Mistral AI在3月24日突然发布并开源了 Mistral 7B v0.2模型,有如下几个特点:
-
和上一代Mistral v0.1版本相比,上下文窗口长度从8k提升到32k,上下文窗口(context window)是指语言模型在进行预测或生成文本时,所考虑的前一个token或文本片段的大小范围。随着上下文窗口长度的增加,模型可以提供更丰富的语义信息,用户使用时,体验能提升不少,也能很好的应用于RAG场景或者Agent场景这类对上下文长度要求比较高的场景。
-
Rope Theta = 1e6,Rope Theta 有助于控制大语言模型训练期间“利用”(依赖已知的良好解决方案)和“探索”(寻找新解决方案)之间的权衡。 像1e6这样的较大值意味着鼓励模型探索更多。
-
No sliding window(取消滑动窗口机制),在训练大语言模型时,滑动窗口通常用于处理较小块的输入文本(windows)而不是一次性处理全部的输入文本。 不使用sliding window意味着模型同时处理更长的文本序列,这可以提升模型理解上下文并生成更连贯的响应的能力。 但是,同时也可能会使模型变慢或更加占用资源。
以下是对Mistral 7B v0.2带来的第一手推理、微调、评测实战~
环境配置与安装
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
模型链接和下载
Mistral 7B v0.2 模型链接及原始模型权重文件链接:
https://modelscope.cn/models/AI-ModelScope/mistral-7B-v0.2
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir1 = snapshot_download("AI-ModelScope/Mistral-7B-v0.2-hf")
Mistral 7B v0.2模型推理
Mistral 7B v0.2基础模型推理代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("AI-ModelScope/Mistral-7B-v0.2-hf",torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("AI-ModelScope/Mistral-7B-v0.2-hf")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
Mistral 7B v0.2是基础模型,并不适合直接使用推理使用,推荐使用其instruct版本:
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("AI-ModelScope/Mistral-7B-Instruct-v0.2",torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("AI-ModelScope/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
模型链接:
https://modelscope.cn/models/AI-ModelScope/Mistral-7B-Instruct-v0.2
资源消耗:

Mistral 7B v0.2微调和微调后推理
# Experimental environment: A100
# 32GB GPU memory
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_sft.py \
--model_id_or_path AI-ModelScope/Mistral-7B-v0.2-hf \
--model_revision master \
--sft_type lora \
--tuner_backend swift \
--template_type AUTO \
--dtype AUTO \
--output_dir output \
--dataset dureader-robust-zh \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules DEFAULT \
--gradient_checkpointing false \
--batch_size 1 \
--weight_decay 0.1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn true \
--save_only_model true \
微调后推理
# Experimental environment: A100
# 16GB GPU memory
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_infer.py \
--ckpt_dir "output/mistral-7b-v2/vx-xxx/checkpoint-xxx" \
--load_dataset_config true \
--use_flash_attn true \
--max_new_tokens 2048 \
--temperature 0.5 \
--top_p 0.7 \
--repetition_penalty 1. \
--do_sample true \
--merge_lora false \
