华子目录
- 概念
- 工作流程
- awk程序执行方式
- awk命令的基本语法
- 记录和域(记录表示数据行,域表示行中的一小段)
- NR,NF,FILENAME变量
- awk变量
- awk运算符
- awk的模式
- awk控制语句
- 格式化输出
- awk数组
概念
- awk是Linux以及UNIX环境中现有的功能最强大的数据处理工具,awk其名称来自于它的创始人Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母
- awk是一种处理文本数据的编程语言,适合文本处理和报表生成,awk的设计使得它非常适合于处理由行和列组成的文本数据
- awk还是一种编程语言环境,它提供了正则表达式的匹配,流程控制,运算符,表达式,变量以及函数等一系列的程序设计语言所具备的特性,它从C语言中获取了一些优秀的思想(按行处理)
工作流程
工作图
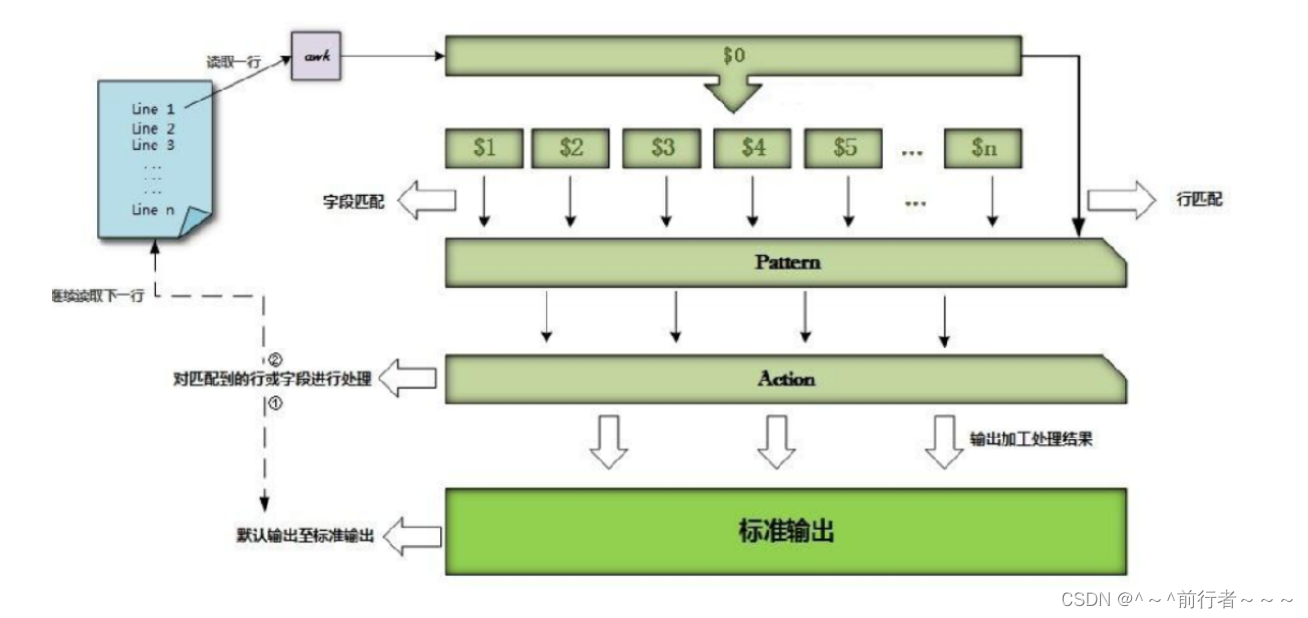
流程(按行处理)
- 第一步:自动从指定的数据文件中读取行文本
- 第二步:自动更新awk的内置系统变量的值,例如列数变量NF,行数变量NR,行变量$0以及各个列变量$1、$2等等
- 第三步:依次执行程序中所有的匹配模式及操作
- 第四步:当执行完程序中所有的匹配模式及其操作之后,如果数据文件中仍然还有读取的数据行,则返回到第(1)步,重复执行(1)~(4)的操作
awk程序执行方式
1.通过命令行执行awk程序
- 任何awk语句都由模式
pattern和动作action组成- 模式:由一组用于测试输入行是否需要执行动作的规则(条件)
- 动作:包含语句,函数和表达式的执行过程
- 简言之:模式决定动作何时触发和触发事件,动作执行对输入行的处理
实例
[root@server ~]# awk '/行向匹配条件/{匹配完后要做的动作}' 文件名
[root@server ~]# vim input.txt #点i键,输入多个空行
[root@server ~]# awk '/^$/{print "This is a blank line."}' input.txt #^$:匹配空行,在input.txt文本中匹配空行后输出This is a blank line. 直到处理到input.txt中的最后一行为止
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
2.awk命令调用脚本执行
- 在awk程序语句比较多的情况下,用户可以将所有的语句写在一个脚本文件中,然后通过awk命令来解释并执行其中的语句。awk调用脚本的语法如下
[root@server ~]# awk -f program-file file
- -f选项表示从脚本文件中读取awk程序语句,program-file表示awk脚本文件名称,file表示要处理的数据文件
实例
[root@server ~]# vim scr.awk
/^$/{print "This is a blank line."}
[root@server ~]# awk -f scr.awk input.txt #使用命令及脚本结合的方法执行
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
3.直接使用awk脚本文件调用
- 在上面介绍的两种方式中,用户都需要输入awk命令才能执行程序。除此之外,用户还可以通过类似于Shell脚本的方式来执行awk程序。在这种方式中,需要在awk程序中指定命令解释器,并且赋予脚本文件的可执行权限。其中指定命令解释器的语法如下
