t分布理论基础
t分布也称Student’s t-distribution,主要出现在小样本统计推断中,特别是当样本量较小且总体标准差未知时,用于估计正态分布的均值。其定义基于正态分布和
X
2
X^{2}
X2分布(卡方分布)。如果随机变量X服从标准正态分布
N
(
0
,
1
)
N(0,1)
N(0,1),而
Y
Y
Y服从自由度为
n
n
n的卡方分布,且
X
X
X与
Y
Y
Y相互独立,那么变量
T
=
Y
n
T = \sqrt{\frac{Y}{n}}
T=nY 服从自由度(
v
v
v)为
n
n
n的
t
t
t分布,其形状会随着自由度的变化而变化,t分布的形状会随自由度的变化而变化,当自由度较小时,t分布曲线较为平坦,且尾部较高,随着自由度的增加,t分布曲线逐渐接近正态分布曲线。
通常在大样本且假设总体标准差是已知的情况下使用正态分布,在小样本且总体标准差未知的情况下使用
t
t
t分布,特别是在进行假设检验和估计总体均值时。
t
t
t分布计算公式
T
=
X
ˉ
−
μ
S
n
.
T = \sqrt{\frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}}.
T=nSXˉ−μ.
其中:
X
ˉ
\bar{X}
Xˉ:样本均值;
μ
\mu
μ:假设的总体均值;
S
S
S:样本标准差;
n
n
n:样本大小.
t检验理论基础
t
t
t检验利用
t
t
t分布的性质来判断样本均值之间的差异是否显著,
t
t
t检验是一种统计假设检验方法,它利用t分布理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。t检验通常用于检验样本均值与某个已知值或两个样本均值间是否存在显著差异的统计方法,在进行
t
t
t检验时,会计算出一个
t
t
t统计量,该统计量服从
t
t
t分布。
单样本t检验
用于检验单个样本的均值是否与已知的某个值存在显著差异
t
=
x
ˉ
−
μ
0
s
/
n
.
t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}}.
t=s/nxˉ−μ0.
其中:
x
ˉ
\bar{x}
xˉ是样本均值,
μ
0
\mu_0
μ0是假设的总体均值,
s
s
s是样本标准差,
n
n
n是样本量。
双样本t检验
用于检验两个独立样本的均值是否存在显著差异。
t
=
x
ˉ
1
−
x
ˉ
2
s
1
2
n
1
+
s
2
2
n
2
.
t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}.
t=n1s12+n2s22xˉ1−xˉ2.
其中:
x
ˉ
1
\bar{x}_{1}
xˉ1、
x
ˉ
2
\bar{x}_{2}
xˉ2:两个样本的均值;
s
1
、
s_{1}、
s1、s_{2}$:两个样本的标准差;
n
1
n_{1}
n1、
n
2
n_{2}
n2分别是两个样本的样本量。
配对样本t检验
用于检验两个相关样本(同一组对象在不同条件下的测量值)。
t
=
d
ˉ
−
μ
d
s
d
/
n
.
t = \frac{\bar{d} - \mu_d}{s_d/\sqrt{n}}.
t=sd/ndˉ−μd.
