新脚本会首先检查 tags 字段是否存在,如果不存在则创建一个空数组,然后将新的标签添加到数组中。这样可以避免类型转换错误。
POST /website/_update/1
{
"script" : {
"source": "if (!ctx._source.containsKey('tags')) { ctx._source.tags = [] } ctx._source.tags.add(params.new_tag)",
"params" : {
"new_tag" : "search"
}
}
}
获取文档并显示最后两次请求的效果:
{
"title": "My first blog entry",
"text": "Just trying this out...",
"views": 1,
"tags": [
"testing",
"search",
"search"
]
}
search 标签已追加到 tags 数组中。
views 字段已递增。
我们甚至可以选择通过设置 ctx.op 为 delete 来删除基于其内容的文档:
POST /website/_update/1
{
"script" : {
"source": "if (ctx._source.views == params.count) { ctx.op = 'delete' } else { ctx.op = 'none' }",
"params" : {
"count" : 1
}
}
}
删除成功
{
"_index": "website",
"_id": "1",
"_version": 9,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}
更新的文档可能尚不存在
假设我们需要在 Elasticsearch 中存储一个页面访问量计数器。 每当有用户浏览网页,我们对该页面的计数器进行累加。但是,如果它是一个新网页,我们不能确定计数器已经存在。 如果我们尝试更新一个不存在的文档,那么更新操作将会失败。
在这样的情况下,我们可以使用 upsert 参数,指定如果文档不存在就应该先创建它:
POST /website/_update/4
{
"script" : {
"source": "if (ctx._source.containsKey('views')) { ctx._source.views += 1 } else { ctx._source.views = params.initialValue }",
"params" : {
"initialValue" : 1
}
},
"upsert": {
"views": 1
}
}
这个更新请求中使用了 upsert 参数来处理文档不存在的情况,它会根据提供的文档内容创建一个新文档。如果文档ID为 2 的文档存在,则执行脚本将 views 字段加一;如果文档不存在,则创建一个新文档并将 views 字段的初始值设为 1。
请注意,script 中的脚本判断了文档中是否包含 views 字段,如果存在则将其加一,否则将其设为初始值。这样可以确保在不同情况下都能正确地更新文档。
更新和冲突
在本节的介绍中,我们说明 检索 和 重建索引 步骤的间隔越小,变更冲突的机会越小。 但是它并不能完全消除冲突的可能性。 还是有可能在 update 设法重新索引之前,来自另一进程的请求修改了文档。
为了避免数据丢失, update API 在 检索 步骤时检索得到文档当前的 _version 号,并传递版本号到 重建索引 步骤的 index 请求。 如果另一个进程修改了处于检索和重新索引步骤之间的文档,那么 _version 号将不匹配,更新请求将会失败。
对于部分更新的很多使用场景,文档已经被改变也没有关系。 例如,如果两个进程都对页面访问量计数器进行递增操作,它们发生的先后顺序其实不太重要; 如果冲突发生了,我们唯一需要做的就是尝试再次更新。
这可以通过设置参数 retry_on_conflict 来自动完成, 这个参数规定了失败之前 update 应该重试的次数,它的默认值为 0 。
POST /website/_update/1?retry_on_conflict=5
{
"script" : "ctx._source.views+=1",
"upsert": {
"views": 0
}
}
失败之前重试该更新5次。
在增量操作无关顺序的场景,例如递增计数器等这个方法十分有效,但是在其他情况下变更的顺序 是 非常重要的。 类似 index API , update API 默认采用 最终写入生效 的方案,但它也接受一个 version 参数来允许你使用 optimistic concurrency control 指定想要更新文档的版本。
取回多个文档
Elasticsearch 的速度已经很快了,但甚至能更快。 将多个请求合并成一个,避免单独处理每个请求花费的网络延时和开销。 如果你需要从 Elasticsearch 检索很多文档,那么使用 multi-get 或者 mget API 来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
mget API 要求有一个 docs 数组作为参数,每个元素包含需要检索文档的元数据, 包括 _index 、 _type 和 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字:
GET /_mget
{
"docs" : [
{
"_index" : "website",
"_id" : 2
},
{
"_index" : "website",
"_id" : 1,
"_source": "views"
}
]
}
该响应体也包含一个 docs 数组, 对于每一个在请求中指定的文档,这个数组中都包含有一个对应的响应,且顺序与请求中的顺序相同。 其中的每一个响应都和使用单个 get request 请求所得到的响应体相同:
{
"docs": [
{
"_index": "website",
"_id": "2",
"_version": 2,
"_seq_no": 30,
"_primary_term": 2,
"found": true,
"_source": {
"title": "My first blog entry",
"text": "Just trying this out...",
"views": 1
}
},