#!/bin/awk -f
- 以上语句必须位于脚本文件的第一行
- 通过以下命令执行awk程序:
[root@server ~]# ./script.awk file
实例
[root@server ~]# vim awktest.awk
#!/bin/awk -f #注意:awk脚本解释器
/^$/{print "This is a blank line."}
[root@server ~]# chmod +x awktest.awk #赋予执行权限
[root@server ~]# ./awktest.awk input.txt #执行
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
This is a blank line.
awk命令的基本语法
格式
[root@server ~]# awk 'BEGIN{commands} pattern{comands} END{comands}' [inputfile]
- inputfile表示awk处理的文件
BEGIN模式与END模式
- BEGIN模式是一种特殊的内置模式,其执行的时机为awk程序刚开始执行,但是又尚未读取任何数据之前。因此,该模式所对应的操作仅仅被执行一次,当awk读取数据之后,BEGIN模式便不再成立。所以,用户可以将与数据文件无关,而且在整个程序的生命周期中,只需执行一次的代码放在BEGIN模式对应的操作中,一般用于打印报告的标题和更改内在变量的值
- END模式是awk的另外一种特殊模式,该模式执行的时机与BEGIN模式恰好相反,它是在awk命令处理完所有的数据,即将退出程序时成立,在此之前,END模式并不成立。无论数据文件中包含多少行数据,在整个程序的生命周期中,该模式所对应的操作只被执行1次。因此,一般情况下,用户可以将许多善后工作放在END模式对应的操作中,一般用于打印总结性的描述或数值总和
实例
[root@server ~]# awk 'BEGIN{print "begin..."} {print $0} END{print "The end"}' /etc/fstab
begin...
#
# /etc/fstab
# Created by anaconda on Fri Nov 10 15:23:57 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=efa541c3-f73f-4597-84b4-40b9185aee51 /boot xfs defaults 0 0
/dev/mapper/rhel-swap none swap defaults 0 0
The end
[root@server ~]# awk 'BEGIN{print "begin..."} {print $0} END{print "The end"}' /etc/hosts #0表示打印全部
begin...
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
The end
[root@server ~]# awk 'BEGIN{print "begin..."} {print $1} END{print "The end"}' /etc/hosts #1表示打印每行的第一段
begin...
127.0.0.1
::1
The end
[root@server ~]# awk 'BEGIN{print "begin..."} {print $2} END{print "The end"}' /etc/hosts #2表示打印每行的第二段
begin...