其中:
d
ˉ
\bar{d}
dˉ:差值的均值;
μ
d
\mu_d
μd:假设的差值均值(通常为0);
s
d
s_d
sd:差值的标准差;
n
n
n:配对数据的数量。
R语言实现
使用R语言绘制 t t t分布曲线图
# 设置自由度
df <- 5
curve(dt(x, df), from = -5, to = 5, xlab = "t值", ylab = "概率密度",
main = paste("t分布曲线图 (df =", df, ")"), col = "blue", lwd = 2)
grid(col="gray", lty="dotted")
abline(v=0, col="gray")
abline(h=0, col="gray")
polygon(c(-5, seq(-5, 5, length=200), 5),
c(0, dt(seq(-5, 5, length=200), df), 0),
col="lightblue", border=NA)
生成图形
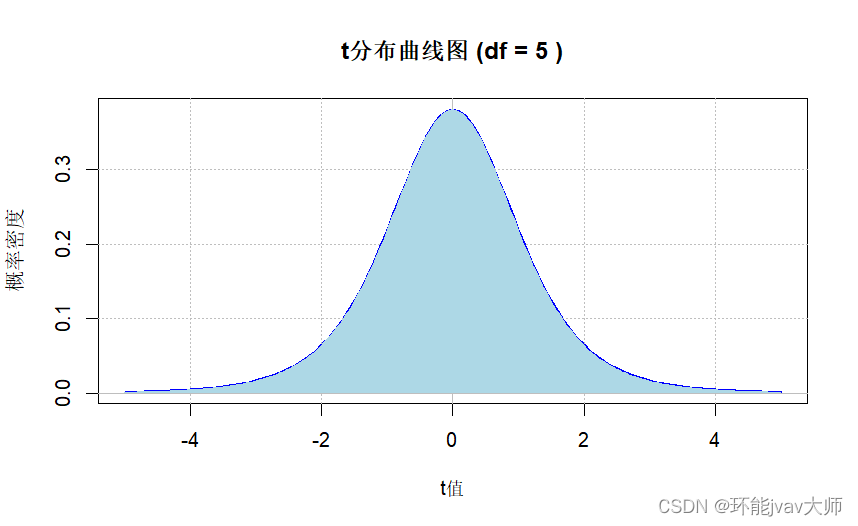
t
t
t分布单尾曲线图
df <- 5
# t > 0
curve(dt(x, df), from = 0, to = 5, xlab = "t值", ylab = "概率密度",
main = paste("t分布单尾曲线图 (df =", df, ")"), col = "blue", lwd = 2, xlim = c(0, 5))
grid(col = "gray", lty = "dotted")
polygon(c(0, seq(0, 5, length = 200), 5),
c(0, dt(seq(0, 5, length = 200), df), 0),
col = "lightblue", border = NA)
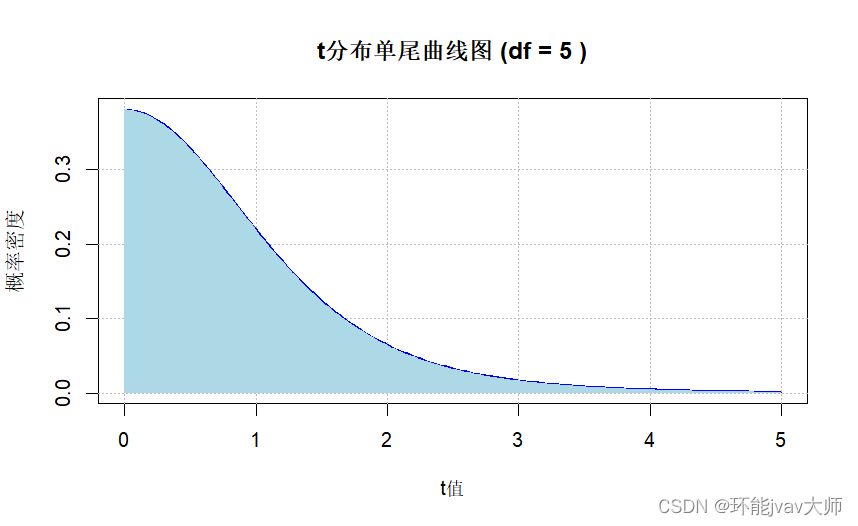
t
t
t分布双尾曲线图
df <- 5
curve(dt(x, df), from = -5, to = 5, xlab = "t值", ylab = "概率密度",
main = paste("t分布双尾曲线图 (df =", df, ")"), col = "blue", lwd = 2)
grid(col = "gray", lty = "dotted")
# t < -2
polygon(c(-5, seq(-5, -2, length = 200), -2),
c(0, dt(seq(-5, -2, length = 200), df), 0),
col = "blue", border = NA)
polygon(c(2, seq(2, 5, length = 200), 5),
c(0, dt(seq(2, 5, length = 200), df), 0),
col = "blue", border = NA)
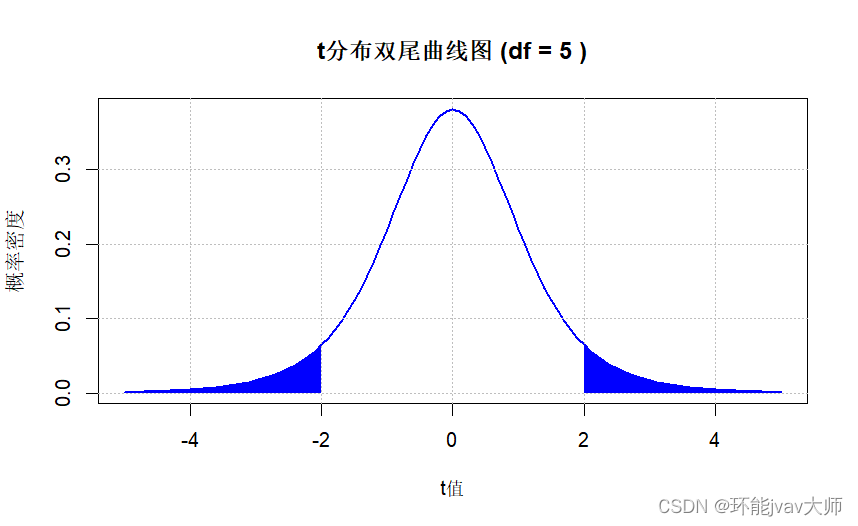 单样品t检验
单样品t检验
单样品t检验用于检验单个样本的均值与已知的某个值(通常是理论值或标准值)是否有显著差异。
# 检验数据的均值是否与某个已知值(比如10)有显著差异
data <- c(9.8, 10.2, 9.9, 10.1, 10.0, 9.7, 10.3)
print(t.test(data, mu = 10))
输出
One Sample t-test
data: data