--eval_human false \
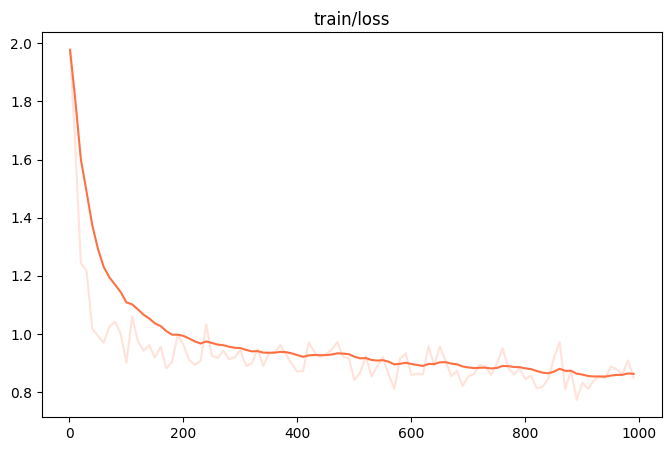
微调效果
[PROMPT]<s> Task: Question Generation
Context: 下载速度达到72mbp/s速度相当快。 相当于500兆带宽。 在网速计算中, b=bit ,B=byte 8×b=1×B 意思是 8个小写的b 才是一个大写B。 4M理论下载速度:4M就是4Mb/s 理论下载速度公式:4×1024÷8=512KB /s 请注意按公式单位已经变为 KB/s 依此类推: 2M理论下载速度:2×1024÷8=256KB /s 8M理论下载速度:8×1024÷8=1024KB /s =1MB/s 10M理论下载速度:10×1024÷8=1280KB /s =2M理论下载速度+8M理论下载速度 50M理论下载速度:50×1024÷8=6400KB /s 1Gb理论下载速度:1024×1024÷8=128MB /s 公式:几兆带宽×1024÷8=()KB/s。
Answer: 500兆带宽
Question:[OUTPUT]72mbps是多少兆带宽</s>
[LABELS]72mbps是多少网速
--------------------------------------------------
[PROMPT]<s> Task: Question Generation
Context: 【东奥会计在线——中级会计职称频道推荐】根据《关于提高科技型中小企业研究开发费用税前加计扣除比例的通知》的规定,研发费加计扣除比例提高到75%。|财政部、国家税务总局、科技部发布《关于提高科技型中小企业研究开发费用税前加计扣除比例的通知》。|通知称,为进一步激励中小企业加大研发投入,支持科技创新,就提高科技型中小企业研究开发费用(以下简称研发费用)税前加计扣除比例有关问题发布通知。|通知明确,科技型中小企业开展研发活动中实际发生的研发费用,未形成无形资产计入当期损益的,在按规定据实扣除的基础上,在2017年1月1日至2019年12月31日期间,再按照实际发生额的75%在税前加计扣除;形成无形资产的,在上述期间按照无形资产成本的175%在税前摊销。|科技型中小企业享受研发费用税前加计扣除政策的其他政策口径按照《财政部国家税务总局科技部关于完善研究开发费用税前加计扣除政策的通知》(财税〔2015〕119号)规定执行。|科技型中小企业条件和管理办法由科技部、财政部和国家税务总局另行发布。科技、财政和税务部门应建立信息共享机制,及时共享科技型中小企业的相关信息,加强协调配合,保障优惠政策落实到位。|上一篇文章:关于2016年度企业研究开发费用税前加计扣除政策企业所得税纳税申报问题的公告 下一篇文章:关于提高科技型中小企业研究开发费用税前加计扣除比例的通知
Answer: 75%
Question:[OUTPUT]研发费用扣除比例</s>
[LABELS]研发费用加计扣除比例
--------------------------------------------------
[PROMPT]<s> Task: Question Generation
Context: 防水作为目前高端手机的标配,特别是苹果也支持防水之后,国产大多数高端旗舰手机都已经支持防水。虽然我们真的不会故意把手机放入水中,但是有了防水之后,用户心里会多一重安全感。那么近日最为火热的小米6防水吗?小米6的防水级别又是多少呢? 小编查询了很多资料发现,小米6确实是防水的,但是为了保持低调,同时为了不被别人说防水等级不够,很多资料都没有标注小米是否防水。根据评测资料显示,小米6是支持IP68级的防水,是绝对能够满足日常生活中的防水需求的。
Answer: IP68级
Question:[OUTPUT]小米6防水级别</s>
[LABELS]小米6防水等级
--------------------------------------------------
[PROMPT]<s> Task: Question Generation
Context: 爬行垫根据中间材料的不同可以分为:XPE爬行垫、EPE爬行垫、EVA爬行垫、PVC爬行垫;其中XPE爬行垫、EPE爬行垫都属于PE材料加保鲜膜复合而成,都是无异味的环保材料,但是XPE爬行垫是品质较好的爬行垫,韩国进口爬行垫都是这种爬行垫,而EPE爬行垫是国内厂家为了减低成本,使用EPE(珍珠棉)作为原料生产的一款爬行垫,该材料弹性差,易碎,开孔发泡防水性弱。EVA爬行垫、PVC爬行垫是用EVA或PVC作为原材料与保鲜膜复合的而成的爬行垫,或者把图案转印在原材料上,这两款爬行垫通常有异味,如果是图案转印的爬行垫,油墨外露容易脱落。 当时我儿子爬的时候,我们也买了垫子,但是始终有味。最后就没用了,铺的就的薄毯子让他爬。
Answer: XPE
Question:[OUTPUT]爬行垫什么材质好</s>
[LABELS]爬行垫什么材质的好

用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
- 用通俗易懂的方式讲解:大模型微调方法总结
- 用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
- 用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
- 用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了