localhost
localhost
The end
awk的输出
- 格式
[root@server ~]# awk 'BEGIN{commands} {print item1,item2...} END{comands}' [inputfile]
- 各项目之间使用逗号隔开,而输出到屏幕时则以空格字符分隔
- 输出的item可以为字符串或数值或当前记录的字段(如$1)或变量或awk的表达式;数值会先转换为字符串,然后再输出
记录和域(记录表示数据行,域表示行中的一小段)
概念
- awk认为输入文件是结构化的,awk将每个输入文件行定义为记录,行中的每个字符串定义为域,域之间用空格,Tab键或其他符号进行分隔,分隔域的符号就叫做分隔符,默认为空格或Tab
- awk定义域操作符
$来指定执行动作的域,域操作符$后面跟数字或变量来标识域的位置,每条记录的域从1开始编号,如$1表示第一个域 ,$0表示所有域
实例
[root@server ~]# vim awk1.txt
li xiaoming xian 13289776875
zhang cunhua beijing 14796823450
wang xiaoer xiaoyang 14356990823
[root@server ~]# awk '{print $0}' awk1.txt
li xiaoming xian 13289776875
zhang cunhua beijing 14796823450
wang xiaoer xiaoyang 14356990823
[root@server ~]# awk '{print $1,$2}' awk1.txt
li xiaoming
zhang cunhua
wang xiaoer
[root@server ~]# awk '{print $1}' awk1.txt
li
zhang
wang
[root@server ~]# awk '{print $1,$4}' awk1.txt
li 13289776875
zhang 14796823450
wang 14356990823
[root@server ~]# awk 'BEGIN{one=1;two=2} {print $(one+two)}' awk1.txt #BEGIN中的变量必须使用;隔开
xian
beijing
xiaoyang
- 查看本机IP
[root@server ~]# ip a | grep ens160 | grep inet | awk '{print $2}'
192.168.80.129/24
或
[root@server ~]# ip a | grep ens160 | awk '/inet/{print $2}'
192.168.80.129/24
- 查看内存剩余量
[root@server ~]# free -m | awk '/Mem/{print $4}' #西安执行条件匹配,再执行动作
845
- 查看开机挂载设备的文件系统
[root@server ~]# awk '/^[^#]/{print $3}' /etc/fstab
xfs
xfs
swap
- 查看hosts文件的IP地址
[root@server ~]# awk '{print $1}' /etc/hosts
127.0.0.1
::1
使用-F参数指定域之前的分隔符(默认为空格或tab)
语法
[root@server ~]# awk -F "符号" '/匹配条件/{执行动作}' 文件名
实例
- 查看本机所有账户的名称及UID
[root@server ~]# awk -F ':' '{print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 65534
systemd-coredump 999
dbus 81
polkitd 998
avahi 70
tss 59
colord 997
clevis 996
rtkit 172
sssd 995
geoclue 994
libstoragemgmt 993
setroubleshoot 992
pipewire 991
flatpak 990
gdm 42
cockpit-ws 989
cockpit-wsinstance 988
gnome-initial-setup 987
sshd 74
chrony 986
dnsmasq 985
tcpdump 72
systemd-oom 978
redhat 1000
[root@server ~]# awk -F ':' 'BEGIN{print "账户名","UID"} {print $1,$3}' /etc/passwd
账户名 UID
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 65534
systemd-coredump 999
dbus 81
polkitd 998
avahi 70
tss 59
colord 997
clevis 996
rtkit 172
sssd 995
geoclue 994
libstoragemgmt 993
setroubleshoot 992
pipewire 991
flatpak 990
gdm 42
cockpit-ws 989
cockpit-wsinstance 988
gnome-initial-setup 987
sshd 74
chrony 986
dnsmasq 985
tcpdump 72
systemd-oom 978
redhat 1000
使用系统内置变量FS修改分隔符
语法
[root@server ~]# awk 'BEGIN{FS="符号"} /匹配条件/{执行动作}' 文件名
[root@server ~]# awk 'BEGIN{print $FS}'
[root@server ~]# awk 'BEGIN{FS=":";print "账户名","UID"} {print $1,$3}' /etc/passwd
