在面对复杂条件查询时,MYSQL往往显得力不从心,一般公司的做法会通过将mysql中的数据同步到ES,之后的查询就通过ES进行查询,ES在面对多条件复杂查询时,能较快的查询出结果集。
在MYSQL数据 到ES中的数据同步 方案设计上,就有多种选择,
1,最简单的便是直接在业务代码中对数据库进行修改,插入,删除时,同步修改ES中的数据。 但这种方案也是最不可靠的一种设计。在写入MYSQL后,业务服务宕机了,ES数据就会丢失。如果写入ES失败,重试逻辑将会嵌套在业务代码中,业务代码复杂性增加了,并且如果一直失败,要一直重试吗?
所以,对于这种方案,直接pass掉了。
2,第二种同步方案则是业界用的比较多的同步方案,通过binlog进行同步,目前业界已经有比较成熟的模拟mysql从库,拉取binlog的组件,例如阿里开源的canal。整个同步架构如下所示,canal组件充当mysql从库的角色,将mysql的binlog拉取下来,由客户端从canal拉取消息进行消费,再由客户端主动插入或者更新ES中的数据。
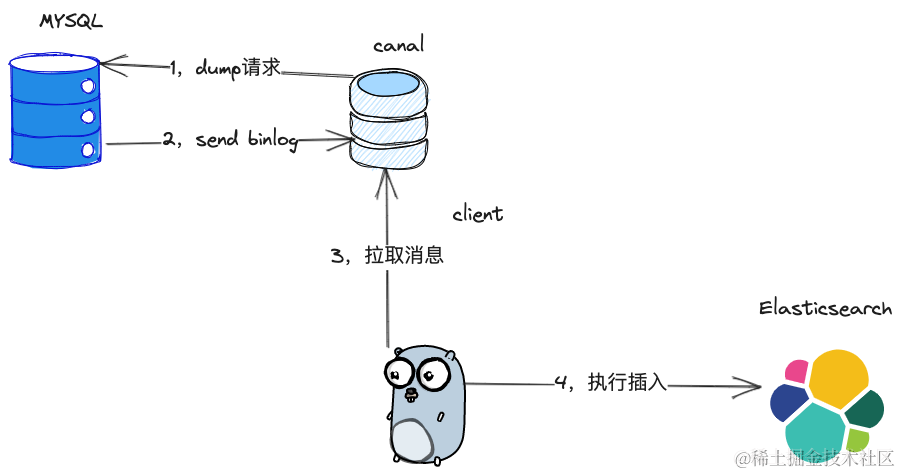
所以,我们部门选择了第二种同步方案,并且由于数据量并不大,也没有接入kafka,直接采用客户端从cannal侧拉数据的方式。
canal 同步数据异常情况分析
接着我先来提几个问题,我们可以思考🤔看看当前的架构设计是否能满足数据同步的基本要求。
1,如果客户端消费数据失败,会造成数据丢失吗?
2,如果cannal崩溃了,那么会造成拉取的binlog没有被消费而造成数据丢失的情况吗?
3,canal会有重复推送消费消息的情况吗?
4,如果ES侧暂时宕机,要想不丢失数据,应该怎么做?