t = 0, df = 6, p-value = 1
alternative hypothesis: true mean is not equal to 10
95 percent confidence interval:
9.80021 10.19979
sample estimates:
mean of x
10
根据输出的报告可以看出:
t值=0,样本均值与假设的均值(在这里是10)之间没有差异。
自由度=6,对于单样本t检验,
d
f
=
n
−
1
df = n - 1
df=n−1,
n
n
n是样本数量。
p值=1,不能拒绝样本均值与10没有显著差异的原假设。
置信区间=95%。
双样品t检验
用于比较两个独立样本的均值是否存在显著差异。
# 现有两组独立的数据,比较这两组数据的均值是否有显著差异
data1 <- c(9.8, 10.2, 9.9, 10.1, 10.0)
data2 <- c(9.5, 9.6, 9.7, 9.9, 9.8, 10.0, 9.7, 9.8)
print(t.test(data1, data2))
输出
Welch Two Sample t-test
data: data1 and data2
t = 2.7584, df = 8.7335, p-value = 0.02279
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.04401691 0.45598309
sample estimates:
mean of x mean of y
10.00 9.75
根据输出的报告可以看出:
t值=2.7584,在双样本t检验中,t值用于衡量两组数据的均值之间的差异,相对于它们的合并标准误差来说是否显著。
自由度=8.7335,对于双样本t检验,使用Welch公式对两个样本的大小和方差进行调整计算得出。
p值=0.02279,这小于常用的显著性水平0.05,两组数据的均值存在显著差异。
置信区间=95%。
根据R语言的输出报告显示,可以拒绝两组数据均值相同的原假设。
配对样品t检验
配对样品t检验用于比较同一组观测对象在不同条件下的测量值是否存在显著差异。
# 现有一组观测对象在两种不同条件下的测量值,检验这两种条件下测量值的均值是否有显著差异
data1 <- c(5.1, 5.5, 5.3, 5.6, 5.4)
data2 <- c(4.8, 5.0, 5.2, 5.4, 5.1)
print(t.test(data2, data1, paired = TRUE))
输出
Paired t-test
data: data2 and data1
t = -4.2212, df = 4, p-value = 0.01347
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.46416853 -0.09583147
sample estimates:
mean difference
-0.28
t值=-4.2212,在配对t检验中,t值用于衡量配对观测值之间的差异是否显著,第一组数据的均值小于第二组。
自由度=4。
p值=0.01347,由于p值小于常用的显著性水平0.05,我们可以拒绝两组数据的均值差异为0的原假设,认为两组数据的均值存在显著差异。
置信区间=95%,对于两组数据的均值差异,有95%的信心认为这个差异在-0.46416853到-0.09583147之间。
样本估计=-0.28。配对数据中计算出的实际均值差异。