账户名 UID
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 65534
systemd-coredump 999
dbus 81
polkitd 998
avahi 70
tss 59
colord 997
clevis 996
rtkit 172
sssd 995
geoclue 994
libstoragemgmt 993
setroubleshoot 992
pipewire 991
flatpak 990
gdm 42
cockpit-ws 989
cockpit-wsinstance 988
gnome-initial-setup 987
sshd 74
chrony 986
dnsmasq 985
tcpdump 72
systemd-oom 978
redhat 1000
[root@server ~]# awk 'BEGIN{FS=":";print "UID","GID"} {print $3,$4}' /etc/passwd
UID GID
0 0
1 1
2 2
3 4
4 7
5 0
6 0
7 0
8 12
11 0
12 100
14 50
65534 65534
999 997
81 81
998 996
70 70
59 59
997 993
996 992
172 172
995 991
994 990
993 989
992 988
991 986
990 985
42 42
989 984
988 983
987 982
74 74
986 981
985 980
72 72
978 978
1000 1000
NR,NF,FILENAME变量
- NR变量:表示记录数,及行号
- NF变量:表示处理的域数量
- FILENAME变量:被处理的文件名
实例
[root@server ~]# awk '{print NR,NF,$0} END{print FILENAME}' awk1.txt
1 4 li xiaoming xian 13289776875
2 4 zhang cunhua beijing 14796823450
3 4 wang xiaoer xiaoyang 14356990823
awk1.txt
#4表示这一行有4段
[root@server ~]# awk '{print "第",NR,"行","有",NF,"段" > "/root/t1.txt"}' awk1.txt
[root@server ~]# cat t1.txt
第 1 行 有 4 段
第 2 行 有 4 段
第 3 行 有 4 段
[root@server ~]# awk '{print "第",NR,"行","有",NF,"段"}' awk1.txt > /root/t1.txt
[root@server ~]# cat t1.txt
第 1 行 有 4 段
第 2 行 有 4 段
第 3 行 有 4 段
awk变量
概念
- 与其他的程序设计语言一样,awk本身支持变量的相关操作,包括变量的定义和引用,以及参与相关的运算等。此外,还包含了许多内置的系统变量
- 变量的作用是用来存储数据。变量由变量名和值两部分组成,其中变量名是用来实现变量值的引用的途径,而变量值则是内存空间中存储的用户数据
- awk的变量名只能包括字母、数字和下划线,并且不能以数字开头。例如abc、a_、_z以及a123都是合法的变量名,而123abc则是非法的变量名。另外,awk的变量名是区分大小写的,因此,X和x分别表示不同的变量
- awk中的变量类型分为两种,分别为字符串和数值。但是在定义awk变量时,无需指定变量类型,awk会根据变量所处的环境自动判断。如果没有指定值,数值类型的变量的缺省值为0,字符串类型的变量的缺省值为空串
内置变量
| 变量 | 作用 |
|---|---|
| $0 | 记录变量,表示所有域 |
| $n | 字段变量,表示第n个域(n为1-9) |
| NF | 当前记录的域个数 |
| NR | 记录行号 |
| FS | 输入字段分隔符,默认值是空格或者制表符,可使用-F指定分隔符 |
| OFS | 输出字段分隔符 ,OFS=”#”指定输出分割符为# |
| RS | 记录分隔符,默认值是换行符 \n |
| ENVIRON | 当前shell环境变量及其值的关联数组 |
| FILENAME | 记录文件名 |
实例
- 准备实例文件
[root@server ~]# vim awk2.txt
zhangsan 68 88 92 45 71
lisi 77 99 63 52 84
wangwu 61 80 93 77 81
- 例1
[root@server ~]# vim test.awk
{
print
print "$0:",$0
print "$1:",$1
print "$2:",$2
print "NF:",NF
print "NR:",NR
print "FILENAME:",FILENAME
}
[root@server ~]# awk -f test.awk awk2.txt
zhangsan 68 88 92 45 71
$0: zhangsan 68 88 92 45 71
$1: zhangsan
$2: 68
NF: 6
NR: 1
FILENAME: awk2.txt
lisi 77 99 63 52 84
$0: lisi 77 99 63 52 84
$1: lisi
$2: 77
NF: 6
NR: 2
FILENAME: awk2.txt
wangwu 61 80 93 77 81
$0: wangwu 61 80 93 77 81
$1: wangwu
$2: 61
NF: 6
NR: 3
FILENAME: awk2.txt
- 例2
[root@server ~]# awk -F ":" 'BEGIN{OFS="\t"} {print $1,$2}' /etc/passwd #写命令时域之间用逗号,显示内容的域之间使用OFS控制