{
"_index": "website",
"_id": "1",
"_version": 34,
"_seq_no": 45,
"_primary_term": 2,
"found": true,
"_source": {
"views": 18
}
}
]
}
如果想检索的数据都在相同的 _index 中,则可以在 URL 中指定默认的 /_index 或者默认的 /_index/_type 。
你仍然可以通过单独请求覆盖这些值:
GET /website/_mget
{
"docs" : [
{ "_id" : 2 },
{ "_id" : 1 }
]
}
事实上,如果所有文档的 _index 都是相同的,你可以只传一个 ids 数组,而不是整个 docs 数组:
GET /website/_mget
{
"ids" : [ "2", "1" ]
}
注意,我们请求的第二个文档如果是不存在的。并不妨碍第一个文档被检索到。每个文档都是单独检索和报告的。
代价较小的批量操作
与 mget 可以使我们一次取回多个文档同样的方式, bulk API 允许在单个步骤中进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
......
这种格式类似一个有效的单行 JSON 文档 流 ,它通过换行符(\n)连接到一起。注意两个要点:
- 每行一定要以换行符
(\n)结尾, 包括最后一行 。这些换行符被用作一个标记,可以有效分隔行。 - 这些行不能包含未转义的换行符,因为他们将会对解析造成干扰。这意味着这个 JSON 不 能使用 pretty 参数打印。
action/metadata 行指定 哪一个文档 做 什么操作 。
action 必须是以下选项之一:
create
如果文档不存在,那么就创建它。详情请见 创建新文档。
index
创建一个新文档或者替换一个现有的文档。详情请见 索引文档 和 更新整个文档。
update
部分更新一个文档。详情请见 文档的部分更新。
delete
删除一个文档。详情请见 删除文档。
metadata 应该指定被索引、创建、更新或者删除的文档的 _index 和 _id 。
例如,一个 delete 请求看起来是这样的:
{ "delete": { "_index": "website", "_id": "123" }}
request body 行由文档的 _source 本身组成—文档包含的字段和值。它是 index 和 create 操作所必需的,这是有道理的:你必须提供文档以索引。
它也是 update 操作所必需的,并且应该包含你传递给 update API 的相同请求体: doc 、 upsert 、 script 等等。 删除操作不需要 request body 行。
{ "create": { "_index": "website", "_id": "123" }}
{ "title": "My first blog post" }
如果不指定 _id ,将会自动生成一个 ID :
{ "create": { "_index": "website"}}
{ "title": "My second blog post" }
为了把所有的操作组合在一起,一个完整的 bulk 请求 有以下形式:
POST /_bulk
{ "delete": { "_index": "website", "_id": "123" }}
{ "create": { "_index": "website", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website"}}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_id": "123"} }
{ "doc" : {"title" : "My updated blog post"} }
请注意 delete 动作不能有请求体,它后面跟着的是另外一个操作。
谨记最后一个换行符不要落下。
这个 Elasticsearch 响应包含 items 数组,这个数组的内容是以请求的顺序列出来的每个请求的结果。
{
"took": 18,
"errors": false,
"items": [
{
"delete": {
"_index": "website",
"_id": "123",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 46,
"_primary_term": 2,
"status": 404
}
},
{
"create": {
"_index": "website",
"_id": "123",
"_version": 2,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 47,
"_primary_term": 2,
"status": 201
}
},
{
"index": {
"_index": "website",
"_id": "GlCcpI4BZKfEnzIxjB5j",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 48,
"_primary_term": 2,
"status": 201
}
},
{
"update": {
"_index": "website",
"_id": "123",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 49,
"_primary_term": 2,
"status": 200
}
}
]
}
每个子请求都是独立执行,因此某个子请求的失败不会对其他子请求的成功与否造成影响。 如果其中任何子请求失败,最顶层的 error 标志被设置为 true ,并且在相应的请求报告出错误明细:
Bulk update example
When using the update action, retry_on_conflict can be used as a field in the action itself (not in the extra payload line), to specify how many times an update should be retried in the case of a version conflict.