以上是我针对同步数据时 围绕这个设计方案的可靠性与可恢复 提出的几个问题,我们针对它们来看看同步数据应该如何来做。
第一个问题, 客户端如果从canal 拉取到了消息,但是本地由于异常,或者宕机 导致消费失败了,可以做到不丢失数据。因为canal 对于消息的消费模型提供了ACK机制,客户端在拉取完一批消息后,可以依次消费消息,然后发送对应消息的ACK,如果消费失败,或者本地宕机,那么下次拉取消息的时候依然能够拉取到没有消费完的消息。
第二个问题, cannal 如果异常崩溃,也是可以做到 消息不丢失,canal在从数据库拉取binlog时,会记录拉取的日志偏移量offset到内存,但是偏移量的持久化 其实是通过定时任务 考虑客户端ACK位点后,才进行记录的,可以选择记录到zookeeper或者本地文件。所以如果canal宕机了,那么重启后,会从zookeeper或者本地文件中读取客户端最后ack的位点,然后从这个位置开始从数据库拉取消息。为了让canal 快速恢复,还可以做canal集群,让集群中始终有备节点。
第三个问题,canal的确会有重复推送消费消息的可能,正如第二问题说的那样 偏移量的持久化是通过定时任务记录的,所以存在客户端消费了消息,但是这个ack位点还没有持久化的情况,如果这个时候canal 宕机重启了,那么将会把客户端消费过的消息也再发一遍。所以客户端消费消息需要做幂等处理。
第四个问题, 如果ES侧的数据写入失败了,或者ES直接宕机,也是能够做到ES宕机恢复后,数据不丢失的,最简单的方式其实是客户端发现ES写入失败了,然后不ACK消息,直接不断重试,直到写入成功为止,不过这种做法其实不太好,因为不ACK,那么消息会一直存到canal的内存里,同时canal会不断dump 数据库的binlog日志,又塞到内存里等待被客户端拉取消费,这样造成的后果就是canal 的内存会越来越大,最终停止数据库的同步操作。
一个比较好点的方式是,客户端消费了canal的消息,直接在本地将消息保存起来,比如写入到磁盘文件上,写入成功后即可发起ACK,然后本地启一个协程慢慢将磁盘文件上的消息更新到ES中,所以,最后选用了leveldb 对做本地文件的写入,leveldb写入文件的操作是很快的,这样快速的ACK消息对canal的内存压力也会小很多。
综上,我们部门的数据同步模型就变成了下面这样,canal做了集群,保证宕机了还有其他节点可以继续同步,客户端则是消费消息后将先把消息写入到本地,然后开启定时任务写入到ES,如果有错误的话,会一直重试,直到成功为止。
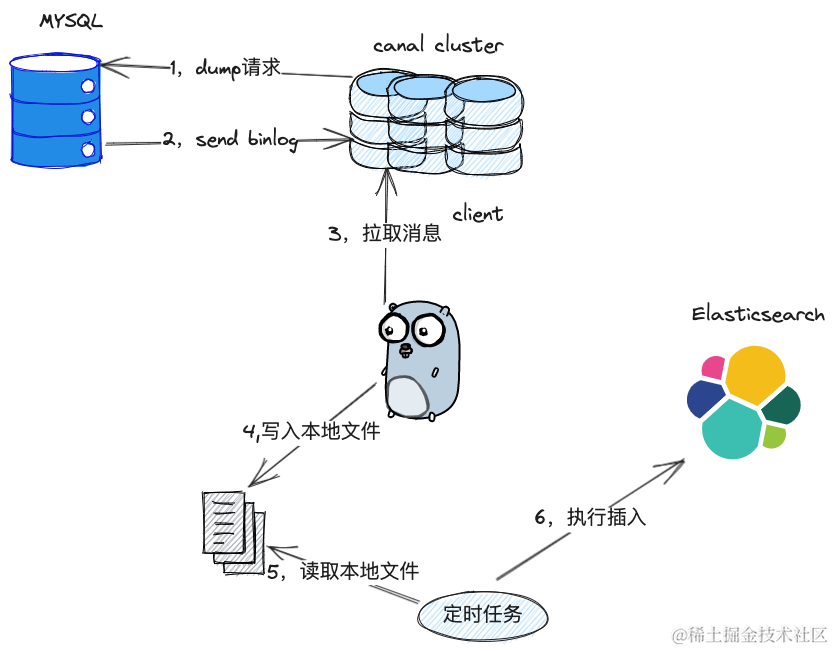
总结
最后,我来总结下,采用canal 去做MySQL 到ES的数据同步,我们的确是可以做到高可靠性的,但是要注意的canal的消息消费是有可能出现重复消息的,不过由于目前我们部门没有对消息进行统计的需求,仅仅是将数据进行更新或者插入,存在即更新,没有即插入,所以是幂等,可以不用太过关注。