root x
bin x
daemon x
adm x
lp x
sync x
shutdown x
halt x
mail x
operator x
games x
ftp x
nobody x
systemd-coredump x
dbus x
polkitd x
avahi x
tss x
colord x
clevis x
rtkit x
sssd x
geoclue x
libstoragemgmt x
setroubleshoot x
pipewire x
flatpak x
gdm x
cockpit-ws x
cockpit-wsinstance x
gnome-initial-setup x
sshd x
chrony x
dnsmasq x
tcpdump x
systemd-oom x
redhat x
[root@server ~]# awk -F ":" 'BEGIN{OFS="---"} {print $1,$2}' /etc/passwd
root---x
bin---x
daemon---x
adm---x
lp---x
sync---x
shutdown---x
halt---x
mail---x
operator---x
games---x
ftp---x
nobody---x
systemd-coredump---x
dbus---x
polkitd---x
avahi---x
tss---x
colord---x
clevis---x
rtkit---x
sssd---x
geoclue---x
libstoragemgmt---x
setroubleshoot---x
pipewire---x
flatpak---x
gdm---x
cockpit-ws---x
cockpit-wsinstance---x
gnome-initial-setup---x
sshd---x
chrony---x
dnsmasq---x
tcpdump---x
systemd-oom---x
redhat---x
- 例3
# 面试题:打印/etc/sos/sos.conf中所有的空白行的行号
[root@server ~]# awk '/^$/{print NR}' /etc/sos/sos.conf
10
17
25
32
用户自定义变量
- awk允许用户自定义自己的变量以便在程序代码中使用
- 变量名命名规则与大多数编程语言相同,只能使用字母、数字和下划线,且不能以数字开头
- awk变量名称区分字符大小写
实例
#变量定义在BEGIN中
[root@server ~]# awk 'BEGIN{test="hello world";print test}'
hello world
#变量定义在-V参数后
[root@server ~]# awk -v test="hello world" 'BEGIN{print test}'
hello world
awk运算符
- awk是一种编程语言环境,因此,它也支持常用的运算符以及表达式,例如算术运算、逻辑运算以及关系运算等
算术运算符
+ - * / % ^(指数) **(指数)
实例
[root@server ~]# awk 'BEGIN{x=2;y=3;print x+y,x-y,x*y,x/y,x^y,x**y}'
5 -1 6 0.666667 8 8
#面试题:统计某目录下的文件占用存储空间字节数
[root@server ~]# ll /root | awk 'BEGIN{size=0} {size=size+$5} END{print size/1024,"KB"}'
1.7959 KB
赋值运算符
- 符号
= += /= *= %= ^=
实例
[root@server ~]# awk 'BEGIN{a=5;a+=5;print a}'
10
[root@server ~]# awk 'BEGIN{a=5;a*=3+2;print a}'
25
条件运算符
条件表达式?表达式1:表达式2
- 条件运算符是一个三目运算符,条表成立,则表达式1为最终结果否则表达式2为最终结果
实例
[root@server ~]# vim awk2.txt
zhangsan 68 88
lisi 77 99
wangwu 61 80
[root@server ~]# awk '{max=$2>$3?$2:$3;print NR,"max=",max}' awk2.txt
1 max= 88
2 max= 99
3 max= 80
逻辑运算符
- 符号
&& || !
关系运算符
- 符号
> < >= <= == != ~(匹配) !~(不匹配)
实例
# 查询/etc/passwd文件中第三列小于10以下的信息,仅列出账户与uid
[root@server ~]# awk -F ":" '$3<10{print $1 , $3}' /etc/passwd
# 查看ip地址
[root@server ~]# ifconfig ens160 | awk 'NR==2{print $2}' #NR定位到第二行
其他运算符
++ -- + - 等
[root@server ~]# awk 'BEGIN{a=0 ; print a++ , ++a }'
0 2
# 注意:awk变量为字符串变量时参与了算术操作,其值自动转为数值0
[root@server ~]# awk 'BEGIN{a="china" ; print a++ , ++a }'
0 2
[root@server ~]# awk 'BEGIN{a="ABABABAB" ; print a++ , ++a }'
0 2
[root@server ~]# awk '{++count ; print $0} END{print "账户数:" , count}' /etc/passwd
# 注意:count未赋初值参与算术运算时数值自动转为0
awk的模式
- awk支持关系表达式、正则表达式、混合模式、BEGIN模式、END模式等
关系表达式
- 新建示例文件