The update action payload supports the following options: doc (partial document), upsert, doc_as_upsert, script, params (for script), lang (for script), and _source. See update documentation for details on the options. Example with update actions:
POST _bulk
{"update":{"_id":"1","_index":"index1","retry_on_conflict":3}}
{"doc":{"field":"value"}}
{"update":{"_id":"0","_index":"index1","retry_on_conflict":3}}
{"script":{"source":"ctx._source.counter += params.param1","lang":"painless","params":{"param1":1}},"upsert":{"counter":1}}
{"update":{"_id":"2","_index":"index1","retry_on_conflict":3}}
{"doc":{"field":"value"},"doc_as_upsert":true}
{"update":{"_id":"3","_index":"index1","_source":true}}
{"doc":{"field":"value"}}
{"update":{"_id":"4","_index":"index1"}}
{"doc":{"field":"value"},"_source":true}
- {“update” : {“_id” : “1”, “_index” : “index1”, “retry_on_conflict” : 3} 这一行表示要更新索引名称为 index1 中文档ID为 1 的文档。
retry_on_conflict 参数指定在发生版本冲突时重试的次数。 - {“doc” : {“field” : “value”}} 这一行表示更新操作的内容,将文档中的 field 字段更新为 “value”。
- {“update” : { “_id” : “0”, “_index” : “index1”, “retry_on_conflict” : 3}} 这一行表示要更新索引名称为 index1 中文档ID为 0 的文档。retry_on_conflict 参数指定在发生版本冲突时重试的次数。
- {“script” : { “source”: “ctx._source.counter += params.param1”, “lang” : “painless”, “params” : {“param1” : 1}}, “upsert” : {“counter” : 1}} 这一行表示更新操作的内容,使用脚本更新文档。脚本会将文档中的 counter 字段加一,如果文档不存在则创建一个新文档并设置 counter 字段为 1。
- {“update” : {“_id” : “2”, “_index” : “index1”, “retry_on_conflict” : 3}} 这一行表示要更新索引名称为 index1 中文档ID为 2 的文档。 retry_on_conflict 参数指定在发生版本冲突时重试的次数。
- {“doc” : {“field” : “value”}, “doc_as_upsert” : true} 这一行表示更新操作的内容,如果文档不存在则插入新文档。doc_as_upsert 参数指示如果文档不存在,则将内容作为新文档插入。
- {“update” : {“_id” : “3”, “_index” : “index1”, “_source” : true}} 这一行表示要更新索引名称为 index1 中文档ID为 3 的文档。_source 参数指示返回更新后的文档内容。
- {“doc” : {“field” : “value”}} 这一行表示更新操作的内容,将文档中的 field 字段更新为 “value”。
- {“update” : {“_id” : “4”, “_index” : “index1”}} 这一行表示要更新索引名称为 index1 中文档ID为 4 的文档。
- {“doc” : {“field” : “value”}, “_source”: true} 这一行表示更新操作的内容,将文档中的 field 字段更新为 “value”,并返回更新后的文档内容。
不要重复指定Index和Type
也许你正在批量索引日志数据到相同的 index。 但为每一个文档指定相同的元数据是一种浪费。相反,可以像 mget API 一样,在 bulk 请求的 URL 中接收默认的 /_index:
POST /website/_bulk
{ "index": {}}
{ "event": "User logged in" }
你仍然可以覆盖元数据行中的 _index , 但是它将使用 URL 中的这些元数据值作为默认值:
POST /website/_bulk
{ "index": {}}
{ "event": "User logged in" }
{ "index": { "_index": "index1" }}
{ "title": "Overriding the default type" }
{
"took": 73,
"errors": false,
"items": [
{
"index": {
"_index": "website",
"_id": "ftOwpI4BcLBcQz50F_Fh",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 56,
"_primary_term": 2,
"status": 201
}
},
{
"index": {
"_index": "index1",
"_id": "f9OwpI4BcLBcQz50F_Fh",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1,
"status": 201
}
}
]
}
多大是太大了?
整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
幸运的是,很容易找到这个 最佳点 :通过批量索引典型文档,并不断增加批量大小进行尝试。 当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。
密切关注你的批量请求的物理大小往往非常有用,一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 一个好的批量大小在开始处理后所占用的物理大小约为 5-15 MB。