[root@server ~]# vim awk3.txt
liming 85
wangwei 99
zhangsan 68
- 例
[root@server ~]# awk '$2>80{print }' awk3.txt #print什么也不写,表示输出全部内容
正则表达式
- 与sed一样awk的正则表达式必须放置在两个/之间(/正则表达式/)
[root@server ~]# awk '/^l/{print}' awk3.txt
liming 85
[root@server ~]# awk '/^l|z/{print}' awk3.txt
liming 85
zhangsan 68
[root@server ~]# awk '/root/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
混合模式
- awk支持关系表达式或正则表达式,还支持逻辑运算符&&、|| 、!组成的混合表达式
[root@server ~]# awk '/^l/ && $2 > 80 {print}' awk3.txt
liming 85
awk控制语句
if语句
- 格式:与C语言类似
if (expression)
{
语句1
语句2
……
}
else
{
语句3
语句4
……
}
实例
[root@server ~]# vim if.awk
#!/bin/awk -f
{
if($2>=90)
{
print "优秀"
}
else
{
if($2>=80)
{
print "良好"
}
else
{
if($2>=60)
{
print "及格"
}
else
{
print "补考"
}
}
}
}
[root@server ~]# chmod +x if.awk
[root@server ~]# ./if.awk awk3.txt
良好
优秀
及格
[root@server ~]# cat awk3.txt
liming 85
wangwei 99
zhangsan 68
# 输出UID小于GID的账户名
[root@server ~]# awk 'BEGIN{FS=":"} {if($3<$4) print $1}' /etc/passwd
adm
lp
mail
games
ftp
# UID为奇数的账户名
[root@server ~]# awk 'BEGIN{FS=":"} {if($3%2==1) print $1}' /etc/passwd
# UID为偶数,但小于20的账户名
[root@server ~]# awk 'BEGIN{FS=":"} {if($3%2==0 && $3<20) print $1}' /etc/passwd
# uid包含9的账户名
[root@server ~]# awk 'BEGIN{FS=":"} {if($3~9) print $1}' /etc/passwd
# 面试题:
1.查询cpu占用率大于指定数值的信息
[root@server ~]# ps -eo user,pid,pcpu,comm | awk '{if($3>0) print}'
2.统计系统账户数(UID小于1000的为系统账户,其它为普通账户)
[root@server ~]# awk -F ":" '{if($3<1000) {x++} else {y++}} END{print "系统账户数:",x,"\n","普通账户数:",y}' /etc/passwd
系统账户数: 35
普通账户数: 2
for循环
- 格式与C语言格式相同
实例
[root@server ~]# awk 'BEGIN{for(i=1;i<=100;i++) {sum=sum+i} ; print "sum=",sum}'
sum= 5050
while循环
- 格式1
while(expression)
{
循环语句1
循环语句2
……
}
- 格式2
do{
循环语句1
循环语句2
……
}while(expression)
实例
[root@server ~]# awk 'BEGIN{while(i<=100) {sum+=i ; i++} ; print "sum=",sum}'
sum= 5050
break,continue语句
next语句
- next语句并不是用在循环结构中,而是用于awk整个执行过程中,当awk程序执行时,若遇到next语句则提前结束本行处理,会继续读取下一行
[root@server ~]# awk -F ":" '{if($3%2==0) next ; print $1}' /etc/passwd
exit
- 作用:终止awk程序执行
格式化输出
1、格式
-
与c语言格式相同
-
printf("format\n",输出列表项)
2、format
- format是一种控制输出格式的字符串,以%开头,后跟上一个字符,如:
%c:字符
%d,%i:十进制整数
%u:无符号整数
%f:浮点数
%e,%E:科学计数法
%s:字符串
%%:显示一个%
- format说明符有修饰符
N:数字
-:左对齐
+:显示数值符号
3、注意
- printf语句不会打印\n
- 字符串一般使用双引号作为定界符
4、示例
[root@server ~]# awk 'BEGIN{printf("%d,%c\n","A",97)}'
0,a
[root@server ~]# awk 'BEGIN{printf("%5d\n",12345)}'
12345
[root@server ~]# awk 'BEGIN{printf("%2d\n",12345)}'
12345
[root@server ~]# awk 'BEGIN{printf("%5d\n",12)}' #右对齐,左边补空格
12
[root@server ~]# awk 'BEGIN{printf("%-5d\n",12)}' #左对齐,右边补空格
12
[root@server ~]# awk 'BEGIN{printf("%10.2f\n",123.4567)}'
123.46
[root@server ~]# awk 'BEGIN{printf("%5.2f\n",123.4567)}'
123.46
[root@server ~]# awk 'BEGIN{printf("%.2f\n",123.4567)}'
123.46
[root@server ~]# awk 'BEGIN{printf("%E\n",123.4567)}'
1.234567E+02
[root@server ~]# awk -F ":" '{printf("%-20s%d\n",$1,$3)}' /etc/passwd
# 面试题:计算本机内存的占用率%
[root@server ~]# free | awk 'NR==2{printf("内存利用率:%%%.2f\n",($3/$2)*100)}'
awk数组
1、索引数组
- 索引数组以数字作为下标
- 通过数组的下标(索引)引用数组中所有元素,下标一般从0开始
- 例:
[root@server ~]# awk 'BEGIN{a[0]="a" ; a[1]="b" ; a[2]="c" ; a[3]="d" ; print a[0],a[1],a[2],a[3]}'
a b c d
- awk数组中元素若为空串,是合法的,注意:空串不是空
[root@server ~]# awk 'BEGIN{a[0]="a" ; a[1]="" ; a[2]="c" ; a[3]="d" ; print a[0],a[1],a[2],a[3]}'
a c d
- 当一个元素不存在于数组时,此时若引用该数值,awk会自动创建该元素,值为空串
[root@server ~]# awk 'BEGIN{a[0]="a" ; a[1]="b" ; a[2]="c" ; a[3]="d" ; print a[0],a[1],a[2],a[3],a[4]}'
a b c d
2、关联数组
- 原则:数组的索引以字符串作为下标
[root@server ~]# awk 'BEGIN{a["zero"]="a" ; a["one"]="b" ; a["two"]="c" ; a["three"]="d" ; print a["zero"],a["one"],a["two"],a["three"]}'
a b c d
- 注意:
- awk数组本质是一种使用字符串作为下标的关联数组
- awk数组中的数字下标最终会转为字符串
3、循环遍历数组
- 格式1
for(初始化;条件表达式;步长)
{
循环体语句
}
- 格式2
for(变量 in 数组)
{
循环体语句
}
- 例1:利用for循环变量i与数组下标都是数字的这一特征,按顺序输出数组元素
[root@server ~]# awk 'BEGIN{a[0]="a";a[1]="b";a[2]="c";a[3]="d"; for(i=0;i<4;i++) {print i,a[i]}}'
0 a
1 b
2 c
3 d
- 例2:数组中下标为字符串,且无规律则使用for循环的in方式访问,输出内容为无序状态
[root@server ~]# awk 'BEGIN{a["zero"]="a" ; a["one"]="b" ; a["two"]="c" ; a["three"]="d" ; for(i in a) {print i,a[i]}}'
three d
two c
zero a
one b
- 注意:awk数组本质是一种“关联数组”,默认打印的顺序是无序的,例1中时借助for循环中循环变量i的值实现输出有序的,由于i的值是数值并递增的,且刚好与数组下标相等,则使得使用数值作为数组下标时,for循环访问是按一定顺序的。
4、利用数组统计字符串出现次数
- awk中可以利用数值进行运算,如:
[root@server ~]# awk 'BEGIN{a=1;print ++a}'
2
- 变量值为字符串的自增运算
[root@server ~]# awk 'BEGIN{a="test" ; print a,++a}'
test 1
- 注意
- awk中字符串参与算术运算时会被当做数值0
- 当引用一个不存在的数组元素时,该元素被赋值为空字符串,若该空字符串参与算术运算会被当做数值0
- 例1:统计文本中IP出现次数
# 准备文本
[root@server ~]# vim iptest.txt
192.168.48.1
192.168.48.2
192.168.48.5
192.168.48.1
192.168.48.3
192.168.48.1
192.168.48.5
192.168.48.2
192.168.48.4
192.168.48.1
[root@server ~]# awk '{count[$1]++} END{ for(i in count) {print i,"次数:",count[i]}}' iptest.txt
192.168.48.1 次数: 4
192.168.48.2 次数: 2
192.168.48.3 次数: 1
192.168.48.4 次数: 1
192.168.48.5 次数: 2
- 分析
- 创建一个count数组,并将文件中ip地址行作为元素的下标,所以执行第一行时,引用的数组为count[“192.168.48.1”]
- count[“192.168.48.1”]++相当于存储的数据为0并自增1
- 继续下一行处理,运算过程同上
- 当再次遇到192.168.48.1IP地址时,会使用上一次的数组存储数据参与自增运算
- 直到所有行遍历结束,执行END模式完成打印
- 例2:查看服务器连接状态并汇总
[root@server ~]# netstat -an | awk '/^tcp/{++s[$NF]} END{for(i in s) {print i,s[i]}}'
LISTEN 8
ESTABLISHED 2
- 分析
- netstat -an:查看连接
- /^tcp/ : 通过正则过滤
- $NF:过滤结果的第6行










